







 本文探讨了分布式计算框架在大数据处理中的应用,包括不可变基础设施、Tachyon内存存储系统、Spark on Yarn的配置与运行问题。文章详细介绍了在Hadoop编译和运行SparkPi时遇到的挑战及解决方案,强调了MapReduce作为大数据理论基石的重要性。
本文探讨了分布式计算框架在大数据处理中的应用,包括不可变基础设施、Tachyon内存存储系统、Spark on Yarn的配置与运行问题。文章详细介绍了在Hadoop编译和运行SparkPi时遇到的挑战及解决方案,强调了MapReduce作为大数据理论基石的重要性。
因为对大数据处理的需求,使得我们不断扩展计算能力,集群计算的要求导致分布式计算框架的诞生,用廉价的集群计算资源在短短的时间内完成以往数周甚至数月的运行等待,有人说谁掌握了庞大的数据,谁就主导了需求。虽然在十几年间,通过过去几十年的积淀,诞生了mapreduce,诞生了分布式文件系统,诞生了霸主级别的Spark,不知道这是不是分布式计算框架的终点,如果还有下一代的处理框架,必然来自更大规模的数据,我想那个量级已经不是今天可以想象的。先研究好当前的,走得越深,看得越深,所以诞生Spark的地方是在AMPLab,而不是一家互联网电商巨头。
不可变基础设施
干货链接
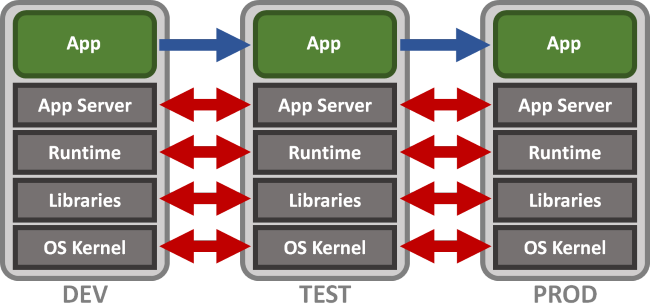
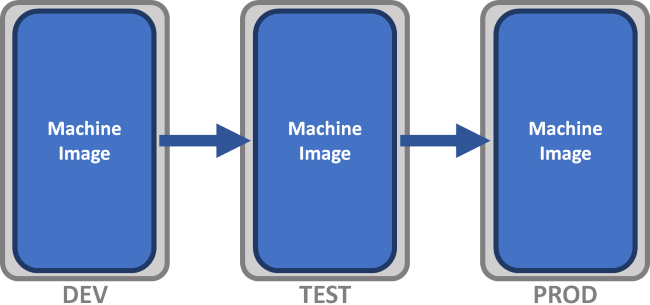
我们在本地用Eclipse Scala或者IntelliJ IDEA编写好Spark程序后,需要对其进行测试,在测试环境下,我们部署好了运行Spark所需的 Software Stack,并特别注意各个Software的版本。那如果有人想用这个程序,在他的环境下,是不同的Software Stack,那么程序就有可能失败。假如我们想要在任何机器上不费力气的部署和运行我们所开发的Spark程序,我们使用Docker将操作系统和Software Stack打成一个镜像包,让这个镜像包成为一个不可变单元,那么在任何机器上我们只要部署好这个镜像的示例,所开发的Spark应用程序便可成功运行。
下面的图出自上面第二个链接,第二个图就表述了不可变基础设施,第一个是传统的DevOps环境。
Tachyon
Spark on Yarn
搭建spark on yarn集群全过程 —— 可与 3 形成参考
Spark On YARN 集群安装部署 —— 推荐
下面是阿里云梯给出的Spark on YARN架构图
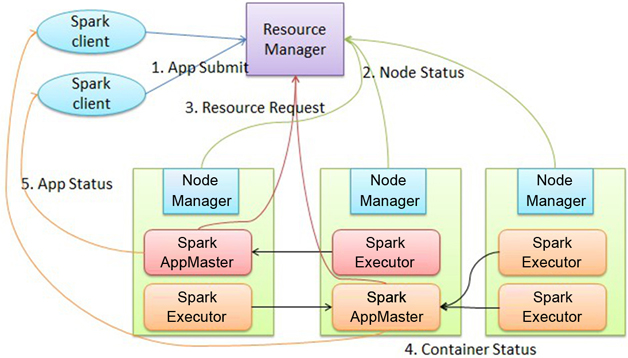
“基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager,ResourceManager在某一 NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动 SparkAppMaster,SparkAppMaster启动后初始化作业,然后向ResourceManager申请资源,申请到相应资源后 SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor,SparkExecutor向 SparkAppMaster汇报并完成相应的任务。此外,SparkClient会通过AppMaster获取作业运行状态。”
上面的信息来自
深入剖析阿里巴巴云梯YARN集群
是一篇不错的干货
1) 配置Hadoop Yarn集群时出现的问题及修复:
在每一台机器上(master和各个slave),都要对hadoop-env.sh和yarn-env.sh两个文件末尾添加(export)JAVA_HOME这个环境变量(根据具体机器上JAVA_HOME的不同而不同)。
在经过
cd ~/hadoop-2.7.1 #进入hadoop目录
bin/hadoop namenode -format #格式化namenode
sbin/start-dfs.sh #启动dfs
sbin/start-yarn.sh  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2019
2019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









