







ABAP-读取长文本
在日常开发中经常会遇到取长文本的需求,SAP针对长文本有专用的设计与底表。一般来说最常见的方法是获取长文本的表头明细,通过调用READ_TEXT函数得到一个包含文本内容的内表,此时得到的内表与前台编辑时的行内容相对应,但是一般在自开发报表中还需要将内表中的内容拼接合并显示在一个字段中。
其实在SAP中还提供了类方法来读取长文本,使用类方法替换后,可以直接获取到拼接好的字符串,并且SAP会针对其中的特殊字符进行处理,避免了一部分ALV显示bug或者接口中的报文异常问题。
首先查看长文本的表头参数。双击进入需要读取的长文本明细页面,菜单栏——转到——表头,即可查看长文本的文本抬头,包括:文本名、语言、文本ID与文本对象。其中,文本名通常由凭证号与行项目等关键对象KEY组成,文本ID根据系统实际配置有不同命名。
例如:
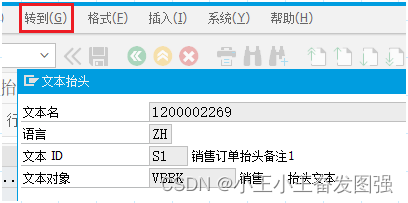
以下是调用示例:
DATA: ls_thead TYPE thead.
cl_eso_extraction_tools=>extract_long_text_by_id(
EXPORTING
iv_langu = ls_thead-tdspras "语言
iv_text_id = ls_thead-tdid "文本标识
iv_name = ls_thead-tdname "文本名
iv_object = ls_thead-tdobject "文本对象
IMPORTING
ev_search_terms = DATA(lv_long_text) ).
笔者系统为S4 1809,如果在ECC版本的系统中未找到该类方法,可以参考下文中的处理,使用正则表达式过滤特殊字符:
* Eliminate control sequences for highlighting and underlining
REPLACE ALL OCCURRENCES OF REGEX '<\s?[HU/]\s?>' IN ev_search_terms WITH space.
* Eliminate control sequences
REPLACE ALL OCCURRENCES OF REGEX '<\s?\(\s?>\s?<\s?<\s?\)\s?>\s?([^>[:blank:]]+)\s?>' IN ev_search_terms WITH space.
* Unescape the control sequences for highlighting and underlining which are part of the ordinary text
REPLACE ALL OCCURRENCES OF REGEX '<\s?\(\s?>\s?<\s?<\s?\)\s?>' IN ev_search_terms WITH '<'.
* Unescape the control sequences which are part of the ordinary text
REPLACE ALL OCCURRENCES OF REGEX '<\s?\(\s?>\s?&\s?<\s?\)\s?>\s?lt\s?;' IN ev_search_terms WITH '<' IGNORING CASE.

















 3349
3349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









