







一、张量的拼接与切分
1.1 torch.cat()
torch.cat(tensors,dim=0,out=None)
功能:将张量按维度dim进行拼接
-
tensors:张量序列
-
dim:要拼接的维度
#代码示例
flag=True
if flag:
t=torch.ones((2,3))
t_0=torch.cat([t,t],dim=0)#2+2
t_1=torch.cat([t,t],dim=1)#3+3
print("t_0:{} shape:{}\nt_1:{} shape:{}".format(t_0,t_0.shape,t_1,t_1.shape))
输出:
t_0:tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]) shape:torch.Size([4, 3])
t_1:tensor([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]]) shape:torch.Size([2, 6])
1.2torch.stack()
torch.stack(tensors,dim=0,out=None)
功能:在新创建的维度dim上进行拼接
-
tensors:张量序列
-
dim:要拼接的维度
#代码示例
flag=True
if flag:
t=torch.ones((2,3))
t_stack=torch.stack([t,t],dim=2)#原维度只有0,1,新创建维度2
t_stack1=torch.stack([t,t],dim=0)
t_stack2=torch.stack([t,t,t],dim=2)
print("t_stack:{} shape:{}".format(t_stack,t_stack.shape))
print("t_stack1:{} shape:{}".format(t_stack1,t_stack1.shape))
print("t_stack2:{} shape:{}".format(t_stack2,t_stack2.shape))
输出:
t_stack:tensor([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]]) shape:torch.Size([2, 3, 2])
t_stack1:tensor([[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]]) shape:torch.Size([2, 2, 3])
t_stack2:tensor([[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]]) shape:torch.Size([2, 3, 3])
1.3 torch.chunk()
torch.chunk(imput,chunks,dim=0)
功能:将张量按dim进行平均切分
返回值:张量列表
注意事项:若不能整除,最后一份张量小于其他张量
-
input:要切分的张量
-
chunks:要切分的份数
-
dim:要切分的维度
#代码示例
flag=True
if flag:
a=torch.ones((2,5))#任取一个张量[2,5]
list_of_tensors=torch.chunk(a,dim=1,chunks=2)#在第1维度’5‘上进行切分,切分成两份
for idx,t in enumerate(list_of_tensors):
print("第{}个张量:{} shape is {}".format(idx+1,t,t.shape))
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
#同时列出数据和数据下标,一般用在 for 循环当中。
输出:
第1个张量:tensor([[1., 1., 1.],
[1., 1., 1.]]) shape is torch.Size([2, 3])
第2个张量:tensor([[1., 1.],
[1., 1.]]) shape is torch.Size([2, 2])
1.4 torch.split()
torch.split(tensor,split_size_or_sections,dim=0)
功能:将张量按dim进行切分
返回值:张量列表
-
tensor:要切分的张量
-
split_size_or_sections:为int时,表示每一份的长度;为list时,表示按list元素切分
-
dim:要切分的维度
#代码示例
flag=True
if flag:
t=torch.ones((2,5))#任取一个张量[2,5]
list_of_tensors=torch.split(t,2,dim=1)#int
# for idx,t in enumerate(list_of_tensors):
#print("第{}个张量:{} shape is {}".format(idx+1,t,t.shape))
list_of_tensors=torch.split(t,[2,1,2],dim=1)#list[2,1,2],2+1+2=5
for idx,t in enumerate(list_of_tensors):
print("第{}个张量:{} shape is {}".format(idx+1,t,t.shape))
输出:
第1个张量:tensor([[1., 1.],
[1., 1.]]) shape is torch.Size([2, 2])
第2个张量:tensor([[1.],
[1.]]) shape is torch.Size([2, 1])
第3个张量:tensor([[1., 1.],
[1., 1.]]) shape is torch.Size([2, 2])
二、张量的索引
2.1 torch.index_select()
torch.index_select(input,dim,index,out=None)
功能:在维度dim上按index索引数据
返回值:依index索引数据拼接的张量
-
input:要索引的张量
-
dim:要索引的维度
-
index:要索引数据的序号
#代码示例
flag=True
if flag:
t=torch.randint(0,9,size=(3,3))#创建一个3*3的均匀分布张量
idx=torch.tensor([0,2],dtype=torch.long)#index数据类型必须为torch.long
t_select=torch.index_select(t,dim=0,index=idx)#查找t中0维序列号为0,2的两个张量
print("t:\n{}\n t_select:\n{} ".format(t,t_select))
输出:
t:
tensor([[4, 6, 1],
[0, 3, 4],
[4, 6, 6]])
t_select:
tensor([[4, 6, 1],
[4, 6, 6]])
2.2 torch.masked_select()
torch.masked_select(input,mask,out=None)
功能:按mask中的Ture进行索引(通常用来筛选数据)
返回值:一维张量
-
input:要索引的张量 \quad
-
mask:与input同形状的布尔类型的张量
#代码示例
flag=True
if flag:
t=torch.randint(0,9,size=(3,3))#创建一个3*3的均匀分布张量
mask=t.ge(5)#含义ge():>= gt():> le():<= lt():<,筛选t中>=5的张量元素
t_select=torch.masked_select(t,mask)#查找t中0维序列号为0,2的两个张量
print("t:\n{}\n mask:\n{}\n t_select:\n{} ".format(t,mask,t_select))
输出:
t:
tensor([[5, 6, 3],
[8, 2, 0],
[4, 0, 0]])
mask:
tensor([[ True, True, False],
[ True, False, False],
[False, False, False]])
t_select:
tensor([5, 6, 8])
三、张量的变换
3.1 torch.reshape()
torch.reshape(input,shape)
功能:变换张量形状
注意事项:当张量在内存中是连续时,新张量与input共享内存
-
input:要变换的张量
-
shape:新张量的形状
#代码示例
flag=True
if flag:
t=torch.randperm(8)#创建一个一维的张量,0-7的随机排列
t_reshape=torch.reshape(t,(2,4))#变换为[2,4]形状的张量,2*4=8
print("t:\n{}\n t_reshape:\n{}\n ".format(t,t_reshape))
t[0]=1024#改变旧张量t的第一个元素,新张量t_reshape也会改变
print("t:\n{}\nt_reshape:\n{}\n ".format(t,t_reshape))
print("t.data内存地址:{} ".format(id(t.data)))
print("t_reshape.data内存地址:{} ".format(id(t_reshape.data)))
输出:
t:
tensor([7, 3, 1, 0, 4, 6, 5, 2])
t_reshape:
tensor([[7, 3, 1, 0],
[4, 6, 5, 2]])
t:
tensor([1024, 3, 1, 0, 4, 6, 5, 2])
t_reshape:
tensor([[1024, 3, 1, 0],
[ 4, 6, 5, 2]])
t.data内存地址:2280184355840
t_reshape.data内存地址:2280184355840
3.2 torch.transpose()
torch.transpose(input,dim0,dim1)
功能:交换张量的两个维度
-
input:要变换的张量
-
dim0:要交换的维度
-
dim1:要交换的维度
#代码示例
flag=True
if flag:
t=torch.rand((2,3,4))#创建一个3维的张量
t_transpose=torch.transpose(t,dim0=1,dim1=2)#变换第2,3维
print("t.shape:{}\nt_transpose.shape:{}\n ".format(t.shape,t_transpose.shape))
输出:
t.shape:torch.Size([2, 3, 4])
t_transpose.shape:torch.Size([2, 4, 3])
3.3 torch.t()
torch.t(input)
功能:二维张量的转置,对矩阵而言等价于torch.transpose(input,0,1)
- input:要变换的张量
#代码示例
flag=True
if flag:
arr = np.ones((2, 3))#给数组取随机值
t= torch.tensor(arr)#由数组创建Tensor,两者不共用内存,修改Tensor原arry不会改变
t_t=torch.t(t)#相当于矩阵转置
print("张量t:{}\n 转置张量t_t:{}\n ".format(t,t_t))
输出:
张量t:tensor([[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
转置张量t_t:tensor([[1., 1.],
[1., 1.],
[1., 1.]], dtype=torch.float64)
3.4 torch.squeeze()
torch.squeeze(input,dim=None,out=None)
功能:压缩长度为1的维度(轴)
-
input:要变换的张量
-
dim:若为None,移除所有长度为1的轴;若指定维度,当且仅当该轴长度为1时,可以被移除
#代码示例
flag=True
if flag:
t = torch.rand((1,2,3,1))#随机创建一个4维张量
t_sq= torch.squeeze(t)#dim为None移除所有长度为1的轴
t_0=torch.squeeze(t,dim=0)#dim为0,当该轴长度为1时,可以被移除
t_1=torch.squeeze(t,dim=1)#dim为1,当该轴长度为1时,可以被移除
print("t.shape:{}\nt_sq.shape:{}\nt_0.shape:{}\nt_1.shape:{}\n ".format(t.shape,t_sq.shape,t_0.shape,t_1.shape))
输出:
t.shape:torch.Size([1, 2, 3, 1])
t_sq.shape:torch.Size([2, 3])
t_0.shape:torch.Size([2, 3, 1])
t_1.shape:torch.Size([1, 2, 3, 1])
3.5 torch.unsqueeze()
torch.unsqueeze(input,dim,out=None)
功能:依据dim拓展维度
-
input:要变换的张量$\quad
-
dim:拓展的维度
#代码示例
flag=True
if flag:
t = torch.rand((1,2,3))#随机创建一个3维张量
t_unsq= torch.unsqueeze(t,dim=0)#依据0维扩展
t_1=torch.unsqueeze(t,dim=1)#dim为1,扩展第2维
t_2=torch.unsqueeze(t,dim=2)#dim为2,扩展第3维
print("t.shape:{}\nt_unsq.shape:{}\nt_1.shape:{}\nt_2.shape:{}\n ".format(t.shape,t_unsq.shape,t_1.shape,t_2.shape))
输出:
t.shape:torch.Size([1, 2, 3])
t_unsq.shape:torch.Size([1, 1, 2, 3])
t_1.shape:torch.Size([1, 1, 2, 3])
t_2.shape:torch.Size([1, 2, 1, 3])
四、张量的运算
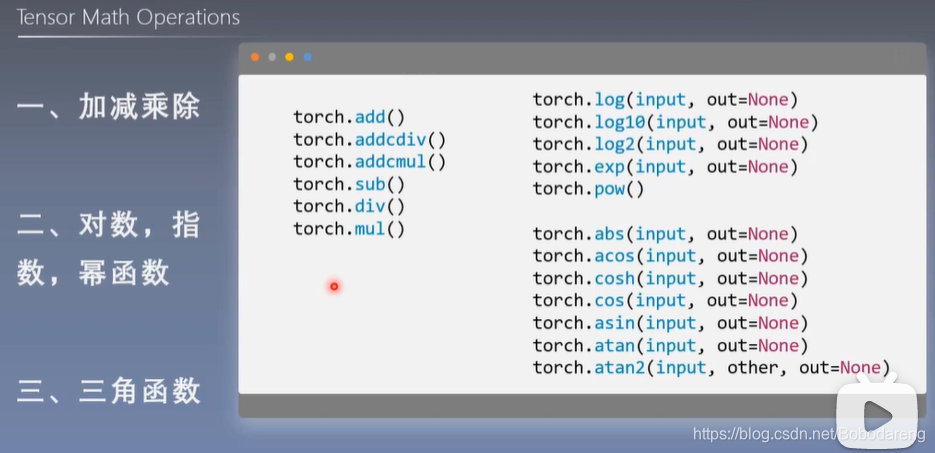
4.1 torch.add()
torch.add(input,alph=1,other,out=None)
功能:逐元素计算
i
n
p
u
t
+
a
l
p
h
a
×
o
t
h
e
r
input+alpha\times other
input+alpha×other
o u t i = i n p u t i + a l p h a × o t h e r i out_i=input_i+alpha\times other_i outi=inputi+alpha×otheri
-
input:第一个张量
-
alpha:乘项因子
-
other:第二个张量
#代码示例
flag=True
if flag:
t_0= torch.randn((3,3))#创建一个标准正态分布的[3,3]张量
t_1= torch.ones_like(t_0)#创建一个和t_0形状相同的全1张量
t_add=torch.add(t_0,10,t_1)
print("t_0:\n{}\nt_1:\n{}\nt_add_10:\n{}\n ".format(t_0,t_1,t_add))
输出:
t_0:
tensor([[-0.5449, -0.9501, 0.8472],
[-1.2785, -1.1365, -0.0290],
[-0.5881, -1.3120, 0.2595]])
t_1:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
t_add_10:
tensor([[ 9.4551, 9.0499, 10.8472],
[ 8.7215, 8.8635, 9.9710],
[ 9.4119, 8.6880, 10.2595]])
4.2 torch.addcmul()
torch.addcmul(input,value=1,tensor1,tensor2,out=None)
功能:逐元素计算
i
n
p
u
t
+
v
a
l
u
e
×
t
e
n
s
o
r
1
×
t
e
n
s
o
r
2
input+value\times tensor1\times tensor2
input+value×tensor1×tensor2
o u t i = i n p u t i + v a l u e × t e n s o r 1 i × t e n s o r 2 i out_i=input_i+value\times tensor1_i\times tensor2_i outi=inputi+value×tensor1i×tensor2i
-
input:第一个张量
-
value:乘项因子
-
tensor1:第二个张量
-
tensor2:第三个张量
4.3 torch.addcdiv()
torch.addcdiv(input,value=1,tensor1,tensor2,out=None)
功能:逐元素计算
i
n
p
u
t
+
v
a
l
u
e
×
t
e
n
s
o
r
1
t
e
n
s
o
r
2
input+value\times\frac{tensor1}{tensor2}
input+value×tensor2tensor1
o u t i = i n p u t i + v a l u e × t e n s o r 1 i t e n s o r 2 i out_i=input_i+value\times\frac{tensor1_i}{tensor2_i} outi=inputi+value×tensor2itensor1i
-
input:第一个张量
-
value:乘项因子
-
tensor1:第二个张量
-
tensor2:第三个张量
五、线性回归(Linear Regression)
线性回归是分析一个变量与另外一(多)个变量之间关系的方法
因变量:y 变量:x 关系:线性
y
=
w
×
x
+
b
y=w\times x+b
y=w×x+b
分析:求解 w,b
求解步骤:
-
确定模型:
M o d e l : y = w × x + b Model:y=w\times x+b Model:y=w×x+b -
选择损失函数:
M S E ( 均 方 差 ) : 1 m ∑ i = 1 m ( y i − y i ^ ) 2 MSE(均方差):\frac{1}{m}\sum_{i=1}^m (y_i-\hat{y_i})^2 MSE(均方差):m1i=1∑m(yi−yi^)2 -
求解梯度并更新w,b:
w = w − L R × w . g r a d b = b − L R × w . g r a d w=w-LR\times w.grad\quad \quad \quad b=b-LR\times w.grad w=w−LR×w.gradb=b−LR×w.grad
import torch.nn as nn
import pandas as pd
import matplotlib.pyplot as plt
import torch.optim as optim
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
torch.manual_seed(10)
lr=0.1#学习率
#创建训练数据
x=torch.rand(20,1)*10#随机生成的方法创建 x data (tensor),shape=[20,1]
y=2*x+(5+torch.randn(20,1))#y data (tensor),shape=[20,1]
#构建线性回归参数
w=torch.randn((1),requires_grad=True)
b=torch.zeros((1),requires_grad=True)
for iteration in range(1000):
#前向传播
wx=torch.mul(w,x)
y_pred=torch.add(wx,b)
#计算 MSE Loss
loss=(0.5*(y-y_pred)**2).mean()
#反向传播
loss.backward()
#更新参数
b.data.sub_(lr*b.grad)
w.data.sub_(lr*w.grad)
#绘图
if iteration %20==0:
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.detach().numpy(),y_pred.detach().numpy(),'turquoise',lw=2)
plt.text(2,20,'Loss=%.4f'% loss.data.numpy(),fontdict={'size':15,'color':'black'})
plt.xlim(1.5,10)
plt.ylim(8,28)
plt.title("Iteration:{}\nw:{} b:{}".format(iteration,x.data.numpy(),b.data.numpy()))
plt.pause(0.5)
if loss.data.numpy()<0.8:#设置停止迭代更新的条件
break






码字不易,觉得喜欢就请点赞或关注!谢谢
















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











