







JAVA运行时内存
JVM运行时数据区

完整的java虚拟机是由 类装载子系统, 运行时数据区, 字节码执行引擎组成首先java底层会通过类装载子系统把字节码文件装载到内存区域,最终由字节码执行引擎,执行内存中代码.字节码文件包含了java类执行的全部逻辑,反编译后可得到java指令码
大多数 JVM 将内存区域划分为 Method Area(Non-Heap)(方法区) ,Heap(堆) , Program Counter Register(程序计数器) , VM Stack(虚拟机栈,也有翻译成JAVA 方法栈的),Native Method Stack ( 本地方法栈 ),其中Method Area(方法区) 和 Heap (堆)是线程共享的
java程序的工作过程是一个 Java 源程序文件,会被编译为字节码文件(以 class 为扩展名),每个java程序都需要运行在自己的JVM上,然后告知 JVM 程序的运行入口,再被 JVM 通过字节码解释器加载运行。
JVM初始运行的时候都会分配好 Method Area(方法区) 和Heap(堆) ,而JVM 每遇到一个线程,就为其分配一个 Program Counter Register(程序计数器) , VM Stack(虚拟机栈)和Native Method Stack (本地方法栈), 当线程终止时,三者(虚拟机栈,本地方法栈和程序计数器)所占用的内存空间也会被释放掉。这也是为什么把内存区域分为线程共享和非线程共享的原因,非线程共享的那三个区域的生命周期与所属线程相同,而线程共享的区域与JAVA程序运行的生命周期相同,所以这也是系统垃圾回收的场所只发生在线程共享的区域(实际上对大部分虚拟机来说知发生在Heap上)的原因。
运行时数据区
栈内存
栈,也叫虚拟机栈,我个人更愿意称它为线程栈.线程栈主管的是java程序的运行,是在线程创建的时候创建的,生命周期就是线程的生命周期.线程结束,栈的内存也就释放了,对于栈来说不存在垃圾回收问题.基本类型的变量和对象的引用变量都是在函数的栈内存中分配
虚拟机栈为所有执行的java方法服务
栈帧
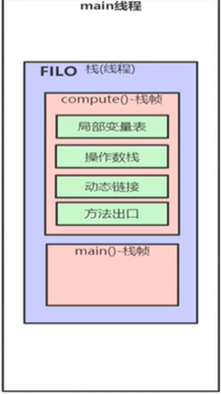
栈中的数据都是以栈帧(Stack Frame)的格式存在,栈帧是一个内存区块,是一个数据集,是一个有关方法和运行期数据的数据集.每个方法都会创建一个栈帧一个方法对应一个栈帧.当一个方法A被调用时就产生了一个栈帧F1,并被压入到栈中,A方法又调用了B方法,于是产生栈帧F2也被压入栈,B方法又调用了C方法,于是产生栈帧F3也被压入栈…… 依次执行完毕后,先弹出后进…F3栈帧,再弹出F2栈帧,再弹出F1栈帧.每个方法被调用和完成的过程,都对应一个栈帧从虚拟机上入栈和出栈的过程.
Main方法的局部变量表中,类型是Class的局部变量会把在堆中的引用地址存放在栈的局部变量表中
- 每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用,对象都存放在堆区中
- 每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问
栈帧中包括局部变量表 ,操作数栈, 动态链接, 方法出口
也就是本地变量表,就是局部变量表,只是翻译不同.局部变量表的容量以变量槽(Variable Slot)为最小单位, 虚拟机中并没有明确指明一个Slot应占用的内存空间大小,只是很有导向性的说到每个Slot都应该能存放一个八种基本类型的其中一个。不使用的对象,应当手动赋值为null
操作数栈,在方法执行过程中,根据字节码指令,往栈中写入数据或提取数据,即入栈(push) 出栈(pop)。主要用于保存计算过程中的中间结果,同时作为计算过程中变量临时的存储空间
某些字节码指令将值压入操作数栈,其余的字节码指令将操作数取出栈。使用它们后再把结果压入栈。
比如:执行复制、交换、求和等操作。
因为 Java 是在运行期间动态链接的,所以为了支持动态链接,需要将方法区里面的符号引用转为直接引用(即:给出地址),这就叫动态链接,也就是存放方法在方法区运行的一个入口位置的数据
方法执行完的返回地址.当一个方法开始执行时,可能有两种方式退出该方法
一种是正常运行完毕,正常完成出口,退出方法;
另一种是异常完成出口, 方法执行过程中遇到异常,并且这个异常在方法体内部没有得到处理,导致方法退出
永久代
- 方法区(Method Area) 与Java堆一样, 是各个线程共享的内存区域, 它用于存储已被虚拟机加载的类信息, 常量, 静态变量, 即时编译器编译后的代码等数据。 虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分, 但是它却有一个别名叫做Non-Heap非堆, 目的应该是与Java Heap 区分开来
- 在JDK1.7以前HotSpot虚拟机使用永久代来实现方法区,永久代的大小在启动JVM时可以设置一个固定值(-XX:MaxPermSize),不可变
- 在JDK1.7中 存储在永久代的部分数据就已经转移到Java Heap或者Native memory。譬如符号引用(Symbols)转移到了native memory,原本存放在永久代的字符常量池移出。但永久代仍存在于JDK 1.7中,并没有完全移除。
- JDK1.8中移除了永久代(PermGen),替换为元空间(Metaspace)
堆内存

堆这块区域是JVM中最大的,应用的对象和数据都是存在这个区域,这块区域也是线程共享的,也是 gc 主要的回收区,一个 JVM 实例只存在一个堆类存,堆内存的大小是可以调节的。类加载器读取了类文件后,需要把类、方法、常变量放到堆内存中,以方便执行器执行,堆内存分为年轻代和老年代
堆中存储的全部是对象,每个对象都包含一个与之对应的class的信息
jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身
堆大小 = 新生代 + 老年代。其中,堆的大小可以通过参数 –Xms、-Xmx 来指定。
默认的,新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 ),即:新生代 ( Young ) = 1/3 的堆空间大小。老年代 ( Old ) = 2/3 的堆空间大小。其中,新生代 ( Young ) 被细分为 Eden 和 两个 Survivor 区域,这两个 Survivor 区域分别被命名为 from 和 to,以示区分
默认的,Edem : from : to = 8 : 1 : 1 ( 可以通过参数 –XX:SurvivorRatio 来设定 ),即: Eden = 8/10 的新生代空间大小,from = to = 1/10 的新生代空间大小
JVM 每次只会使用 Eden 和其中的一块 Survivor 区域来为对象服务,所以无论什么时候,总是有一块 Survivor 区域是空闲着的。
因此,新生代实际可用的内存空间为 9/10 ( 即90% )的新生代空间。
GC

Java 中的堆也是 GC 收集垃圾的主要区域。GC 分为两种:Minor GC、Full GC ( 或称为 Major GC )
Minor GC 是发生在新生代中的垃圾收集动作,所采用的是复制算法。
新生代几乎是所有 Java 对象出生的地方,即 Java 对象申请的内存以及存放都是在这个地方。Java 中的大部分对象通常不需长久存活,具有朝生夕灭的性质。
当对象在 Eden ( 包括一个 Survivor 区域,这里假设是 from 区域 ) 出生后,在经过一次 Minor GC 后,如果对象还存活,并且能够被另外一块 Survivor 区域所容纳( 上面已经假设为 from 区域,这里应为 to 区域,即 to 区域有足够的内存空间来存储 Eden 和 from 区域中存活的对象 ),则使用复制算法将这些仍然还存活的对象复制到另外一块 Survivor 区域 ( 即 to 区域 ) 中,然后清理所使用过的 Eden 以及 Survivor 区域 ( 即 from 区域 ),并且将这些对象的年龄设置为1,以后对象在 Survivor 区每熬过一次 Minor GC,就将对象的年龄 + 1,当对象的年龄达到某个值时 ( 默认是 15 岁,可以通过参数 -XX:MaxTenuringThreshold 来设定 ),这些对象就会成为老年代。

但也不是一定的,对于一些较大的对象 ( 即需要分配一块较大的连续内存空间 ) 则是直接进入到老年代。虚拟机提供了一个-XX:PretenureSizeThreshold参数,令大于这个设置值的对象直接在老年代分配。这样做的目的是避免在Eden区及两个Survivor区之间发生大量的内存复制,因为新生代采用的是复制算法收集内存
虚拟机并不是永远地要求对象的年龄必须达到了15岁最大阀值才能晋升老年代,如果在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄
Full GC 是发生在老年代的垃圾收集动作,所采用的是“标记-清除”或者“标记-整理”算法。标记-清除算法收集垃圾的时候会产生许多的内存碎片 ( 即不连续的内存空间 ),此后需要为较大的对象分配内存空间时,若无法找到足够的连续的内存空间,就会提前触发一次 GC 的收集动作。
老年代里面的对象几乎个个都是在 Survivor 区域中生存下来的,它们是不会那么容易就 “死掉” 的。因此,Full GC 发生的次数不会有 Minor GC 那么频繁,并且做一次 Full GC 要比进行一次 Minor GC 的时间更长。
GC Roots
堆中几乎存放着Java世界所有的对象实例,垃圾收集器在对堆进行回收前,第一件事情就是要确定这些对象有哪些是“存活”着,哪些已经“死去”。

可达性分析算法
在Java中,是通过可达性分析(Reachability Analysis)来判定对象是否存活的。该算法的基本思路就是通过一些被称为引用链(GC Roots)的对象作为起点,从这些节点开始向下搜索,搜索走过的路径被称为(Reference Chain),当一个对象到GC Roots没有任何引用链相连时(即从GC Roots节点到该节点不可达),则证明该对象是不可用的。
在Java中,可作为GC Root的对象包括以下几种:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(即一般说的Native方法)引用的对象
JDK自带的调优诊断工具:jvisualvm,可以看到所有在运行的JVM中内存的使用情况,可能需要下载工具内的Visual GC插件
STW GC卡顿(stop the world)
在垃圾回收时,都会产生应用程序的停顿,停顿产生时,整个应用程序会被卡死,没有任何响应, 是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起(除了垃圾收集帮助器之外)。Java中一种全局暂停现象,全局停顿,所有Java代码停止,native代码可以执行,但不能与JVM交互;这些现象多半是由于GC引起。
为什么要设置STW?
如果,在GC的过程中不设置STW, GC时GC roots搜索完一系列的非垃圾对象后,会再去找其他的非垃圾对象,但是如果没有STW的话,一些用户线程会继续执行,线程执行结束后,内存空间全部都会被释放掉,释放掉全部的内存,表示之GC Roots的引用就没了,那一系列的对象也不会被继续引用了,之前不是垃圾的对象又变成了垃圾对象,那么在GC的过程中,一些对象,那么这次GC可能很难结束,所以会设置一个STW,使所有的应用线程停止,在做GC时让这些对象的状态不会发生变化,准确地进行垃圾收集.
程序计数器
程序计数器是每个线程专有的.只要java虚拟机开始运行,java虚拟机就会给当前的线程分配一个专属的内存空间,也就是程序计数器的空间,用来记录当前线程运行的一个位置,也可以说当前运行到的一个行号.
此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
为什么要设置程序计数器?
因为java是多线程的,如果当前线程正在运行,又来了一个优先级更高的线程,把CPU抢占过去,之前的线程就会先挂起,把CPU让出来,会先执行优先级更高的,那么优先级更高的执行完之后,继续运行之前的那个挂起的线程,程序计数器会记录那个位置,会从那个位置继续执行.程序计数器的值都是由字节码执行引擎完成修改的
本地方法栈
调用系统的一些方法,使用native修饰的方法.
本地方法栈和虚拟机栈发挥的作用十分相似。同样是线程私有,它们之间的区别不过是虚拟机栈为Java 方法服务,而本地方法栈为虚拟机使用到的Native 方法服务。
参考文献:
《深入理解Java虚拟机》-周志明
《Java虚拟机规范》 -John Clellon Holmes















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









