







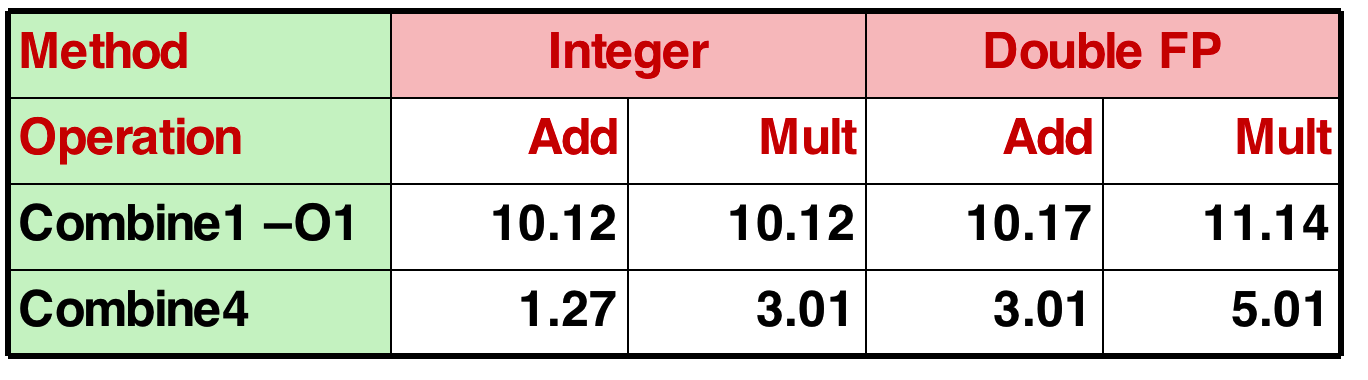
Exploiting Instruction-level Parallelism
- Need general understanding of modern processor design
- Hardware can execute multiple instructions in parallel
- Performance limited by data dependencies
- Simple transformations can yield dramatic performance improvement
- Compilers often cannot make these transformations
- Lack of associativity and distributivity in floating-point arithmetic
Cycles Per Element (CPE)
- Convenient way to express performance of program that operates on vectors or lists
- Length = n
- In our case: CPE = cycles per OP
- T = CPE*n + Overhead
- CPE is slope of line
Basic Optimizations
void combine4(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
data_t *d = get_vec_start(v);
data_t t = IDENT;
for (i = 0; i < length; i++)
t = t OP d[i];
*dest = t;
}
- Move vec_length out of loop
- Avoid bounds check on each cycle
- Accumulate in temporary
就是要把vec_length(v)移动到循环外并用临时的变量来存储其值,这样每次在每次循环检查边间条件时不需要对vec_length(v)进行计算。
虽然程序是按顺序写的,是一个linear sequence of instruction,但是可以拆分成不同的部分,某些部分相互依赖,有些部分相互独立,所以可以跳过前面的部分执行后面的→指令级并行instructuon level parallelism.
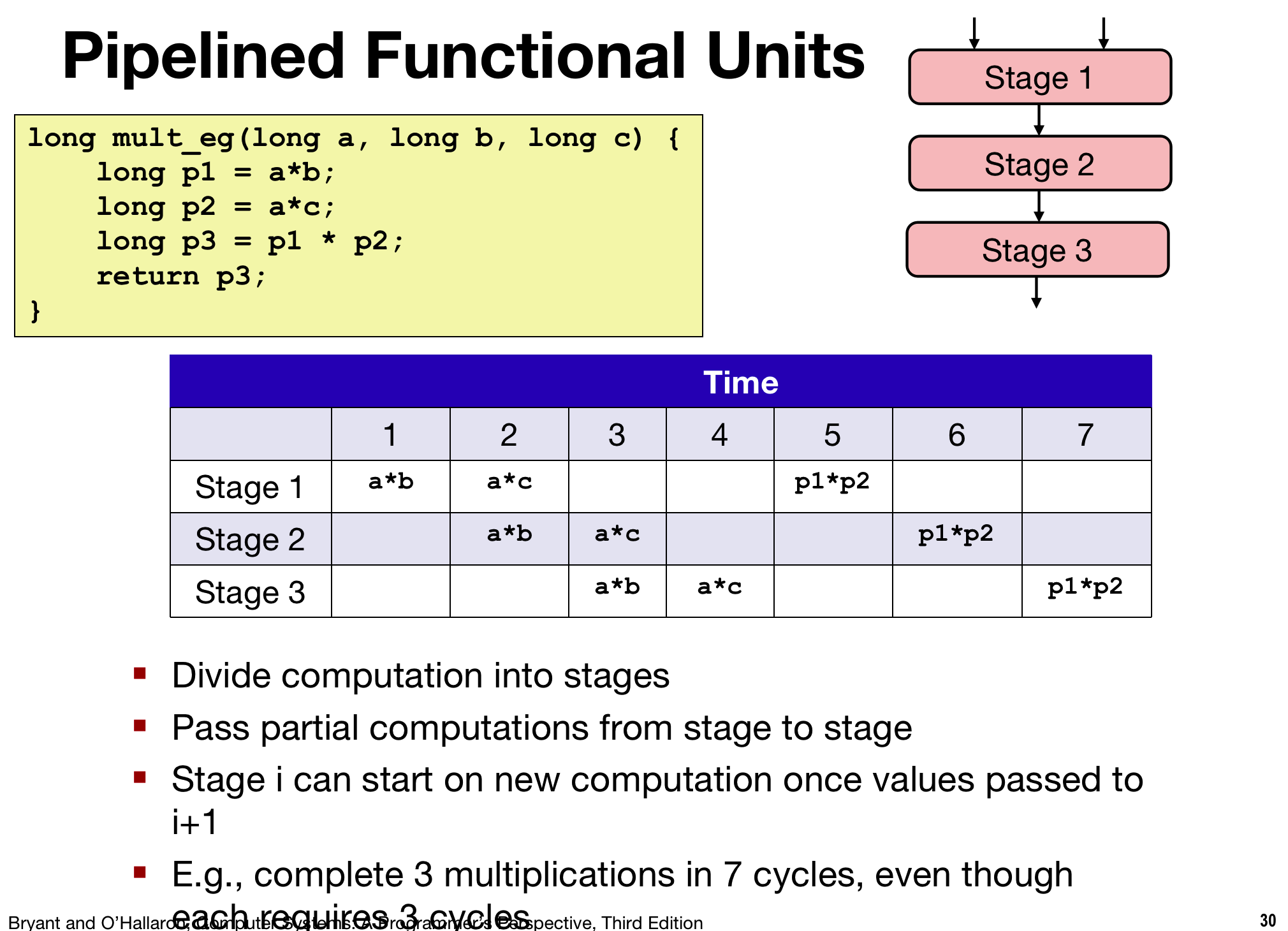
- Break multiplication up into smaller steps that they can be done one after another,
- and we have a sperate dedicated hardware for each of those stages.
- do pipelining 当一个操作从一个stage1移动到下一个stage2, 后面的操作就可以填入 stage2
如上图,把一个乘法运算分为三个部分, a*b a*c是 相互独立的,time1a*b 完成计算的第一部分,Time2进入stage2,并且在Time2中stage1 available, 所以在Time2可以进行 a*c的运算
但是p1*p2是需要在a*b a*c完成后进行,所以对于原来的乘法需要 3*3 现在只需要7个time就可以完成

-
Latency(延迟)只从开始执行一个instruction到结束所花费的cycle, cycles/issue是指由于流水线的操作,两个operation之间的距离
-
division操作没有pipeline.
Loop Unrolling
Rather than executing one value within a loop, we execute a multiple ones
The original one:

1.

- 同时计算两个 i+=2

- i+=2,只有加法的时间得到了缩短
2.

结果:

原因:
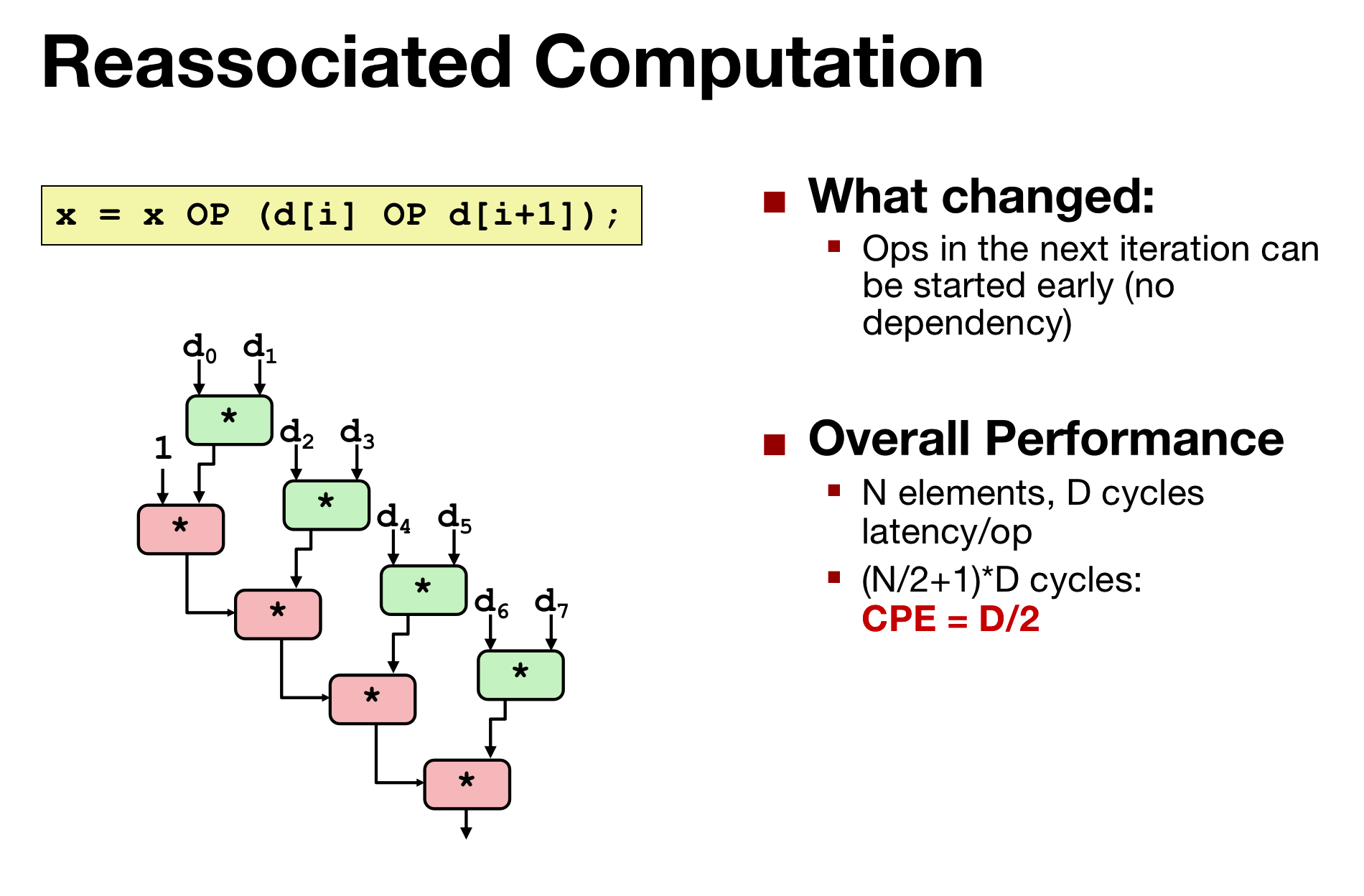
- 前面那种需要计算出前半部分的结果才能接着计算,后面这种是并行的,读取数据可以并行
- 注意:这里是整数运算,如果是floating point的运算可能会出现:
- rounding
- potential overflow
3. Loop Unrolling with Separate Accumulators (2x2)
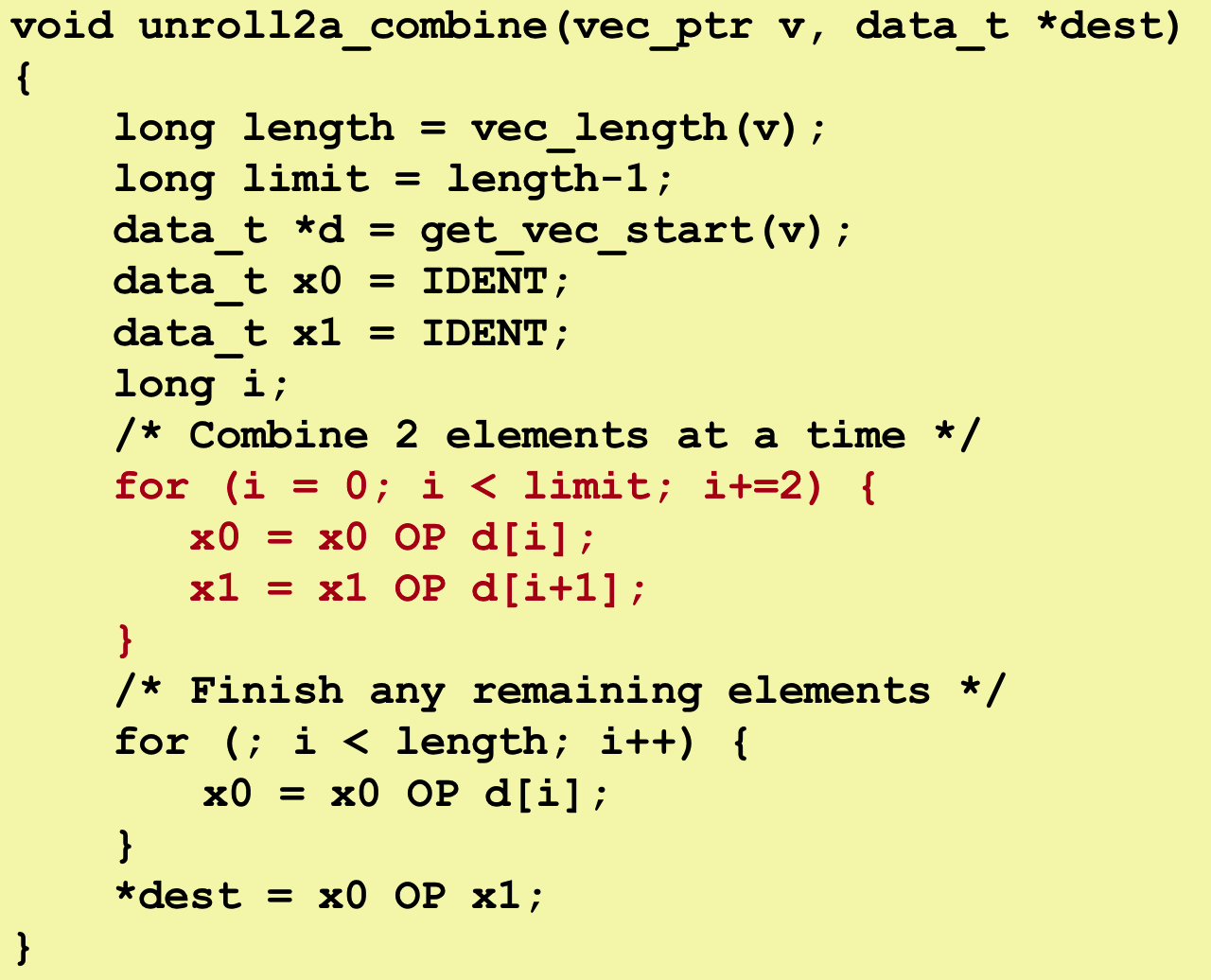
Get more parallelism going Multiple Accumulator
We have odd-numbered elements and even-numbered elements in tha array,→ we can compute sperate sum or products of these two sets of elements → the very end combine them together
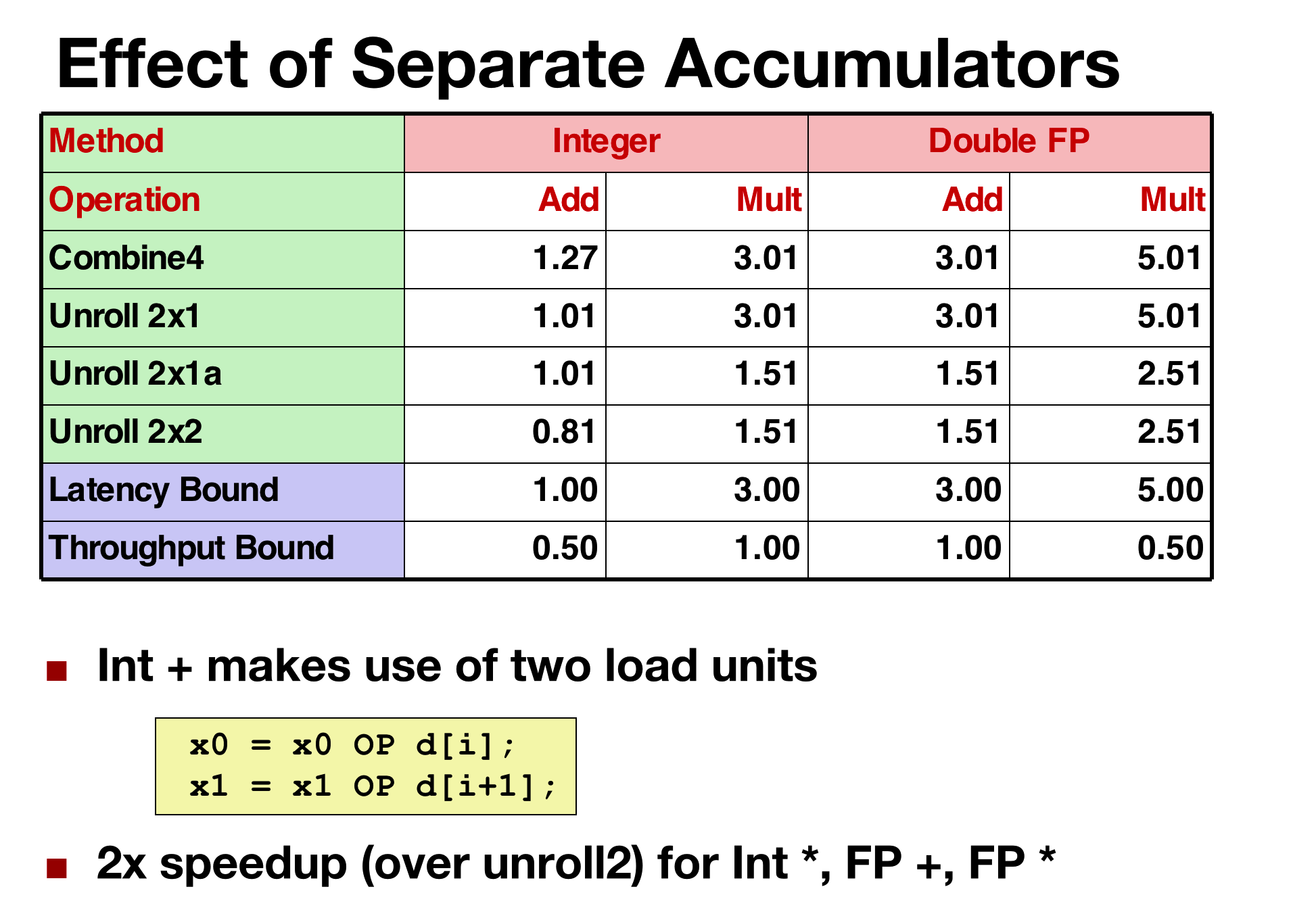
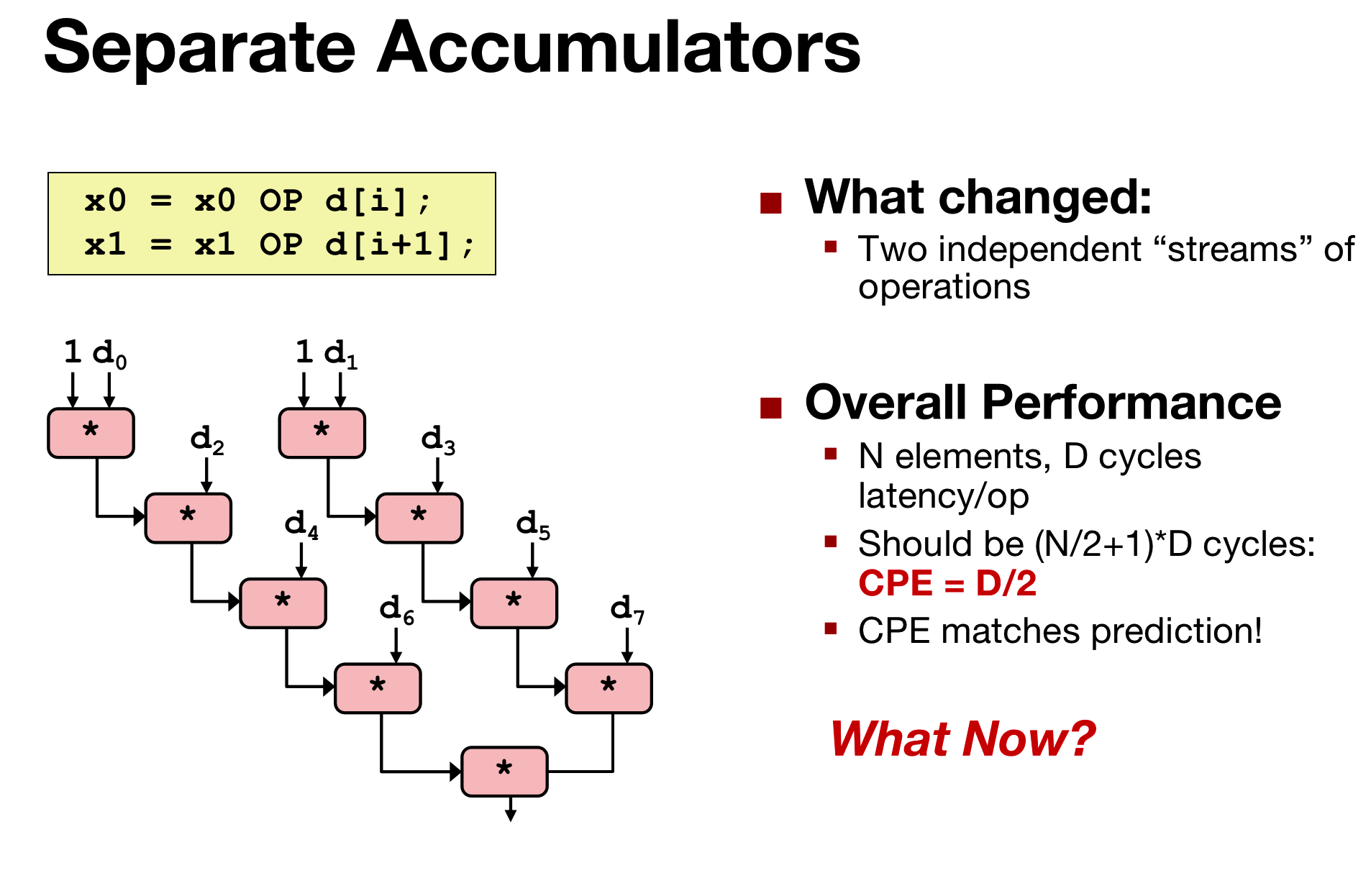
Unrolling & Accumulating

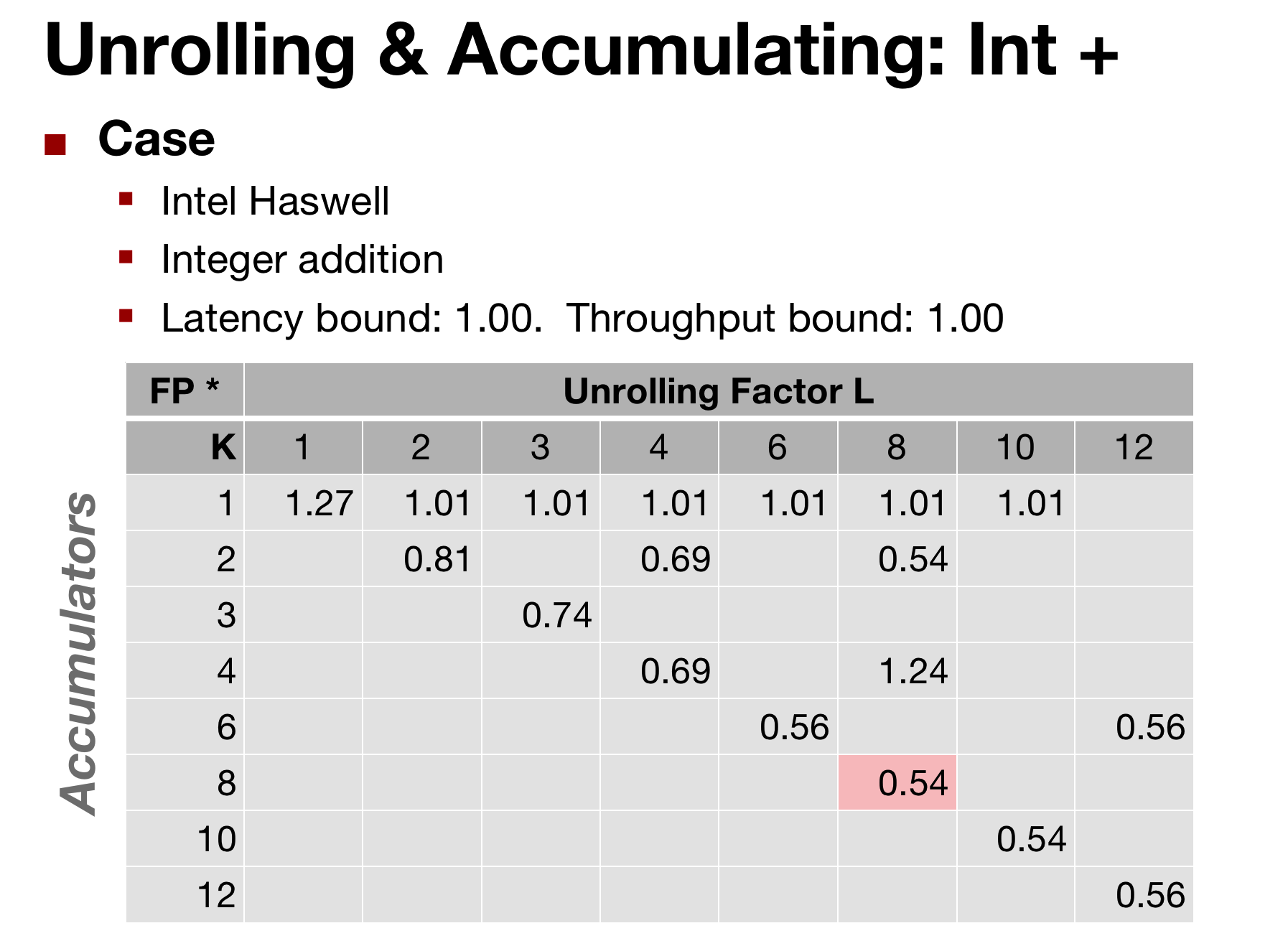
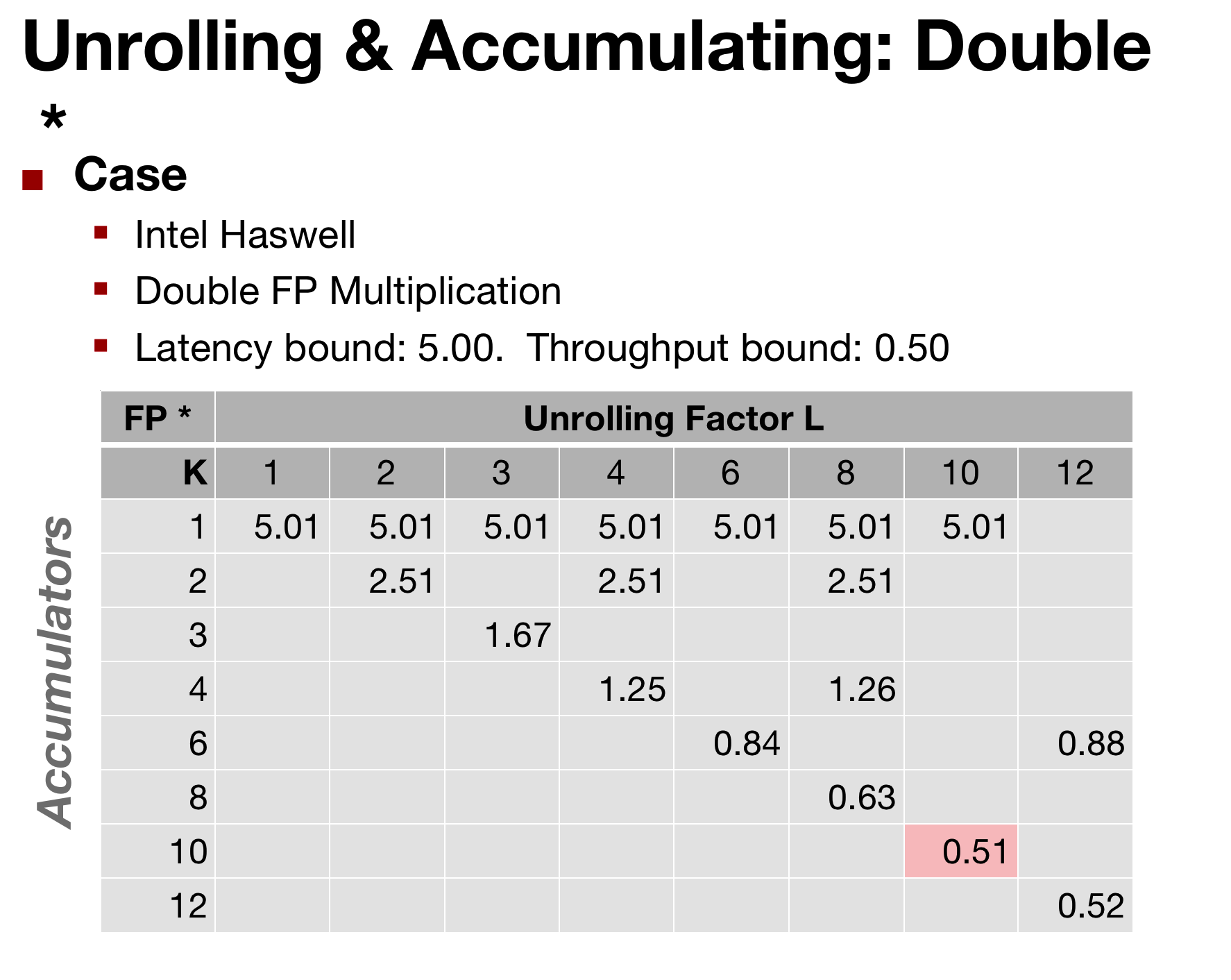
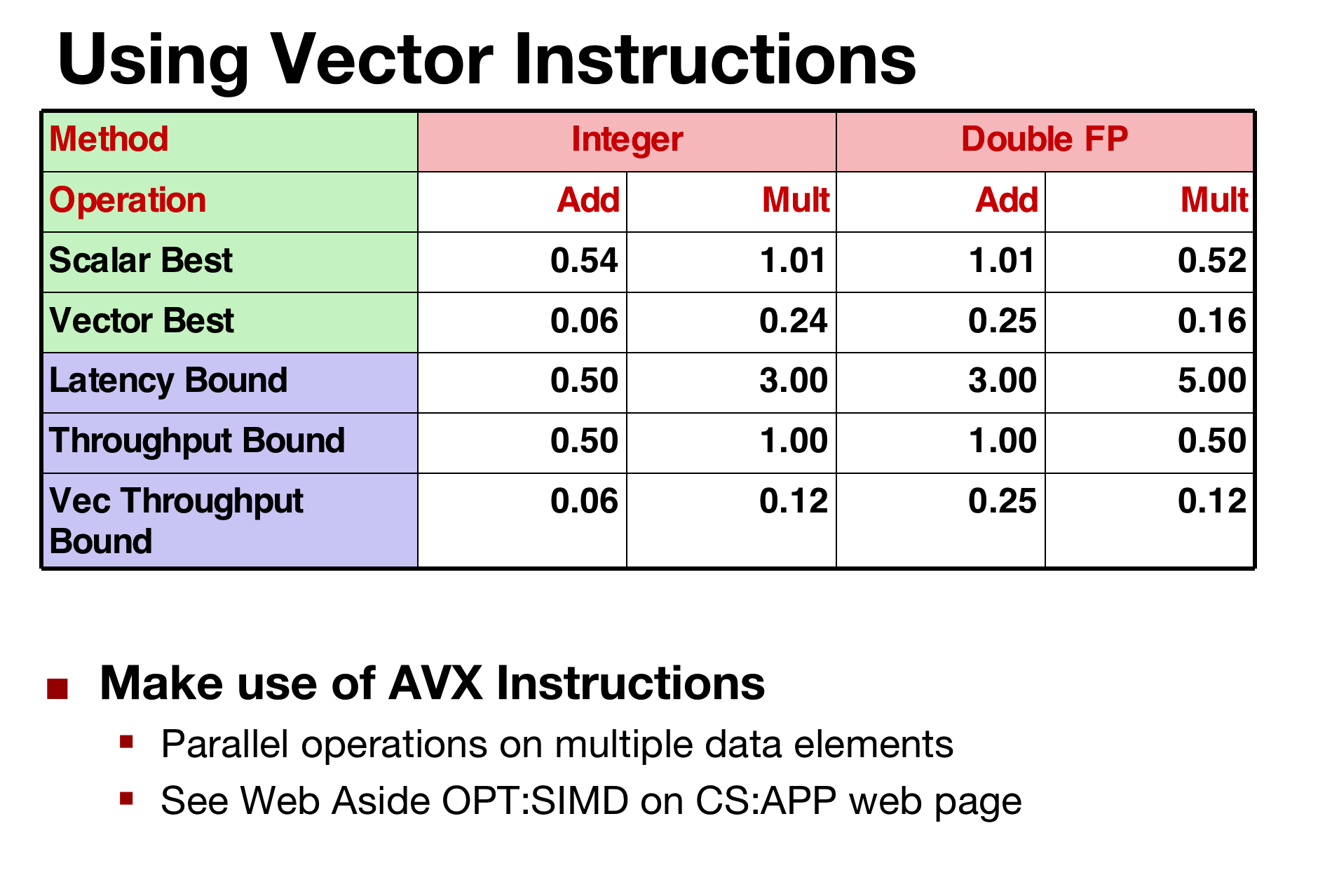
By sorting of picking the best parameters, we can get very close to the throughput bound of the processor.
the original CPE was 20 clock cycles and 10 -> now: 1 and 0.5

- Limited only by throughput of functional units
- Up to 42X improvement over original, unoptimized code
本质是利用流水线,流水线本质是cpu太块,你不管从哪读取都跟不上cpu计算速度,当然在寄存器内存扩大,相当于缓存,减少时间,使流水线尽可能多的被利用
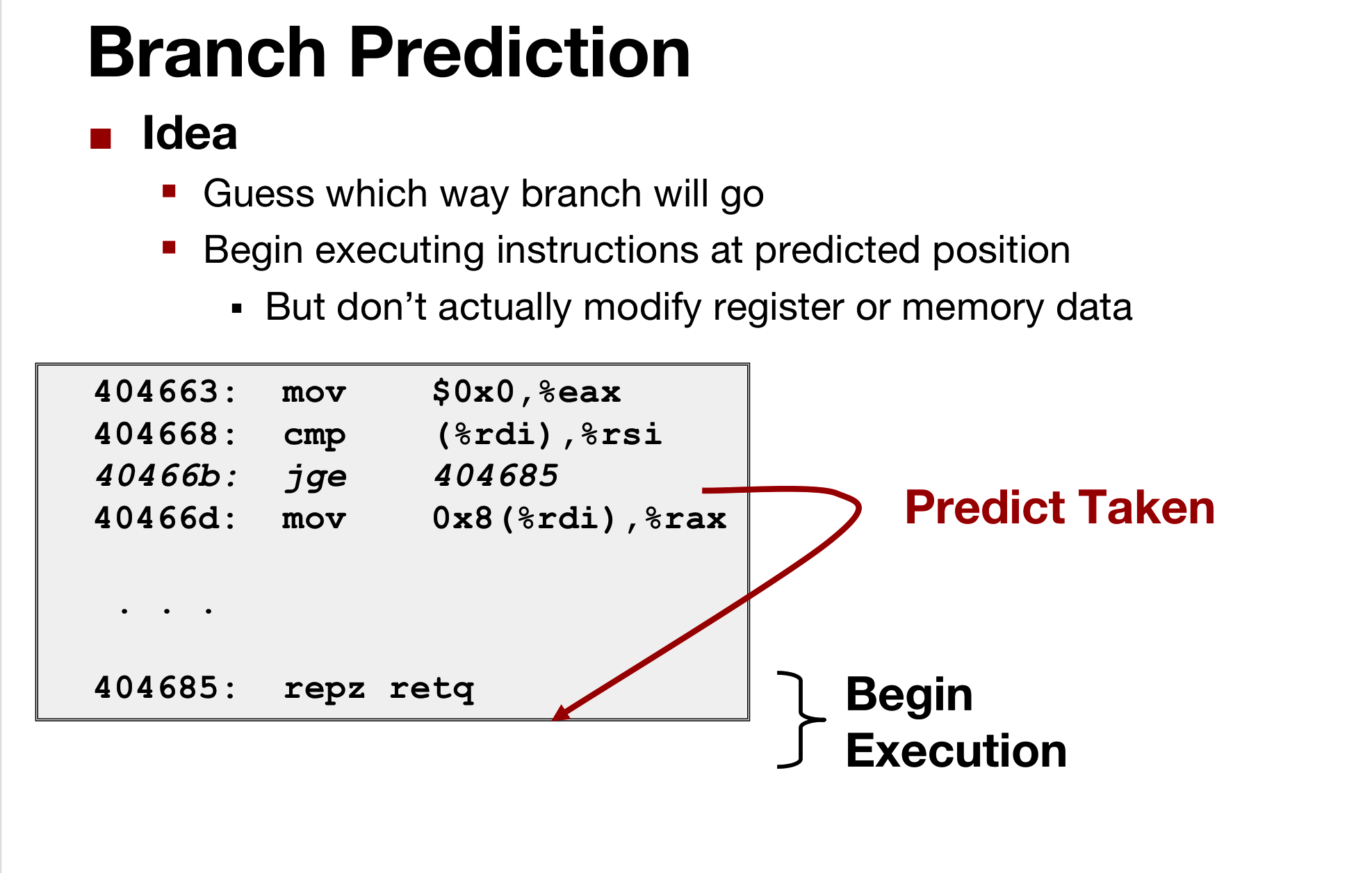
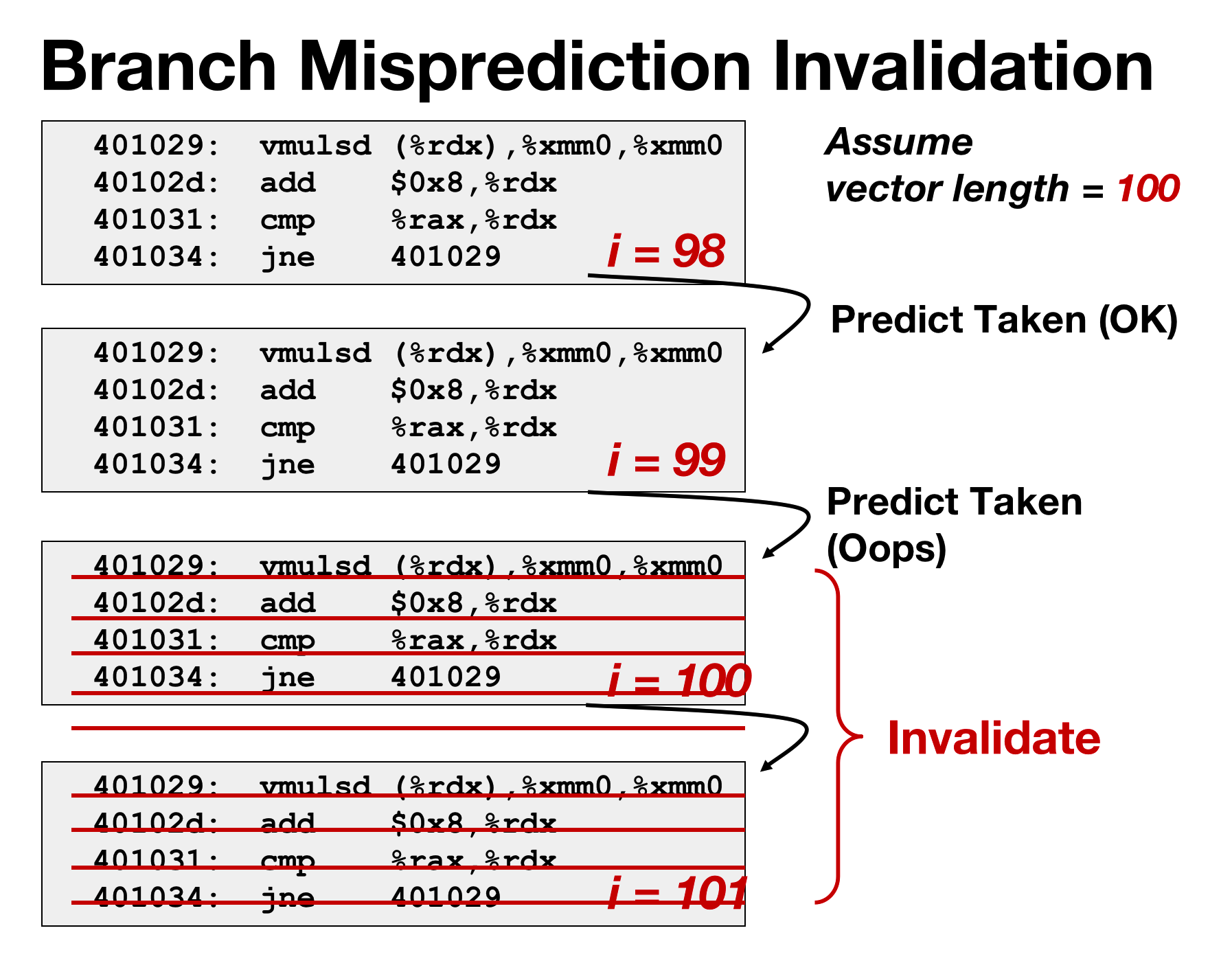
These instructions only modify registers. And also it has multiple copies of registers, and these are sort of speculative values appending updates to them.(to registers, so the correct speculative values position ahead of the wrong ones)
→ so when it comes time to cancel it, it just cancels out all those pending updates.
寄存器重命名块: In cpu, there is a big block called the register renaming unit ,which is, multiple copies of all the registers as they get accumulated. And there are several hundred reg copies( virtual registers ) to keep pending copies to actual registers.















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









