









Requests库入门
Requests库安装
http://www.python-requests.org
安装方法,以管理员身份打开cmd,在cmd中输入如下命令:
pip install requests
requests库的7个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP中的get |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP中的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
Requests库的个体()方法
r=requests.get(url)
1.构造一个向服务器请求资源的Request对象
2.返回一个包含服务器资源的Response对象
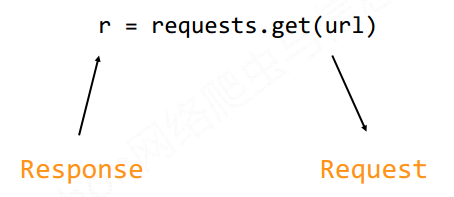
Response对象包含爬虫返回的内容
requests.get()函数完整使用
requests.get(url, params=None, **kwargs)
#url:拟获取页面的url链接
#params:url中的额外参数,字典或字节流格式,可选
#**kwargs:12个控制访问的参数
Response对象的属性
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP相应内容的字符串形式,即url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式 |
| r.content | HTTP响应内容的二进制形式 |
访问流程

Response的编码
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
|---|---|
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
r.encoding:如果header中不存在charset,则认为编码为ISO‐8859‐1
r.text根据r.encoding显示网页内容
r.apparent_encoding:根据网页内容分析出的编码方式,可以看作是r.encoding的备选
爬取网页的通用代码框架
网络连接有风险,异常处理很重要
Requests库的异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequire | URL缺失 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求url超时,产生超时异常 |
Response的异常
| r.raise_for_status() | 如果不是200,产生异常 requests.HttpError |
|---|
r.raise_for_status()在方法内部判断r.status_code是否等于200,不需要增加额外的if语句,该语句便于利用try‐except进行异常处理
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r=requests.get(url, timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
网络爬虫的盗亦有道
网络爬虫的尺寸
| 规模 | 库 |
|---|---|
| 小规模,数据量小 | Requests库 |
| 中规模,数据规模较大 | Scrapy库 |
| 大规模,搜索引擎 | 定制开发 |
Robots协议
作用:网站告知网络爬虫哪些页面可以抓取,哪些不行
形式:在网站根目录下的robots.txt
网络爬虫:自动或人工识别robots.txt,再进行内容爬取
约束性:Robots协议是建议但非约束性,网络爬虫可以不遵循,但存在法律风险
Requests库爬取实例
实例1:京东商品页面的爬取
链接:https://item.jd.com/100009177400.html
import requests
url="https://item.jd.com/100009177400.html"
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
实例2:亚马逊商品页面的爬取
链接:https://www.amazon.cn/dp/B0785D5L1H/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&keywords=%E6%9E%81%E7%AE%80&qid=1581779862&sr=8-1
import requests
url="https://www.amazon.cn/dp/B0785D5L1H/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&keywords=%E6%9E%81%E7%AE%80&qid=1581779862&sr=8-1"
kv={'user-agent':'Mozilla/5.0'}
try:
r=requests.get(url, headers=kv)
# print(r.status_code)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.request.headers)
print(r.text[:1000])
except:
print("爬取失败")
实例3:百度/360搜搜关键词提交
百度的关键词接口:http://www.baidu.com/s?wd=keyword
360的关键词接口:http://www.so.com/s?q=keyword
import requests
keyword="Python"
url="http://www.baidu.com/s"
try:
kv = {'wd': keyword}
r=requests.get(url, params=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
# print(r.request.url)
print(len(r.text))
except:
print("爬取失败")
实例4:网络图片的爬取
网络图片链接格式:http://www.example.com/picture.jpg
eg.从国家地理网站中选择图片,链接如下
http://image.ngchina.com.cn/userpic/3925/2019/071013374839255121.jpeg
import requests
import os
root="E:/000/FIVE/top5python/catch-doc/temp-pic/"
url="http://image.ngchina.com.cn/userpic/3925/2019/071013374839255121.jpeg"
path=root+url.split("/")[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path, "wb") as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
实例5:IP地址归属地的自动查询
网站:http://m.ip138.com/ip.asp?ip=ipaddress
import requests
url="http://m.ip138.com/ip.asp?ip="
try:
r=requests.get(url+"202.204.80.112")
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









