







1. 实验数据
根据美国疾病控制预防中心的数据,现在美国1/7的成年人患有糖尿病。但是到2050年,这个比例将会快速增长至高达1/3。在UCL机器学习数据库里一个糖尿病数据集,通过这一数据集,建立一个数据分析模型实现对病人是否患病进行预测。
数据地址:https://github.com/susanli2016/Machine-Learning-with-Python/blob/master/diabetes.csv
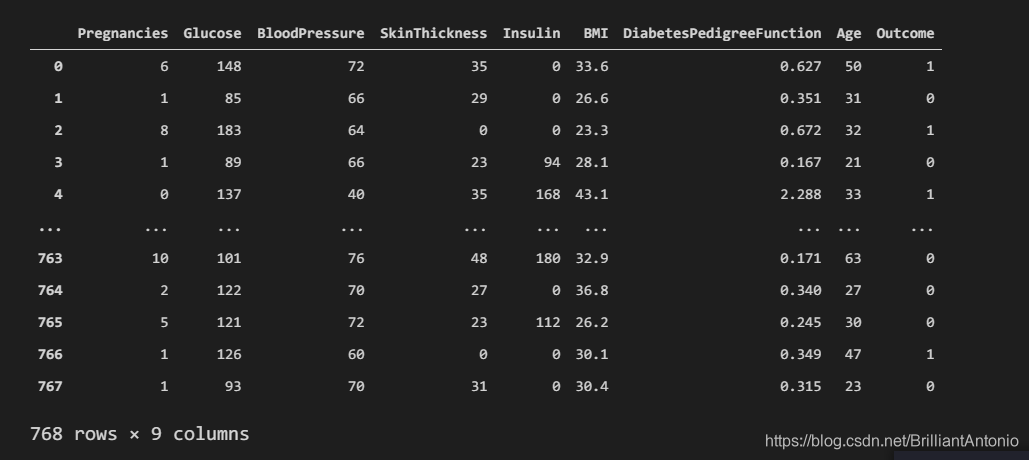
数据集位768 × \times × 9的矩阵,其中前8列为数据特征(怀孕次数,血糖,血压,皮脂厚度,胰岛素,BMI身体质量指数,糖尿病遗传函数,年龄),最后一列为标签(结果),0意味着未患糖尿病,1意味着患有糖尿病。在768个样本钟,500个被标记为0,268个标记为1。数据可视化如下:
2. 实验展示
在本次实验中,我们打算比较多种经典机器学习模型。为方便比较,我们首先搭建统一的机器学习框架,建立统一的评价指标。下面我们将逐一介绍。
2.1 实验环境
本次实验我们将用到下个库(函数):
import numpy as np
import pandas as pd
from imblearn.over_sampling import SMOTE
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.metrics import precision_score, recall_score, roc_auc_score, average_precision_score, f1_score
2.2 加载数据
我们首先读入整个数据集,通过上述可是化结果我们可以观察到数据中共有8个属性,:
具体实现代码如下:
def LoadData():
rawDataset = pd.read_csv('diabetes.txt')
return rawDataset
我们统计算出数据的多种统计值来观察数据的分布,结果如下:
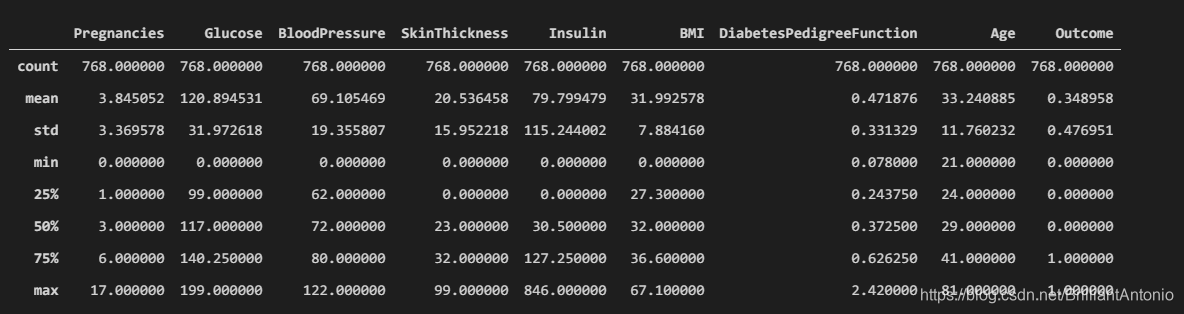
我们可以发现:
- 数据中不存在缺失值
- 数据的各个属性值均大于零,且均为连续值
- 数据的各个属性分布较为不均衡,体现为不同属性的均值和标准差相差较大
- 通过观察数据的同一个属性下的均值和方差,我们任务部分数据存在异常值
- 样本正负比例不均衡,多数样本为负样本
因此,我们需要对数据进行预处理。
2.3 异常点去除
我们首先考虑 3 σ 3\sigma 3σ准则来去除异常点:
3 σ 3\sigma 3σ准则
借助正态分布的优良性质, 3 σ 3\sigma 3σ准则常用来判定数据是否异常。由于正态分布关于均值 μ \mu μ对称,数值分布在 ( μ − σ , μ + σ ) (μ-\sigma,μ+\sigma) (μ−σ,μ+σ)中的概率为0.6827,数值分布在 ( μ − 3 σ , μ + 3 σ ) (μ-3\sigma,μ+3\sigma) (μ−3σ,μ+3σ)中的概率为0.9973。也就是说只有0.3%的数据会落在均值的 ± 3 σ ±3\sigma ±3σ之外,这是一个小概率事件,如下图所示:
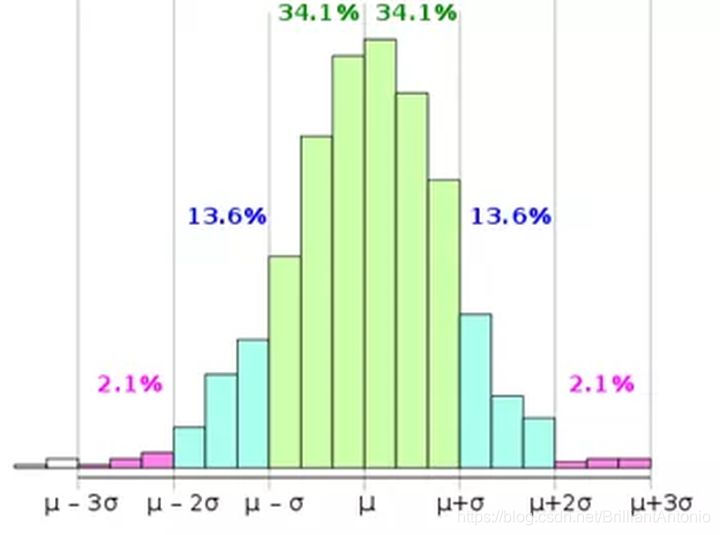
但是正态分布的参数 μ \mu μ和 σ \sigma σ极易受到个别异常值的影响,从而影响判定的有效性。因此又产生了Tukey箱型图法。
IQR准则
上图中IQR,即四分位间距 Q 3 − Q 1 Q3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2132
2132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









