








这是CVPR19 paper reading精读任务中的第一篇,Oral Presentation, Best Paper Final List, Top 1%,反正很屌就对了,其实是从他们团队之前AAAI19的一篇文章进化而来的,为了精读这篇CVPR,我读了他们的AAAI19,顺便再go deep读了关于知识蒸馏(knowledge distillation)的三篇稍微古老一点的paper。
NIPS14: Do Deep Nets Really Need to be Deep?
模型压缩
知识蒸馏的学术源头大家都说来自于这篇文章,其实更早的源头是06年SIGKDD的Model Compression,模型压缩的核心思想是用有label的数据来训练一个大而且准确的model,然后用没有label的数据经过这个model生成score作为数据的伪label,即合成label,然后用这些label去指导小的mimic model来学习。
小的mimic model并不是用original的label来训练出来的,而是被训练用于学习大model学习到的函数,说起来有点绕,其实就是大model学习original label,小model学习大model,相当于大的model是小的model的老师,因此这种方式又被称为teacher-student modeling。模型压缩证明了一个问题,那就是小model无法直接学习到的东西,可以通过大model来学习,然后指导小model进行学习,往往会达到和大的model近似、比直接用original label更好的效果。
换言之,复杂的模型学习到的函数,并没有想像中那么复杂,以至于简单模型无法学习。
深度网络 vs. 浅层网络
NIPS14这篇文章的核心观点在于,现有的很多研究都证明了,深层网络能够比浅层网络达到更高的准确率,那么这个准确率增益得益于深层网络的什么特征呢?是更多的参数,深层网络的层次化结构,还是现有的优化算法和正则更适用于深层网络呢?文章通过实验证明了,浅层的网络可以学习到深层网络能够学到的一样复杂的函数,并且获得近似的accuracy,从而说明了浅层网络相比于深层网络的问题并不在与capacity和表征能力,而是在于训练和正则的方法。
文章的做法是这样的,在语音分类数据集TIMIT和图像分类数据集CIFAR-10上,用深度网络训练一个高准确率的分类器,使用正常的softmax分类输出p_k = e^{z_{k}}/\sum_j e^{z_j}pk=ezk/∑jezj和cross-entropy损失函数。
在此之后,就是训练浅层网络了,浅层的mimic model训练的时候使用的不是softmax而是logits,也就是深层网络的输出在送入softmax之前的内容z_kzk,这种方式的好处在于两点:
-
如果使用概率值也就是softmax的输出,那么如果teacher输出[2\times 10^{-9}, 4\times 10^{-5},0.9999][2×10−9,4×10−5,0.9999],那么student模型在学习的时候会忽略前两项,因为它们太小了,但实际上如果关注logits的话,可以看到[10,20,30],其实差别不大,说明这个input还是对前两类有一定的倾向性的,student学习这种label,会更利于学习teacher模型的表征;
-
传统的分类问题,模型的目标是将输入的特征映射到输出空间给定的某些点中的一个,换言之,就是要将所有的输入图像映射到输出空间的N个点上,例如在著名的Imagenet比赛中,就是要将所有可能的输入图片映射到输出空间的1000个点上。这么做的话这1000个点中的每一个点是一个one hot编码的类别信息。这样一个label能提供的监督信息只有log(class)这么多bit。然而在KD中,我们可以使用teacher model对于每个样本输出一个连续的label分布,这样可以利用的监督信息就远比one hot的多了。另外一个角度的理解,大家可以想象如果只有label这样的一个目标的话,那么这个模型的目标就是把训练样本中每一类的样本强制映射到同一个点上,这样其实对于训练很有帮助的类内variance和类间distance就损失掉了。然而使用teacher model的输出可以恢复出这方面的信息。具体的举例就像是paper中讲的, 猫和狗的距离比猫和桌子要近,同时如果一个动物确实长得像猫又像狗,那么它是可以给两类都提供监督。综上所述,KD的核心思想在于”打散”原来压缩到了一个点的监督信息,让student模型的输出尽量match teacher模型的输出分布。其实要达到这个目标其实不一定使用teacher model,在数据标注或者采集的时候本身保留的不确定信息也可以帮助模型的训练。
小结一下就是,将原本hard的分类label变成soft的话,能够提供样本更加丰富的特征信息,有助于model去理解样本的更深入的、更加独特的特征,也就是所谓的类内difference。
可以看一下在TIMIT上的实验结果的对比,TIMIT上的实验是用将original label直接遗弃替换成teacher model给的label做的,后面的CIFAR-10则是引入了额外的unlabeled data:
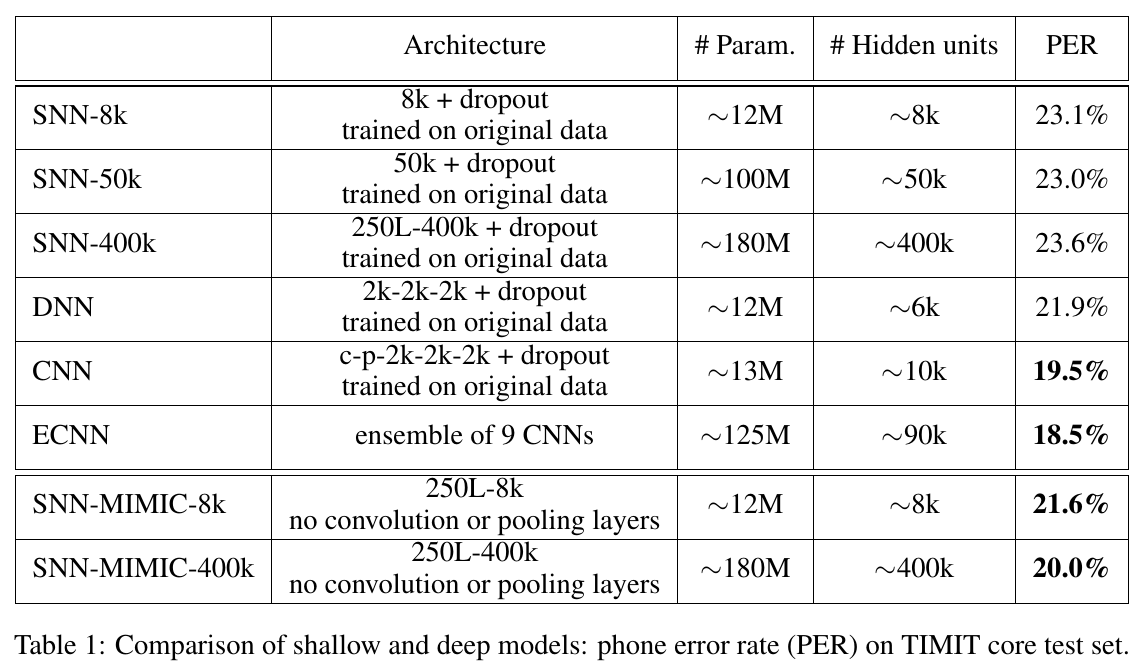
可以看出,使用了teacher model的label做训练的时候,会比使用hard label训练的准确率更高,这就证明了teacher model的有效性,如果在训练的时候,保留一定的不确定信息(这个往往人类是很难给出的),会更有助于训练。
小结:
shallow model如果想要达到好的效果,肯定要变得wide,但同时,就会带来优化上的难度和overfit的风险,可以从下图看出,当参数量变大的时候,使用hard的label会导致效果下降。
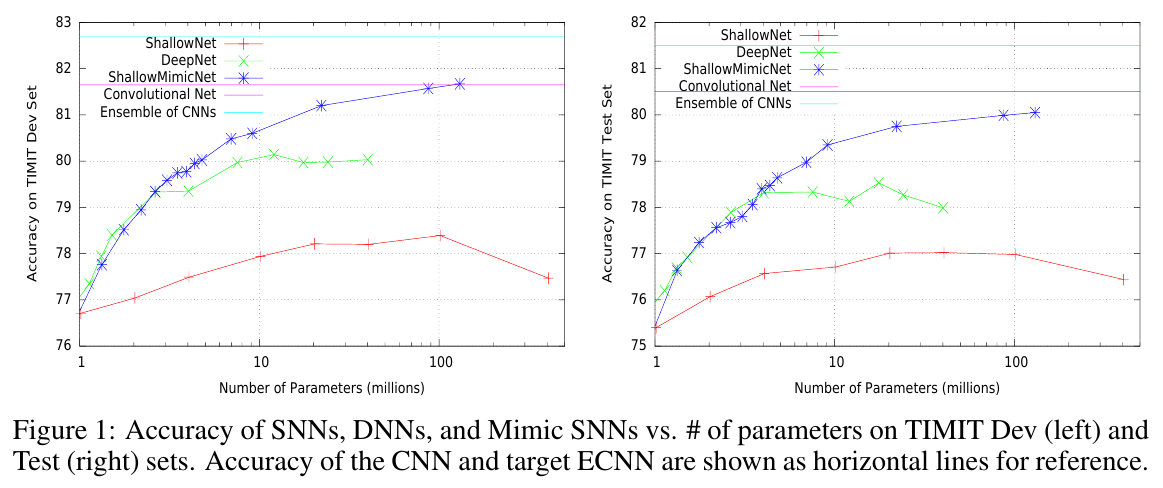
Mimic model可以防止过拟合
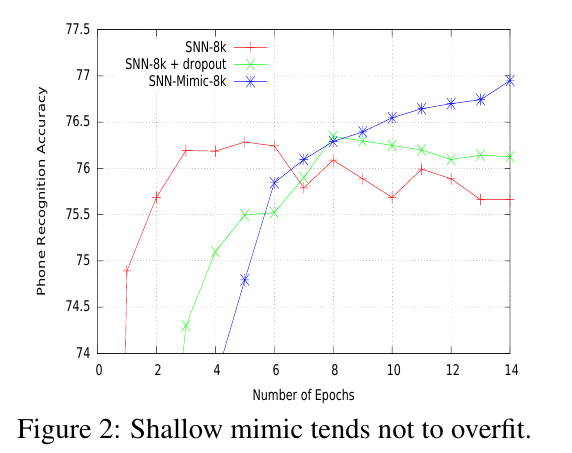
teacher-student模型给训练的target一个soft的label,实质上是给出了一个从input直接(通过深层模型)得到的target,增加了label赋予样本的信息量,放宽了output的空间,相当于某种形式的正则化,因此从下图可以看出,过拟合被有效地防止了:
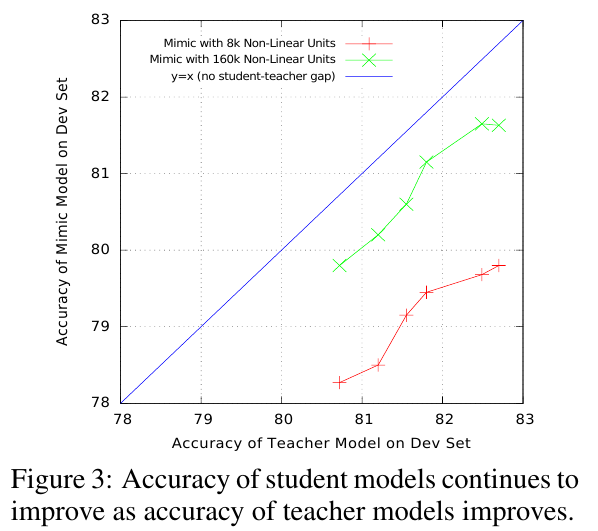
另外,从下图可以看出,浅层模型并不像13年Big neural networks waste capacity说的那样,表达能力不行,它与深层模型相比,是训练和正则化的算法限制了它的performance:
小结
浅层模型在并行计算大行其道的当下,是一种适用于商业产品的好模型,但是它的各种问题也很显然,那就是在参数量大的时候难以训练,因为矩阵乘法的维度太高,往往得不到好的结果。本文证明了在使用模型压缩技术,也就是teacher-student模型的情况下,能够将浅层模型训练得很好,只要给一个足够准确的老师或者足够多的unlabeled data。这项发现在实际应用中是很有前途的。
同时也给我们提供了一个关于软标签的好处:能够表达类内相异性和类间的相似性。
SIGKDD06: Model Compression
既然NIPS14的这篇文章是基于model compression,后面要读的那篇Hinton老爷子的文章,也就是最早提出知识蒸馏的文章,也是基于这篇KDD的,那就先把这篇文章读一下吧,逐本溯源嘛,而且这篇文章的二作Rich Caruana正是NIPS14的二作。
Model compression
所谓的model compression,主要是考虑到了一个问题,基本上最好的有监督学习模型都是很多基础模型的ensemble,ensemble的方法多种多样, 比如bagging, boosting, random forests等等,但是它们带来高准确率的同时也带来了巨大的计算和内存消耗,如果能够“压缩”模型,使得模型在不怎么损失准确率的情况下能够降低计算和内存消耗,岂不美哉?
文章提出的方案:ensemble网络是用一个相对而言不太大的有label数据集训练得到的,而我们希望用一个单一更加轻量的ANN(那时候deep learning还不怎么火热呢)来得到接近的效果,那么用大量的无label数据送入训练好的ensemble网络,用它来生成伪label,然后让ANN去学习这个伪label,进而达到接近ensemble的效果。
为什么可以这样做?我个人认为,主要是简单的ANN要么太简单,表达能力不够,要么就是表达能力够但是没有合适的训练或者监督来使它学好,因此一个teacher模型就显得至关重要了,复杂网络学习到的表征,不一定是简单网络无法学习的,这也是NIPS14的观点之一。
优势:
- 能够用轻量级的网络去得到高准确率的模型,减少了开销;
- 由于大量的无label数据的引入,训练出来的网络能够有效地防止overfit;
数据生成
从上面的分析可以看出,model compression的重点在于两个,一个是好的ensemble网络,一个是大量没有label的数据,前者提供一个好的label生成模型,后者则提供大量的训练数据。文章提到,某些域的数据是很好获取的,例如text、web、image等,但是有些域的数据可能并不一定好获取,它们的不同属性数据可能比较难从真实数据中获取,那么文章就提出了一个非参数的生成合成数据的方法MUNGE,也提出了两个含参的生成方法RANDOM和NBE,RANDOM是从各个拟合的边缘分布中采样,NBE则是用朴素贝叶斯估计来估计联合分布,而MUNGE作为一个非参方法,是用最近邻样本属性交换或者重采样的方法获取样本的,具体方法就不再赘述。
给出三个结果图就可以看出这篇文章思路的价值所在了:
第一个是RMSE和训练数据的关系,有label的训练数据只有4k,所以横坐标从4k开始:
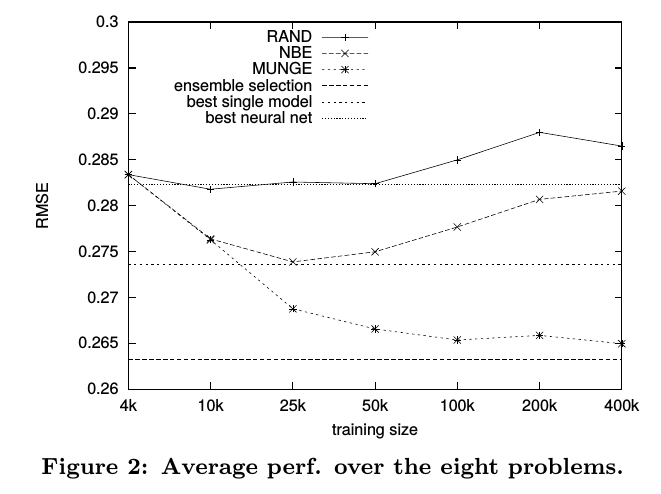
从上述结果可以看出MUNGE是三个生成方法中最好的,而且通过这种model compression的方式,确实能够达到用轻量级模型去接近ensemble模型效果的目的。
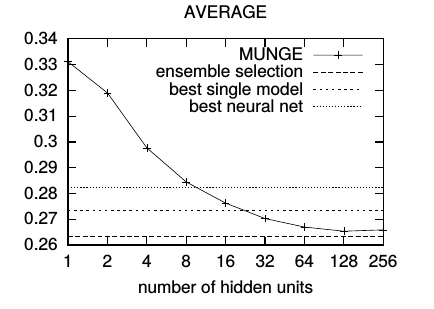
第二个是轻量级模型的hidden units个数和RMSE的关系,表现了当轻量级网络的参数量增多时,用model compression方法能够得到越来越好的效果。
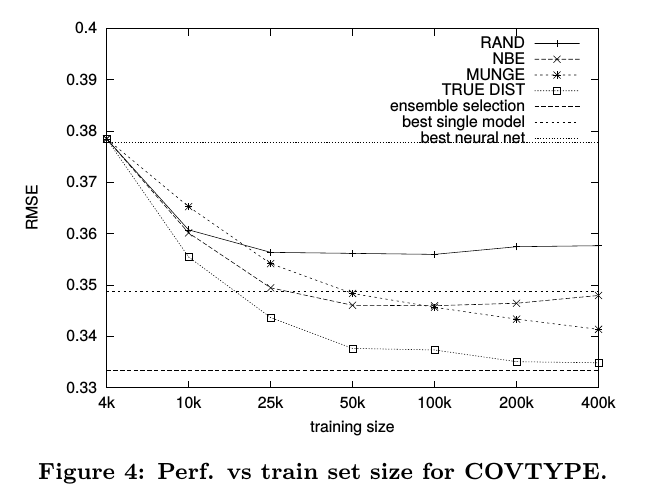
第三个则是表现数据合成方法的,表明数据合成还是不如真实的unlabeled data(废话):
小结
这篇文章可以说很有意思,它针对当时ensemble大行其道的情况做了一个很有远见的思考,那就是,ensemble固然可以增强效果,但是却给模型带来了大量的复杂度,导致模型的开销太大,但使用轻量级的网络又训练不出那么好的效果,要么是数据量不够,要么是表达能力不够,咋整呢?Model compression就一定程度上解决了这个问题。
这个方案也引领我反思了一下目前的SISR方法,大多数的网络方法都喜欢学习完之后用个ensemble,如果SISR需要好的效果同时也需要低开销的话,用一用model compression也就是后来的知识蒸馏,未尝不是个好的方案。
同时呢,文章也向我们展示了一个问题,那就是,轻量级的网络并不是表达能力不够,而是没有用足够的数据和合适的方案去调教它,14年这篇文章提到一个观点,放在这里也适用,那就是正常的label都是人工标注的,和数据是没有一个显式的直接的函数关系的,而从复杂模型输出的伪label是从一个显式的函数输出出来的,轻量级的网络尽管是轻量的,但是它也能够更好地学习这种拥有显示输入输出关系的函数。我们以前都认为轻量级网络学不到东西是它太weak,然而实际上不是小兵底子差,而是长官没教好hhhhh
另外,NIPS14在此文上的改进就是,将单纯地用高准确率模型生成的伪label替换成了分类网络的logits,放松了label的形式,增大了不确定度,对输入的表达反而增强了,提供了更多的信息,soft的label使得浅层的网络也能够很好地表征input的特征了。
NIPS15: Distilling the Knowledge in a Neural Network
这篇文章是三巨头之一的Geoffrey Hinton写的,和NIPS14的思路很像,NIPS14是借助模型压缩来研究深层网络和浅层网络之间的差别,这一篇则是研究怎样用一个单一的模型来达到ensemble多个复杂模型得到的效果。NIPS14使用logits来提供类内相异性和类间相似性,而这篇文章则提出了更general的“蒸馏”方法。
Knowledge distilling
文章提出的知识蒸馏的方法其实就是之前的model compression,不知道为啥被他解释成了知识蒸馏之后大家就都开始用这个词,知识蒸馏听起来确实很高大上,但是太花里胡哨了点。。。
OK讲正题,文章提出用带温度TT的分类概率值来代替NIPS14用的logits以及KDD06用的分类器输出,并提出这种方式的soft label能够提供更好的蒸馏效果。同时它也提出发现在训练student model的时候加入一项hard label的loss会更有帮助。文章证明了优化带温度的分类概率在T很大的时候,等效于matching logits:
q_i = \frac{exp(z_i/T)}{\sum_j exp(z_j/T)}qi=∑jexp(zj/T)exp(zi/T)
如果teacher model的logits是v_ivi,则优化上述情况下的loss就等效于:
\frac{\partial C}{\partial z_i}=\frac{1}{T}(q_i-p_i)=\frac{1}{T}(\frac{e^{z_i/T}}{\sum _j e^{z_j/T}}-\frac{e^{v_i/T}}{\sum _j e^{v_j/T}})∂zi∂C=T1(qi−pi)=T1(∑jezj/Tezi/T−∑jevj/Tevi/T)
进而当T足够大时,可以近似得到:
\frac{\partial C}{\partial z_{i}} \approx \frac{1}{N T^{2}}\left(z_{i}-v_{i}\right)∂zi∂C≈NT21(zi−vi)
也就是说T足够大时,是等效于NIPS14的做法的。
因此所谓的蒸馏,相比于之前的做法提出的新东西主要是两点:
- 将softmax或者logits改为soften softmax,加入了温度参数来控制,提供一个可控的软化输出;
- 将true label加入loss会更利于小的model的学习。
遗憾的是文章似乎并没有和NIPS14以及KDD06的蒸馏方法做比较,没法看出它的优越性。从理论上说,当然是一个可控的软输出比较适合,这样相当于在控制软label的能力,能够比较适配于不同的student model,使这种蒸馏方法更加灵活,但是效果呢?
MNIST上的实验
这篇文章有个很有意思的实验,那就是在训练student模型的时候,去掉了3这个label对应的data,但是训练出来的网络仍然能够比较好地分类出3的图片。这个就有点像老师看过学过3,而学生没有,于是老师来教他的感觉,这里充分体现了所谓的teacher-student model的一点意思了。
小结
说实话这篇文章不知道咋回事读起来挺难受的,我感觉是因为作者喜欢把简单的东西说得贼复杂,而且一句话写得老长,阅读体验不是很好。不过文章的想法是很有价值的,对于ensemble的网络,test阶段太耗费资源,因此使用知识蒸馏的方式来训练一个蒸馏网络,利用软label,能够让小模型学习到ensemble这种大模型能够学到的准确率。但是我觉得文章有个小问题就是,明明他们提出的软label是在NIPS14和KDD06的方法基础上做了个小修改,却不跟别人的方案做比较,只讨论相似性,其实有点奇怪的。不过NIPS14和KDD06倒是都没有明确地讨论软label带来的好处,这也算是这篇文章的一个贡献点了。
另外有一点我没记录的就是,对于大型的网络,训练ensemble可能都比较麻烦,因此文章还提出了一个使用specialist model和generalist model结合的方式,具体方法没有细看,就不看了。
AAAI 19: DDFlow: Learning Optical Flow with Unlabeled Data Distillation
基于数据蒸馏的光流估计
这篇文章是用所谓的数据蒸馏的方法来从没有光流label的视频数据中学习光流的,其核心思想就是从teacher网络中得到置信度比较高的预测值,用来作为student网络的标签,当然单纯这样做是没有什么意义的,文章提出的做法是,用teacher网络去学习非遮挡区域的光流,然后通过crop patch来让原本不遮挡的点强行被遮挡(移到了patch外头),从而用teacher网络学习到的光流来监督遮挡区域的学习,大致流程图如下:
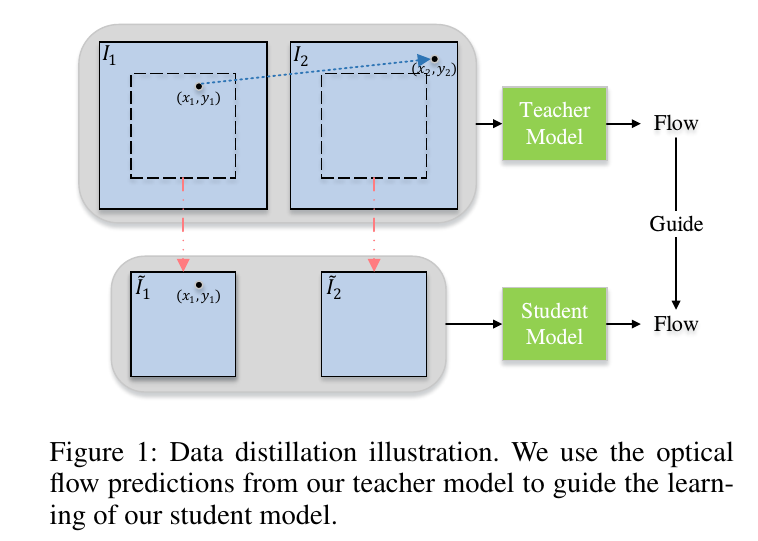
在遮挡区域,所谓的亮度一致性不再成立,因此很难得到遮挡区域的较为准确的光流估计,这种自学习的方式利用模拟遮挡的方式,能够让student模型比较好地学习到对遮挡情况的处理,但是成也模拟败也模拟,这种遮挡的建模方式理论上会非常适用于图像边界附近被遮挡的pixel(被移出去了),然后一定程度上适用于图像内的遮挡(因为random crop会cover很多类型的遮挡),但是任意位置的遮挡仍然还是一个不太好处理的问题。
网络的大体框图如下图所示:
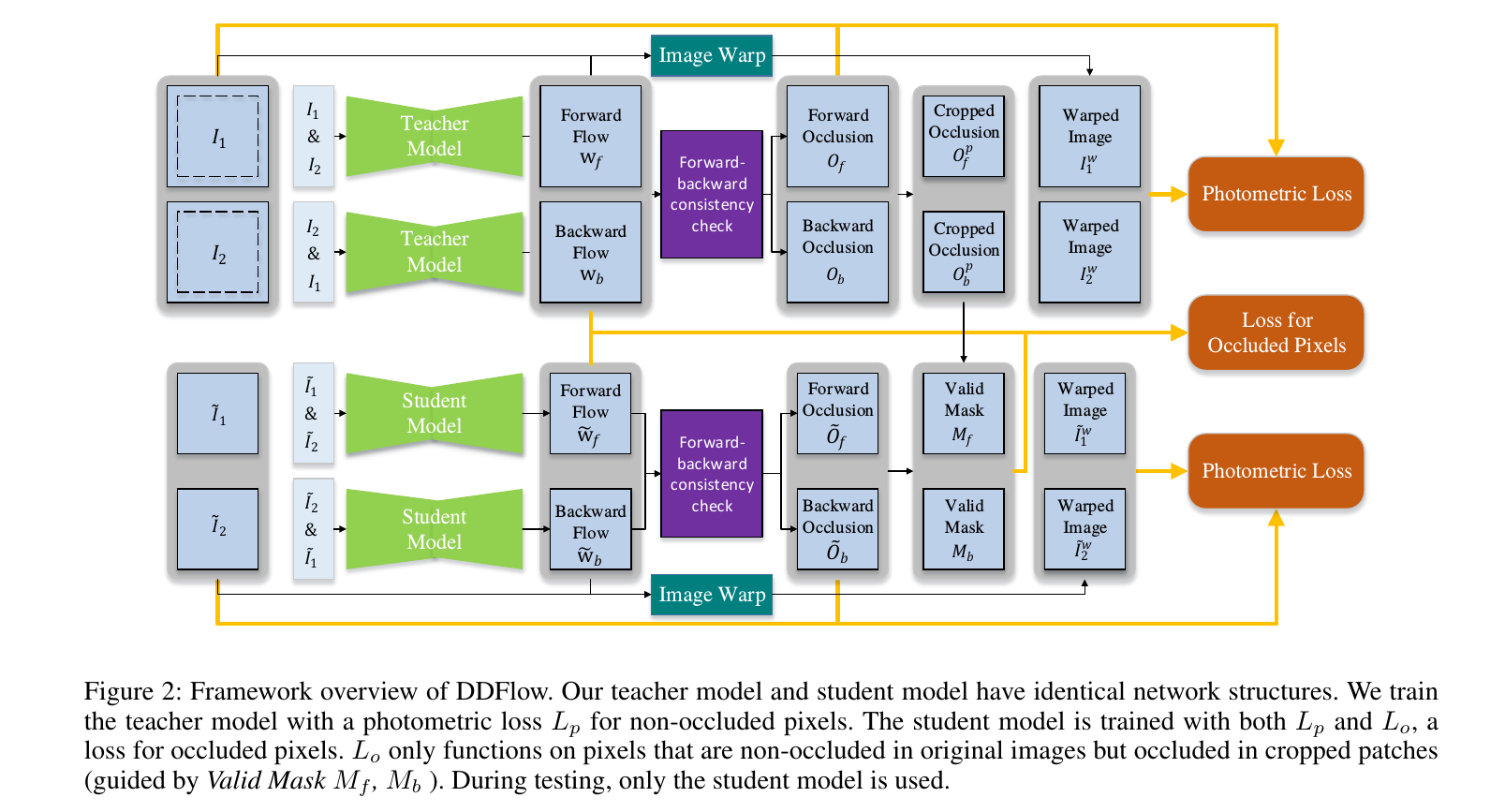
可以看到,首先teacher模型学习forward和backward的光流,然后通过两个光流的一致性检测(对应位置光流互为相反数)来获得occlusion map,然后warp之后的image和source image在non-occlusion区域计算一致性的loss,然后对于student模型,它学习crop之后的video的光流,同样得到occlusion map,然后与teacher模型得到的occlusion map进行比较,得到在大patch中没遮挡但在合成数据中有遮挡的点的位置的mask,用来计算“occlusion”区域的loss。
其实我对这里也有一点疑问,teacher模型和student模型得到的O肯定是有误差的,这样估计到的mask也不一定代表了“occlusion”区域,不过在光流逐渐接近真实光流的情况下,这种假设也不是不成立的,只能说。。。蛮奇怪的。。。另外还有一点,文章的loss函数里面,无论是non-occlusion区域的photometric loss还是occlusion区域的occlusion loss,都用到了由光流生成的1bit的map(O以及M),那反传的时候是否考虑了这两个东西呢?还是说压根就不考虑?那就有点奇怪了吧。。。
训练过程
上一段的疑问可以通过训练过程多少回答一点,训练过程是这样的,分三步进行:
- 不考虑遮挡,直接训练teacher模型;
- 加上occlusion map,用L_pLp(photometric loss)训练teacher模型;
- 给teacher模型加L_pLp,给student模型用teacher模型做初始化,加loss为L_p+L_oLp+Lo,一起训练这两个模型;
从上述训练过程可以看出,teacher模型是经过预训练的,然后第三步,student模型是和teacher模型的初始化一样的,这就一定程度上保证了O和M的有效性。
小结
这篇文章的思路很有意思,传统的光流估计方法,是用一些优化的能量函数来正则输出的光流,费时而且准确度低,而学习的方法呢,如果是有监督的,那么就会带来数据量不够的问题,而且合成的数据很难迁移到真实数据集,如果是无监督的,那么使用的loss对occlusion很难处理,文章的着力点就在于模拟了一个occlusion,然后通过teacher-student模型把occlusion下的情况学习了出来,使得student模型具备了对occlusion的handle能力,从而使得输出的光流在occlusion区域能够表现良好。
当然文章也有一点问题,首先是前面提到的O和M的反传问题,另一方面则是random crop模拟的occlusion是很有限的,复杂的occlusion它也模拟不出来,任意位置的它也没办法模拟。这种random crop模拟的实际上是矩形或者类似矩形的occlusion,如果能用支持任意形状的模型,比如super-pixel,应该就能够使模拟的效果更好了。
CVPR19: SelFlow: Self-Supervised Learning of Optical Flow
那么终于到了这篇正主儿了,这篇文章是AAAI19同一批作者,他们在提出使用random crop来模拟occlusion之后,意识到random crop是算法的限制所在,它只能够模拟边界上或者是物体就消失在图像中了的情况,但是如果物体还在图像里面,只不过是被其他东西遮住了,亦即图像中任意位置任意形状的occlusion,就比较难模拟了。
Self supervision: NOC to OCC
鉴于此,文章提出使用super-pixel来模拟occlusion关系,具体做法见下图:
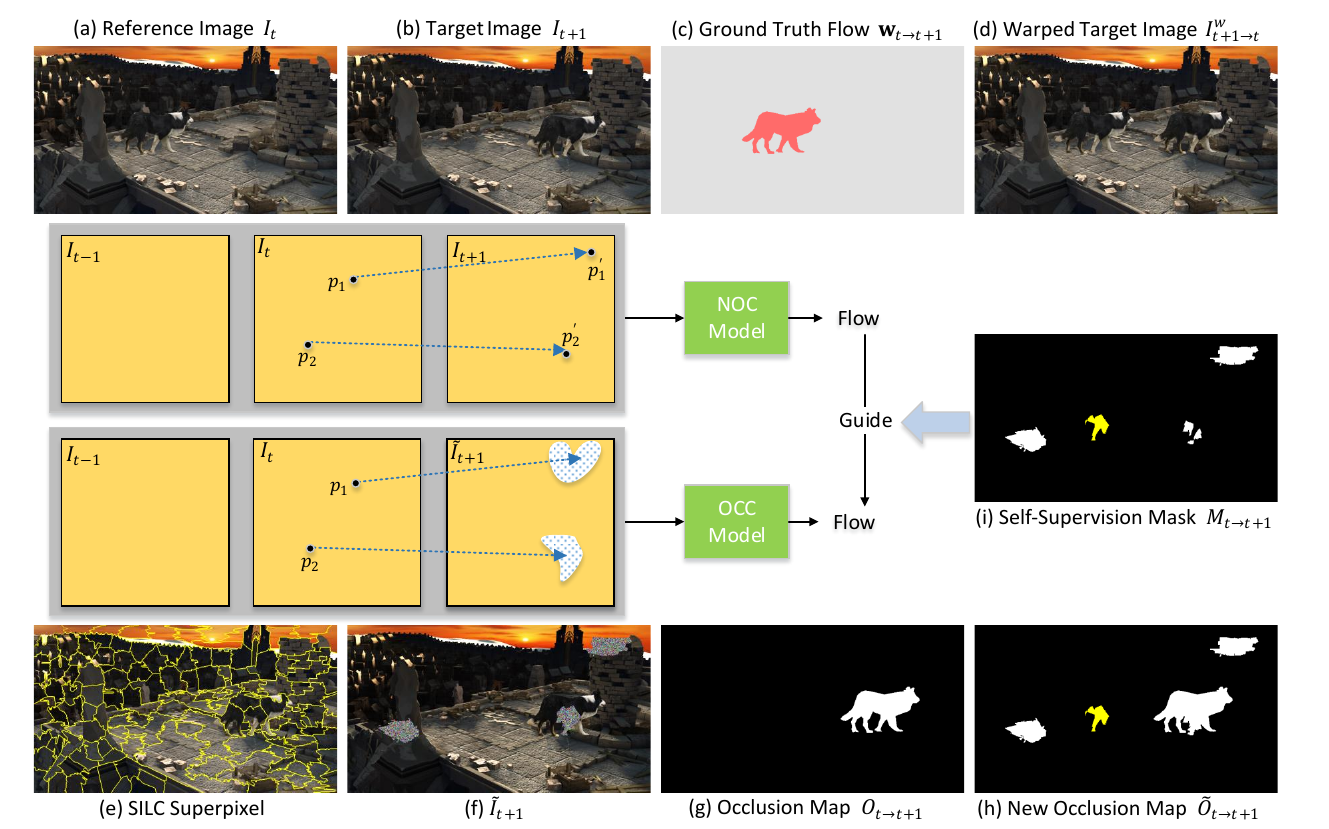
文章首先训练一个非occlusion区域的NOC网络,使用常用的photometric loss,然后在将target帧进行superpixel分割之后,随机对其中几个superpixel注入随机噪声,举例而言,I_tIt中p_1p1对应在I_{t+1}It+1中的p_1^{'}p1′,在注入噪声之后,I_{t-1},I_t,\hat I_{t+1}It−1,It,I^t+1成为了input,p_1p1点在\hat I_{t+1}I^t+1中被遮挡了,于是遮挡就被模拟了出来。这与之前AAAI的做法其实不谋而合,只不过是把被遮挡掉的区域换成了0值(crop掉了,其实也可以理解成什么值都有可能,那就是随机值了),而且用的是方形的遮挡。
使用superpixel的优点也很明显,首先是superpixel的形状往往都比较随机,而且贴近物体边缘,利于对物体之间遮挡的模拟,其次就是在同一个superpixel内的物体一般是同一个物体,有同样的流场,因此也有方法用superpixel来做光流估计的。
其实可以看出这两个方法对遮挡的生成都是通过强行增加干扰来模拟的,其实这么做是有一定的道理的,遮挡物能够将被遮挡物体的部分或者所有pixel挡住,从而当前帧与前一帧之间的motion就被挡住了,无法预料了,因此对于被遮挡物的光流预测而言,遮挡物是啥并没有任何影响,反正都被挡住了,我们可以通过teacher模型生成的label以及上下文的motion信息推断出被遮挡pixel的光流。与此同时,随机干扰的好处在于泛化能力,相当于只考虑了遮挡物的形状而随机化遮挡物的纹理。
到这里做法就很清晰了,其实整个网络做法是和AAAI几乎一致的,只不过生成遮挡的方式变了而已。那么肯定还是要有O map和M map来对loss做个划分,也就是非occlusion区域的loss和模拟出来的occlusion区域的loss。occlusion区域的loss为:
L_{p}=\sum_{i, j} \frac{\sum \psi\left(I_{i}-I_{j \rightarrow i}^{w}\right) \odot\left(1-O_{i}\right)}{\sum\left(1-O_{i}\right)}Lp=i,j∑∑(1−Oi)∑ψ(Ii−Ij→iw)⊙(1−Oi)
其中呢\psi(x)=(|x|+\epsilon)^{q}ψ(x)=(∣x∣+ϵ)q,是一个鲁棒的loss函数,q取的是0.4。occlusion区域的loss为:
L_{o}=\sum_{i, j} \frac{\sum \psi\left(\mathbf{w}_{i \rightarrow j}-\widetilde{\mathbf{w}}_{i \rightarrow j}\right) \odot M_{i \rightarrow j}}{\sum M_{i \rightarrow j}}Lo=i,j∑∑Mi→j∑ψ(wi→j−wi→j)⊙Mi→j
其中occlusion map的生成是和AAAI一样的,唉其实O map、M map以及loss函数的参数,这些东西都是一样样的,还有训练方法,三步走,也是一样的。
网络改进
文章另一个contribution是引入了多帧的信息来辅助,当t+1帧上看不到t帧能看到但是在t+1帧被遮挡的信息时,可能t-1帧可以看到或者提供更多的信息,因此文章相比于AAAI不一样的地方在于,AAAI只是单纯地用了PWCNet,文章还将PWCNet拓展为用三帧作为输入得到两个光流的网络,在teacher-student模型中,当然还是只perturbate第t+1帧了。
我们都知道PWCNet是一个结合了金字塔、Warp和Cost Volume的网络,是CVPR18年效果很好的光流估计网络,其网络设计如下图所示。
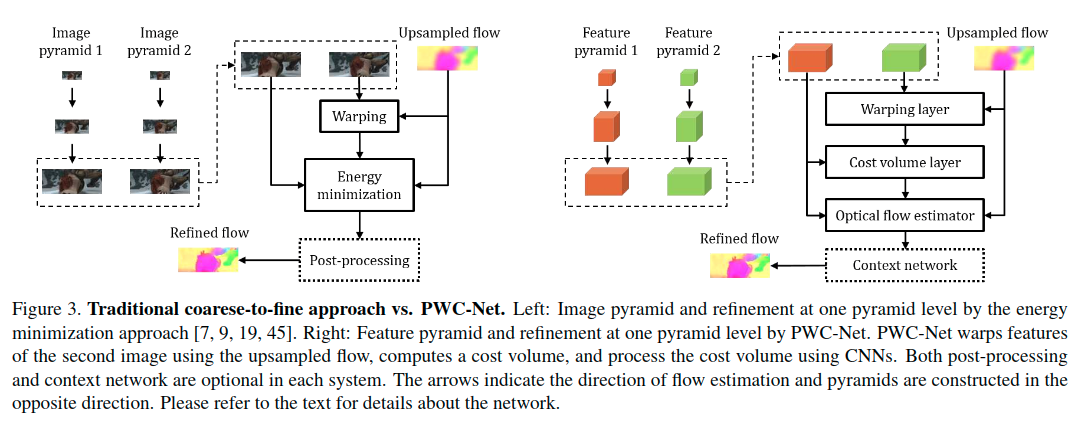
网络将以前用的图像金字塔改成了特征金字塔,同样是用浅层传来的低分辨率光流上采样之后来warp,不过这里是warp特征金字塔中该层的特征,然后与target的特征计算cost volume,再将cost volume、target feature以及upsampled flow一起输入光流估计网络,进行flow refinement,得到该层估计的光流。
文章将其修改为下图的形式:
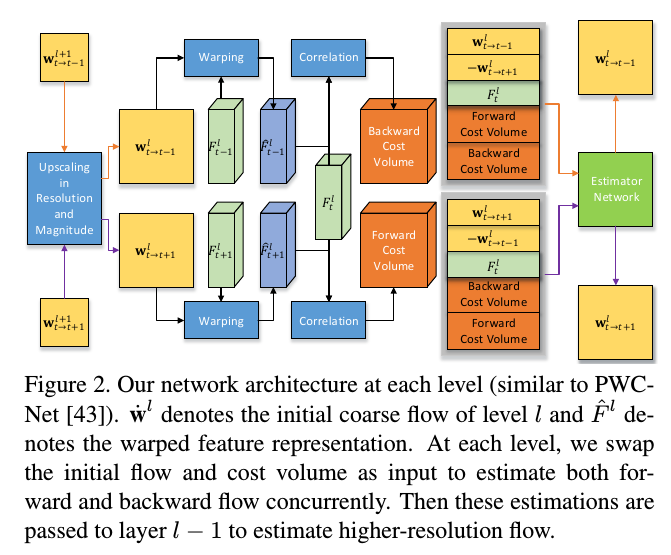
可以看出文章的修改其实是把多帧放到一起去算了,同时还把来自上层的两个光流都送进了光流估计网络,增多了网络输入的信息。
对于occlusion map,由于这样重新设计的网络只输出一个前向的光流,所以文章用5帧作为输入,强行得到了两个方向的光流,用他们的一致性来计算了O map,计算方式如下:
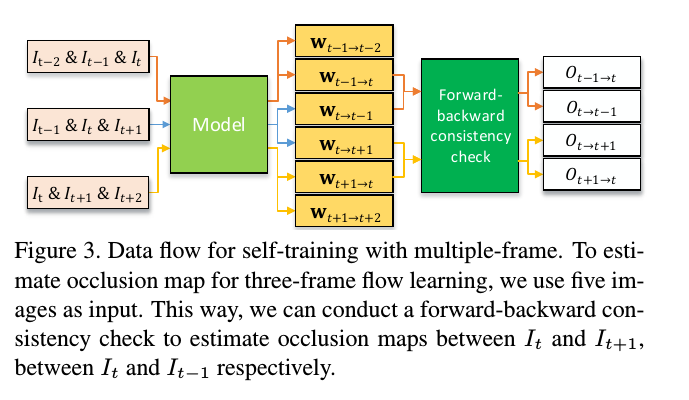
对有监督方法的益处
现有的有监督深度学习方法总是因为数据量不够,或者仿真数据和真实数据gap太大,导致结果不够好或需要特别设计的finetune方法。文章通过这种self learning的方式得到了一个能够很好地处理occlusion的student model,并且证明用它做初始化来用真实的数据集(一般比较小)来finetune,能够得到比直接在这些数据上面训练更好的结果。它不需要额外的有label的数据做pretrain,而且收敛得更快,因此是个很有用的初始化。
总结
通过这五篇文章的阅读,我对知识蒸馏、teacher-student模型有了比较初步的认识,前三篇文章主要是通过这种方法做模型压缩以及轻量化,后两个方法则是侧重于通过容易学习的东西来学习难学的东西,核心思想就是把非遮挡区域模拟成遮挡区域,从而又有遮挡又有label,皆大欢喜,使得student模型能够很好地处理occlusion区域。
这篇文章的思想还是很巧妙的,引入superpixel和随机噪声的方法很大胆却也很有根据,它给我们的一个启示就是,在一些数据的label不好获取的场合,self learning是一种很不错的方式,通过学习容易获取的label或者subset,通过这些subset来模拟出不容易获取label的的情景,然后进行学习,处理难以handle的情况。
当然我还有那个O和M的梯度问题,我有点想不明白这个东西到底要不要参与反传。。。















 1806
1806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









