







GRU是RNN的一种结构,设计思路来源于LSTM,现在大都使用GRU来代替LSTM.因为效果差不多,但是计算更简单,LSTM计算稍微复杂了点.他们都是为了解决长期记忆和反向传播中的梯度等问题而提出来的.

1.介绍一些定义
GRU里面2个重要的门控,reset和update.
h为隐藏层(hidden),t,t-1, ' 表示时间状态.
x为输入,y为输出
为哈达码积,即对应元素相乘
为矩阵加法操作
2.介绍一些运算

通常,RNN的计算为上一次隐藏层()+输入(
)得到输出(
),和下一个隐藏层
在GRU内部有重置门和更新门,重置向量和更新向量具体计算步骤如下
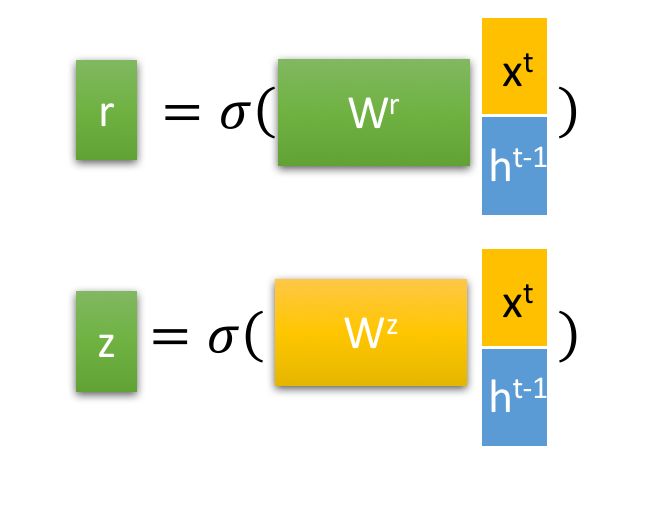
其中为激活函数,sigmoid,W为可学习的权重矩阵,r为重置门的权重向量,z为更新门的权重向量
2.1 进一步通过重置门得到

这里的主要是包含了当前输入
的数据
2.2 再来计算更新门的数据,在这个阶段,我们同时进行了遗忘和记忆两个步骤
由2.1的计算得知z为更新门权重,z越大,记忆当前状态越多,遗忘t-1状态越多.门控信号越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。
GRU计算性能的提升就在于此,使用一个门控就可以同时进行遗忘和记忆
结合上述,这一步的操作就是忘记传递下来的中的某些维度信息,并加入当前节点输入的
某些维度信息。
2.3 最后计算输出
这时候反过来再看这张图就很容易理解GRU是怎么运行的了
3.作为对比,看下LSTM原理

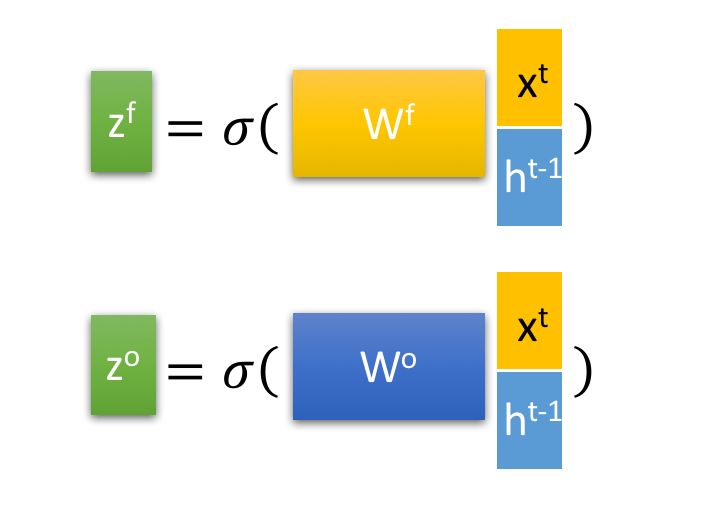
LSTM有2个隐藏层,h和c
有3个门控,f=forget,i=infomation,o=output
z这一层的计算都是类似的,,输入完全相同,i,f,o的权重w不同,z为对输入的变换
tanh将数据变换为-1到1,sigmoid将数据变换为0-1作为权重
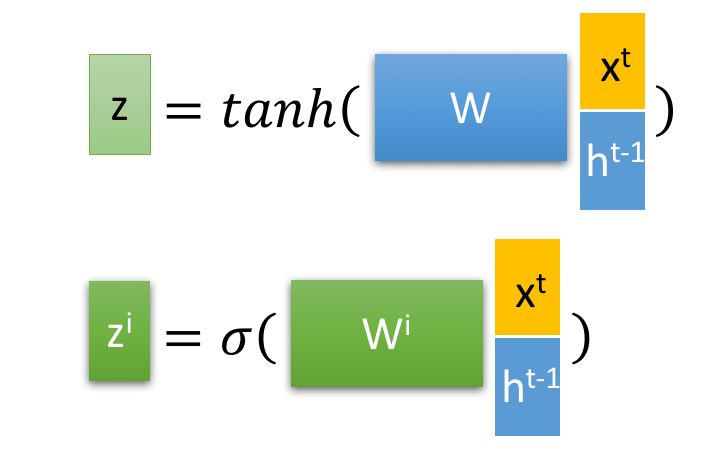















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









