






一、前言
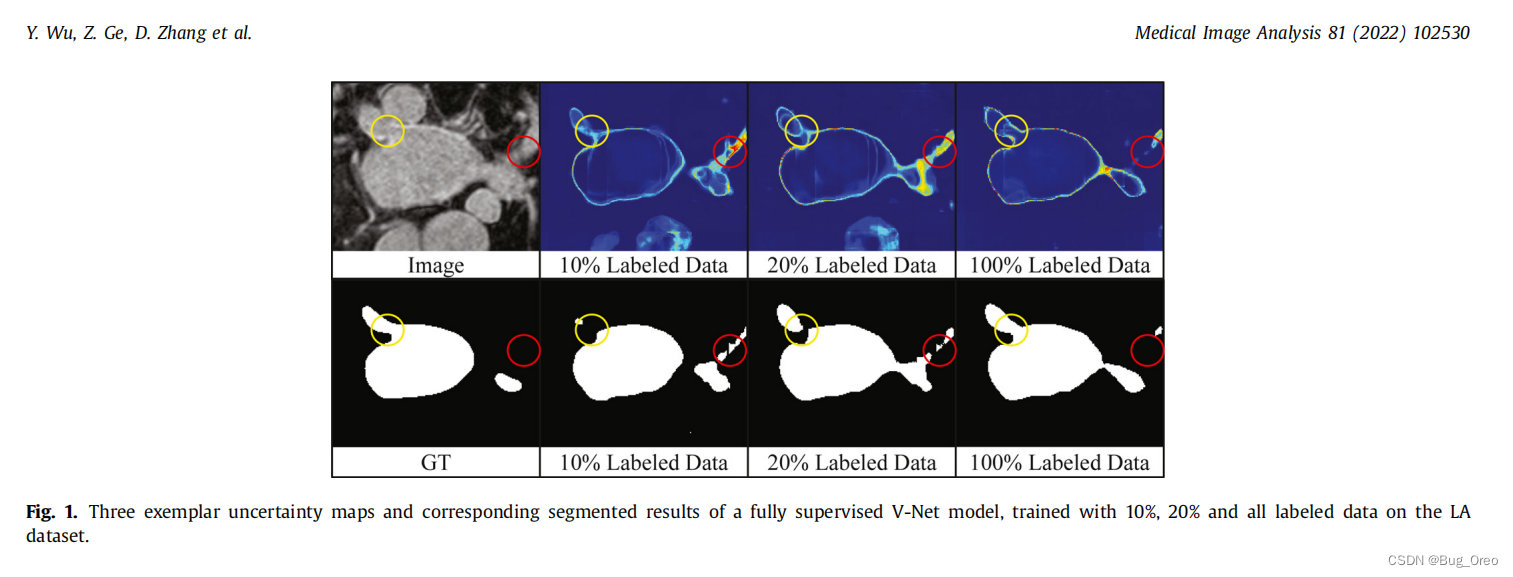
论文Motivation: 用有限数据训练出的model在医学图像模糊区域的书橱往往具有高度不确定以及容易分割错误。因此提出了本文的模型MC-NET+。
源码地址:论文代码
二、 简介
提出了MC-NET+的网络来利用未标注的数据进行半监督的医学图像分割。这个网络模型包含两个主要创新点: 1. 模型包含一个共享的encoder以及多个在上采样阶段略有不同的decoder。多decoder输出的计算用于表示模型的不确定性, 也就相当于代指了未标注的hard区域。2. 在一个decoder概率输出和其它decoder的soft 伪标签之中采用了新的交互一致性限制。这样可以最小化多个输出结果的差异性。在三个公共数据集上,模型与五个SOTA的半监督方法进行了比较。
三、 Inrtoduction
四、 Related work
4.1 半监督学习
半监督学习是指,训练集中一部分数据有特征和标签,另一部分只有特征(只有输入没有输出),综合两类数据来生成合适的函数。
目前普遍认为一致性约束以及熵最小化约束都能提高半监督模型的特征判别能力。本文我们采用了这两种方法用于我们的MC-NET+模型中来实现精确的半监督MIS(Medical Image Segmentation)。
4.2 半监督的MIS
文章举例了近些年来所提出用于医学图像分割任务的半监督方法,发现尽管这些方法在半监督MIS取得了良好的结果,但是忽视了在未标注数据中的有挑战区域的影响。因此我们假设,即使没有相应的标签,我们也可以通过更有效地建模具有挑战性的区域来进一步提高任务的性能。我们的模型是基于图1,并采用了一个具有多个略有不同的解码器的共享编码器进行训练。
4.3 多任务学习
改进深度模型泛化的另一个研究方向是通过学习跨任务特征表示或进行无监督的预训练。我们提出的MC-Net+模型不需要设计特定的辅助任务,只考虑了模型训练的原始分割任务。另一方面,我们提出的方法可以很容易地与这些多任务学习模型相结合,以进一步提高半监督医学图像的分割。
4.4 不确定性估计
不确定性分析在机器学习以及CV领域中都受到了极大关注,我们不仅期望模型输出正确的结果, 并且也希望能获得生成的predition的置信度。在半监督的场景中,我们在这里只讨论认知的不确定性,这可以通过提供更多的训练数据来减少。
有一些现存的方法用于评估不确定性,例如:变体Unet,模型集成策略, MC-Dropout方法.....而本文中受Zheng and Yang等人启发,在模型训练之前我们的模型预定义了多个子模型, 这些子模型用于评估模型的认知不确定性。
五、 Method
用于定义半监督分割问题的注释:
x ∈ X代表输入图像, p(ypred|x; θ ) 是x的生成概率图, θ 表示的是骨干网络f的参数;
yl ∈ Y 表示给出的分割注释, DL 与 Du分别代表标注与未标注的数据集
5.1 模型结构
MC-Net+模型利用未标记中的模糊区域用于模型的训练, 可以通过模型的认知不确定性来表示。模型结构如图二所示:
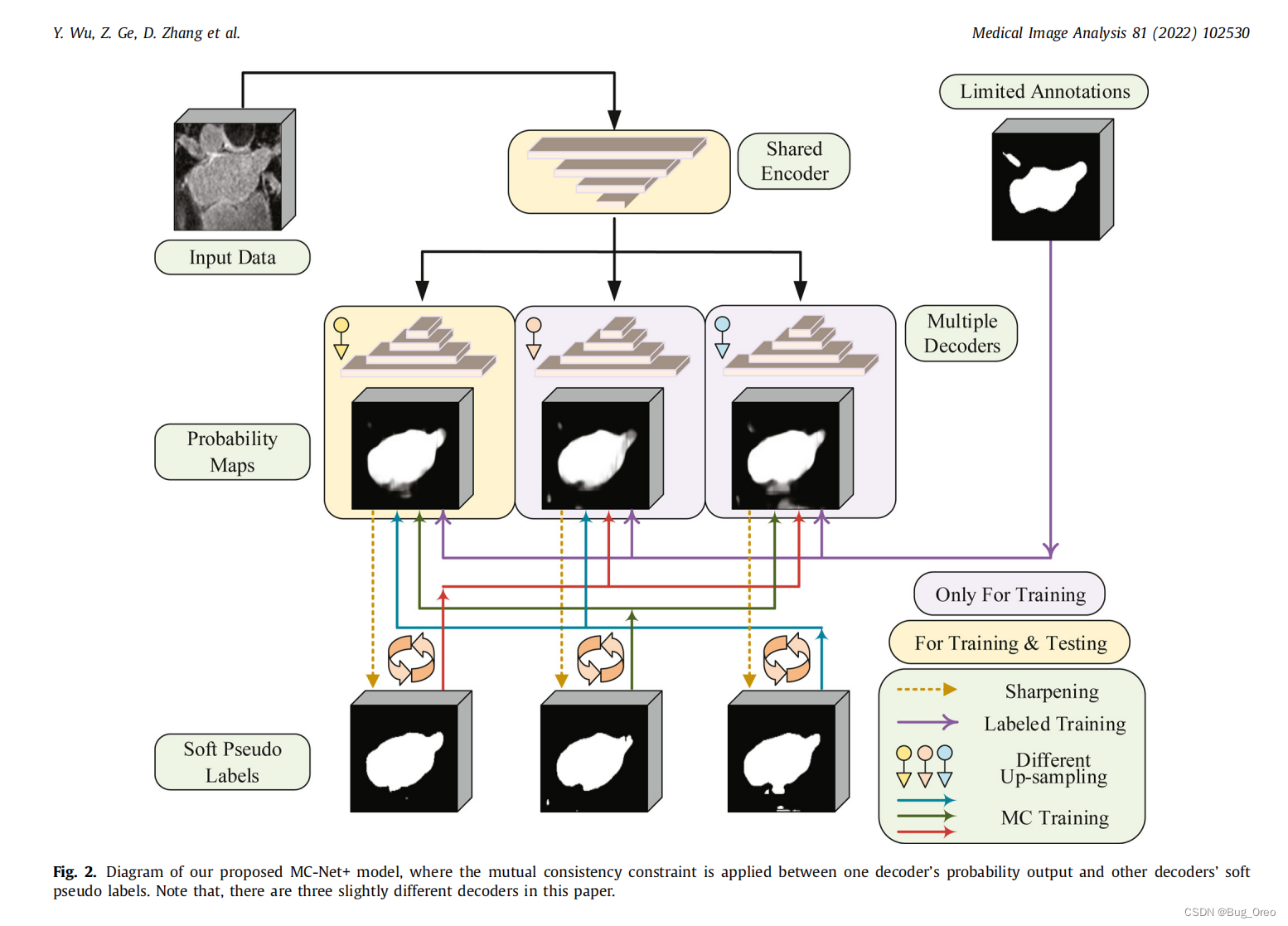
由图可知,该网络用的是一个共享的encoder以及多个上采样方式不同的decoder(默认decoder数量为3).为了解决原有的MC-Dropout算法中需要多个前向传播的问题,我们提出了该结构。利用共享的encoder,在不确定性估计之前预定义了n个子模型(n默认为3, 为了权衡有效性与效率)。以这种方式对于输入数据x的不确定性估计Ux就变为了:
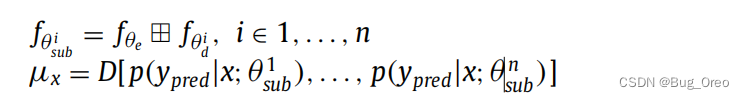
其中,在第一行中田代表一个子模型 fθ i sub 是由一个共享的编码器 fθ e 与 一个解码器 fθ d组成的。D是用于计算n个输出的统计学差异。
5.2 相互一致性约束
结合4.1中一致性约束以及最小熵约束,提出了一个新型相互一致性训练策略, 使用了一个 sharpening 函数将输出的概率图转换为了一个软伪标签。首先我们使用了sharpening函数将输出的概率图转换成了伪标签,其次我们在一个decoder的概率输出与其它decoder的伪标签之间进行相互学习,来指导 模型的学习 和 高度不确定区域的预测保持一致。
sharpening函数公式如下:
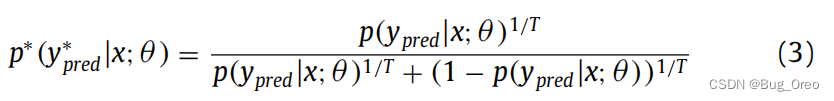
p*代表软伪标签, p代表原来的概率输出图。
在5.1图中的这一部分: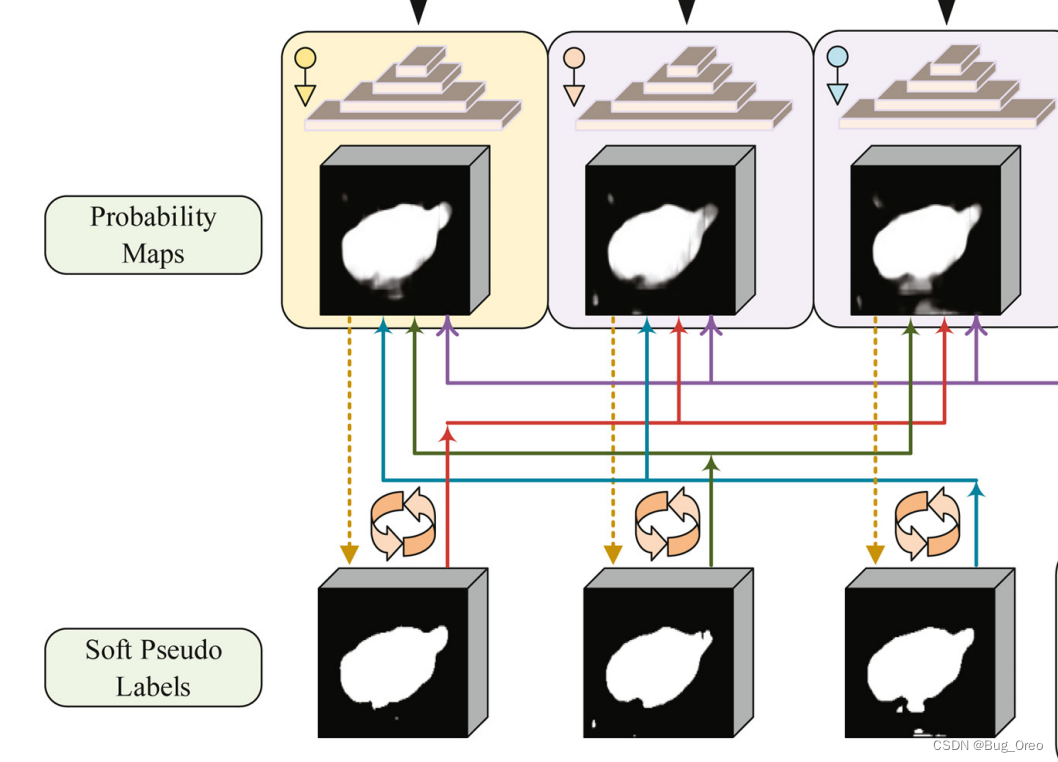
红色,绿色以及蓝色的线分别代表在 一个概率输出与其他解码器的软伪标签之间 进行相互学习。以这种减少输出之间差异的方式来指导模型的学习。在高度不确定区域的预测一致的这种设计的优点如下:
1. 通过子模型输出的一致来实现一致性约束
2. 在软伪标签的监督下,学习模型作为熵最小化约束产生低熵结果
3. 以“端到端”的方式进行训练,不需要多次正向传递
6、 实验
6.1 数据集
我们在LA、Pancreas-ct和ACDC数据集上评估了所提出的MC-Net+模型.
(1)LA数据集的基准数据集链接: http://atriaseg2018.cardiacatlas.org
本文使用的LA数据集的切片为:https://github.com/yulequan/UA-MT/tree/master/data.
(2)Pancreas-ct数据集: https://wiki.cancerimagingarchive.net/display/Public/Pancreas-CT. (TCIA上直接搜名称即可找到)
(3)本文使用的ACDC数据集固定切片:https://github.com/HiLab-git/SSL4MIS/tree/master/data/ACDC.
6.2 实施细节
(1) 3D分割
使用三线性插值层将3D分割的backbone设置为V-Net,用于放大特征图。在我们的3D MC-Net+模型进行了15k次迭代的训练。在测试中,我们采用了一个尺寸为112×112×80或96×96×96的滑动窗口,固定步幅为18×18×4或16×16×16,分别提取LA或Pancreas-ct上的patches。然后,我们将基于patches的预测重新组合为最终的整个结果。
(2) 2D分割
2D的MC-Net+采用U-net作为backbone,利用双线性插值来拓展特征图。2D模型通过30k次迭代进行训练。ACDC数据集上的所有设置都遵循公共基准(Luo,2020)以进行公平比较。
7、 结果
7.1 在LA数据集上的性能
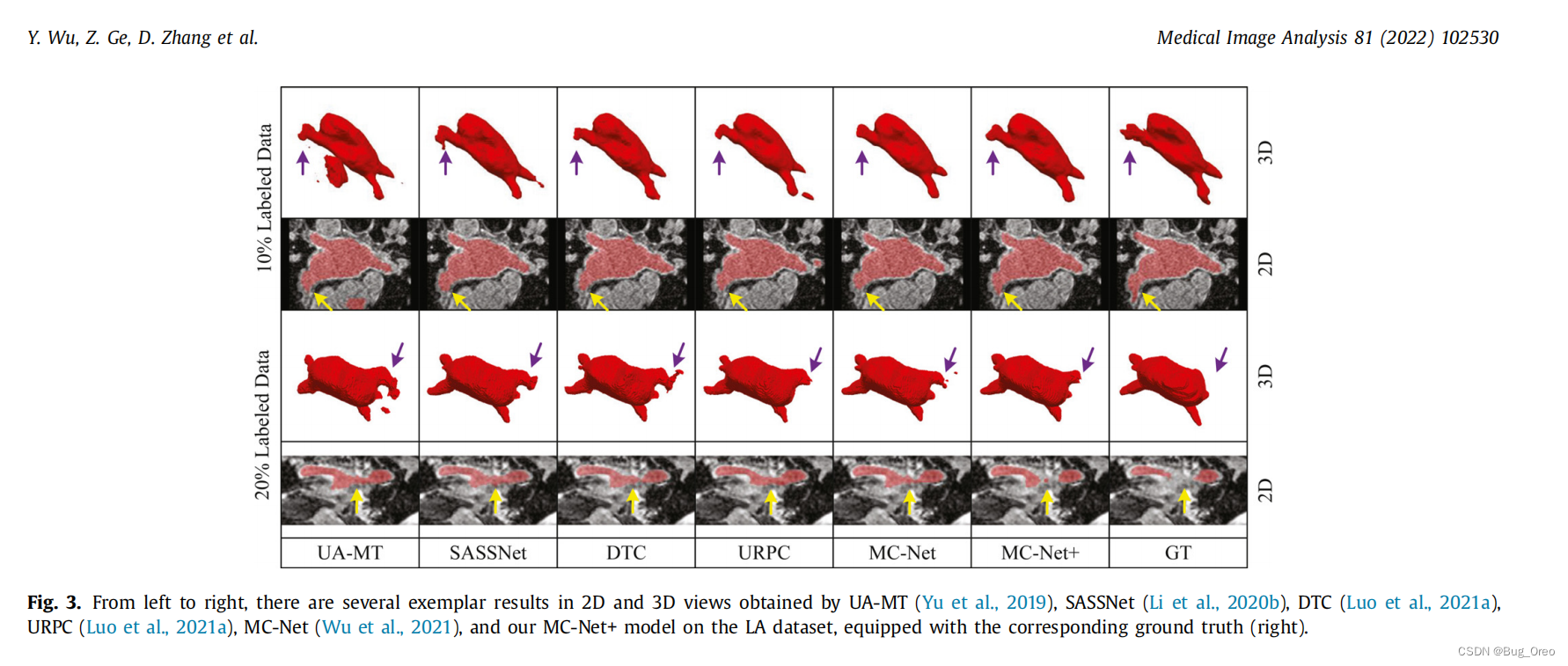
如上图所示, 给出了两个样本在LA数据集上的3D和3D视图中的多个定性分析分割结果。从左到右是由五个最近的模型和我们的方法所得到的结果,可以看出MC-Net+模型比其他SOTA方法产生了更完整的左心房。黄色与紫色箭头表明了,保留了半监督左心房的更多细节。
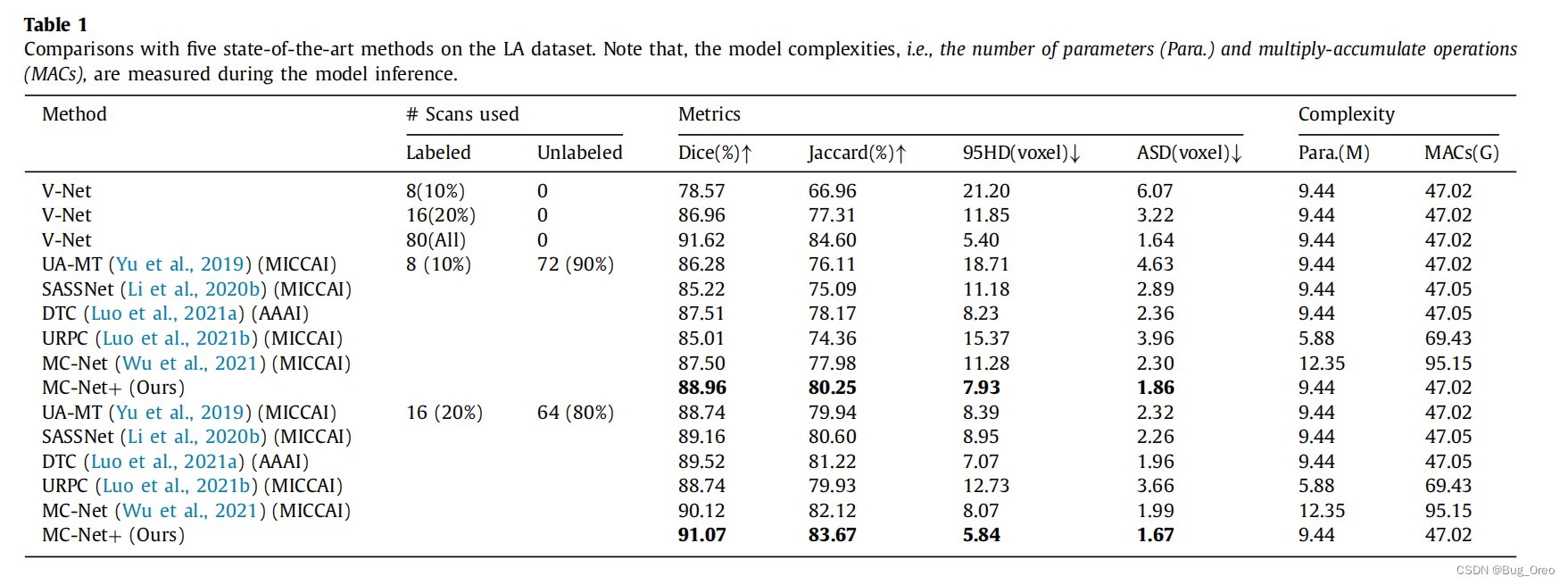
该表给出了定量分析的结果,它还参考了一个全监督的V-Net模型的结果,以及训练了10%,20%和所有标记的数据作为参考。我们提出的MC-Net+模型仅通过10%的labeled数据训练,就从78.57%到88.96%获得了令人印象深刻的性能提高;与此同时,只用20%的labeled数据训练的模型得到了与全监督的V-Net可比性的结果,91.07%和91.62%。
Jaccard系数(Jaccard index),又称为Jaccard相似系数(Jaccard similarity coefficient)用于比较有限样本集之间的相似性。
HD指标,豪斯多夫距离,计算两个集合之间的距离,值越小,代表两个集合的相似度越高
ASD指标,指的是平均表面距离(Average Surface Distance),它是用于评估两个三维表面之间的差异的一个度量。
个人复现的代码用tensorboard可视化的结果如下(仅LA数据集, 20%labeled,即labeled data数量为16)
下列图中深颜色的线代表的是经过平滑处理的数据,而浅颜色线则代表的是未经平滑处理所得到的原始数据。在tensorboard中通常用smoothing的值来控制深颜色线的生成,通常设置为0.6.
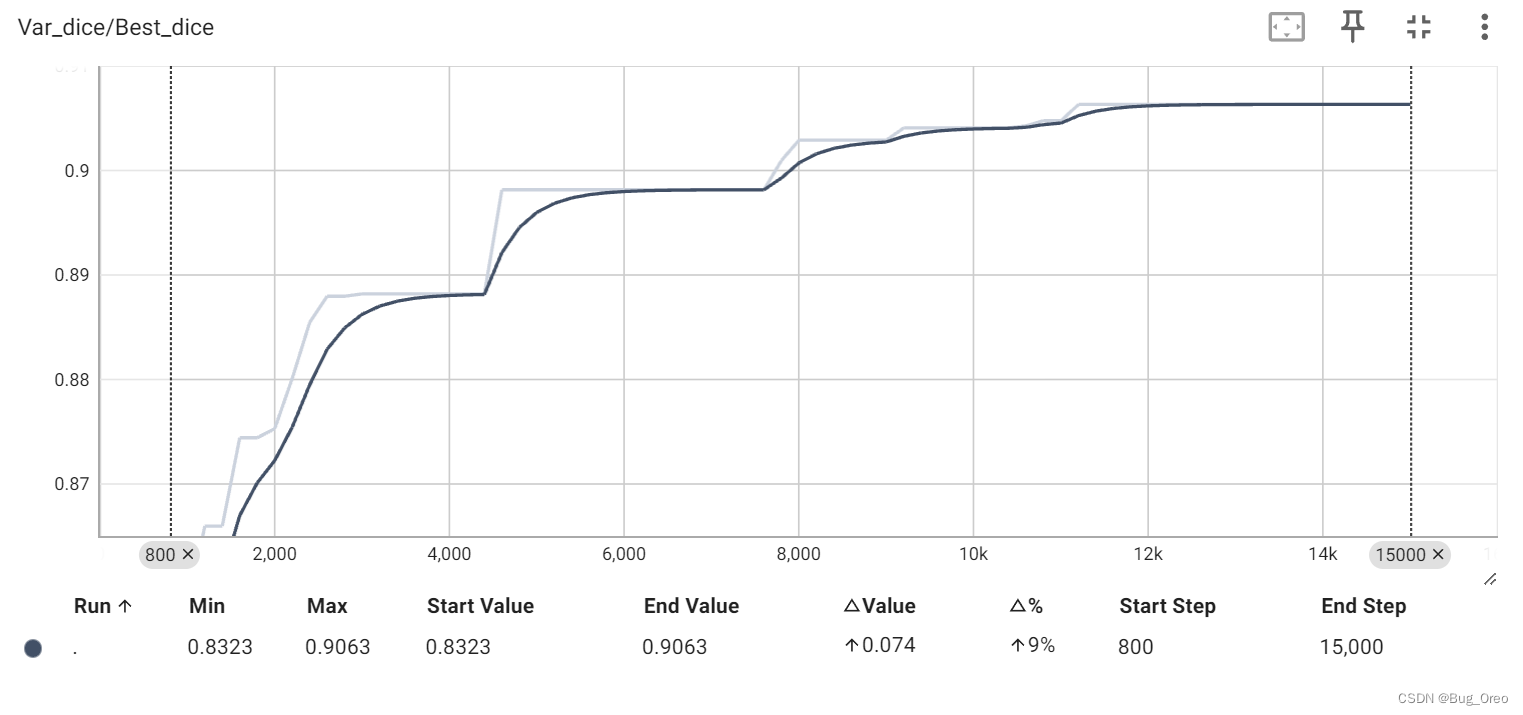
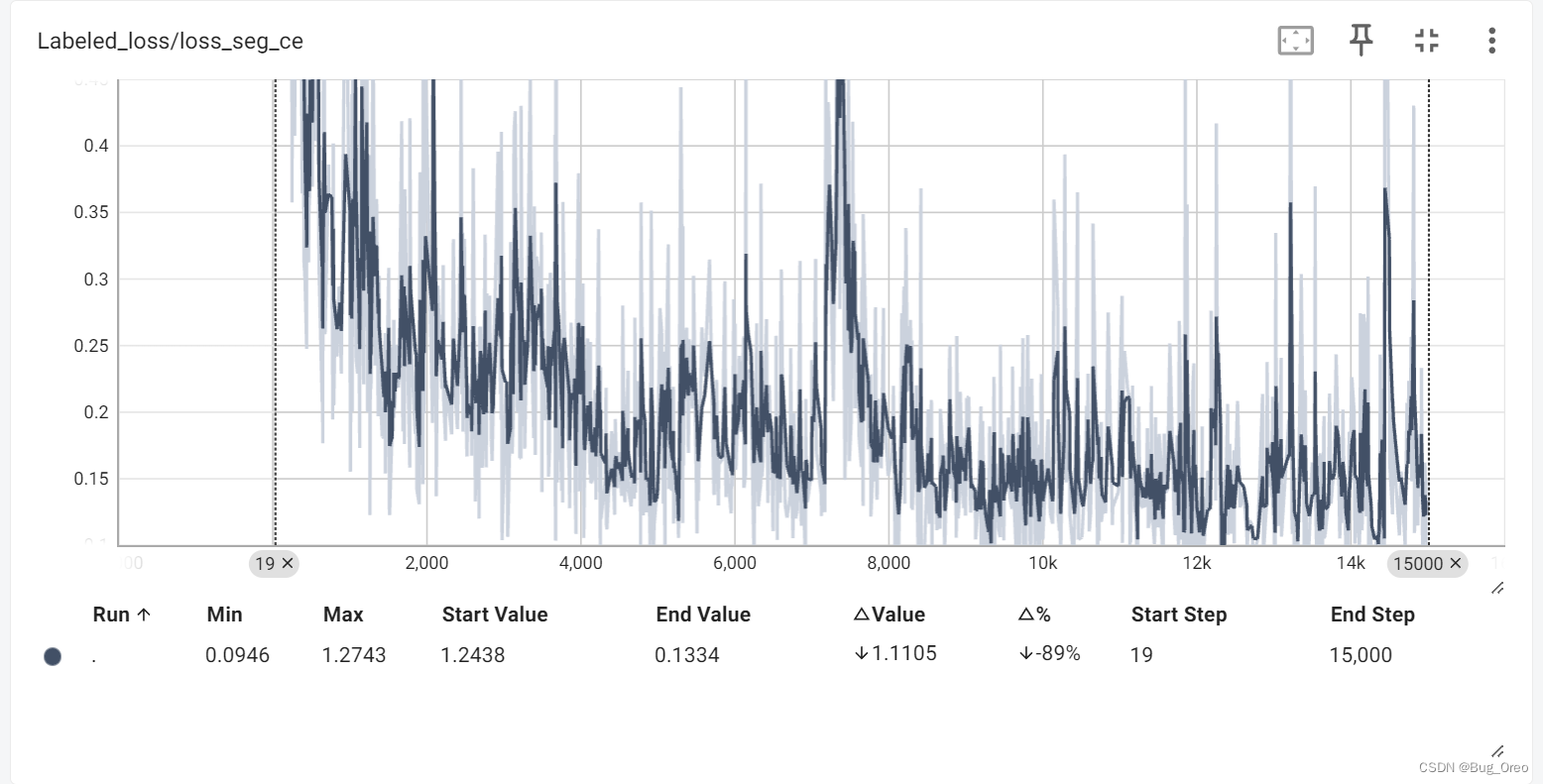
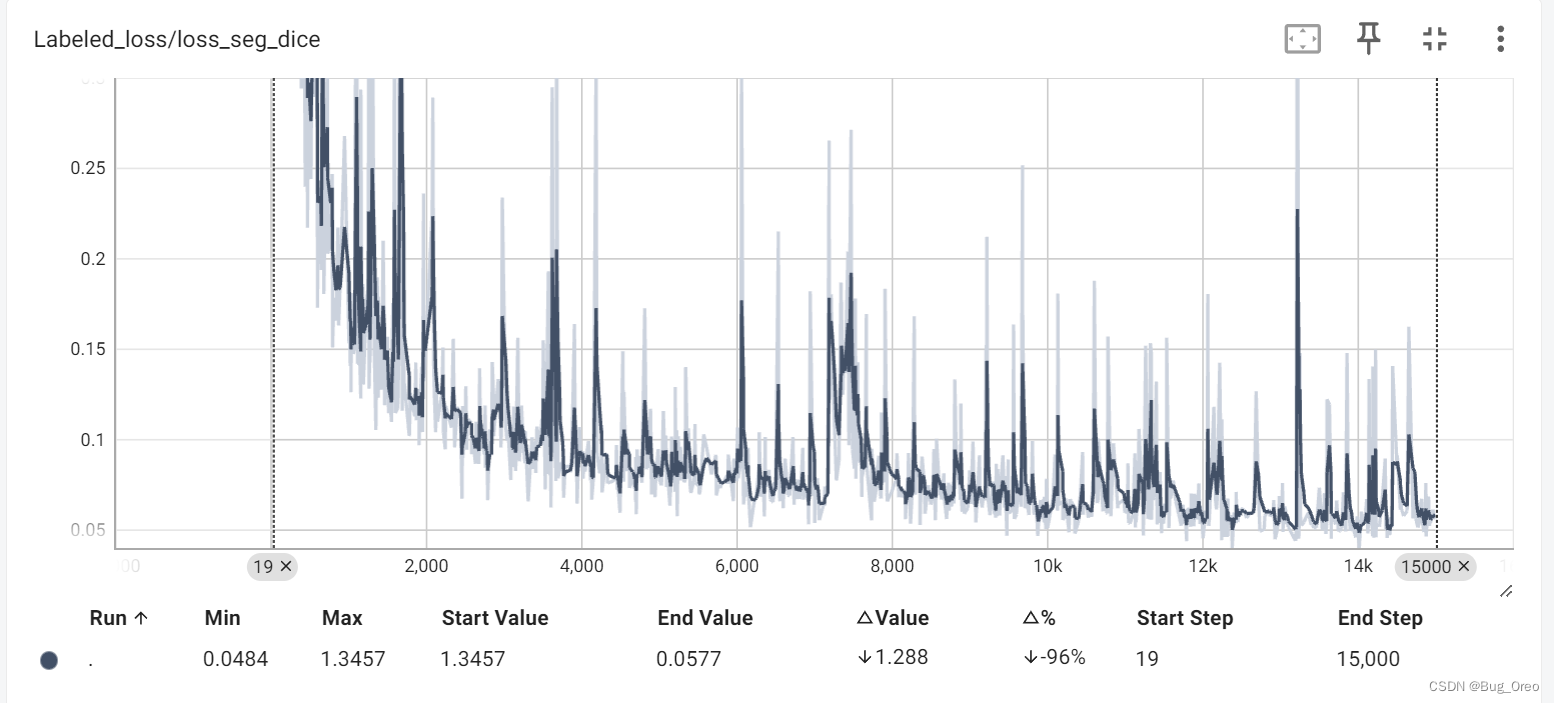
下列是本人在15000次迭代训练后得到的Dice得分, jaccard得分,95HD得分以及ASD得分:
![]()
decoder 1代指的是源码中默认的两个decoder的形式进行的解码操作得到的四分指标得分。
我们发现,在本地通过训练后得到的四个指标的值与原论文中的值进行对比可以发现,误差分别在1%,0.71%,0.83与0.17。属于正常现象。
7.2 在Pancreas-ct数据集上的性能
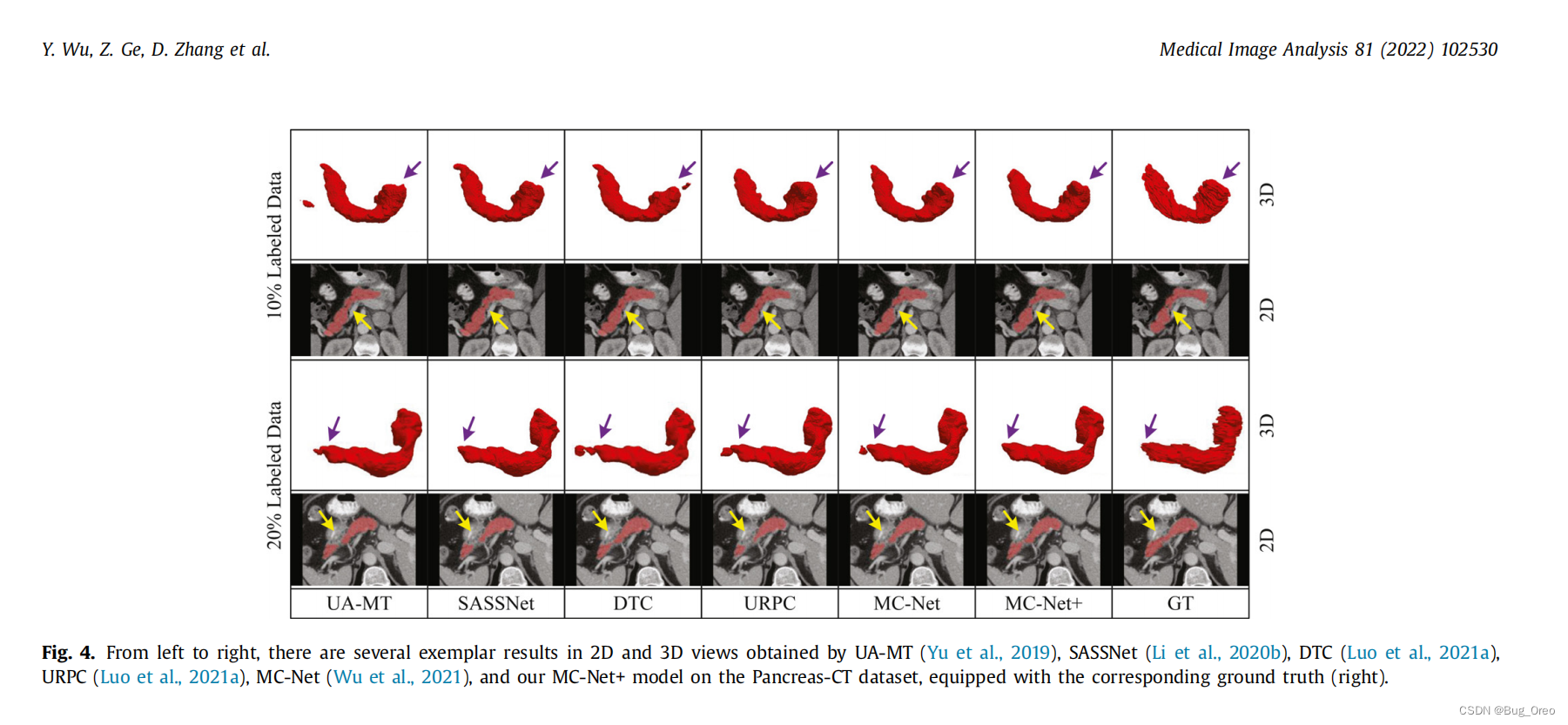
与在LA数据集上相似,我们的方法(MC-Net+)在定性分析上相比于其他五种半监督方法,在最后的预测结果上有更多的细节。
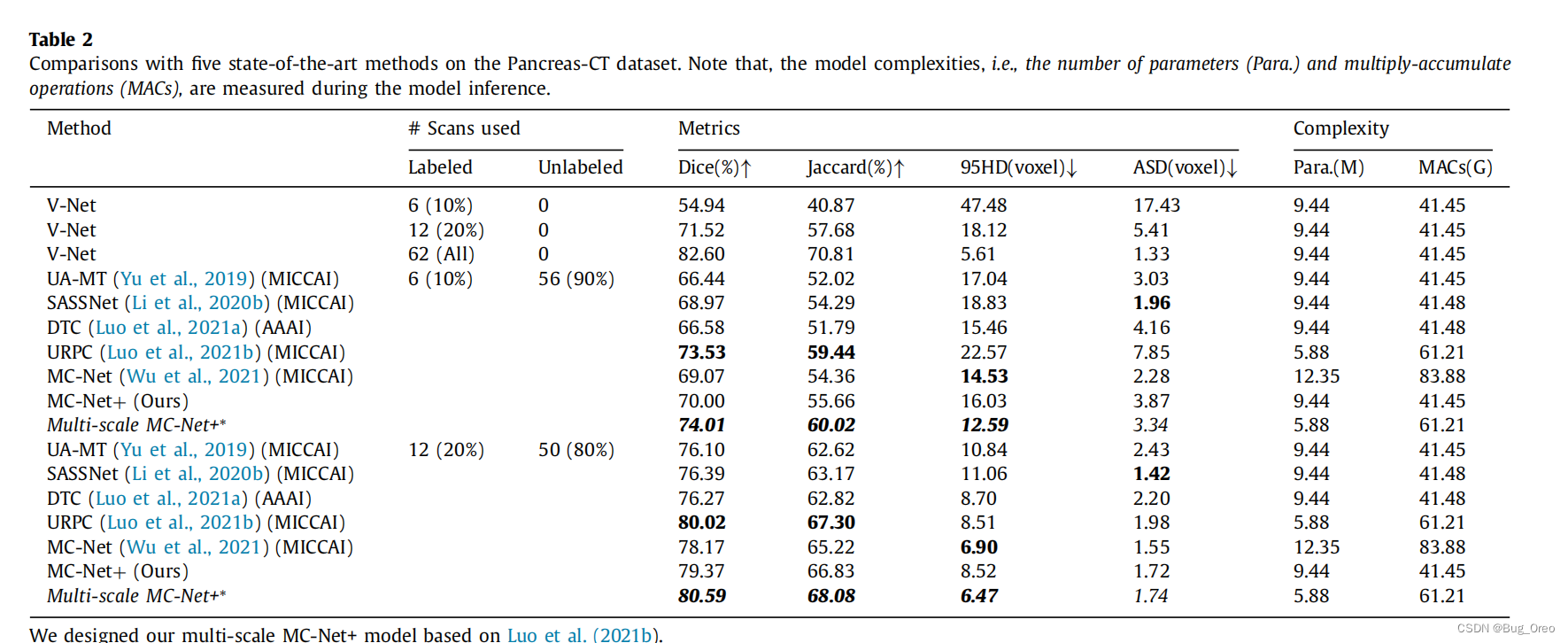
由于胰腺的分割是一项相对困难的任务,可能需要更多的多尺度信息,因此我们进一步依据Luo et al等人的论文设计了我们的 Multi-scale MC-Net+模型,也实现了在每个Pancreas-ct数据集设置中的最棒性能。这证明了模型MC-Net+模型可以与其它多尺度方法进行结合来进一步提高分割的性能。
7.3 在ACDC数据集上的性能
我们进一步把我们的模型拓展到了2D多类别分割的任务中。在下表中的结果是三个分割目标的平均性能。
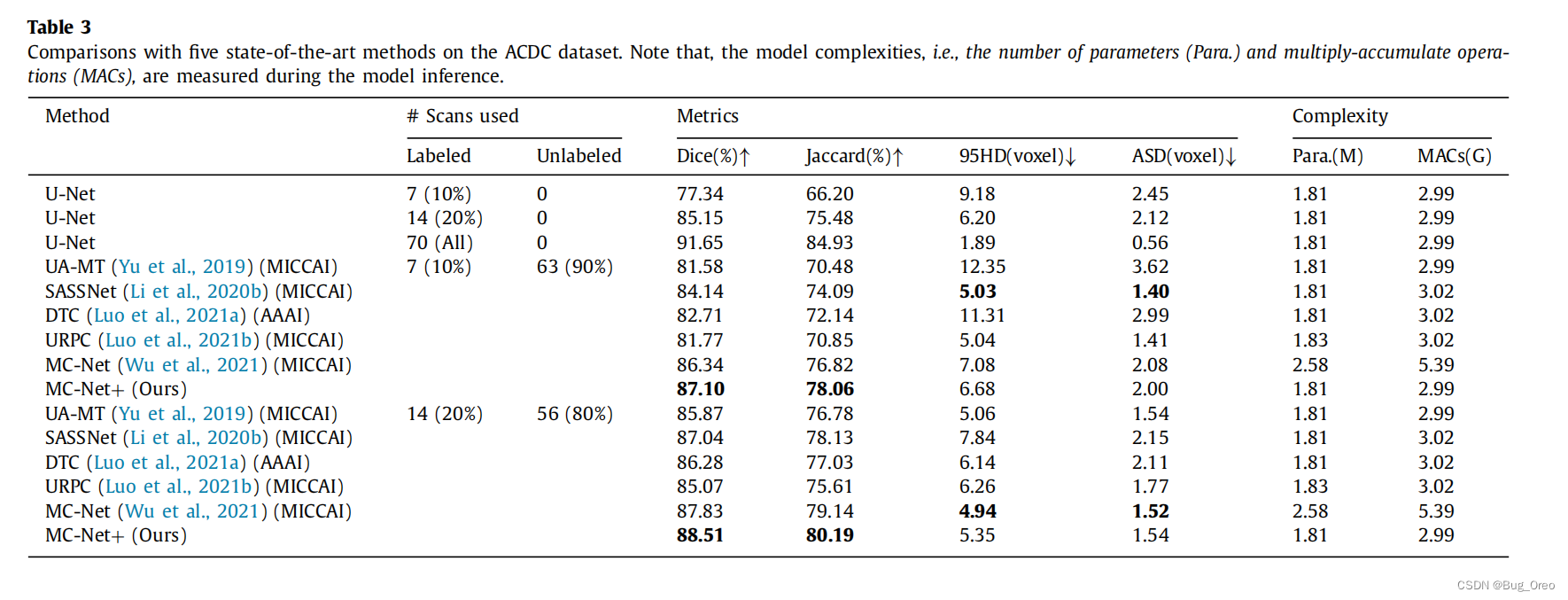
如表所示,证明了相比于其他方法,我们的模型在每个半监督的设置下都获得了最高的DICE得分,Jaccard得分以及与全监督相类似的性能表现。此外,我们的模型在10%或20%的标记数据的训练设置下比全监督的U-Net模型,产生了约10%(87.10-77.34)和3%(88.51-85.15)的平均DICE增益。
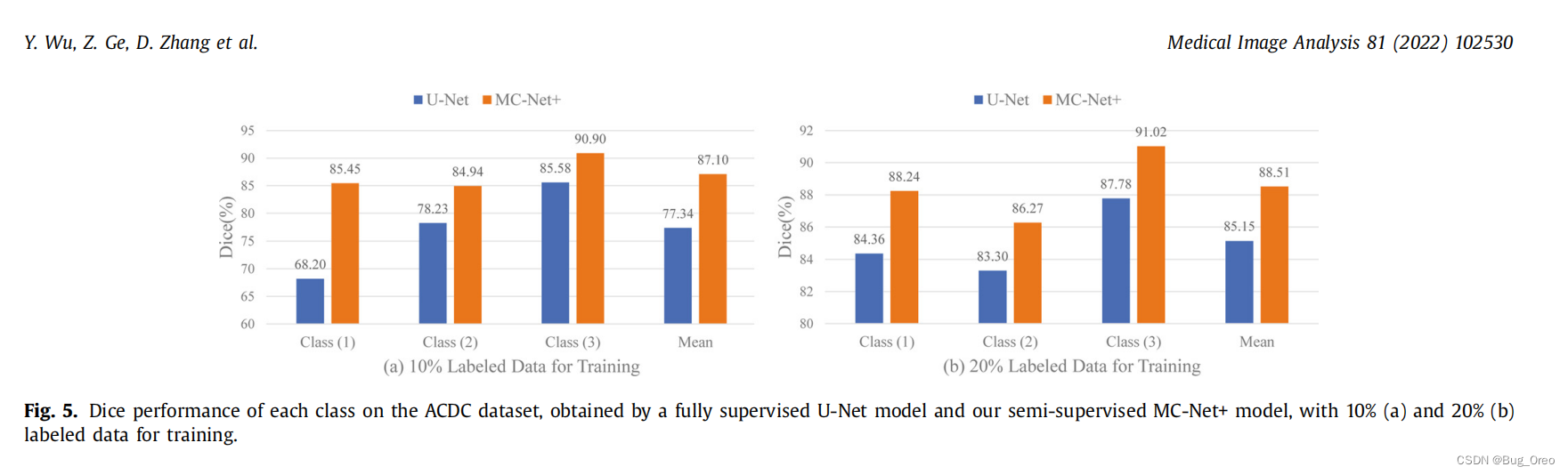
如上图所示,无论是10%或者20%的标注数据用于训练, 我们的模型都能在2D医学图像分割任务的每个类中实现性能的增加。
8、 讨论
8.1 消融实验
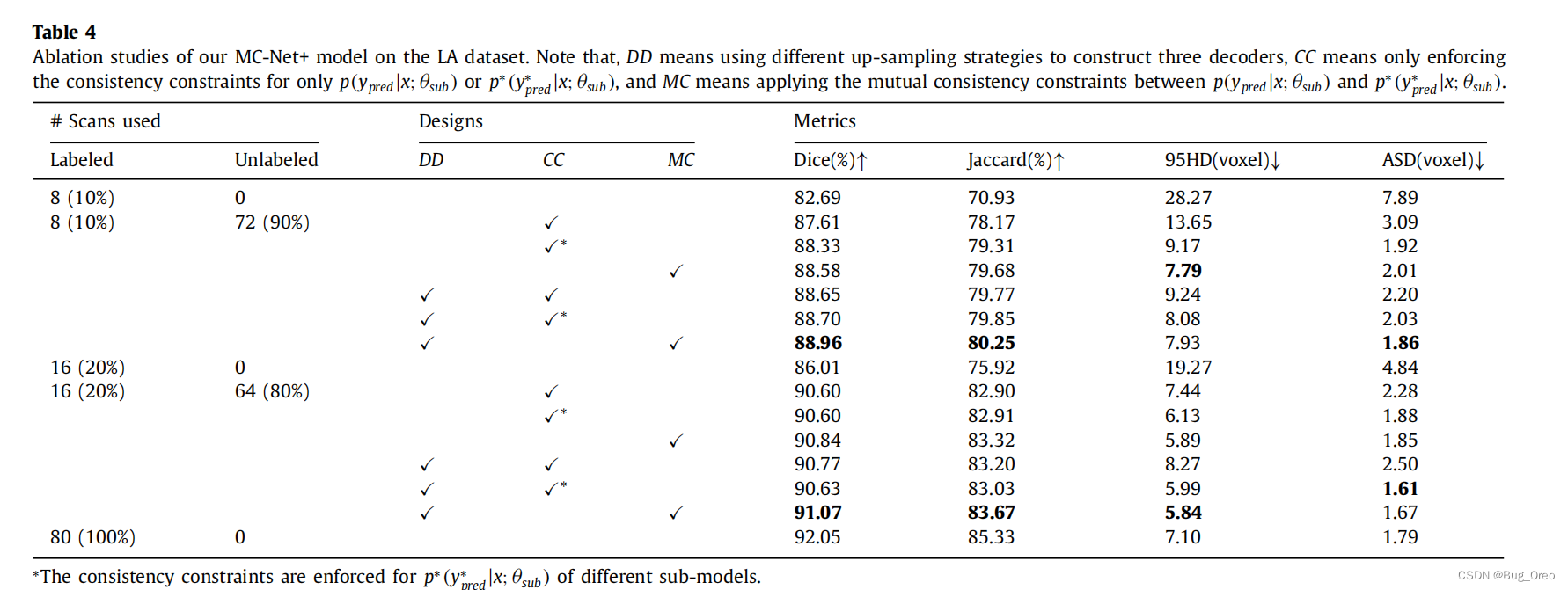
消融实验是在LA数据集上进行的,结果表明,用10%或20%的标记数据进行训练,(1)通过强迫三个解码器产生相似的结果,获得了显著的性能增益,Dice得分分别增加了5.28%和4.59%。 (2)DD导致了结果平均Dice收益分别为0.63%和0.13%。(3)由MC标记的训练相互一致性总是比CC标记的一致性约束的概率输出结果好。此外,在最后一行还提供了完全监督的MC-Net+模型,即没有Lmc进行训练,作为参考。
8.2 上采样策略不同的影响
等后续代码复现再进一步完善。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









