






一、文章来源
论文全名:Local contrastive loss with pseudo-label based self-training for
semi-supervised medical image segmentation
论文源码地址: https://github.com/krishnabits001/pseudo_label_contrastive_
training

二、 代码记录
先看ReadMe部分:
在图中第三部分的数据集下载中,值得注意的是下载完数据集之后要根据N4_bias_correction.py与create_cropped_imgs.py进行相应的数据预处理。
以ACDC数据集为例,ACDC数据集中的结构信息如下:测试集中包含50个病患信息,training训练集中包含100个病患信息。
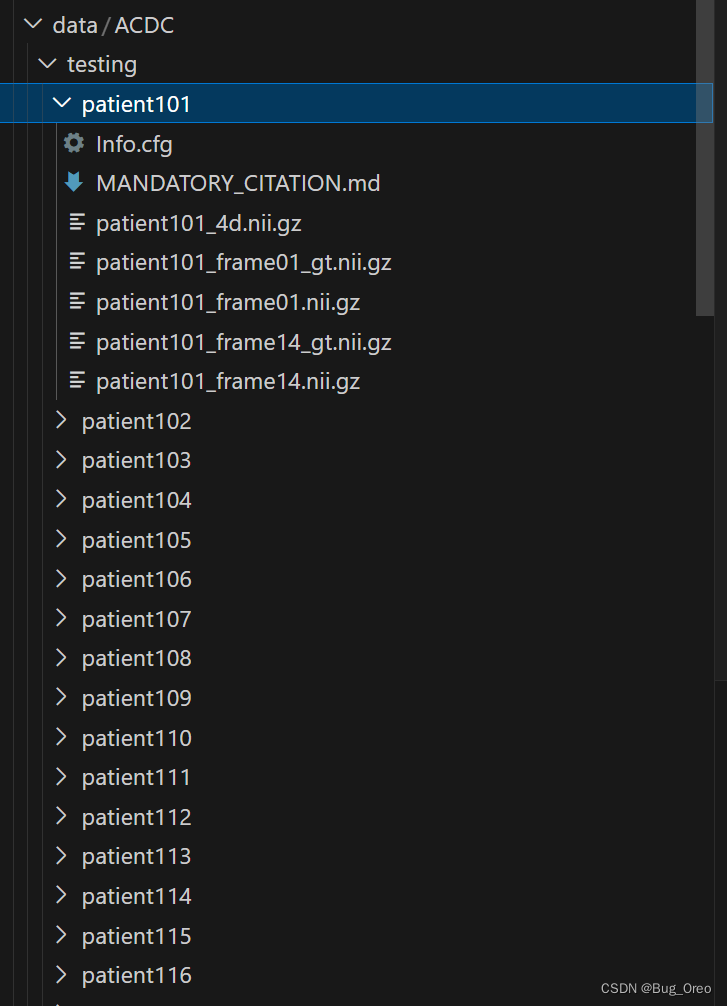
Info.cfg:表示3D图像的基本信息
_4d.nii.gz:表示的是该病患所有的切片信息
_frame01.nii.gz与_frame01_gt.nii.gz: 表示的是该病患某一时期的nii与其对应的GT label
_frame14.nii.gz与_frame14_gt.nii.gz: 表示的是该病患另一时期的nii与其对应的GT label
N4偏差矫正.
我们首先看源代码scripts文件夹下用N4算法进行了偏差校正的N4_bias_correction.py文件,
# To perform N4 Bias Correction on input image
import numpy as np
import SimpleITK as sitk
import sys
import os
# parameters for ACDC
threshold_value = 0.001
n_fitting_levels = 4
n_iters = 50
# Input and output image path
in_file_name='<input_path>/img.nii.gz'
out_file_name='<output_path>/img_bias_corr.nii.gz'
# Read the image
inputImage = sitk.ReadImage(in_file_name)
inputImage = sitk.Cast(inputImage, sitk.sitkFloat32)
# Apply N4 bias correction
corrector = sitk.N4BiasFieldCorrectionImageFilter()
corrector.SetConvergenceThreshold(threshold_value)
corrector.SetMaximumNumberOfIterations([int(n_iters)] * n_fitting_levels)
#Save the bias corrected output file
output = corrector.Execute(inputImage)
sitk.WriteImage(output, out_file_name)
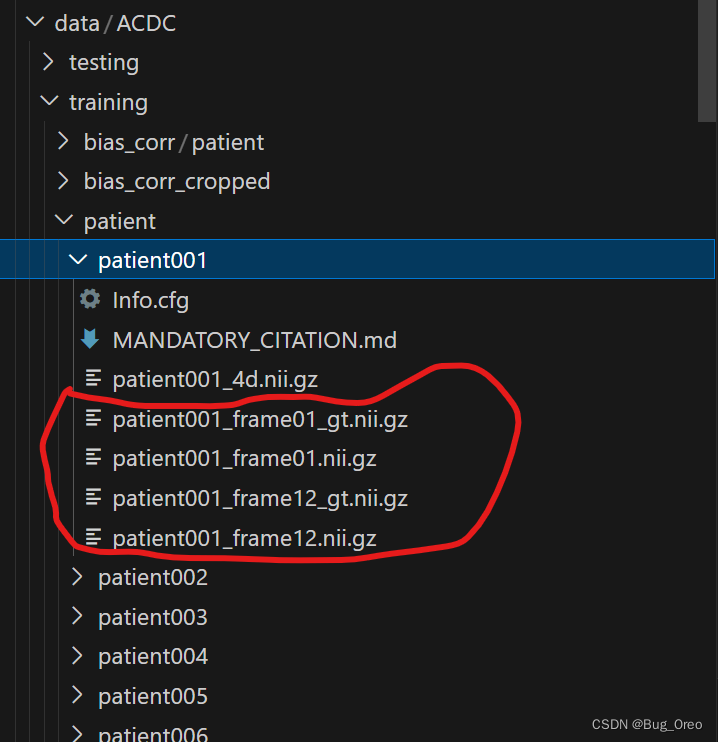
我们发现该文件只给出了单次处理.nii图像的代码,而未给出批次处理.nii文件的方法,因此我们需要自己实现循环来实现批次处理,并保存到相应的文件夹下。[PS:以patient101为例, 我们只处理patient101_frame01.nii.gz,patient101_frame01_gt.nii.gz 与 patient101_frame14.nii.gz, patient101_frame14_gt.nii.gz, 而不处理4d文件]。
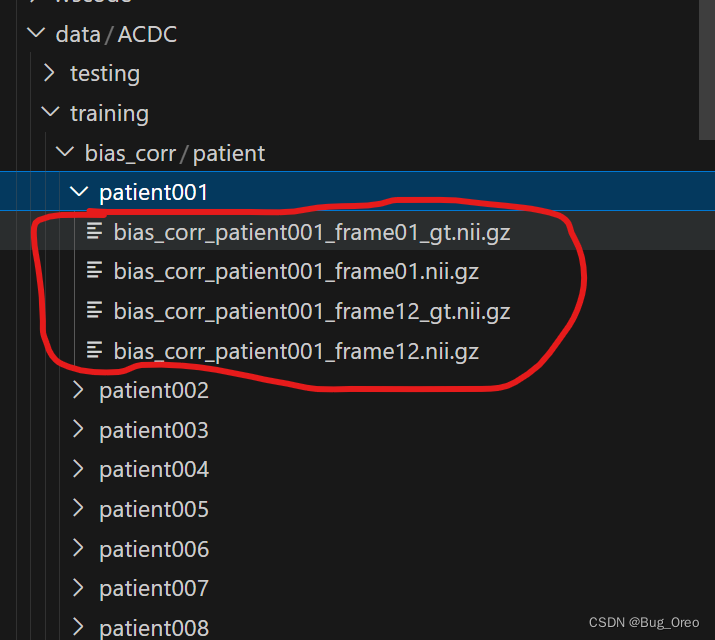
下面给出自己实现的代码,功能是将patient001文件夹中patient001_frame01.nii.gz,patient001_frame01_gt.nii.gz 与 patient001_frame12.nii.gz,patient001_frame12_gt.nii.gz处理后的.nii.gz图像保存在 training/bias_corr/patient/patient001文件夹中。
import os
import SimpleITK as sitk
# N4 Bias Correction参数
threshold_value = 0.001
n_fitting_levels = 4
n_iters = 50
def n4_bias_correction(input_image, output_path):
"""
对给定的输入图像进行N4偏置校正, 并保存校正后的图像。
"""
# 转换图像数据类型
input_image = sitk.Cast(input_image, sitk.sitkFloat32)
# 应用N4偏置校正
corrector = sitk.N4BiasFieldCorrectionImageFilter()
corrector.SetConvergenceThreshold(threshold_value)
corrector.SetMaximumNumberOfIterations([int(n_iters)] * n_fitting_levels)
output_image = corrector.Execute(input_image)
# 保存校正后的图像
sitk.WriteImage(output_image, output_path)
def process_directory(root_dir, output_dir):
"""
处理指定目录下的所有.nii.gz文件。
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for dirpath, dirnames, filenames in os.walk(root_dir):
for filename in filenames:
if filename.endswith('.nii.gz') and 'frame' in filename :
input_path = os.path.join(dirpath, filename)
output_dir_save = os.path.join(output_dir, filename.split('_')[0])
if not os.path.exists(output_dir_save):
os.makedirs(output_dir_save)
output_path = os.path.join(output_dir_save, f'bias_corr_{filename}')
print(f'Processing {input_path}...')
# 读取图像
input_image = sitk.ReadImage(input_path)
# 进行N4偏置校正
n4_bias_correction(input_image, output_path)
print(f'Saved to {output_path}')
# 设置输入和输出目录路径
input_dir = 'pseudo_label_contrastive_training/data/ACDC/training/patient'
output_dir = 'pseudo_label_contrastive_training/data/ACDC/training/bias_corr/patient'
# 处理目录中的文件
process_directory(input_dir, output_dir)剪切图像.
随后我们再进入数据预处理之将N4偏差矫正后的图像剪切到target_size,本文还是以ACDC数据集中的training set为例进行记录。
首先我们进入scripts/create_cropped_imgs.py文件中观察到这么一行代码, 我们要把其中的字符串进行相应的替换。
import sys
sys.path.append("<path_to_git_code>/git_code")本人理解是再这个py文件中 存在这类代码,而这类代码与scripts/create_cropped_imgs.py不存在于统一目录下,因此要在系统路径下添加相关路径,从而保证下面的导入模块代码不进行报错。
import experiment_init.init_acdc as cfg
import experiment_init.data_cfg_acdc as data_list以我的项目文件目录为例,大家可以自行修改。
因此我修改的代码如下:
import sys
sys.path.append("pseudo_label_contrastive_training/")除此之外,我们还要额外注意在create_cropped_imgs.py中起到关键作用的cfg变量是由这行代码引入的。因此我们也要进入experiment_init/init_acdc.py中一探究竟。
import experiment_init.init_acdc as cfginit_acdc.py原生部分路径代码如下,其它代码都是超参数的一些数值以及输出图片的大小等数据:
#base directory of the code
base_dir='/usr/bmicnas01/data-biwi-01/krishnch/projects/self_tr/pseudo_label_cont_lr/test_run/'
srt_dir='/usr/bmicnas01/data-biwi-01/krishnch/projects/self_tr/pseudo_label_cont_lr/test_run/'
#Path to data in original dimensions in default resolution
data_path_tr='/usr/bmicnas01/data-biwi-01/krishnch/datasets/heart_acdc/acdc_bias_corr/patient'
#Path to data in cropped dimensions in target resolution (saved apriori)
data_path_tr_cropped='/usr/bmicnas01/data-biwi-01/krishnch/datasets/heart_acdc/acdc_bias_corr_cropped/patient'先看第一部分:该路径我目前没搞太明白,但不影响图像的剪裁等操作,因此未作修改,若有大佬明白,还望不吝分享。
第二部分:其实就是放由 N4偏差矫正预处理过的图片数据的路径,以及将偏差矫正过的图片再经过剪裁处理后的图片存放路径。
按照本人工作目录的情况,我修改这两个路径如下:
#Path to data in original dimensions in default resolution
data_path_tr='pseudo_label_contrastive_training/data/ACDC/training/bias_corr/patient'
#Path to data in cropped dimensions in target resolution (saved apriori)
data_path_tr_cropped='pseudo_label_contrastive_training/data/ACDC/training/bias_corr_cropped/patient'按照N4偏差矫正处理之后,将处理后的数据都存放在了这个目录下。
而对于将偏差矫正过的图片再经过剪裁处理后的图片存放路径如下图所示:
由于自己存放文件路径信息的不同,因此对原生 create_cropped_imgs.py文件中的相关路径语句也做了对应的修改,如下:
file_path=str(cfg.data_path_tr)+'/patient'+str(test_id)+'/bias_corr_'+'patient'+str(test_id)+'_frame01.nii.gz'
mask_path=str(cfg.data_path_tr)+'/patient'+str(test_id)+'/bias_corr_'+'patient'+str(test_id)+'_frame01_gt.nii.gz' #保存 cropped image &/mask的路径
save_dir_tmp=str(cfg.data_path_tr_cropped)+'/patient'+str(test_id)+'/'剪切图像的完整代码如下(仅对ACDC数据部分做了修改):
# script to crop the images into the target resolution and save them.
import numpy as np
import pathlib
import nibabel as nib
import os.path
from os import path
import sys
sys.path.append("pseudo_label_contrastive_training/")
import argparse
parser = argparse.ArgumentParser()
#data set type
parser.add_argument('--dataset', type=str, default='acdc', choices=['acdc','prostate_md'])
parse_config = parser.parse_args()
#parse_config = parser.parse_args(args=[])
if parse_config.dataset == 'acdc':
print('load acdc configs')
import experiment_init.init_acdc as cfg
import experiment_init.data_cfg_acdc as data_list
elif parse_config.dataset == 'prostate_md':
print('load prostate_md configs')
import experiment_init.init_prostate_md as cfg
import experiment_init.data_cfg_prostate_md as data_list
else:
raise ValueError(parse_config.dataset)
######################################
# class loaders
# ####################################
# load dataloader object
from dataloaders import dataloaderObj
dt = dataloaderObj(cfg)
if parse_config.dataset == 'acdc' :
#print('set acdc orig img dataloader handle')
orig_img_dt=dt.load_acdc_imgs
start_id,end_id=1,101
elif parse_config.dataset == 'prostate_md':
#print('set prostate_md orig img dataloader handle')
orig_img_dt=dt.load_prostate_imgs_md
start_id,end_id=0,48
# For loop to go over all available images
for index in range(start_id,end_id):
if(index<10):
test_id='00'+str(index)
elif(index<100):
test_id='0'+str(index)
else:
test_id=str(index)
test_id_l=[test_id]
if parse_config.dataset == 'acdc' :
file_path=str(cfg.data_path_tr)+'/patient'+str(test_id)+'/bias_corr_'+'patient'+str(test_id)+'_frame01.nii.gz'
mask_path=str(cfg.data_path_tr)+'/patient'+str(test_id)+'/bias_corr_'+'patient'+str(test_id)+'_frame01_gt.nii.gz'
elif parse_config.dataset == 'prostate_md':
file_path=str(cfg.data_path_tr)+str(test_id)+'/img.nii.gz'
mask_path=str(cfg.data_path_tr)+str(test_id)+'/mask.nii.gz'
#check if image file exists
if(path.exists(file_path)):
print('crop',test_id)
else:
print('continue',test_id)
continue
#check if mask exists
if(path.exists(mask_path)):
# Load the image &/mask
img_sys,label_sys,pixel_size,affine_tst= orig_img_dt(test_id_l,ret_affine=1,label_present=1)
# Crop the loaded image &/mask to target resolution
cropped_img_sys,cropped_mask_sys = dt.preprocess_data(img_sys, label_sys, pixel_size)
else:
# Load the image &/mask
img_sys,pixel_size,affine_tst= orig_img_dt(test_id_l,ret_affine=1,label_present=0)
#dummy mask with zeros
label_sys=np.zeros_like(img_sys)
# Crop the loaded image &/mask to target resolution
cropped_img_sys = dt.preprocess_data(img_sys, label_sys, pixel_size, label_present=0)
#保存 cropped image &/mask的路径
save_dir_tmp=str(cfg.data_path_tr_cropped)+'/patient'+str(test_id)+'/'
pathlib.Path(save_dir_tmp).mkdir(parents=True, exist_ok=True)
if (parse_config.dataset == 'acdc') :
affine_tst[0,0]=-cfg.target_resolution[0]
affine_tst[1,1]=-cfg.target_resolution[1]
elif (parse_config.dataset == 'prostate_md') :
affine_tst[0,0]=cfg.target_resolution[0]
affine_tst[1,1]=cfg.target_resolution[1]
#Save the cropped image &/mask
array_img = nib.Nifti1Image(cropped_img_sys, affine_tst)
pred_filename = str(save_dir_tmp)+'img_cropped.nii.gz'
nib.save(array_img, pred_filename)
if(path.exists(mask_path)):
array_mask = nib.Nifti1Image(cropped_mask_sys.astype(np.int16), affine_tst)
pred_filename = str(save_dir_tmp)+'mask_cropped.nii.gz'
nib.save(array_mask, pred_filename)
三、问题记录
报错一:.img_sys,label_sys,pixel_size,affine_tst= orig_img_dt(test_id_l,ret_affine=1,label_present=1)
nibabel.deprecator.ExpiredDeprecationError: get_data() is deprecated in favor of get_fdata(), which has a more predictable return type. To obtain get_data() behavior going forward, use numpy.asanyarray(img.dataobj).描述:该问题是在dataloaders.py中的load_acdc_imgs()方法中出现的,这是由于依赖库版本不同造成的问题。
解决:直接将get_data()-->get_fdata()即可

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









