






引用是C++ 的一个别名机制,所谓别名,就是同一块内存共用多个名字,每个名字都指的是这片空间,通过这些别名都能访问到同样的一块空间。
就像鲁迅和周树人是同一个人。
——鲁迅
一、引用的基本用法
int a = 10;
int& ref = a; // ref 是 a 的引用
ref = 20; // 这也会改变 a 的值
std::cout << a; // 输出 20需要注意的是,这里定义的引用变量ref并不会在内存上开辟新的空间,而是给a对应的那片空间取了一个新的名字,现在通过ref也能访问到那片空间了。
`&`符号我们不会陌生,在之前他的名字是取地址符,在C++中它还有新的作用:定义引用。
在使用中,主要有这两个区别和联系:
1.定义引用时:`&`在类型之后,表示该变量是引用。
int& ref = a;2. 获取地址时:`&`在变量前边, 表示获取该变量的地址。
int* ptr = &a;二、引用的特点
- 必须初始化:引用在声明时必须进行初始化。
int& a; //错误的!! - 不可重新绑定:初始化后不能再指向其他变量。
int a = 0; int b = 0; int& ref = a; int& ref = b; //错误的!! - 类型一致:引用的类型必须与其引用的变量类型一致。
int a = 0; float& b = a; //错误的!! - 权限不能放大:在引用的过程中,权限可以平移,缩小,但不能放大
const int a = 0; int& b = a; //权限的放大 const int& b = a; //权限的平移 int c = 0; const int& d = c; //权限的缩小 - 多个别名:一个变量可以有多个引用。
int a = 0; int& ref1 = a; int& ref2 = a; - 没有独立空间:在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间(在底层实现上实际是有空间的,因为引用是按照指针方式来实现的)
int a = 0; int& ref = a;
- 没有“二级引用”、没有“空引用”
int a = 0; int& ref1 = NULL; //错误的!! int&& ref2 = a; //错误的!!
三、引用的作用
以前的交换函数我们只能通过传递参数的指针来实现,而有了引用,我们可以通过给要交换的参数取别名的方式来实现:
#include<iostream>
using namespace std;
void swap(int& a, int& b)
{
int t = a;
a = b;
b = t;
}
int main()
{
int i = 6, j = 2;
swap(i, j);
cout << i << endl;
cout << j << endl;
return 0;
}i,j是实参,a,b是形参,且由于我们在形参类型后加了`&`,也就是说定义了a,b分别是i,j的别名,现在a,b分别代表i,j的那片空间了,所以在交换函数中我们可以通过直接交换a,b的值来交换i,j的值, 从而实现了实参传给形参,形参的改变可以改变实参的功能。
再来看一个顺序表的例子,这是没有引用前我们的写法:
struct SeqList
{
int a[100];
int size;
int capacity;
};
//C实现的写法
int SLFind(struct SeqList* p, int i)
{
// ... ...
return p->a[i];
}
void SLModify(struct SeqList* p, int i, int x)
{
p->a[i] = x;
}
int main()
{
struct SeqList s;
// ... ...
SLFind(&s, 0);
SLModify(&s, 0, 1);
}要实现查找和修改这两个功能,我们分别需要`SLFind`和`SLModify` 两个函数来实现,而且需要传递顺序表结构的指针才能进行对值的修改。、
而有了引用,首先我们可以优化参数的传递:改为定义引用来接收实参,从而达到修改形参实现修改实参的功能。其次我们还可以优化程序,用一个函数就能实现修改与查找的功能:
struct SeqList
{
int a[100];
int size;
int capacity;
};
//CPP实现的接口
int& SLFind(struct SeqList& p, int i)
{
// ... ...
return p.a[i]; // 返回引用,允许对顺序表元素进行修改
}
int main()
{
struct SeqList s;
// ... ...
SLFind(s, 0) = 1; //Modify
cout << SLFind(s, 0) << endl; //Find
}
在上面这段代码中,我们发现引用也可以作为返回值,但其实这一作用在某些情况下是不安全的,可以看下面这个例子:
int& add(int a, int b)
{
int n = a + b;
return n; //返回n的别名
}
int main()
{
int rst = add(1, 2);
cout << rst << endl;
return 0;
}这段代码的输出值是多少? 是3吗?
这段代码其实存在一个严重安全的问题:add函数返回的是局部变量 n 的引用。在 add 函数执行完毕后,局部变量 n 的生命周期结束,其内存被释放,返回的引用将指向一个已经释放的内存位置。这就像指针里我们提到的野指针。所以,具体输出的值取决于编译器,如果内存释放后编译器将这部分内存置为随机值,那么输出的值就是一个随机值。
如果改成这样呢?
int& add(int a, int b)
{
int n = a + b;
return n; //返回n的别名
}
int main()
{
int& rst = add(1, 2);
cout << rst << endl;
cout << rst << endl;
return 0;
}在上一段代码是将 n 的值拷贝给 rst, 输出的 rst 取决于 存放 n 的那片内存有没有被置为随机值。
而现在变成了 rst 是 n 别名,两次打印 rst 的值可能是不同的,原因:
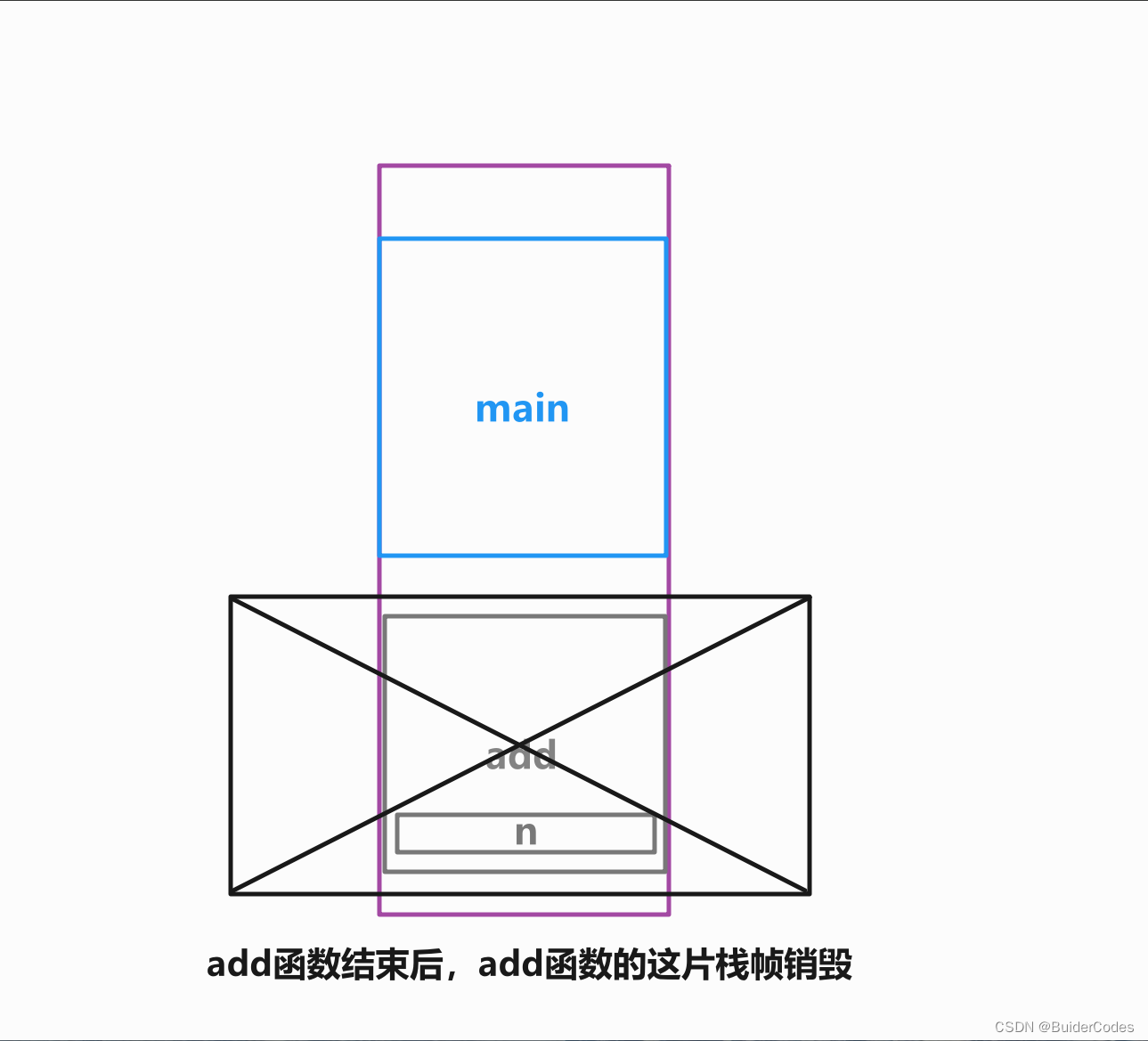
接下来调用 cout 函数,新建立的栈帧在原来的 add 的那片空间中
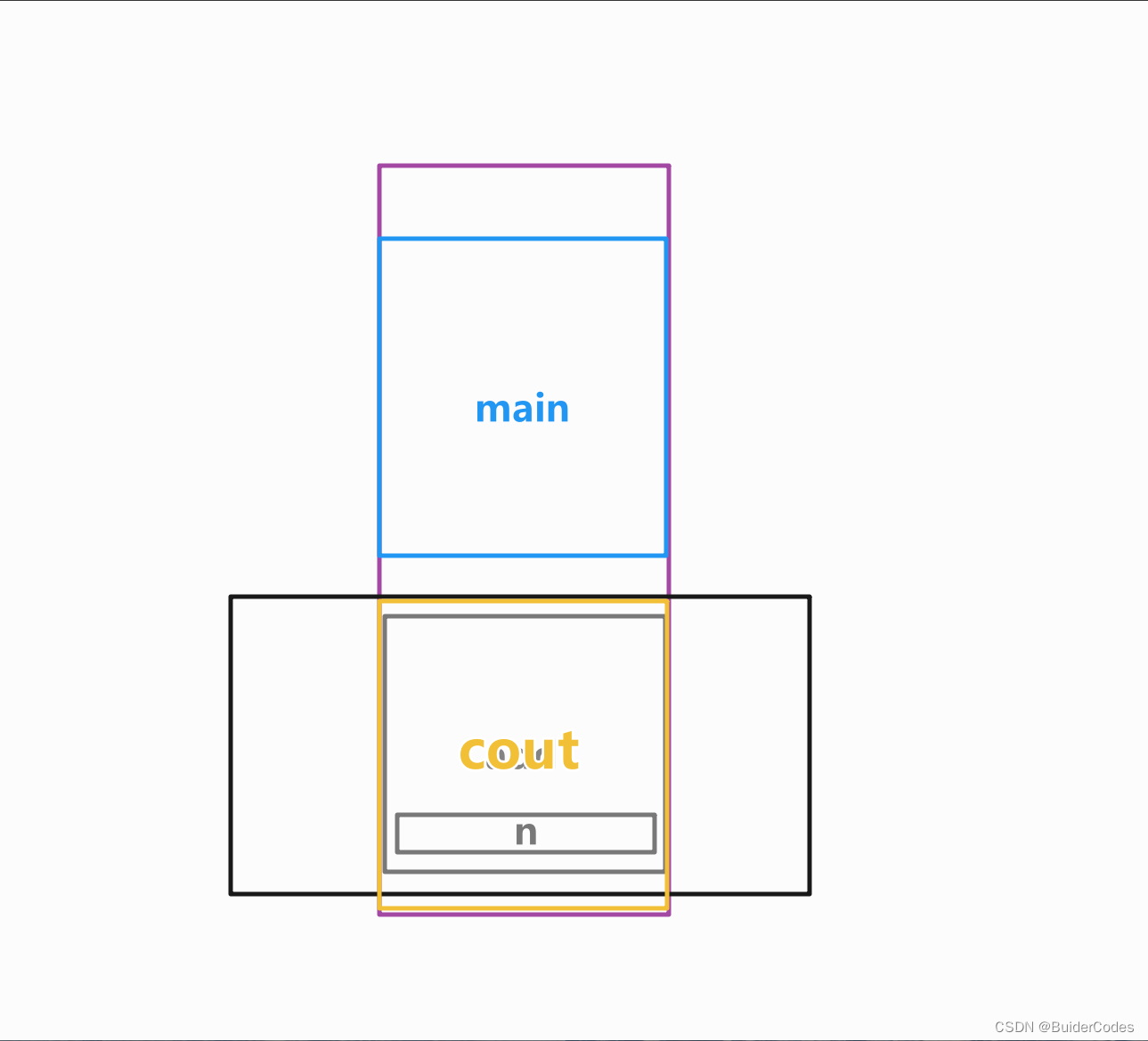
由于调用前 n 的值首先被压入栈帧,所以第一次能够成功读取到 n 的值,但第二次输出的值就是不确定的了,因为 cout 可能会覆盖到存放 n 的值的那片空间(这取决于cout所需要的栈帧空间),如果覆盖到了,那么第二次调用 cout 打印 n 的值就是随机数了。
综上所述,引用的作用有:
- 函数参数传递:避免拷贝,提高效率。尤其是对于传递较大的结构体时,效率的提升是显著的;
- 实现实参传给形参,形参的改变可以改变实参;
- 引用作为返回值:通过返回引用,可以在函数外部修改函数内部的变量。同时避免返回值的拷贝,从而提高性能,尤其是在返回大型对象时效果显著。
注意,引用必须绑定有效对象:函数返回引用时,必须确保返回的引用绑定到一个有效的对象。避免返回局部变量的引用,因为局部变量在函数结束时会被销毁。















 1213
1213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









