









现如今,图像生成技术发展迅猛,离不开计算机视觉和机器学习领域的进步,特别是深度学习技术的兴起——2010年代初期,深度学习在图像识别和分类任务中取得了突破性进展,为图像生成提供了技术基础。2014年,“GANs之父”Ian Goodfellow等人提出了生成对抗网络(GANs),这是一种强大的图像生成模型,能够生成逼真的图像,从而推动了图像生成技术的发展...
越来越多的人开始关注和探索各种图像生成模型。本次,我们精选10个开源图像生成项目,帮助大家更深入地了解这一领域的技术,启发进一步探索和研究。
FLUX.1
FLUX.1是由Stability AI原班人马跳槽后新成立团队Black Forest Lab推出的开源AI图像生成模型。FLUX.1发布不久就在图像生成领域掀起巨大风浪,持续霸榜Hugging Face!
它拥有12B参数,是迄今为止最大的文生图模型之一。其团队表示FLUX.1在性能上大幅超越了DALL·E3、Midjourney V6等闭源模型,并且提供了Pro(专业版)、Dev(开发版)和Schnell(快速版)三个版本,以满足不同用户的需求。
FLUX.1 [Pro专业版] 高质量付费版本,适用于商业用途。它具有顶级的即时跟踪、视觉质量、图像细节和输出多样性。
FLUX.1 [Dev开发版] 原始20步开源版本。是一种开放权重、指导提炼模型,适用于非商业应用。
FLUX.1 [Schnell快速版]可免费使用。是为本地开发和个人使用量身定制。
Pro版开源地址:https://replicate.com/black-forest-labs/flux-pro
Dev版GitHub地址:https://github.com/black-forest-labs/flux
Schnell版开源地址:black-forest-labs/flux-schnell – Run with an API on Replicate

Stable Diffusion 3
Stable Diffusion 3(简称SD3)是由Stability AI开发的最新一代文本到图像生成模型,它在图像质量、文本内容生成、复杂提示理解和资源效率方面有显著提升,是目前全球最强大的文生图模型之一。
它支持多主题提示,参数量从800M到8B 不等,支持手机、电脑等便携式设备使用,大大降低AI大模型的使用门槛。
Hugging Face地址:
https://huggingface.co/stabilityai/stable-diffusion-3-medium

Pix2Pix
Pix2Pix是一种条件生成对抗网络,由Phillip Isola等人提出,用于图像到图像的翻译任务。它能够实现从输入图像到输出图像的一对一映射,常用于图像到图像的转换任务,例如将黑白图像转换为彩色图像、从草图生成照片等。
Pix2Pix模型使用了基于U-Net的生成器和PatchGAN分类器作为判别器。这项技术非特定于应用,具有很好的通用性,能够处理多种类型的图像转换任务。
NVIDIA官方提供的高清版本pix2pixHD知名度较高,其GitHub地址:https://github.com/NVIDIA/pix2pixHD
GigaGAN-PyTorch
GigaGAN-PyTorch是由Adobe提出的GigaGAN算法的PyTorch实现,提供了从低分辨率到高分辨率图像转换的能力,尤其在文本引导的图像合成方面表现出色。这个项目不仅支持无条件图像生成,还包括了用于训练Unet上采样的功能,能够将低分辨率图片转化为高分辨率版本。
核心亮点是其1k到4k的上采样器,它能够实现从低分辨率到高清晰度的无缝转换。此外,该项目还应用了可微分的图像翻转等不同类型的增强策略,进一步提升了模型的性能。
GitHub地址:https://github.com/lucidrains/gigagan-pytorch

Final2x
Final2x是一款开源的图片放大工具,它支持多种模型,能够帮助用户提高图像的分辨率和质量。该软件界面简洁,易于上手,并且支持Windows、macOS、Linux系统。可以直接在本地使用,无需联网,还支持批量处理功能,可以同时处理多张图片。此外,它还支持自定义图像放大倍数,实现更精细的超分辨率效果 。
Final2x 支持的模型包括 RealCUGAN、RealESRGAN、Waifu2x 等,可以根据不同的需求选择最适合的模型来使用。
GitHub地址:https://github.com/Tohrusky/Final2x/

Stable Fast 3D
Stable Fast 3D是由Stability AI推出的模型,可以在0.5秒内将单张图片迅速转换为高质量的3D模型。这项技术特别适合游戏和虚拟现实开发者,以及零售、建筑、设计等图形密集型专业人士使用。
Stable Fast 3D建立在TripoSR的基础上,通过改进的Transformer网络预测更高分辨率的三平面,减少采样伪影,并处理物体的反射特性和光照解纠缠问题,输出无阴影的均匀物体。此外,它还通过网格提取和细化预测顶点偏移和表面法线,得到更平滑的输出形状,并通过快速UV展开和导出模块生成低多边形网格和高分辨率纹理。
GitHub地址:https://github.com/Stability-AI/stable-fast-3d

Grounding DINO
Stable Video 4D (简称SV4D) - 同样是Stability AI 推出的AI模型,专为动态多角度视频生成而设计。这项技术可以将单个对象视频转换成八个不同角度或视图的新视图视频,为游戏开发、视频编辑和虚拟现实等领域带来新的应用前景和创造力。
与以往的方法相比,Stable Video 4D 不需要从图像扩散模型、视频扩散模型和多视图扩散模型的组合中进行采样,而是能够同时生成多个新视图视频,大大提高了空间和时间轴上的一致性

CogVideo
CogVideo是由智谱AI推出的AI视频生成模型,能够将任意文字或图片生成视频,具有快速生成视频的能力。CogVideoX系列模型的第一个模型CogVideoX-2B已经开源(拥有20亿参数),与智谱AI的视频生成产品“清影”同源。
CogVideoX-2B模型特点包括:
在FP-16精度下进行推理时,仅需18GB的显存;单张NVIDIA RTX 4090显卡即可进行推理;微调模型只需要40GB的显存,单张NVIDIA A6000显卡即可完成。
此外,这个模型的一些规格如下:提示词上限为226个token;视频长度为6秒;帧率为8帧/秒;视频分辨率为720×480。
GitHub地址:https://github.com/THUDM/CogVideo

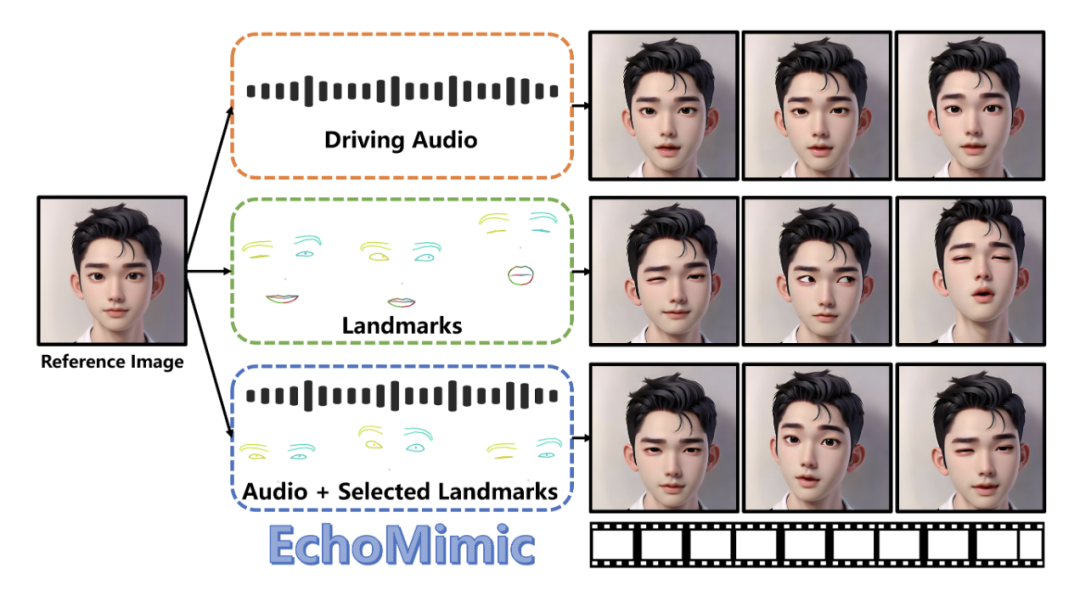
EchoMimic
EchoMimic - 由阿里蚂蚁集团推出的AI数字人开源项目,能够将静态图像赋予生动的语音和表情。它支持音频同步动画和面部特征融合,适用于多种语言和场景。
EchoMimic主要有以下几个特点:
口型同步生成:能根据音频和面部照片,创造出口型动作与语音完美匹配的视频。
自然逼真:它会融合音频和面部特征,生成的面部动画看起来很符合真实的面部运动和表情变化。
多语言支持:不仅支持普通话,还能处理英语和歌唱等多种语言和风格。
GitHub地址:https://github.com/BadToBest/EchoMimic
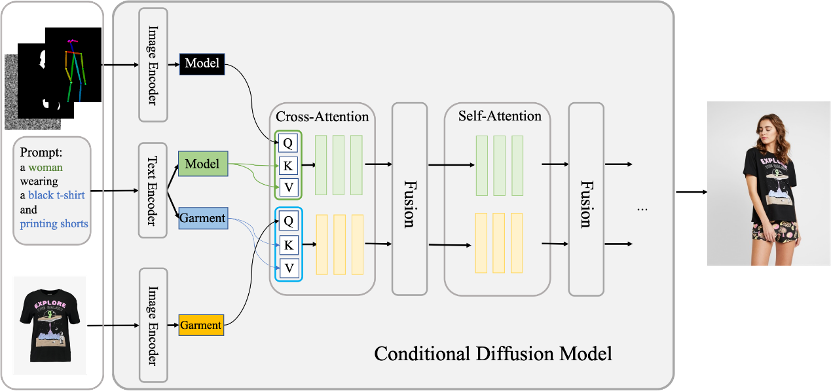
Outfit Anyone
Outfit Anyone是由阿里巴巴智能计算研究院推出的一个高质量服装虚拟试穿项目,它利用双流条件扩散模型,通过处理模特、服装和文本提示,实现逼真的虚拟试穿效果。
通过这项技术,用户可以上传服饰的平铺图来生成服装在模特身上的试穿效果,而无需亲自试穿衣服。且该系统支持上下装的组合搭配,并能够适应不同体型的模特,提供个性化的试穿体验。
GitHub地址:https://github.com/HumanAIGC/OutfitAnyone
算力领取:
BuluAI是一个创新型的算力云平台,算力使用灵活,可为开发者提供强大计算资源和全面支持,帮助BuluAI的使用者能够更专注于技术、应用的研究和优化。
BuluAI算力平台预计9月上线内测,扫码添加客服,可申请获得内测名额,期间算力免费试用!















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









