







2019年5月28日晚上8点40
对之前内容一个零碎的后续
书中尝试了一组参数为 隐藏层神经元30个,学习迭代期为30,小批量数据大小为10,学习速率η=3.0的网络
识别率的峰值为95.42%,但是我们要注意的是我们在一直按照这组参数做实验训练网络也不一定能得到相同的结果,因为我们使用的是随即权重和偏置来初始化我们的网络,后面的训练过程就可能会有所出入。
之后我们再吃尝试隐藏层神经元数量为100个,其余参数不变,这样最后的结果提升到了96.59%。只是从这两组实验相比,我们可以认为更多的隐藏层神经元可以使得网络有更好的结果。
在之后我们尝试调整了我们的学习效率η=0.001,我们得到的结果是
第1次迭代 1139/10000
第2次迭代 1136/10000
第3次迭代 1135/10000
。。。
第28次迭代 2101/10000
第29次迭代 2123/10000
第30次迭代 2142/10000
看上去效果并不十分理想,但是我们也可以看出,随着迭代次数的增加,是别的效果也逐渐变好了。这表明我们应该增大我们的学习效率。可以尝试η=1.0或者之前实验的参数3.0。
我们继续尝试再增大啊=学习效率η=100.0。我们得到了以下的结果
第1次迭代 1009/10000
第2次迭代 1009/10000
第3次迭代 1009/10000
。。。
第28次迭代 982/10000
第29次迭代 982/10000
第30次迭代 982/10000
这样看效果也不理想,我们的的学习效率太高了。但是如果我们第一次如果遇到这种问题,并不意味着这就是因为学习效率的问题,我们应当想到,我们是否使用到了难以学习的初始化权重和偏置?没有足够的数据进行有意义的学习?没有使用足够的迭代期?网络的结构不适合解决当前的问题。这些都是值得我们思考的。
反向传播算法
下面书中介绍了一种快速计算梯度的算法——反向传播算法。
首先给出网络中权重的清晰定义,
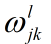
表示从第(l-1)层的第k个神经元到第l层的第j个神经元的连接上的权重
我们用第l层的第j个神经元的激活值表示为
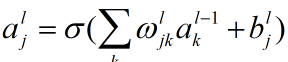
对于上面的公式我们有个简洁的向量形式,如下:
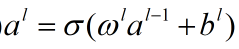
其中各个向量从左到右分别表示第l层的激活值(输出),第l层的权重向量,第(l-1)层的激活值(输入),第l层的偏置向量。σ函数又被称作向量化函数。
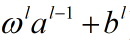
上面的公式是σ函数的一部分,这部分也可以称作第l层神经元的带权输出。
下面说一下关于代价函数的两个假设
反向传播的目的就是计算代价函数C的关于权重ω和偏置b的偏导数
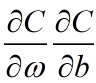
我们复习一下二次代价函数的形式:
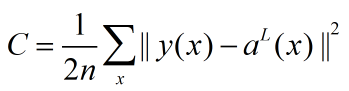
n为训练样本的数量,求和运算遍历了每一个训练样本x,y=y(x)是对应的目标输出;L表示网络的层数,aL(x)为输入为x时网络输出的激活值向量。
第一个假设就是:代价函数可以被写成一个在每个训练样本x上的代价函数Cx的均值
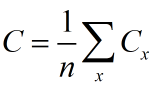
其中

第二个假设就是代价可以写成神功网络输出的函数:
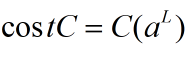
因为
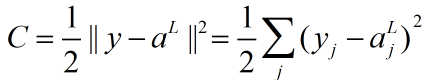
这是输出的激活值函数,也是一个依赖于目标输出y的函数。















 3324
3324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









