







 文章介绍了一种基于改进TLD算法的车辆跟踪方法,通过集成SRCKF滤波器和FREAK特征,增强了跟踪器的鲁棒性。实验在OTB-50和TLD数据集上进行评估,尽管存在一些问题,如实时性和有效性证明不足,但文章提供了一些有价值的技术细节。
文章介绍了一种基于改进TLD算法的车辆跟踪方法,通过集成SRCKF滤波器和FREAK特征,增强了跟踪器的鲁棒性。实验在OTB-50和TLD数据集上进行评估,尽管存在一些问题,如实时性和有效性证明不足,但文章提供了一些有价值的技术细节。
“Moving vehicle tracking based on improved tracking–learning–detection algorithm”
2019年 期刊 IET Computer Vision 计算机科学4区
基于改进后的TLD算法(ITLD,improved TLD)对车辆进行long-term单目标跟踪。
改进内容:
-
将平方根容积卡尔曼滤波器(SRCKF,square root cubature Kalman filter)集成到中值流跟踪器中,其实就是代替了median-flow法来执行跟踪。
-
跟踪器引入快速视网膜关键点(FREAK,fast retina keypoint)特征,缓解目标尺度变化和旋转带来的不稳定性,提高跟踪器的鲁棒性。
- 首先,对于第 t t t和 t − 1 t-1 t−1帧,获取FREAK特征 s i = ( p i , d i ) s_i=(p_i,d_i) si=(pi,di),其中, p i p_i pi是特征点的位置, d i d_i di是特征点的描述算子。
- 使用FLANN算法基于FREAK描述符从帧 t − 1 t-1 t−1向帧 t t t之间寻找最近邻匹配点。为了提高匹配的准确性,算法采用双向匹配策略(反过来,即从 t t t帧向 t − 1 t-1 t−1帧),只有当一个匹配对在这两个方向上都被确认时,才被认为是有效的匹配。
- 通过RANSAC算法移除掉错误的匹配点。
-
在整合模块中采用重叠比较和归一化互相关系数(NCC)来提高精度(这个感觉可以参考):
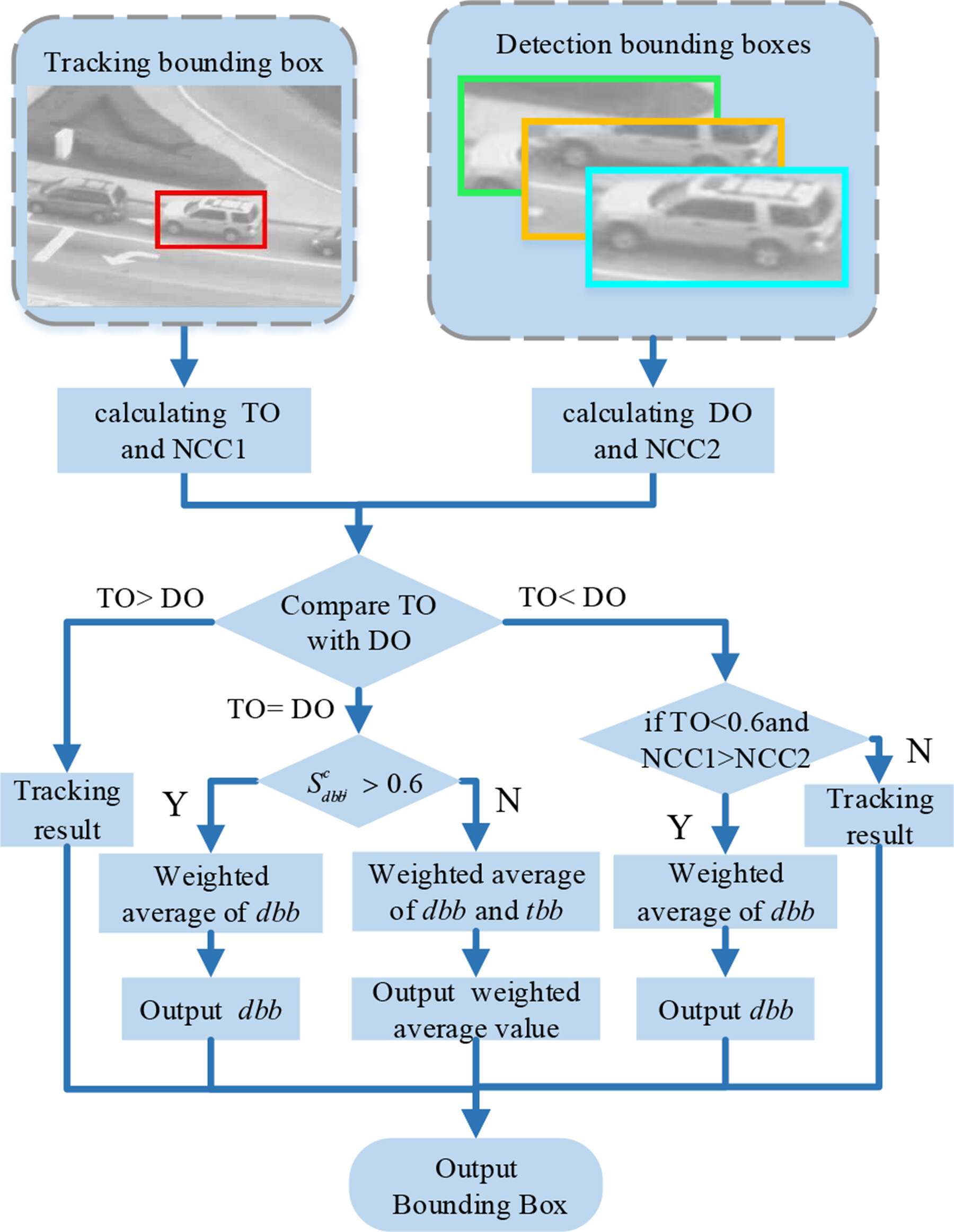
实验环节
- 基于OTB-50和TLD数据集(这是哪里来的?)中具有挑战性的视频来评估所提出的算法。
- 评价指标:精确度(CLE=20),成功率(IOU=0.5)
感想:一篇普通的改进文章,作者同样也发现了整合模块存在的问题。尽管其提出了改进方式,但是并没有足够的消融实验来证明这种改进的有效性(只给了一张曲线图,和在十一个视频序列上的测试性能)。除此之外,算法的实时性进一步降低。使用FREAK特征点来替代原始跟踪点这个思路很不错。
“Deep visual tracking: Review and experimental comparison”
2018年 期刊 PATTERN RECOGNITION 计算机科学1区
Online视觉跟踪跟踪器的组成:
运动模型(描述对象随时间的状态并预测其可能的状态)+观测模型(描述跟踪目标的外观信息并验证每帧的预测),有研究表明观测模型是更重要的。
对于观测模型,可以进一步分为生成式(基于模板来搜索目标)和判别式(训练一个分类器来区分目标和背景)。
视觉跟踪器分类:回顾了现有的基于DL的目标跟踪算法。并根据网络结构、网络功能和网络训练来分类现有的深度视觉跟踪器:
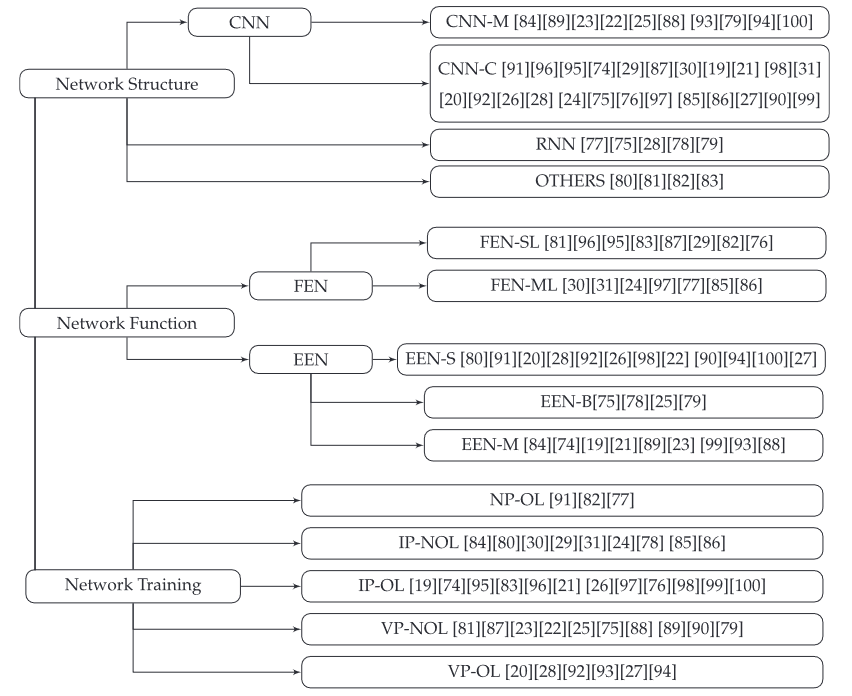
-
网络结构:即视觉跟踪器所使用的深度神经网络的种类,可以分为基于CNN(适合特征提取)、基于RNN(能记住时序信息,适合序列建模)和基于其它网络的跟踪器。
- 基于CNN:可以被进一步分为CNN-C(判别式)和CNN-M(生成式)
- 基于RNN:
- 基于其它网络:
-
网络功能:所使用DNN在所提出的跟踪系统中的作用,主要分为特征提取(FEN,仅利用深度网络提取深层特征,然后采用传统方法定位目标)和端到端(EEN,不仅使用深度网络进行特征提取,还用于候选评估。EEN方法的输出可以是概率图、热力图、候选得分、对象位置甚至直接bounding box)。
-
网络训练:训练DNN所使用的方法。分为NP-OL、IP-NOL、IP-OL、VP-NOL、VP-OL。
跟踪实验:在OTB100、TC-128和VOT2015数据集上进行了实验评估。
- OTB100:20像素距离为阈值的精确度和0.5交并比为阈值的成功率。
- TC-128:评估指标和OTB100相同。
- VOT2015:提供了重新初始化协议,即,如果观察到跟踪失败,则在评估过程中使用ground truth重置跟踪器。使用准确性-鲁棒性(AR)图和预期平均overlap(EAO)来衡量算法的性能。
结论:
- CNN模型的使用可以显着提高跟踪性能,而使用CNN模型进行模板匹配通常速度更快(CNN-C比CNN-M的精度更高,但是CNN-M更快)。
- 具有深层特征的跟踪器比具有低级手工特征的跟踪器表现更好。
- 来自不同卷积层的深层特征具有不同的特征,它们的有效组合通常会产生更鲁棒的跟踪器。
- 使用端到端网络的深度视觉跟踪器通常比仅使用特征提取网络的跟踪器表现更好。
- 对于视觉跟踪,最合适的网络训练方法是用视频信息对网络进行预训练,并通过后续观察对其进行在线微调。
感想:偏概念性的基础文章。
“Automated MV markerless tumor tracking for VMAT”
2020年 期刊 PHYSICS IN MEDICINE AND BIOLOGY 医学3区核医学3区生物医学3区
基于MV射线成像,应用适应性模板匹配方法,实现了在VMAT治疗期间对肺部肿瘤的无标记跟踪,该算法不需要训练。
MV(兆伏级)和KV(千伏级)射线的主要区别在于它们的能量水平,这影响了它们在医疗成像和治疗中的应用。MV射线因其深穿透力而主要用于放射治疗,特别是深部肿瘤的治疗,而KV射线则主要用于诊断成像。
跟踪算法步骤:
- 首先应用盒式滤波器对图像进行滤波平滑,以减少噪点,然后通过自适应阈值算法来区分前景和背景(Aperture Masking)
- 通过局部方差过滤器计算局部区域的局部方差(局部方差高的区域意味着该区域内像素值变化大)以作为纹理特征。之后,计算每个区域的自相关性(没提到是怎么计算的),然后根据纹理值和自相关值对纹理特征(局部区域)进行排序。
- 在每个确定要跟踪的特征(局部区域)周围生成一组模板(21×21像素),构成一个模板集群,每个集群的模板数量为7。
- 跟踪:
- 首先,计算每个模板与当前图像的NCC(归一化交叉互相关),从而确定新的模板位置(其实就是滑动模板,然后计算NCC值,NCC值最大的地方就作为新的模板位置,NCC的计算可以参考:NCC归一化互相关(详解))。
- 将最大NCC值小于0.5的模板和模板集群抛弃,同时抛弃静态模板(在5幅图像中每幅图像移动不超过一个像素的模板)。
- 相对位置分析:在预测模板的新位置前,每个模板集群的相对位置被记录下来从而生成一个矩阵。在完成位置预测后,对每个模板集群,检查各个模板的相对位置,并抛弃那些相对位置变化超过阈值(0.35像素)的模板,只保留仍然符合初始相对位置的模板。对于那些抛弃的模板,基于设置的score(结合了NCC、相对位置变化和模板的平均稳定性)进行重组,以检查被移除的模板是否可以再生成一个通过相对位置分析的子群。
- 模板更新:
- 只对具有高置信度值的特征(局部区域)的模板进行更新。
- 将当前图像中特征的相应子部分用于模板更新,即,将帮助确定匹配位置的模板替换为当前图像中的相同区域。
实验结果:对于体模数据,跟踪误差为1.34mm,对于patient data,跟踪误差为0.68mm。0.2秒处理一帧。
感想:感觉没啥好参考的,文中有一段提到了跟踪成功率比较低,不知道为什么后面又提高了,仔细看了一下也还没明白。模板匹配这个方法还是太老太简单了,很难做出花来,如果真基于扫描的思想,为什么不用SiameseFC网络之类的架构来跟踪呢?
“Real-time tumor tracking using fluoroscopic imaging with deep neural network analysis”
2019年 期刊 Physica Medica-European Journal of Medical Physics 医学3区核医学3区
本文提出了一种基于深度神经网络的markerless肿瘤实时跟踪方法。该方法基于4DCT(主要用于标记肿瘤的真实位置)和DRR数据(DRR是一种通过计算机从3D-CT数据集中生成的2D X射线图像,用于作为训练的全局图像),但其最终目标是应用于荧光成像数据上的实时肿瘤跟踪。
跟踪算法步骤:
训练
-
在DRR图像上设置ROI和目标概率图(TPM):从4D-DRR图像上,设置4个ROI(宽64像素,高128像素),ROI的中心坐标被设置为在图像中位移最大的位置(整个图像序列中每一帧位移之和最大的位置)。
之后,在DRR图像上的每个呼吸相位(每个呼吸相位对应于4DCT扫描中的某个特定时刻的图像帧)的肿瘤中心处定义目标概率图。目标概率图的大小和ROI一样,只是其中心为肿瘤中心。
-
准备训练数据:
-
应用数据增强技术,基于10个放疗CT数据集,生成了10000张训练图像。
-
DRR图像的像素值被归一化到[0,1]。
-
根据设定的ROI,从每张DRR中裁剪出对应的子图像,作为网络的训练输入。
-
根据肿瘤的中心位置和文中的公式2,计算出对应的TPM(矩阵),公式2如下所示:
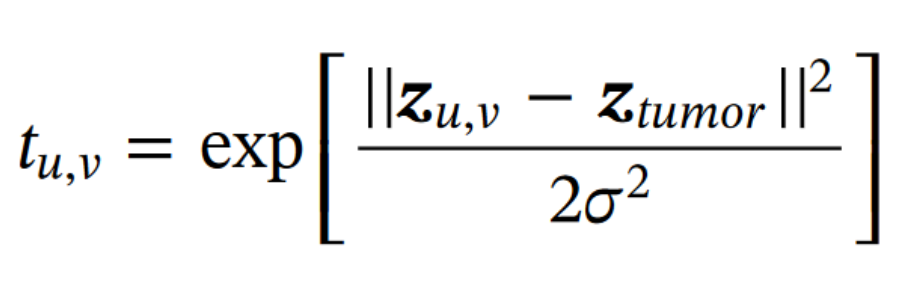
其中, z z z代表特征向量。为什么感觉公式2有问题,应该是越靠近中心的概率值越大啊?
-
-
模型训练:
-
loss function
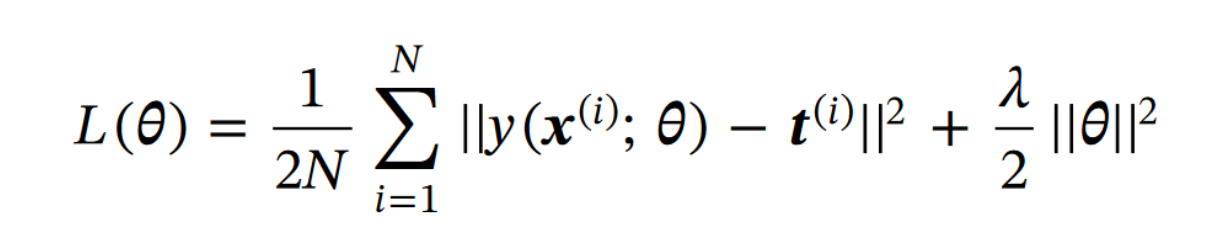
其中, θ \theta θ是需要训练的网络参数。 x ( i ) ∈ R W r × H r × N r x^{(i)}\in R^{W_r\times H_r\times N_r} x(i)∈RWr×Hr×Nr代表从第 i i i帧全局图像中裁剪得到的 N r N_r Nr张子图所组成的输入。 t ( i ) ∈ R W r × H r t^{(i)}\in R^{W_r\times H_r} t(i)∈RWr×Hr代表这帧图像中对应的TPM。
-
应用adam训练,使用xavier初始化,同时应用了dropout。
-
跟踪
- 子图像生成:
- 将DFPD生成的荧光图像的像素尺寸调整到和训练用的DRR图像相同,并对其像素值进行归一化处理。
- 基于ROI来裁剪生成作为输入的子图像,ROI和训练步骤中采用的ROI完全相同。
- 网络预测生成TPM
- 基于TPM计算出肿瘤的位置:
- 生成TPM:对每一张二维荧光图像,网络进行预测并生成一个TPM。这个TPM反映了肿瘤中心在各个位置的概率。
- 计算二维肿瘤中心:利用TPM的概率值和对应的像素位置,通过加权平均的方式计算出肿瘤在该二维荧光图像上的中心位置。
- 生成三维肿瘤中心:在实际的跟踪过程中,使用一对荧光图像(这两张图像通常是从不同角度拍摄的)按照上述步骤生成肿瘤在这两张荧光图像上的二维位置,结合荧光图像的相对角度和位置关系,推算出肿瘤在三维空间中的位置。
- 侧向纠正:考虑到呼吸引起的器官运动主要在上下(SI)方向,即ROI包含的图像变化主要与SI方向相关(也就是说预测出的TPM主要是SI方向的运动,而横向运动的预测不明显)。因此,通过线性回归模型(自变量为SI的位移,拟合目标为横向的位移)进行侧向纠正。
读完了整个算法的训练和实际运行过程,发现这个算法的主要思想就是确定好的ROI来生成一个TPM,TPM中的各个坐标对应的概率值代表了肿瘤中心在该位置的可能性。比较关键的一点在于,ROI是基于最大位移得到的,和ROI相同大小且基于肿瘤初始帧中心定义得到的TPM就一定能确保覆盖到整个跟踪期间肿瘤的所有可能位置。这也是为什么网络只需要预测一个大小小于全局图像的TPM就能够进行后续的跟踪步骤了。相当于这个方法应用了一定的先验信息。
除此之外,个人还是感觉文中给的公式2少了一个负号,不然按照公式2就是越靠近肿瘤中心的t值越低,应该是不对的,所以这里存疑。
网络结构
基于卷积自编码器实现,结构如下图所示:
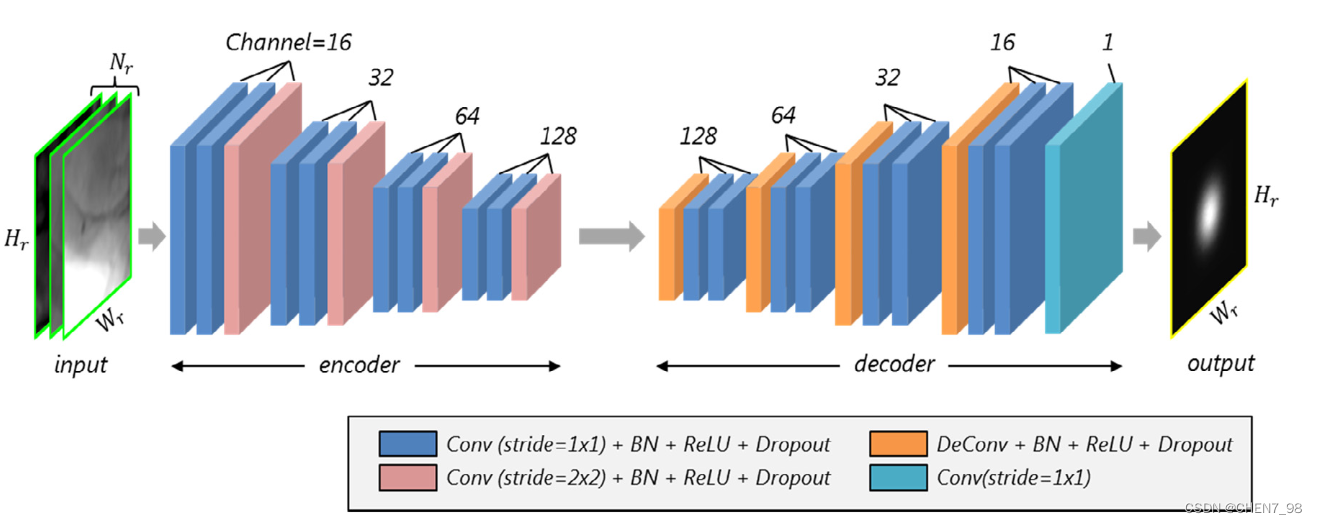
这也能解释为什么生成的不是直接的位置预测,而是一个TPM。
产生一个想法:假如我想实现端到端的肿瘤中心位置预测,是否可以像SiamFC网络一样,加入一个检测帧的分支,然后利用检测帧分支和CAE生成的TPM来预测出实际的肿瘤位置。
其它
- groundtruth确定:图像刚性配准+人工修改。
- 误差定义:预测中心和实际中心的欧氏距离。
实验结果
所有患者平均无校正的跟踪位置精度为2.18±0.89mm(95%CI:2.30mm)。通过应用侧向校正,这些值提高到1.64±0.73mm(95%CI:1.74mm)。侧向矫正(1.37±0.81mm)的肝脏病例的准确性优于肺部病例(1.90±0.65mm)。
所有患者平均使用一对DFPD进行肿瘤跟踪的计算时间为每帧39.8±3.7ms。
感想:首先,作者自己也在discussions部分提到了这个方法的缺陷,就是分次间变化会导致算法的跟踪精度降低(很直观,因为训练数据和实际测试数据的差异会变大)。文章的思路还是直观的,但是我个人觉得可以进一步改进以形成一个end-to-end的跟踪方法。一篇19年的文章,其应用了较多的后处理步骤,感觉不是很elegant。除此之外,相较于之前阅读的其它放疗场景下的目标跟踪方案,其对跟踪场景的设置已经相对接近通用的目标跟踪场景了。总体来说,有值得借鉴的地方。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









