




动手点关注

干货不迷路
1. 概述
本文将首先介绍 Spark AQE SkewedJoin 的基本原理以及字节跳动在使用 AQE SkewedJoin 的实践中遇到的一些问题;其次介绍针对遇到的问题所做的相关优化和功能增强,以及相关优化在字节跳动的收益;此外,我们还将分享 SkewedJoin 的使用经验。
2. 背景
首先对 Spark AQE SkewedJoin 做一个简单的介绍。Spark Adaptive Query Execution, 简称 Spark AQE,总体思想是动态优化和修改 stage 的物理执行计划。利用执行结束的上游 stage 的统计信息(主要是数据量和记录数),来优化下游 stage 的物理执行计划。
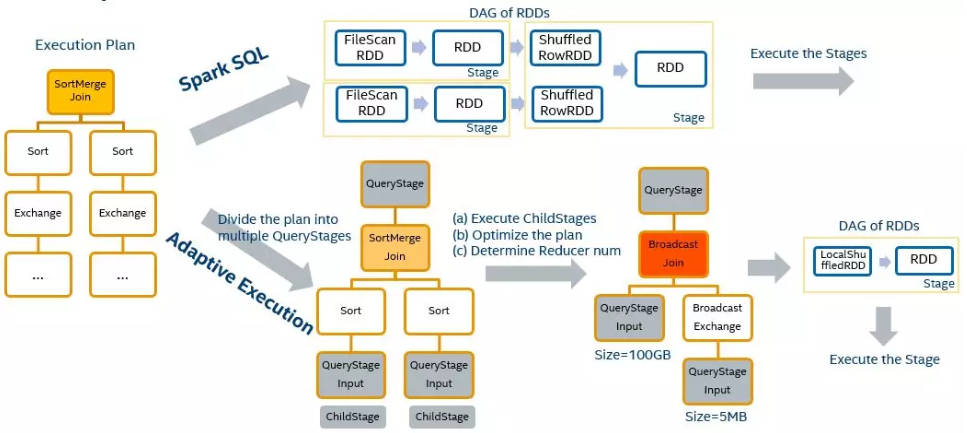
Spark AQE 能够在 stage 提交执行之前,根据上游 stage 的所有 MapTask 的统计信息,计算得到下游每个 ReduceTask 的 shuffle 输入,因此 Spark AQE 能够自动发现发生数据倾斜的 Join,并且做出优化处理,该功能就是 Spark AQE SkewedJoin。
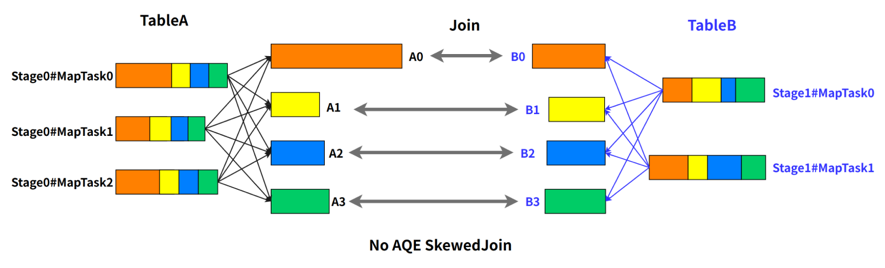
例如 A 表 inner join B 表,并且 A 表中第 0 个 partition(A0)是一个倾斜的 partition,正常情况下,A0 会和 B 表的第 0 个 partition(B0)发生 join,由于此时 A0 倾斜,task 0 就会成为长尾 task。
SkewedJoin 在执行 A Join B 之前,通过上游 stage 的统计信息,发现 partition A0 明显超过平均值的数倍,即判断 A Join B 发生了数据倾斜,且倾斜分区为 partition A0。Spark AQE 会将 A0 的数据拆成 N 份,使用 N 个 task 去处理该 partition,每个 task 只读取若干个 MapTask 的 shuffle 输出文件,如下图所示,A0-0 只会读取 Stage0#MapTask0 中属于 A0 的数据。这 N 个 Task 然后都读取 B 表 partition 0 的数据做 join。这 N 个 task 执行的结果和 A 表的 A0 join B0 的结果是等价的。
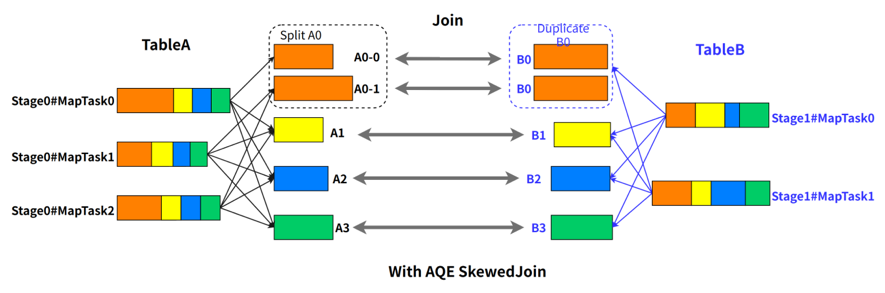
不难看出,在这样的处理中,B 表的 partition 0 会被读取 N 次,虽然这增加了一定的额外成本,但是通过 N 个任务处理倾斜数据带来的收益仍然大于这样的成本。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









