







TOPSIS 法:多属性决策的有效工具
在多属性决策分析领域,TOPSIS 法(Technique for Order Preference by Similarity to Ideal Solution)是一种广泛应用且极具价值的方法。它为解决复杂的决策问题提供了一种系统、科学的途径,尤其在面临多个评价对象和多个评价指标时,能够帮助决策者清晰地辨别各方案的优劣,从而做出更为合理的抉择。
一、TOPSIS 法的基本原理
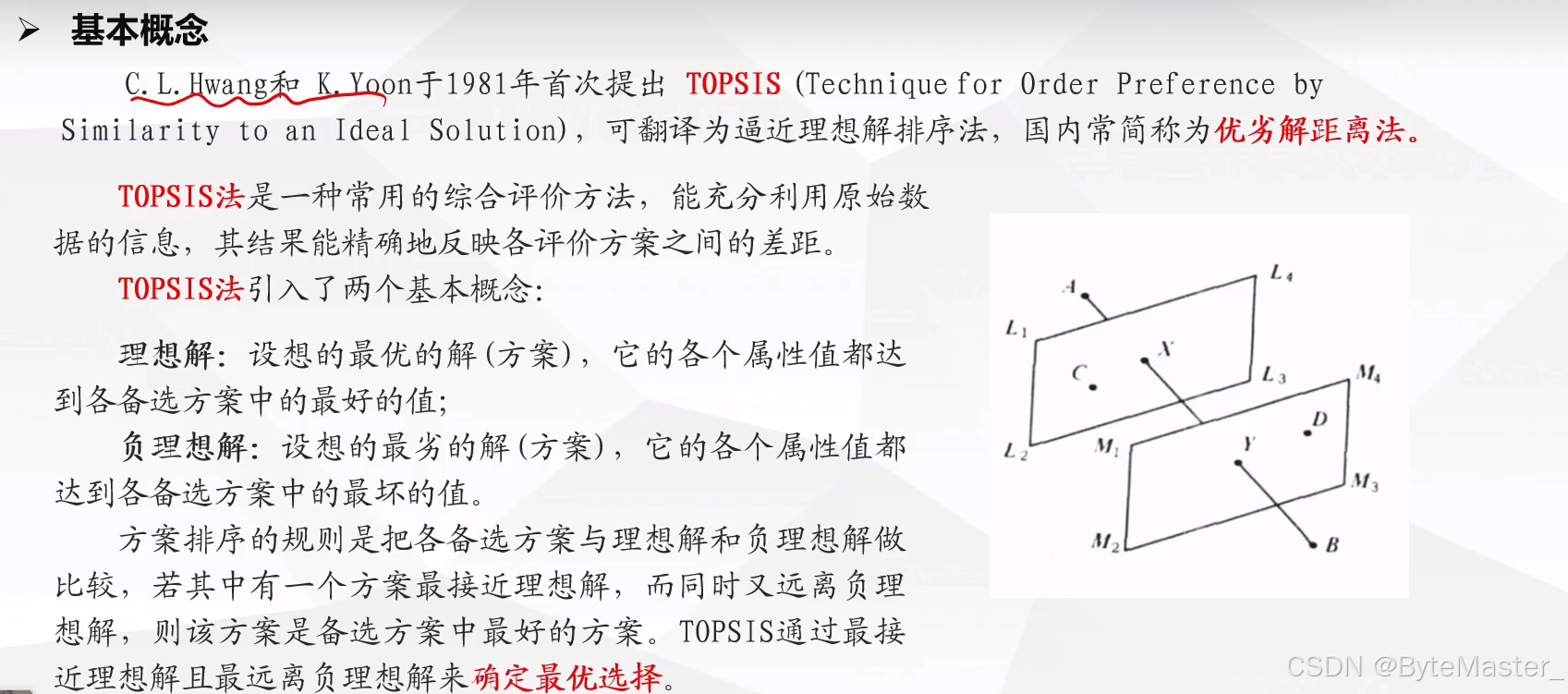
TOPSIS 法的核心思想是基于这样一种直观的概念:在多属性决策中,最优的方案应该是与理想解(正理想解)的距离最近,同时与负理想解的距离最远。所谓理想解,是在各个评价指标上都达到最优值的虚拟方案;而负理想解则是在各个评价指标上都处于最差值的虚拟方案。
具体而言,该方法首先需要构建规范化的决策矩阵。这一步骤旨在消除不同评价指标因量纲和数量级差异而带来的影响,使得各个指标能够在同一尺度上进行比较。例如,在对不同企业的绩效进行评价时,可能涉及到利润(以货币单位衡量)、市场份额(以百分比表示)、员工满意度(以得分表示)等多个指标,通过规范化处理,将它们转化为具有可比性的数值。
接着,确定正理想解和负理想解。正理想解是每个指标在所有方案中的最大值所构成的向量,负理想解则是每个指标在所有方案中的最小值所构成的向量。然后,计算每个方案到正理想解和负理想解的距离。这里的距离度量通常采用欧几里得距离或其他合适的距离公式。
最后,根据各方案到正理想解和负理想解的相对距离,计算每个方案的贴近度。贴近度越大的方案,表明其越接近正理想解,越远离负理想解,从而在多属性决策中越具有优势。通过对贴近度进行排序,即可确定各个方案的优劣顺序,为决策者提供清晰的决策依据。
二、TOPSIS 法的详细步骤

S i = D i − / ( D i + + D i − ) Si = Di^-/(Di^+ + Di^-) Si=Di−/(Di++Di−)
S i Si Si: 得分
D i − Di^- Di−: 与最小值距离
D i + Di^+ Di+: 与最大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7972
7972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









