






缓存是提高应用性能的重要手段之一,而 MySQL 和 Redis 是两种常用的数据存储和缓存技术。在许多应用中,常常将 Redis 用作缓存层,以加速对数据的访问。然而,在使用 MySQL 和 Redis 组合时,保持缓存与数据库之间的一致性是一个不得不考虑的问题。

一、缓存一致性的挑战
MySQL 和 Redis 之间的缓存一致性涉及到两个方面:
数据一致性
数据在 MySQL 和 Redis 中的一致性是指在对数据进行更新操作时,确保MySQL 和 Redis 中的数据保持同步。如果 Redis 中的缓存数据与 MySQL 数据库中的数据不一致,可能会导致应用程序出现错误以及一些未知的问题。
缓存有效性
缓存有效性是指 Redis 中的缓存数据是否仍然有效,是否需要更新或者过期。如果 Redis 中的缓存数据过期,但 MySQL 中的数据已经更新,可能会导致从 Redis 中获取到的数据不准确。
再说实现缓存与数据库数据一致性的实现方法之前,我们先来了解一下什么是缓存模式?
之前写过一篇关于缓存模式的文章,可以跳过去了解一下。
直接往下看也可以,我在这篇文章里面会重新对几种缓存模式进行一下介绍,并加以配图说明。
二、缓存模式有哪些
如果你读过上面缓存模式那篇文章的话,相信你对缓存模式应该有一定的了解了,如果不了解也没关系,我们一起来看看吧。
2.1、Cache Aside
最常用的缓存模式,大体意思是先从 cache 中取数据,没有获取到则从数据库中读取,成功后放到缓存中;
如果在 cache 中获取到数据直接返回;
更新时先把数据存到数据库,成功后再让缓存失效。

- 先更新数据库,再更新缓存
遇到的问题是两个并发的更新操作,数据库先更新的后更新缓存,数据库后更新的先更新缓存,这样就会造成数据库与缓存的数据不一致,应用程序中读取的数据都是脏数据
- 先删除缓存,再更新数据库
遇到的问题是有两个并发操作,一个更新操作先删除了缓存,此时另一个并发的读取操作没有命中缓存,直接读取数据库并更新回了缓存,这个时候正好更新操作完成数据更新。此时数据库和缓存的数据不一致,应用程序读取的数据都脏数据了
- 先更新数据库,再删除缓存
这个方式也算是我们实际系统使用中比较推荐的一种方式,但是这种方式在理论上还是可能会出现问题,两个并发操作,其中一个查询操作没有命中缓存,此时查询出来了数据库中的老数据,此时另一个并发的更新操作,在刚才的并发读操作之后更新了数据库中的数据并删除了缓存,然后并发读操作线程又把老数据写入了缓存,此时又造成了数据的不一致,应用程序读取的都是脏数据。因为这种概率差生的情况实在是太小,所以才是我们系统中经常使用的一种方式了。
2.2、Read/Write Through
Cache Aside 模式中,应用程序需要维护两个数据存储,一个是缓存,一个是数据库,在 Read/Write Through 更新模式中,应用程序只需要维护缓存,数据库的维护工作就有缓存代理了
2.2.1、Read Through
Read Through 模式就是在查询时更新缓存,也就是说,在缓存失效时,Cache Aside 模式是由调用方负责把数据载入缓存,而 Read Through 模式是缓存服务自己更新缓存,自己来加载数据。

当应用程序执行读操作时,如果缓存中不存在所需数据,则缓存会自动从数据源(如数据库)中读取数据,并将数据加载到缓存中,然后返回给应用程序。
Read-Through 策略减少了应用程序与数据源之间的直接交互次数,提高了读操作的性能和响应速度。
2.2.2 Write Through
Write Through 和 Read Through 类似,当数据更新时,如果命中缓存则更新缓存,然后缓存更新数据库,这是一个同步的操作;如果没有命中缓存,直接更新数据库返回。
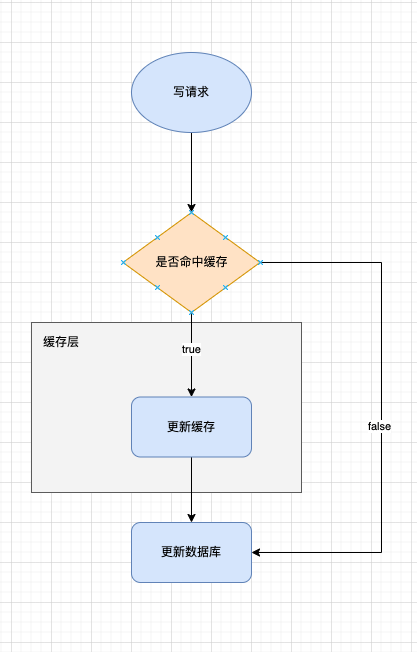
Write-Through 策略保证了缓存和数据源中的数据一致性,但由于每次写操作都需要等待数据源的确认,可能会影响写操作的性能和延迟。
2.3、 Write Behind Caching
Write Behind Caching 更新模式是在更新数据时只更新缓存,不更新数据库,而我们的缓存会异步的更新数据库。这个模式的话就是速度快,毕竟我们直接操作内存,因为是异步的,Write Behind Caching 更新模式还可以合并对同一个数据的多次操作到数据库,所以性能的提升也是很明显的
问题就是数据不是强一致性的,而且还可能会丢失,Write Behind Caching 更新模式实现逻辑复杂,因为它需要确认有哪些数据是被更新的,哪些数据是需要刷到持久层的数据库的。只有当缓存失效的时候才会把它真正的持久化起来。

Write-Behind 策略提高了写操作的性能和响应速度,但在写入缓存后,数据源中的数据可能会落后于缓存中的数据一段时间,存在一定的数据一致性风险。
三、一致性有哪些
说到一致性,我们应该想到的就是分布式系统中多个节点对看到的数据副本都保持一致的特性。换个说法就是,无论用户在哪个节点上执行操作,最终所有节点上的数据是相同的,且满足一定的约束条件。
在分布式系统中,实现一致性是很困难的,因为系统中的多个节点可能会因为网络延迟,节点故障或者其他的因素导致多个数据副本之间的状态不一致。为了实现分布式系统中的一致性,业界常用的算法和协议有 Paxos、Raft、ZAB。
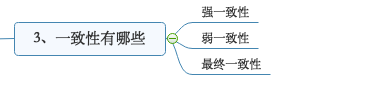
分布式系统的一致性又分为强一致性、弱一致性、最终一致性。
-
强一致性:最严格的一致性,相当于对于用户来说是最友好的。因为这个相当于系统写入的是什么数据,读取时也就是什么数据。
-
弱一致性:相比于强一致性,弱一致性不承诺立即读取最新的值,也不承诺多久之后数据一致。但是会尽可能的保证在到达某个时间点之后,数据达到一致状态。
-
最终一致性:最终一致性是弱一致性的一个特例,保证在一定时间之后达到数据一致状态,因此最终一致性也是目前业界来说最推崇的模型。
四、一致性实现方法
4.1、双写
双写其实就是 Write Through 模式,在写入 MySQL 数据库的同时,立即写入 Redis 缓存。这样可以确保 MySQL 和 Redis 中的数据保持一致,但增加了写入的延迟,并且增加了系统复杂度。
4.1.1、双写为什么先操作数据库在操作缓存?
我们来看如下的例子,线程A 与 线程B 是一组并发请求。
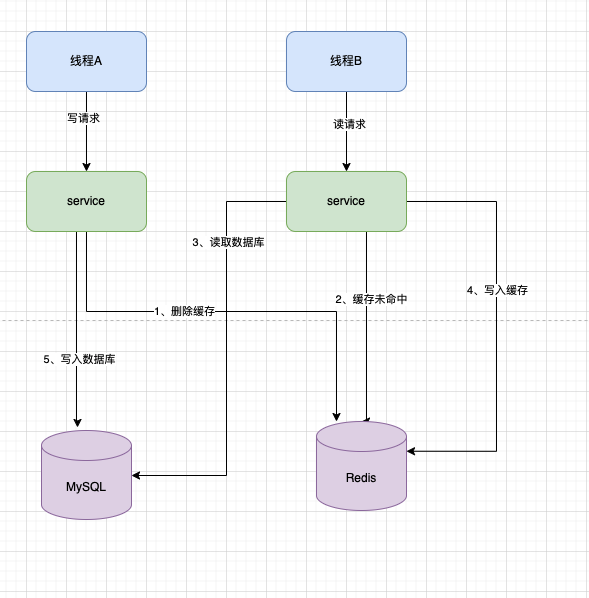
1、线程A 发起一个写请求、先删除 Redis 中的缓存。
2、线程B 发起一个读请求,没有命中缓存。
3、线程B 读取数据库,获取数据。
4、线程B 写入老数据到缓存。
5、线程A 写入DB 新数据。
到这就发现了问题了吧,如果你没发现,那就跟着我的思路来看一下。
大家来看第三步,线程B 去读取数据库,此时 线程A 是还没有写入新数据的,所以此时 线程B 读取的数据是老数据。
而第5步,线程A 往数据库写入的才是最新的数据。
所以此时也就造成了数据不一致 了。
对于这种情况造成的脏数据缓存,有的小伙伴可能就提出来了,可以使用缓存双删啊,那么我们来继续往下看。
4.1.2、缓存延迟双删
延迟双删,就是字面意思,删除两边缓存。你知道问题在哪吗,想一想?
。。。。。。
双删,有可能删除失败吗?
删除失败怎么办?
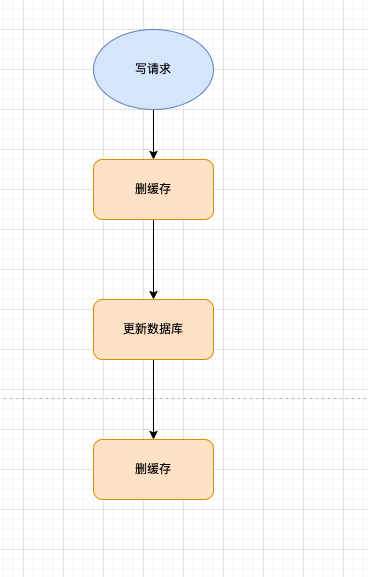
双删的步骤如下
1、删除缓存。
2、更新数据库。
3、延迟删除(此时延迟的差不多是读请求的耗时多一点,防止读请求设置脏数据缓存)。
4.1.3、删除缓存的重试机制
删除缓存失败,第一个想到的应该是,删除失败了就多删除几次吧。
所以我们可以借助于消息队列,将删除失败的 key 加入到消息队列,对消息进行重试删除操作。

既然我们都用到消息队列了,那么我们为什么不直接监听 binlog 实现异步删除缓存呢。
4.2、消息队列
使用消息队列监听数据库变更事件、异步更新缓存。能够保证在数据库更新后,缓存能够按照顺序进行更新。
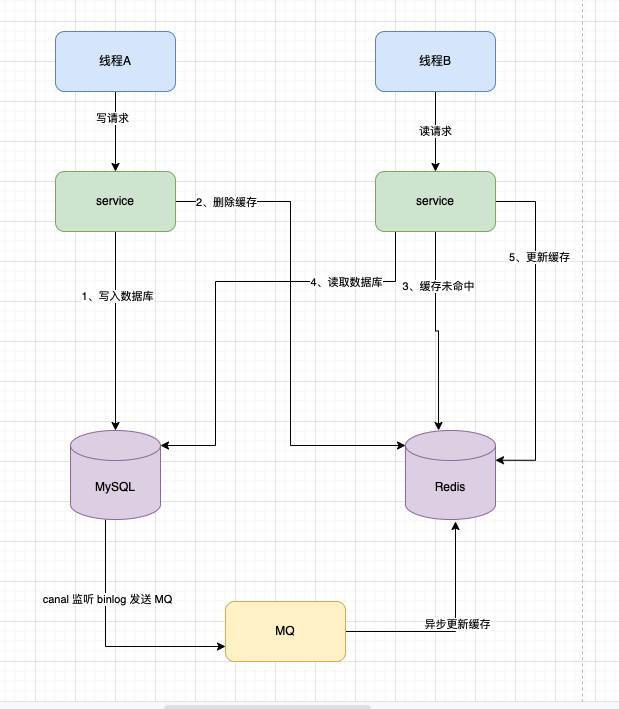
此时的例子就是,使用 Canal 监听 binlog ,发送数据到 MQ 中,应用程序监听 MQ 消息实现 Redis 缓存的更新。
五、总结
实现 MySQL 与 Redis缓存的一致性中,需要考虑很多的方面,最直观的就是业务场景,性能要求,以及数据的安全等因素综合考虑。
例如,对于读多写少的场景,可以采用 Read/Write Through 模式;
而对于写操作频繁的场景,则可能需要考虑 Write Behind Caching 模式。
如果这篇文章对您有所帮助,或者有所启发的话,帮忙点个关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
wx 搜索《醉鱼Java》,回复面试、获取2024面试资料















 2794
2794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









