






您可以从www.packt.com的帐户中下载本书的示例代码文件。如果您在其他地方购买了本书,您可以访问www.packt.com/support并注册,以便文件直接通过电子邮件发送给您。
您可以按照以下步骤下载代码文件:
-
在www.packt.com上登录或注册。
-
选择“支持”选项卡。
-
点击“代码下载和勘误”。
-
在“搜索”框中输入书名,然后按照屏幕上的说明操作。
下载文件后,请确保使用最新版本的解压缩或提取文件夹:
-
WinRAR/7-Zip for Windows
-
Zipeg/iZip/UnRarX for Mac
-
7-Zip/PeaZip for Linux
该书的代码包也托管在 GitHub 上,网址为github.com/PacktPublishing/Hands-On-Web-Scraping-with-Python。如果代码有更新,将在现有的 GitHub 存储库上进行更新。
我们还有来自丰富书籍和视频目录的其他代码包,可以在github.com/PacktPublishing/上找到。去看看吧!
下载彩色图片
我们还提供了一份 PDF 文件,其中包含本书中使用的屏幕截图/图表的彩色图片。您可以在这里下载:www.packtpub.com/sites/default/files/downloads/9781789533392_ColorImages.pdf。
使用的约定
本书中使用了许多文本约定。
CodeInText:表示文本中的代码词、数据库表名、文件夹名、文件名、文件扩展名、路径名、虚拟 URL、用户输入和 Twitter 句柄。这是一个例子:“<p>和<h1> HTML 元素包含与它们一起的一般文本信息(元素内容)。”
代码块设置如下:
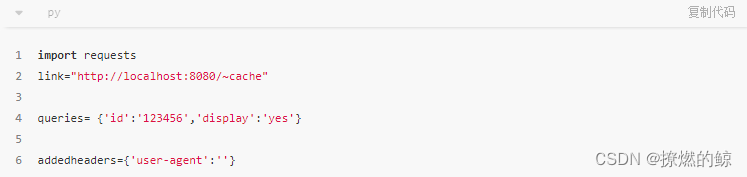
当我们希望引起您对代码块的特定部分的注意时,相关行或项目将以粗体显示:
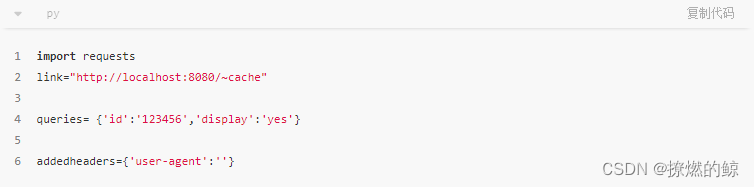 任何命令行输入或输出都以以下方式编写:
任何命令行输入或输出都以以下方式编写:

粗体:表示新术语、重要单词或屏幕上看到的单词。例如,菜单或对话框中的单词会以这样的方式出现在文本中。这是一个例子:“如果通过 Chrome 菜单访问开发者工具,请单击更多工具|开发者工具”
警告或重要说明会以这种方式出现。提示和技巧会以这种方式出现。
第一部分:网络抓取简介
在本节中,您将获得有关网络抓取(抓取要求、数据重要性)、网页内容(模式和布局)、Python 编程和库(基础和高级)、以及数据管理技术(文件处理和数据库)的概述。
本节包括以下章节:
- 第一章,网络抓取基础
第一章:网络爬虫基础知识
在本章中,我们将学习和探讨与网络爬取和基于网络的技术相关的某些基本概念,假设您没有网络爬取的先验经验。
因此,让我们从以下一些问题开始:
-
为什么会出现对数据的不断增长需求?
-
我们将如何管理和满足来自“万维网”(WWW)资源的数据需求?
网络爬虫解决了这两个问题,因为它提供了各种工具和技术,可以用来提取数据或协助信息检索。无论是基于网络的结构化数据还是非结构化数据,我们都可以使用网络爬虫过程来提取数据,并将其用于研究、分析、个人收藏、信息提取、知识发现等多种目的。
我们将学习通用技术,用于从网络中查找数据,并在接下来的章节中使用 Python 编程语言深入探讨这些技术。
在本章中,我们将涵盖以下主题:
-
网络爬虫介绍
-
了解网络开发和技术
-
数据查找技术
网络爬虫介绍
爬取是从网络中提取、复制、筛选或收集数据的过程。从网络(通常称为网站、网页或与互联网相关的资源)中提取或提取数据通常被称为“网络爬取”。
网络爬虫是一种适用于特定需求的从网络中提取数据的过程。数据收集和分析,以及其在信息和决策制定中的参与,以及与研究相关的活动,使得爬取过程对所有类型的行业都很敏感。
互联网及其资源的普及每天都在引起信息领域的演变,这也导致了对原始数据的不断增长需求。数据是科学、技术和管理领域的基本需求。收集或组织的数据经过不同程度的逻辑处理,以获取信息并获得进一步的见解。
网络爬虫提供了用于根据个人或业务需求从网站收集数据的工具和技术,但需要考虑许多法律因素。
在执行爬取任务之前,有许多法律因素需要考虑。大多数网站包含诸如“隐私政策”、“关于我们”和“条款和条件”等页面,其中提供了法律条款、禁止内容政策和一般信息。在计划从网站进行任何爬取和抓取活动之前,开发者有道德责任遵守这些政策。
在本书的各章中,爬取和抓取两个术语通常可以互换使用。抓取,也称为蜘蛛,是用于浏览网站链接的过程,通常由搜索引擎用于索引目的,而爬取大多与从网站中提取内容相关。
了解网络开发和技术
网页不仅仅是一个文档容器。当今计算和网络技术的快速发展已经将网络转变为动态和实时的信息来源。
在我们这一端,我们(用户)使用网络浏览器(如 Google Chrome、Firefox Mozilla、Internet Explorer 和 Safari)来从网络中获取信息。网络浏览器为用户提供各种基于文档的功能,并包含对网页开发人员通常有用的应用级功能。
用户通过浏览器查看或浏览的网页不仅仅是单个文档。存在各种技术可用于开发网站或网页。网页是包含 HTML 标记块的文档。大多数情况下,它是由各种子块构建而成,这些子块作为依赖或独立组件来自各种相互关联的技术,包括 JavaScript 和 CSS。
对网页的一般概念和网页开发技术的理解,以及网页内部的技术,将在抓取过程中提供更多的灵活性和控制。很多时候,开发人员还可以使用反向工程技术。
反向工程是一种涉及分解和检查构建某些产品所需概念的活动。有关反向工程的更多信息,请参阅 GlobalSpec 文章反向工程是如何工作的?,网址为insights.globalspec.com/article/7367/how-does-reverse-engineering-work。
在这里,我们将介绍和探讨一些可以帮助和指导我们进行数据提取过程的技术。
HTTP
超文本传输协议(HTTP)是一种应用协议,用于在客户端和 Web 服务器之间传输资源,例如 HTML 文档。HTTP 是一种遵循客户端-服务器模型的无状态协议。客户端(Web 浏览器)和 Web 服务器使用 HTTP 请求和 HTTP 响应进行通信或交换信息:
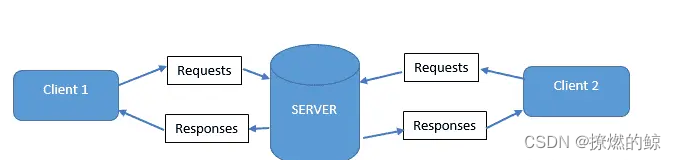
HTTP(客户端-服务器通信)
通过 HTTP 请求或 HTTP 方法,客户端或浏览器向服务器提交请求。有各种方法(也称为 HTTP 请求方法)可以提交请求,例如GET、POST和PUT:
-
GET:这是请求信息的常见方法。它被认为是一种安全方法,因为资源状态不会被改变。此外,它用于提供查询字符串,例如http://www.test-domain.com/,根据请求中发送的id和display参数从服务器请求信息。 -
POST:用于向服务器发出安全请求。所请求的资源状态可以被改变。发送到请求的 URL 的数据不会显示在 URL 中,而是与请求主体一起传输。它用于以安全的方式向服务器提交信息,例如登录和用户注册。
使用浏览器开发者工具显示的以下屏幕截图,可以显示请求方法以及其他与 HTTP 相关的信息:
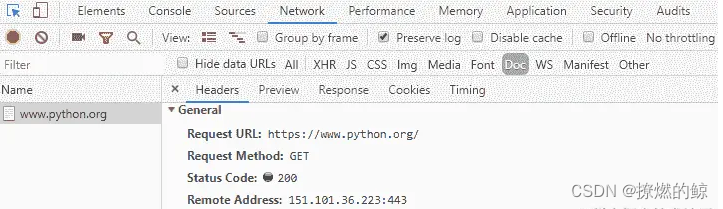
一般的 HTTP 头(使用浏览器开发者工具访问)
我们将在第二章中更多地探讨 HTTP 方法,
Python 和 Web-使用 urllib 和 Requests,在实现 HTTP 方法部分。
HTTP 头在请求或响应过程中向客户端或服务器传递附加信息。头通常是客户端和服务器在通信过程中传输的信息的名称-值对,并且通常分为请求头和响应头:
- 请求头:这些是用于发出请求的头。在发出请求时,会向服务器提供诸如语言和编码请求
-*、引用者、cookie、与浏览器相关的信息等信息。以下屏幕截图显示了在向www.python.org发出请求时从浏览器开发者工具中获取的请求头:
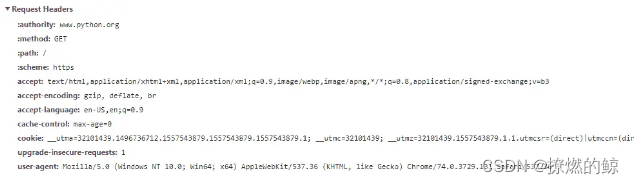
请求头(使用浏览器开发者工具访问)
- 响应头:这些头包含有关服务器响应的信息。响应头通常包含有关响应的信息(包括大小、类型和日期)以及服务器状态。以下屏幕截图显示了在向www.python.org发出请求后从浏览器开发者工具中获取的响应头:
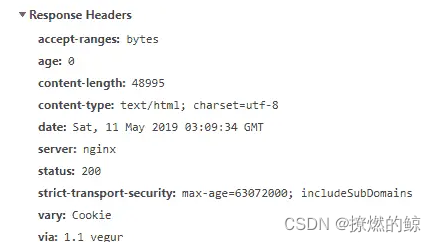
响应头(使用浏览器开发者工具访问)
在之前的屏幕截图中看到的信息是在对www.python.org发出的请求期间捕获的。
在向服务器发出请求时,还可以提供所需的 HTTP 头部。通常可以使用 HTTP 头部信息来探索与请求 URL、请求方法、状态代码、请求头部、查询字符串参数、cookie、POST参数和服务器详细信息相关的信息。
通过HTTP 响应,服务器处理发送到它的请求,有时也处理指定的 HTTP 头部。当接收并处理请求时,它将其响应返回给浏览器。
响应包含状态代码,其含义可以使用开发者工具来查看,就像在之前的屏幕截图中看到的那样。以下列表包含一些状态代码以及一些简要信息:
-
200(OK,请求成功)
-
404(未找到;请求的资源找不到)
-
500(内部服务器错误)
-
204(无内容发送)
-
401(未经授权的请求已发送到服务器)
有关 HTTP、HTTP 响应和状态代码的更多信息,请参阅官方文档www.w3.org/Protocols/和developer.mozilla.org/en-US/docs/Web/HTTP/Status。
HTTP cookie是服务器发送给浏览器的数据。cookie 是网站在您的系统或计算机上生成和存储的数据。cookie 中的数据有助于识别用户对网站的 HTTP 请求。cookie 包含有关会话管理、用户偏好和用户行为的信息。
服务器根据存储在 cookie 中的信息来识别并与浏览器通信。cookie 中存储的数据帮助网站访问和传输某些保存的值,如会话 ID、过期日期和时间等,从而在 web 请求和响应之间提供快速交互:
















 4660
4660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









