






怎样通过 urllib库 发送 HTTP 请求?

urllib库主要由四个模块组成:
- urllib.request 打开和读取 URL
- urllib.error 包含 urllib.request 抛出的异常
- urllib.parse 用于解析 URL
- urllib.robotparser 用于解析
robots.txt文件
1. 使用urllib.parse解析URL
-
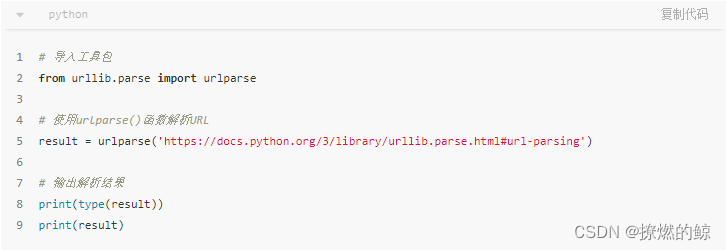
使用
urlparse()分段URL
-
在这里,我们用
urlparse()函数构建了一个实例对象(ParseResult类型),并将其赋值给result,以便调用。事实上,ParseResult类型对象包含6个部分:
- scheme,代表协议,通常在"://"前面,这里即
http - netloc,代表域名,通常在第一个"/"前面,这里即
docs.python.org:80 - path,代表访问路径,通常在域名之后,这里即
/3/library/urllib.parse.html - params,代表参数,通常在"?"之前,这里不存在
- query,代表查询条件,通常在"?"之后,这里也不存在
- fragment,代表瞄点,通常在"#"之后,用于直接定位页面内部的下拉位置,这里即
url-parsing
- scheme,代表协议,通常在"://"前面,这里即
-
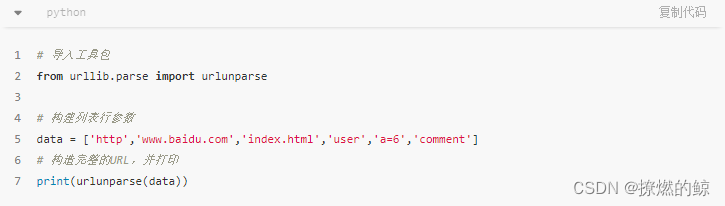
使用
urlunparse()构造URL
-
事实上,在
urllib.parse中,解析URL的方法不仅有urlparse()函数,还有urlsplit()等;构造URL的方法不仅有urlunparse()函数,还有urlunsplit和urlencode()等。
2. 使用urllib.request打开 URL,模拟发送请求
-
使用
urllib.request.urlopen函数发送HTTP请求,构造对象

-
urllib.request.urlopen函数构造一个接受请求的实例对象(HTTPResponse类型),并将其赋值给response变量,以便之后使用。read()方法可以得到返回的网页内容。事实上,HTTPResponse类型的对象,不仅可以调用read()和getheaders()等方法,还可以调用status和msg等属性来查看请求发送后返回的一系列信息。 -
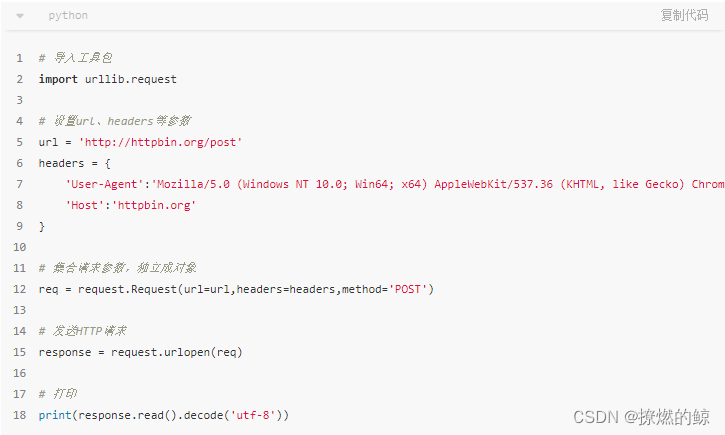
通过
Request类灵活配置参数,构建请求信息对象
-
这里我们依然使用
urlopen()方法来发送HTTP请求,但是传递的不再是单纯的URL,而是一个Request类型的对象。通过集合各种参数,将其独立成一个对象,可以更加丰富和灵活地配置参数。这里的
headers即为请求头,method即为请求方法 -
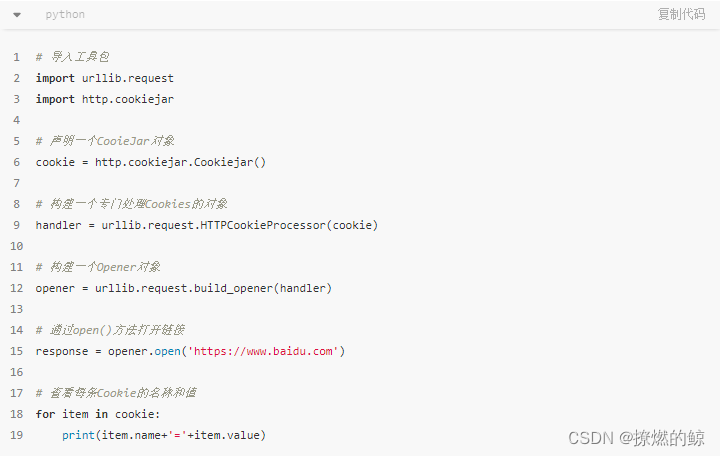
使用
Handler处理器进行高级操作(以Cookies处理为例)
-
HTTPCookieProcessor是urllib.request模块里用于处理Cookie的一个类。值得注意的是这里打开链接的不再是request.urlopen()函数,而是用Opener对象的open()方法来发出请求。
3. 使用urllib.error捕捉请求错误,进行异常处理
-
使用
URLError类捕捉URL异常-
在这里如果发生网页不存在等请求异常,我们就可以通过
URLError捕捉异常,从而避免程序的异常终止 -
使用
HTTPError类捕捉HTTP请求错误
-















 6180
6180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









