







 数据挖掘中,选择合适的分类算法至关重要。支持向量机(SVM)通常用于追求高预测准确性的场景,而决策树则因模型可解释性而被青睐。使用SVM时,高斯核和交叉验证有助于优化模型参数。文章引用了Kotsiantis, Hastie, Tibshirani & Friedman以及Caruana, Niculescu-Mizil的研究,提供了常见分类算法的比较分析。"
78866086,5543195,Mybatis整合Ehcache实现缓存,"['mybatis', '缓存框架', 'Ehcache']
数据挖掘中,选择合适的分类算法至关重要。支持向量机(SVM)通常用于追求高预测准确性的场景,而决策树则因模型可解释性而被青睐。使用SVM时,高斯核和交叉验证有助于优化模型参数。文章引用了Kotsiantis, Hastie, Tibshirani & Friedman以及Caruana, Niculescu-Mizil的研究,提供了常见分类算法的比较分析。"
78866086,5543195,Mybatis整合Ehcache实现缓存,"['mybatis', '缓存框架', 'Ehcache']
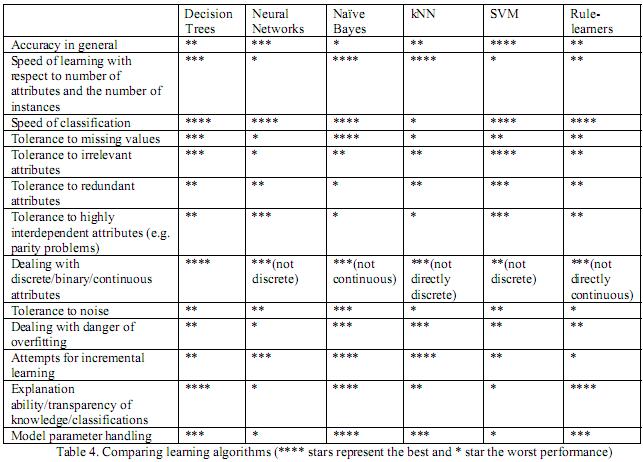
数据挖掘新手常问的一个问题是,这么多算法里面该选用哪一个?在没有更多背景信息给出时,如果追求预测的准确程度,一般用支持向量机(SVM),如果要求模型可以解释,一般用决策树。使用SVM的时候选择高斯核(即RBF kernel),同时要用交叉验证(cross validation)选择合适的模型参数。
下面的表格是对常用分类算法的一个比较,来自一篇文章
Kotsiantis, S. B.
Supervised Machine Learning: A Review of Classification Techniques
Informatica, 2007, 31, 249-268
接下来这个表格的结论类似,它来自经典名著
Hastie, T.; Tibshirani, R. & Friedman, J.
The Elements of Statistical Learning, Second Edition
Springer, 2009
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 69
69

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









