





 本文提出了一种名为SIFU的联邦遗忘学习框架,旨在解决服务器如何识别并遗忘低质量客户端数据的问题。通过实验分析,SIFU在多个数据集上展示了提高全局模型准确性和降低遗忘时间的效果。
本文提出了一种名为SIFU的联邦遗忘学习框架,旨在解决服务器如何识别并遗忘低质量客户端数据的问题。通过实验分析,SIFU在多个数据集上展示了提高全局模型准确性和降低遗忘时间的效果。
【文献阅读系列2】
前言
现在许多联邦遗忘学习的研究聚焦于客户端侧用户遗忘权利,忽视了服务器从全局模型中移除某个本地模型的权力,特别是客户端使用低质量数据进行训练时。因此本文提出了服务器发起的联邦遗忘学习,旨在消除低质量数据对全局模型的影响。
一、两个挑战
为了实现这个目的,本文认为这需要解决两个技术挑战:
挑战一: 识别使用了低质量数据训练的客户端。因为联邦学习的特性,中心服务器无法直接读取客户端数据,客户端无法确定客户端数据集的标签噪声、数据分布等,这导致服务器从众多客户端中识别携带低质量数据的客户端更为困难。
挑战二: 遗忘低质量数据。联邦学习是以客户端为单位训练本地模型,学习过程是增量的,所以虽然能有效遗忘整个客户端的影响,但是只消除客户端部分数据是富有挑战的。总结下两个挑战是,识别带有低质量数据的客户端,并遗忘这些客户端上低质量部分的数据影响。
二、两个目标
针对这两项挑战,本文提出相应的算法设计目标:
- 目标一,有效地识别具有低质量数据的客户端,并在由服务器启动的遗忘过程中区分其低质量数据;
- 目标二,高效消除低质量数据对全局模型的历史影响,并最大化遗忘学习全局模型的质量。
三、系统模型
根据上述目标,本文设计了如图的联邦遗忘学习系统。
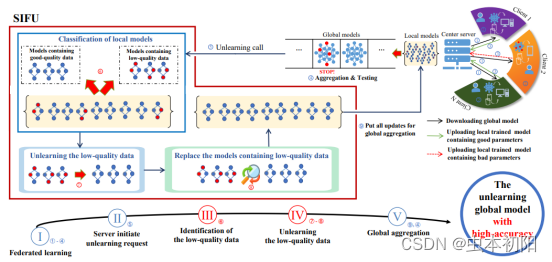
该系统由中心服务器和一组客户端组成。每个客户端拥有各自的本地数据集。对于每个学习任务,中心服务器会保存有一个小型的标准数据集,这个标准数据集通常包含正确的标记的样本,数据分布也平衡。当然,与客户端的数据集相比,服务器上的标准数据集数量有限,其数据量不足以训练高精度的模型。在本文中,这个数据集是用来作为测试集,评估模型准确性,识别包含低质量数据的客户端。这里补充一下,本文指示的‘低质量数据集’主要是指数据出现错误标签的情况,比如由于人为疏忽,某些狮子的图像被错误地标记为“家猫”这样的情况。
在未识别到低质量数据集之前,系统可以看作一个传统的联邦学习系统,进行多轮训练,遵循联邦学习的基本原则。不过在每一轮的训练中,服务器会检查聚合后的全局模型,使用基准数据集进行检测,评估是否受到低质量数据的影响。
那么什么样的情况,服务器会判定需要进行遗忘学习呢?
首先,服务器在收集各客户端模型参数并进行聚合产生全局模型后,会使用标准数据集评估该全局模型的准确性,一旦发现当前全局模型的准确性低于前一轮的全局模型,那么联邦学习的迭代训练过程将被终止,发出遗忘学习请求。如果准确率上升则继续联邦学习过程。
检测到全局模型准确率下降时,中心服务器主动发起取消学习过程,并将接收到的本地模型引导到SIFU框架进行遗忘学习。
四、SIFU框架

SIFU的架构如图所示。中心服务器会识别包含低质量数据的目标客户端,然后发消息给这些识别出来的低质量客户端。每个这样的客户端在本地将其本地数据分类为两个不同的类别,即低质量和高质量数据。每个目标客户端使用梯度上升方法对低质量数据进行本地模型训练,以抵消此类数据的有害影响。随后,模型将经历几批增强训练,以抵消在梯度上升训练阶段引入的模型偏差。遗忘学习过程结束后,遗忘学习的本地模型会替换受低质量数据影响的原始本地模型。随后,将上述模型与其余客户端的正常本地模型聚合,产生新的全局模型。接着,继续联邦学习过程。
可以看到,该框架包含两个模块。下面针对这两模块的细节进行深入探讨。
4.1 寻找低质量客户端
第一步,寻找低质量客户端。
那么大家想一下,在服务器端无法直接访问客户端本地数据的前提下,该如何识别低质量客户端呢?
通常的想法是直接使用中心服务器的小型测试数据集测试各客户端的本地模型的准确率,准确率较低的客户端更有可能包含低质量数据。然而,在联邦学习中,FL 用户的数据通常是非独立同分布的,这种方法无法确定客户端模型准确率较低是由于包含低质量数据还是由于数据分布不平衡等其他原因。
为了解决这一问题,本文提出了一种方案来找出包含低质量数据的客户端。
在联邦学习训练中,中心服务器会保存最新的本地模型参数,以及聚合后的全局模型参数。中心服务器会使用整个基准测试集对全局模型进行测试,得到准确率P用于之后的比较。接着,中心服务器会将全局模型在标准数据集的各个类别上进行测试,并且记录那些准确率比P小的类别,这些类别中可能包含低质量数据集。接着,中心服务器将保存的各客户端模型在标准数据集上进行测试,记录那些准确率比P低的客户端。以上就从两个维度查找出可能包含低质量数据集的客户端和可能的类别。
接着,中心服务器会通知刚才记录的客户端,让它们进行本地低质量数据自查。每个客户端都维护一个数据质量评价分数,该分数初始化为0。刚才中心服务器记录了一些可能包含低质量数据的数据类别,客户端模型会在本地数据集的这些类别上进行模型准确率测试。接着会按照以下公式计算客户端i在本地第j类数据的质量评价分数,将这些分数相加就会得到客户端i的质量评价分数,分数越高,说明包含低质量数据的可能性越大。接着,客户端会将该分数上传给服务器。
中心服务器收到客户端的低质量分数后,会对这些模型进行分类,筛选出真正包含低质量的客户端。本文采用了K均值聚类算法对客户端进行二分类,通过聚类它们的低质量分数将客户端分为“目标客户端”或“正常客户端”。
接下来,服务器向每个目标客户端发送一个遗忘学习通知。在本文中,每个接收到通知的客户端都会使用一个用于检测噪声标签的框架,即 CTRL,来筛选低质数据,并将客户端i的数据集划分为两部分,这样就可以在保留高质量数据的贡献的同时消除低质量数据的影响。
一句话总结,就是服务器会识别出低质量的客户端和可能的低质量类别,通知相应的客户端在这些类别上进行自查,并反馈给中心服务器,中心服务器再筛选出真正的低质量数据客户端,称为目标客户端,在目标客户端中使用CTRL噪声标签检测框架筛选出低质量数据,为后续的遗忘学习打好基础。
4.2 遗忘低质量数据
传统的联邦学习本地训练是最小化模型在本地数据集上的损失,在本文的遗忘过程中,与传统的本地训练过程相反,是最大化模型在低质量数据集上的损失,以此达到遗忘目的。除此之外,本文还设置了一个约束来限制梯度上升训练过程,该约束限制了模型的权重参数。就是将非目标客户端的模型聚合,得到基准模型,然后,我们限制了在目标客户端上训练的模型的权重参数与基础模型 Mb的权重参数之间的欧氏距离不超过阈值r。
尽管我们为梯度上升训练过程设置了约束,但最终模型仍可能产生一些偏差,为了进一步提高模型的准确性,本文使用一个批次的高质量数据进行模型训练,称为boosting训练。在我们的实验中,一个批次只包含 64 个数据样本,与客户端的总数据相比是微不足道的。因此,Boosting 训练的成本非常低。
以上就是本地unlearning的两个步骤。接下来,会测试本地模型在低质量数据集上的性能,并设置一个停止阈值。当训练模型在低质量数据集上的准确率低于该阈值时,训练过程将提前停止。否则,整个过程会循环进行,即梯度上升训练和 Boosting 训练会持续进行,直到达到早停止阈值。通过这种方式,避免了对模型进行过度梯度上升训练。
目标客户端完成所有遗忘学习训练步骤后,服务器将原始目标客户端的本地模型替换为遗忘后的模型,并与其他正常客户端的本地模型进行聚合,得到最终的全局模型,然后继续进行联邦学习训练。
五、实验分析
5.1 数据集

本文利用四个常见数据集来评估SIFU的性能,包括MNIST、FMNIST、CIFAR-10和CelebA 。MNIST是一个由手写数字灰度图像组成的数据集,FMNIST是一个由时尚物品灰度图像组成的数据集,两者均由60,000个训练图像和10,000个测试图像组成。CIFAR-10包含来自10个类别的彩色图像,如“飞机”、“猫”、“狗”等,其中包含50,000个训练图像和10,000个测试图像。CelebA是一个大规模的人脸属性数据集,包含超过200,000张名人图像,每张图像有40个属性注释。特别地,我们针对CelebA的性别属性进行分类任务。在我们的实验中,我们将测试图像放置在中央服务器上作为基准数据集,并将训练图像均匀分配给每个客户端作为其数据集。请注意,如果没有提到数据集,我们默认使用MNIST数据集。
由于很少有现有研究专注于寻找包含低质量数据的客户作为比较算法,因此我们仅对SIFU的unlearning部分进行比较实验。本文将SIFU与六种不同的方法进行比较。有FedRetrain(FR),Gradient ascent training only(GT),Boosting training only(BT), FUL with Knowledge Distillation(FK),Rapid retraining(RR),Federated learning 。
评估指标有准确率、损失值和构建遗忘全局模型所需的时间这三点。

接下来,文章从以下方面对所提算法进行分析。分析了是对SIFU的性能,时间消耗,目标客户百分比的影响,低质量数据百分比的影响,批量大小设置对提升训练的影响这五个方面。
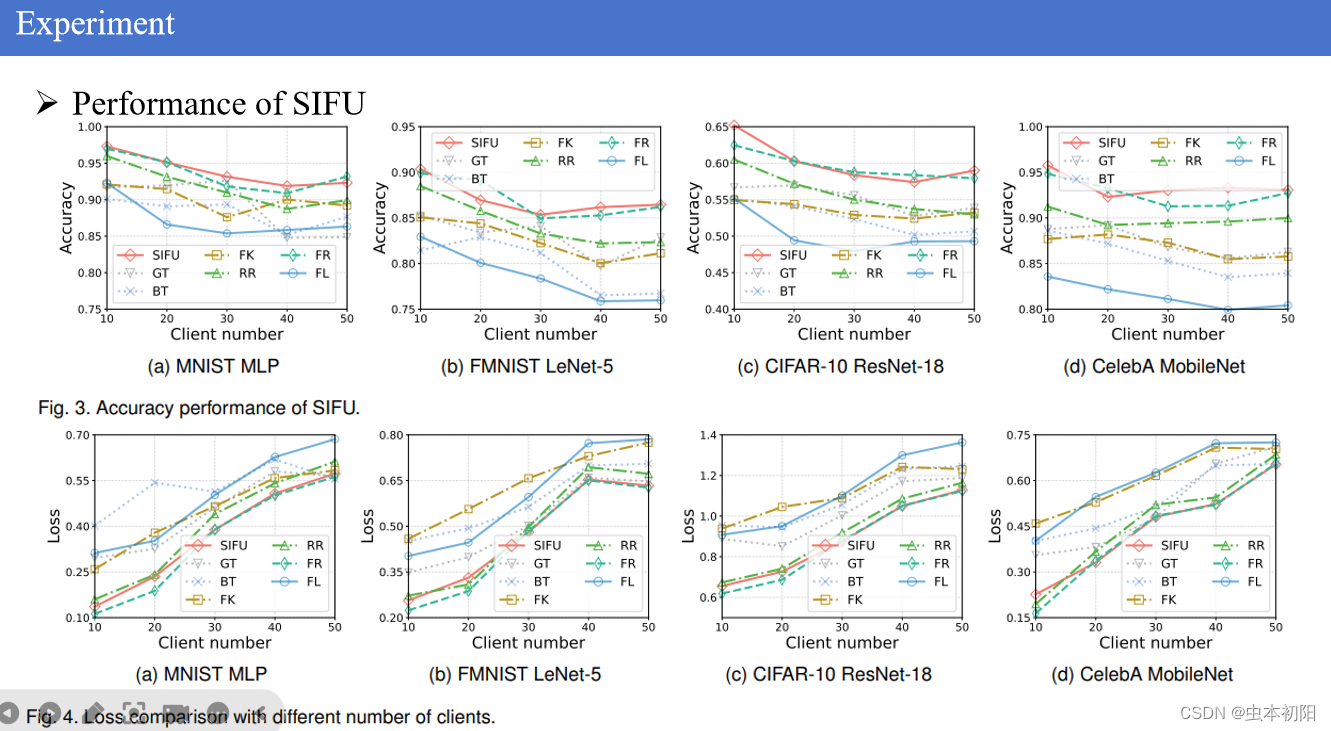
如图显示了SIFU和六种比较算法的模型预测准确率。调查了SIFU在不同客户端数量下改善全局模型准确率的性能。可以看到FedRetrain、Rapid Retraining和SIFU都能够提高受低质量数据影响的FL全局模型的准确性,而且对于任意数量的客户端都是这样。甚至在某些情况下SIFU算法比FedRetrain更佳,比如在mnist数据集上使用mlp模型进行训练,当客户端数量为40个时,本文所提算法准确率比任意算法都高,这可能是因为SIFU的增强训练过程使模型更具收敛性。除了准确率,还进行损失值的比较,可以看到本文所提算法与fedretrain几乎表现一致。
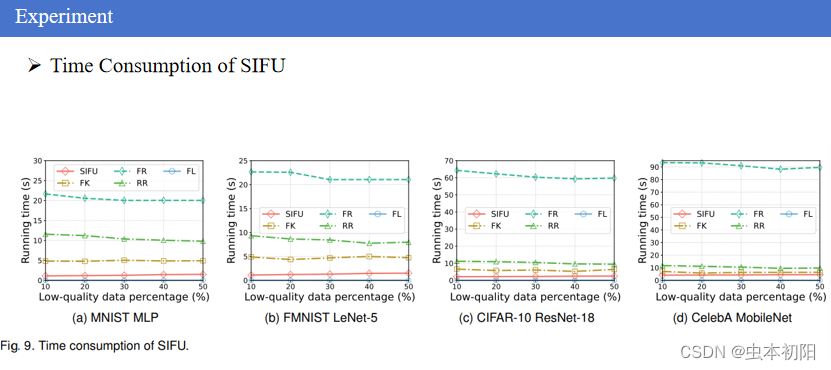
检测了SIFU和其他FUL方法在遗忘全局模型所需的运行时间。可以看到,fedRetrain需要的遗忘时间最长,SIFU所需时间最少,这表明本文所提算法的加速效果显著。
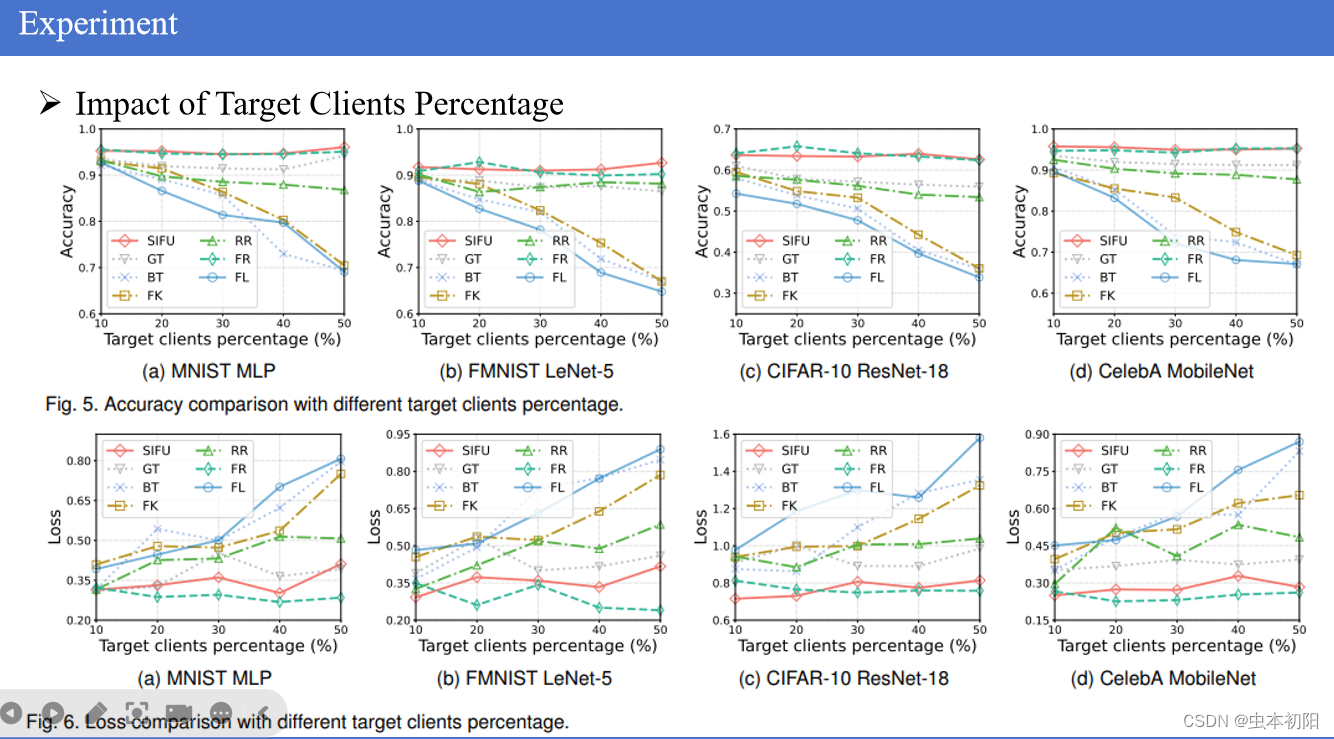
如图,研究了在目标客户百分比发生变化的情况下,SIFU在提高全局模型准确性方面的表现。首先,每个客户端的低质量数据量固定,占30%。因此随着目标客户数量的增加,总数据中的低质量数据量相应增加,那么FL模型的准确性受到更大的负面影响。可以看到对于任意百分比的低质量客户端数量,SIFU都能很好地提高模型的准确性,几乎不受目标客户百分比的影响并且表现类似于FedRetrain,并优于其他遗忘方法。还观察了损失值的变化,可以清楚地看到,在所有方法中,仍然是SIFU和FedRetrain表现最好。
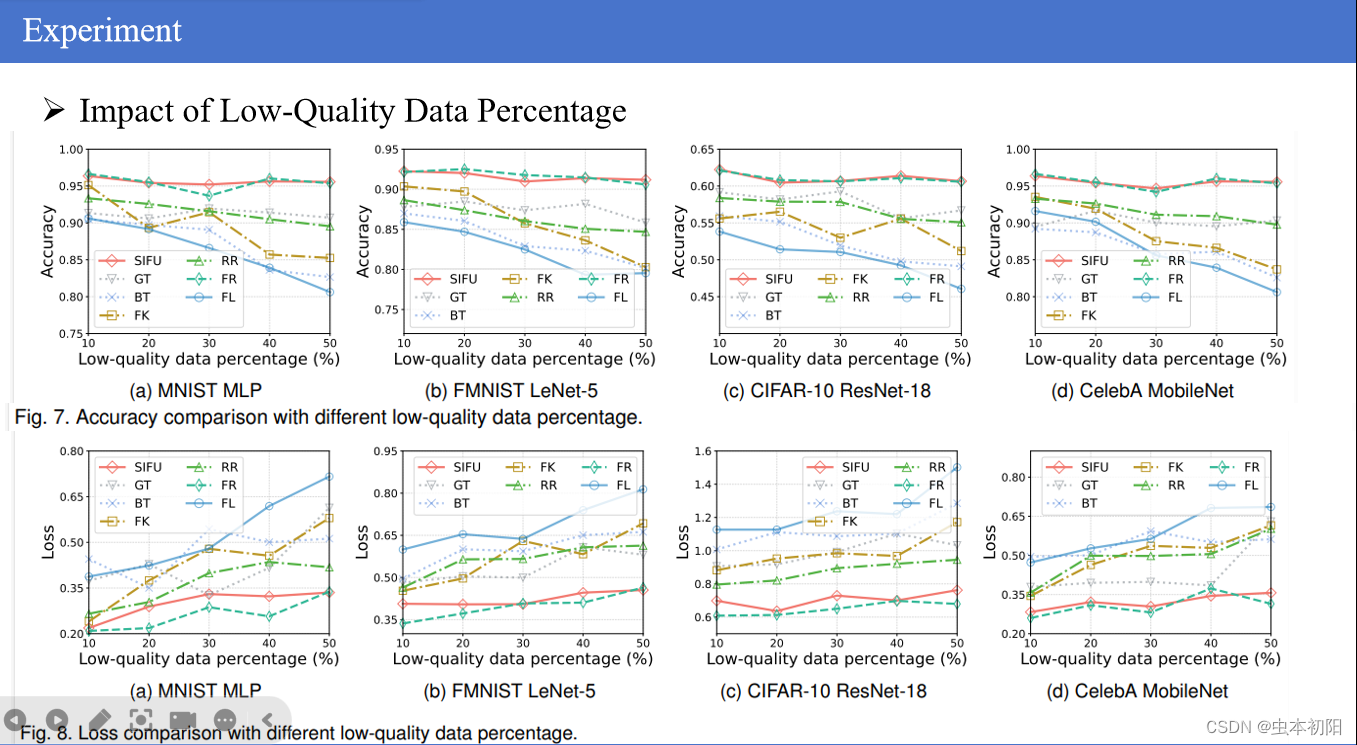
接着,分析了低质量数据百分比对SIFU在提高全局模型准确性以及对应的损失值方面的影响。可以看到本文所提算法依然表现良好。
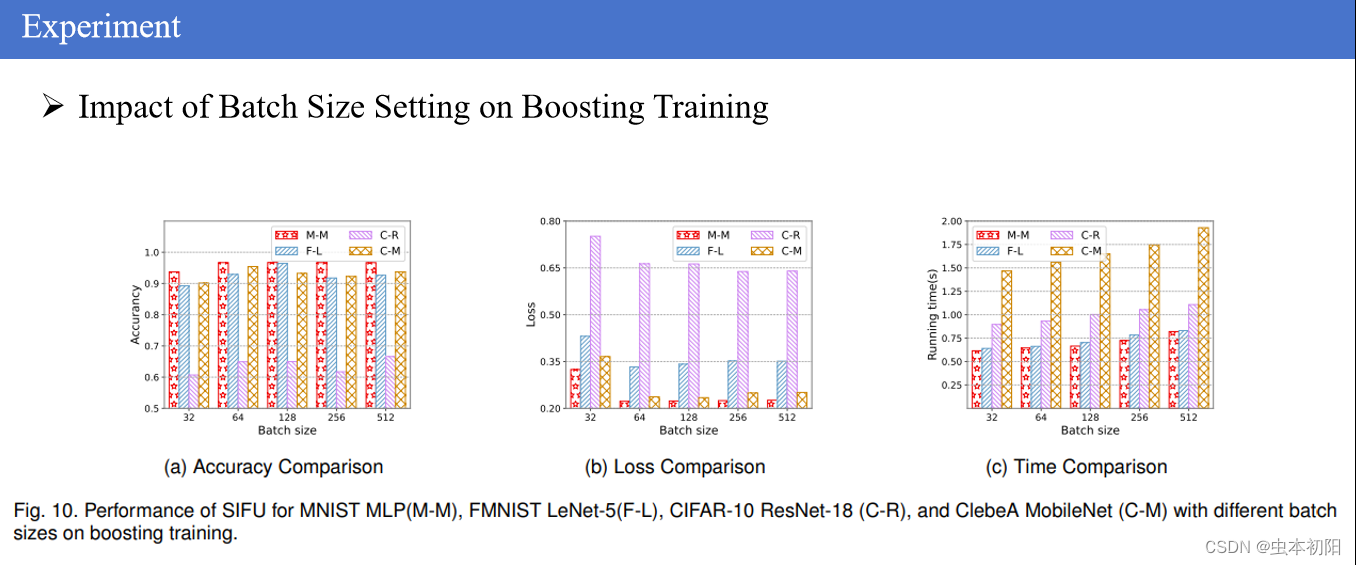
最后,调查了在不同数据集和模型上调整批量大小对增强训练过程的影响,结果显示了批量大小和模型性能之间的关系。可以看到,随着批次大小的增加,模型的准确率也增加了,这是因为当使用较大的批量大小时,用于增强训练过程的数据也就增加了,实现更强大和稳定的模型性能。同时为了平衡好模型准确性、损失和运行时间,本文认为批量大小为64在所有数据集和模型上能够实现最佳的整体性能,实现了最佳的平衡,为在各种场景中实现SIFU提供了稳健而实用的选择。
六、总结
本文提出了SIFU,旨在高效消除低质量数据对全局模型的负面影响,同时保留高质量数据的优势。SIFU首先识别具有低质量数据的目标客户,并相应地过滤其本地数据。接下来,SIFU在目标客户上部署梯度上升训练,为了减少梯度上升训练导致的性能下降,SIFU使用了几批高质量数据进行增强训练。最终,通过聚合剩余本地模型和遗忘学习的本地模型,得到了一个性能良好的遗忘学习全局模型。实验结果证实了SIFU在加速遗忘学习过程并改善全局模型性能方面的优势。















 7035
7035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









