






容器虚拟化
可以实现应用程序的隔离
直接使用物理机的操作系统可以快速响应用户请求
不占用部署时间
占用少量磁盘空间
缺点∶学习成本增加、操作控制麻烦、网络控制与主机虚拟化有所区别、服务治理难。
微服务架构师需要会多门编程语言,才能治理各种服务
三种云平台技术的侧重点不一样,laaS是需要花时间部署虚拟机,但是容器就不用花那么多时间
laaS 虚拟机
阿里云ECS
OpenStack VM实例.
PaaS 容器
LXC
Docker
OpenShift
Rancher
SaaS 应用程序
互联网中应用都是
NameSpace
一个容器就是一个namespace
六大命名空间
UTS
UTS ( UNIX Time-sharing System ) 命名空间允许每个容器拥有独立的主机名和域名,从而可以虚拟出一个有独立主机名和网络空间的环境,就跟网络上一台独立的主机一样。
IPC
容器中进程交互还是采用了Linux常见的进程间交互方法(Interprocess Communication, IPC ),包括信号、消息队列和共享内存等。PID Namespace和IPC Namespace可以组合起来一起使用,同一个IPC命名空间内的进程可以彼此可见,允许进行交互;不同空间的进程则无法交互。
Mount
类似于chroot,将一个进程放到一个特定的目录执行。挂载命名空间允许不同命名空间的进程看到的文件结构不同,这样每个命名空间中的进程所看到的文件目录彼此被隔离。
Net
通过网络命名空间,可以实现网络隔离。网络命名空间为进程提供了一个完全独立的网络协议栈的视图,包括网络设备接口、IPv4和IPv6协议栈、IP路由表、防火墙规则、sockets等,这样每个容器的网络就能隔离开来。Docker采用虚拟网络设备(Virtual Network Device )的方式,将不同命名空间的网络设备连接到一起。默认情况下,容器中的虚拟网卡将同本地主机上的docker0网桥连接在一起。
User
每个容器可以有不同的用户和组id,也就是说可以在容器内使用特定的内部用户执行程序,而非本地系统上存在的用户
每个容器内部都可以有root帐号,但跟宿主主机不在一个命名空间。通过使用隔离的用户命名空间可以提高安全性,避免容器内进程获取到额外的权限。
PID
Linux通过命名空间管理进程号,对于同一进程(即同一个task_struct ),在不同的命名空间中,看到的进程号不相同,每个进程命名空间有一套自己的进程号管理方法。进程命名空间是一个父子关系的结构,子空间中的进程对于父空间是可见的。新fork出的进程在父命名空间和子命名空间将分别有一个进程号来对应。
总结

子进程在容器中,物理机中的就是父进程,子进程也叫线程
什么是命名空间?
应用程序运行环境隔离的空间,就是一个命名空间,每一个空间都将拥有UTS、IPC、Mount 、 Net、User、PID
Control Groups
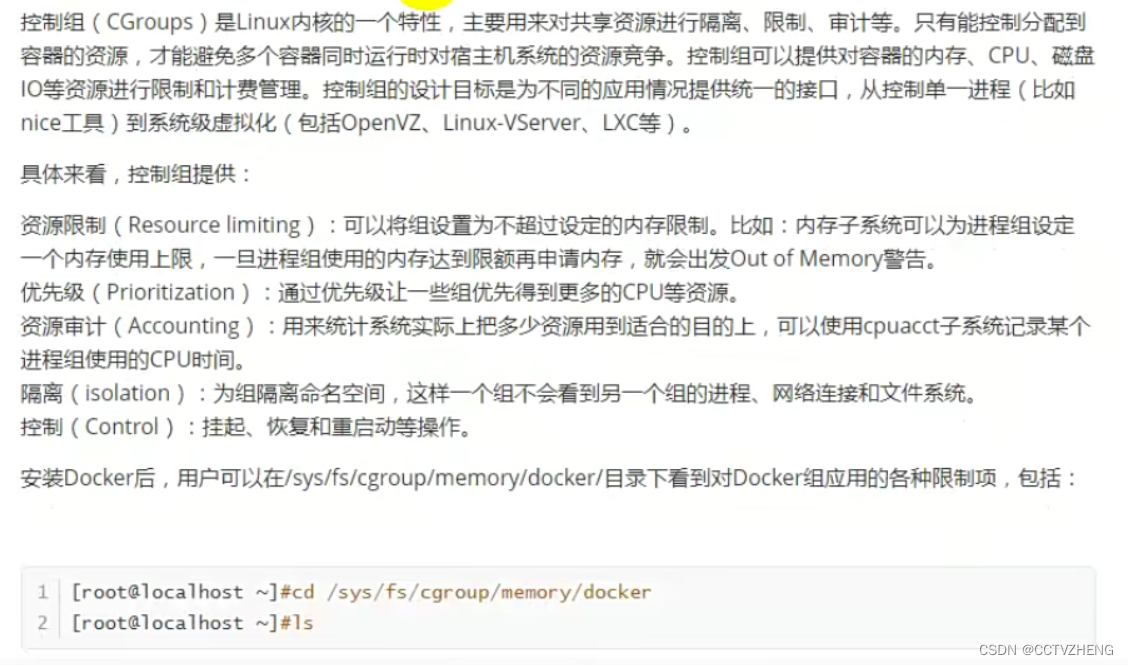
PAM资源限制
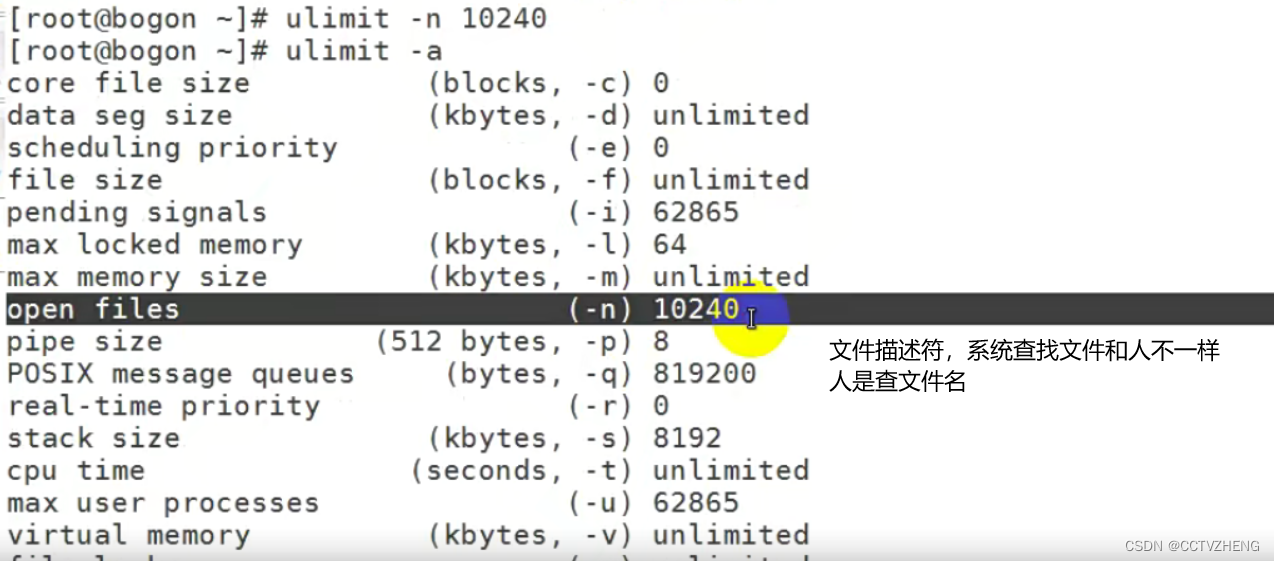
CGroups资源限制是针对进程的,主要是CPU和内存

CGroups九大子系统

总结
9大子系统
把资源定义为子系统,可以通过子系统对资源进行限制
CPU 可以控制进程使用CPU的比例,1024等份一分钟,每秒各进程占用cpu都是分比例分配的
memory 限制内存使用,例如50Mi,150Mi
blkio 限制块设备的IO,也就是限制IO流的带宽
cpuacct 生成Cgroup使用CPU的资源报告,显示各子系统占用的CPU资源
cpuset 用于多CPU执行Cgroups时,对进程进行CPU分组,例如nginx使用4颗,tomcat2颗
应用程序分配到的CPU越多,响应不一定越快
部署CGroup
第一步:安装cgroup
yum -y install libcgroup*

devel开发包和tools工具包都必须安装
第二步:cgconfig的开机自启设置
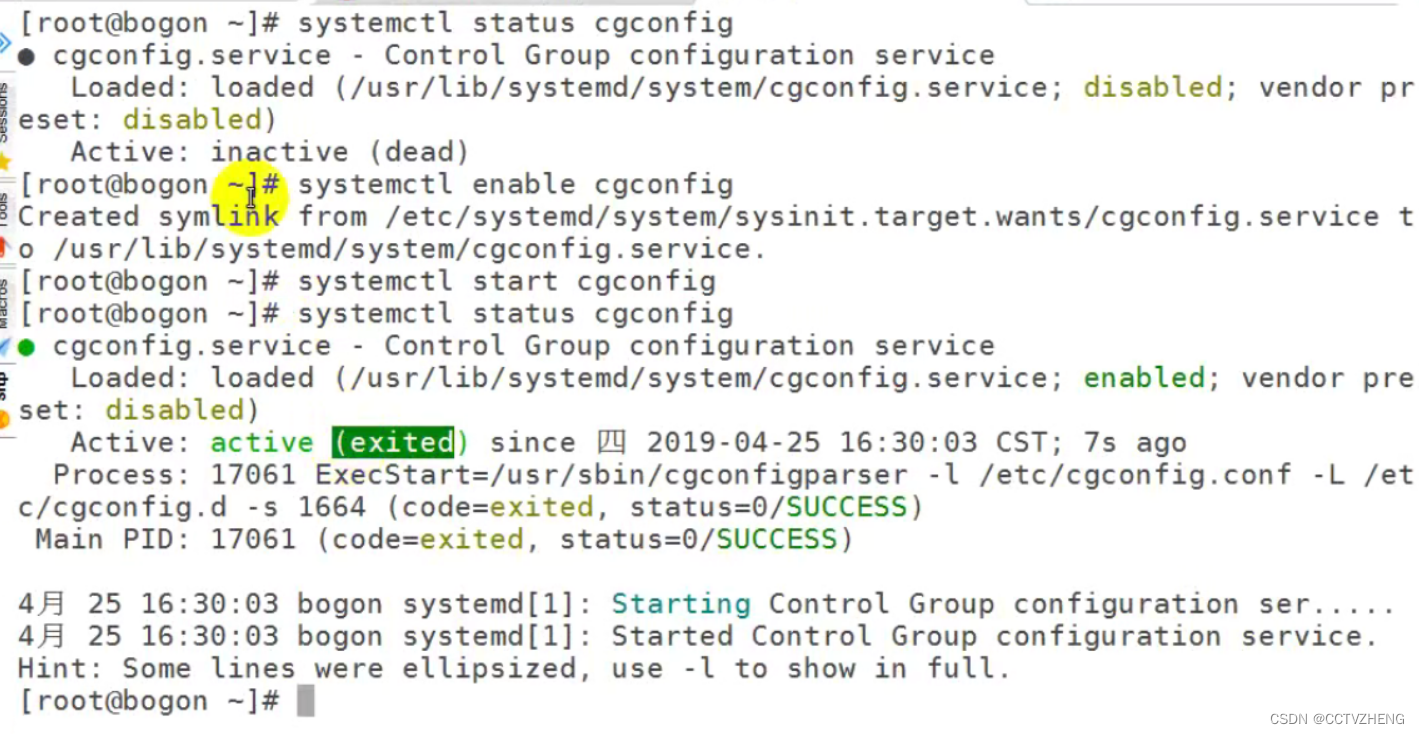
cgroup限制步骤
1.创建cgroup,定义相应的限制
2.分配进程到cgroup

定义两个cpu子系统的cpu占用分片

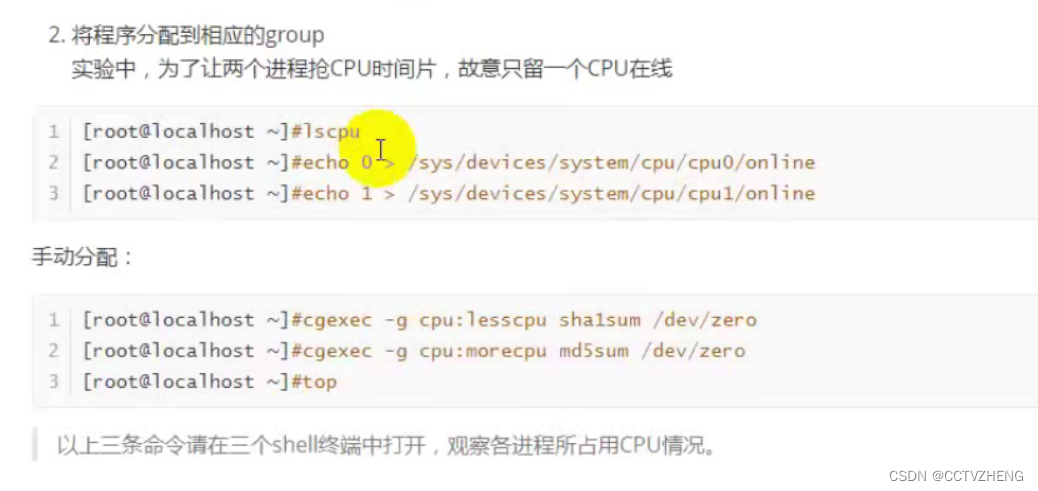
通过md5sum 进行入侵检测,判断文件是否被修改过

md5和sha1都可以计算文件的哈希值
黑洞/dev/null 白洞/dev/zero 白洞的数据是无穷无尽的适合用来测试
md5计算白洞的值一直会增加,可以测试cgroup是否能控制cpu的资源分配
可以在主机里面同时用md5和sha1计算白洞,产生两个进程
然后top查看cpu负载
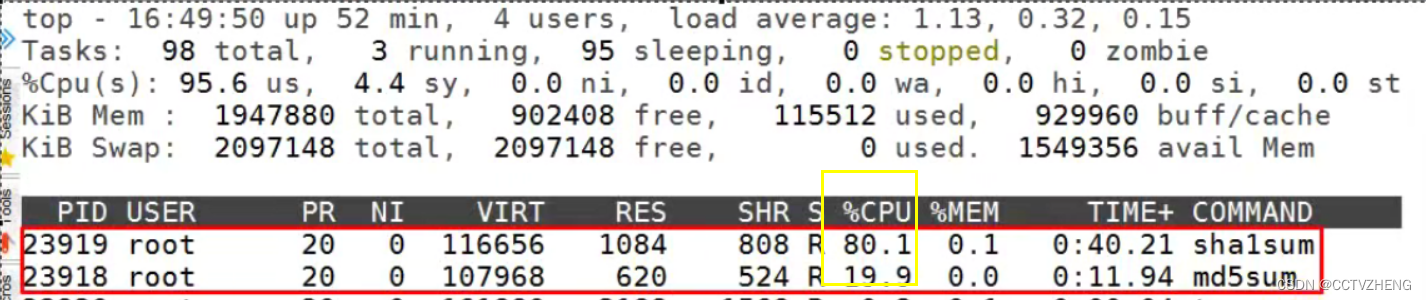
注意,运行进程之前必须分组:
之前创建了两个cpu子系统的cgroup组,和手动分配CPU占用率,1024等份就是1000分之200和800,20%和80%,限制了两个算法进程的CPU资源,这就是利用cgroup限制进程对CPU的使用。

Linux系统中有物理内存mem和swap虚拟内存,限制内存必须一起,要不然无效

total:机器总内存量;
used:以用内存(tips: 包括划出来的缓存);
free:未使用内存;
shared:共享内存;
buffers:缓冲区内存;
cached:缓存;
其中:
物理已用内存 = 实际已用内存 - 缓冲 - 缓存 = 48G - 3.2G - 31G
物理空闲内存 = 总物理内存 - 实际已用内存 + 缓冲 + 缓存
应用程序可用空闲内存 = 总物理内存 - 实际已用内存
应用程序已用内存 = 实际已用内存 - 缓冲 - 缓存
一般都看第二行: -/+ buffers/cache :第一个是-代表物理内存已使用多少,第二个是+代表空闲
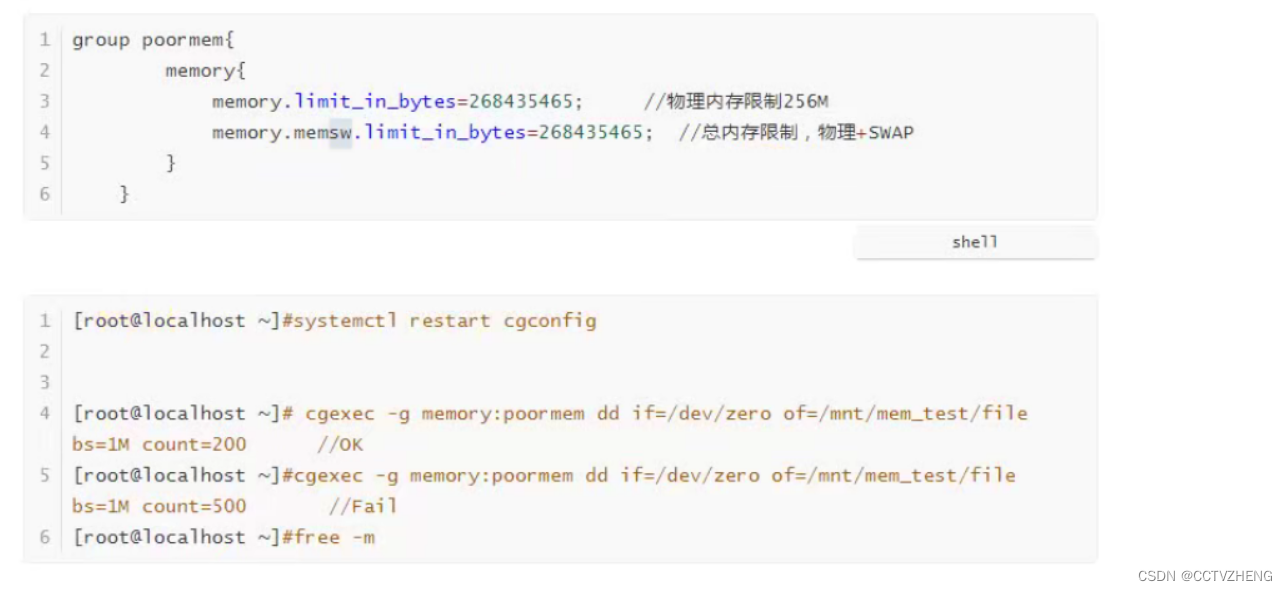
memory.memsw.limit_in_bytes=值; 限制虚拟内存swap分区
如果这个memsw限制的值减去物理内存限制的值,产生的差值就是swap空间提供的内存
cgroup限制容器的资源
已经挂载的要umount解挂之后才能重新挂载
文件缓存tmpfs
基于内存的文件系统,直接使用ram(物理内存)+swap(交换分区)
tmpfs缓存文件系统:动态的使用虚拟内存,文件删除后释放内存,没有持久性(重启失效)
2007年-Control Groups
Control Groups也就是谷歌实现的cgroups,其于2007年被添加至Linux内核当中。















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









