






(刚开始学这方面知识,如有错误,请大家指正)
一、课堂代码+运行结果
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0])
w.requires_grad = True
def forward(x):
return w * x
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
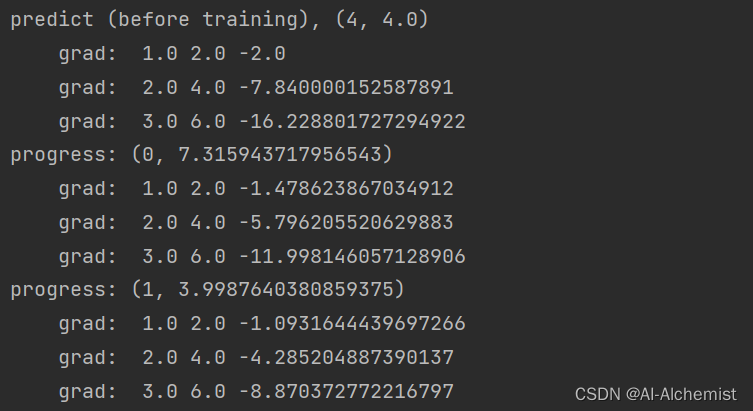
print(f"predict (before training), {4, forward(4).item()}")
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward()
print("\tgrad: ", x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_()
print(f"progress: {epoch, l.item()}")
print(f"predict (after training), {4, forward(4).item()}")
二、课后作业
模型:
损失函数:
训练集:输入=[1, 2, 3],输出=[2, 4, 6]
测试集:输入=4,猜测输出应该是8
利用计算图,算出
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w1 = torch.tensor([1.0])
w2 = torch.tensor([1.0])
b = torch.tensor([1.0])
w1.requires_grad = True
w2.requires_grad = True
b.requires_grad = True
# 前向传播
def forward(x):
return w1 * x * x + w2 * x + b
# 损失
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
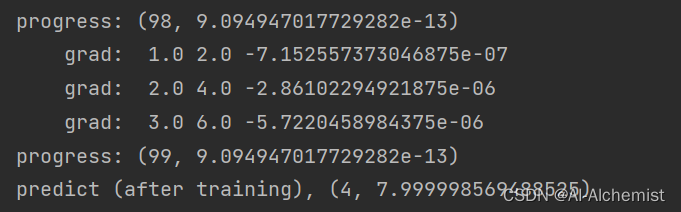
print(f"predict (before training), {4, forward(4).item()}")
# 可以改变range 100 1000 10000 100000 对比效果
for epoch in range(10000):
for x, y in zip(x_data, y_data):
l = loss(x, y)
# 反向传播,求梯度
l.backward()
# 利用梯度更新w1, w2, b
w1.data -= 0.01 * w1.grad.data
w2.data -= 0.01 * w2.grad.data
b.data -= 0.01 * b.grad.data
# print(f"progress: w1 = {w1.data}, w2 = {w2.data}, b = {b.data}")
# 将w1, w2, b的梯度置为0
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
print(f"predict (after training), {4, forward(4).item()}") # 理想是 4, 8
训练次数为100时:

训练次数为1000时:

训练次数为10000时:

训练次数为100000时:(预测与理想越来越接近)

计算图:
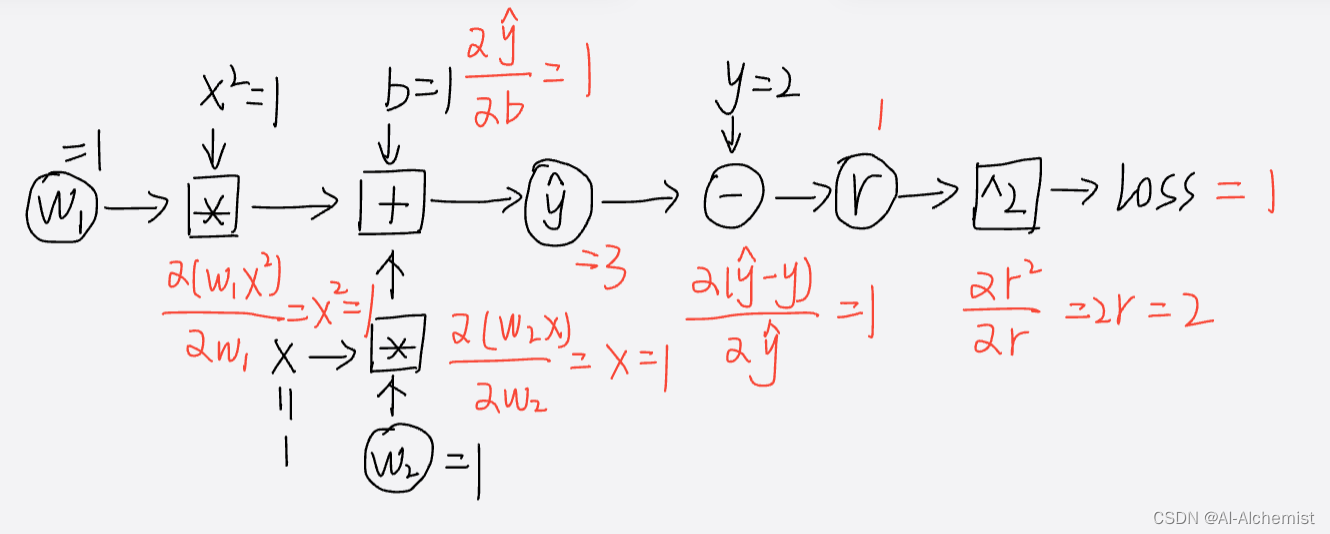
(在 x = 1的情况下)















 9500
9500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









