







链家比起boss和拉勾更好爬
这次使用beautifulsoup+requests爬取链家深圳的租房信息,并进行可视化分析。
一、爬取
代码如下:
import requests
from bs4 import BeautifulSoup
import csv
headers={
'Accept': 'xxx',
'User-Agent':'xxx'
}
price_list=[]
detail_list=[]
brand_list=[]
tag_list=[]
title_list=[]
head=['title','detail','price','brand','tag']
for page in range(1,101):
url='https://sz.lianjia.com/zufang/pg'+str(page)
res= requests.get(url,headers=headers)
# res.status_code
soup=BeautifulSoup(res.text,'html.parser')
#找到最小父级标签info
info=soup.find_all('div',class_="content__list--item--main")
for i in info:
#价格
price = i.find('span',class_="content__list--item-price").text
price_list.append(price)
#房间大小,朝向,区域的集合
detail=i.find('p',class_='content__list--item--des').text.strip()
detail_list.append(detail)
#品牌
brand=i.find('span',class_='brand')
brand_list.append(brand)
#描述标签
tag=i.find('p',class_='content__list--item--bottom oneline').text
tag_list.append(tag)
#标题,用来提取合租与否
title=i.find('p',class_='content__list--item--title twoline').text
title_list.append(title)
#保存下
rows =zip(title_list,detail_list,price_list,brand_list,tag_list)
csv_file=open('lj.csv','w',newline='',encoding='gbk')
writer=csv.writer(csv_file)
writer.writerow(head)
for row in rows:
writer.writerow(row)
csv_file.close()
print('finished')
爬取完之后是这样的:

二、处理
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
lj=pd.read_csv('xxx/lj.csv', encoding ='gbk')
#去重
lj=lj.drop_duplicates()
#填充缺失值
lj['brand']=lj['brand'].fillna('N/A')
#detail的处理,分割
lj.detail.str.split('/')

#先分出第一部分(区域),将其分再拆解
lj['d_part']=lj.detail.str.split('/').str[0].str.strip()
lj['d_part']

#拆解第一部分为:区 district,位置 area,小区 location
lj['district']=lj.d_part.str.split('-').str[0]
lj['area']=lj.d_part.str.split('-').str[1]
lj['location']=lj.d_part.str.split('-').str[2]
#继续分解detail
lj['square']=lj.detail.str.split('/').str[1].str.strip()
lj['orientation']=lj.detail.str.split('/').str[2].str.strip()
lj['rooms']=lj.detail.str.split('/').str[3].str.strip()
lj.detail.str.split('/').str[4].str.strip()
#去除中间的空格
lj['floor_hight']=lj.detail.str.split('/').str[4].str.strip()
lj['floor_hight']=lj['floor_hight'].str.replace(' ','')
lj['brand']=lj['brand'].str.strip()
#调整顺序,删掉多余列
del lj['detail']
del lj['d_part']
lj['price_']=lj['price']
lj['brand_']=lj['brand']
lj['tag_']=lj['tag']
del lj['price']
del lj['brand']
del lj['tag']
#租房形式:合租还是整租
lj['type']=lj['title'].str.split('·').str[0].str.strip()
#调整顺序,删掉多余列
del lj['title']
lj['tag']=lj['tag_']
del lj['tag_']
#对价格进行统一化,使用价格除以面积,得到每平方米的租房价格
lj['s1']=lj['square'].str.extract(('.*?(\d.*\d)'),expand=False).astype('float32')
#使用正则'.*?(\d.*\d)'只能找到平方面积是2位数以上的,如果是1位数的找不到,所以再次使用正则
lj['s2']=lj['square'].str.extract(('.*?(\d)'),expand=False).astype('float32')
lj['s1']=lj['s1'].fillna(lj['s2'])
lj=lj.drop(lj[lj['price_'].str.contains('-')].index)
lj['p']=lj['price_'].str.extract(('.*?(\d.*\d)'),expand=False).astype('float32')
lj['yuan/m2']=(lj['p']/lj['s1'])
brand这一列说一下
我之前也有贴子说明如何对文本数据进行清洗,感兴趣的朋友可以移步至pandas中文本数据的拆分和提取
lj.brand_.value_counts()
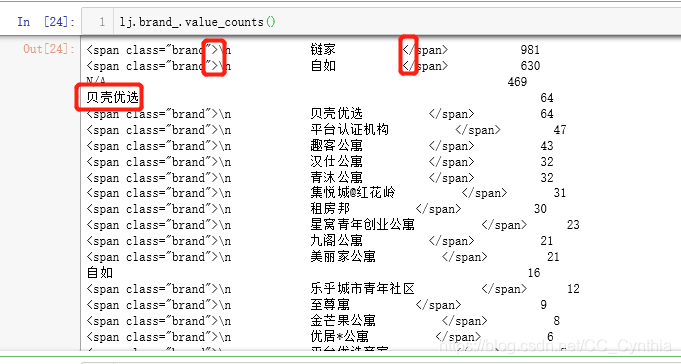
这样处理
lj['b1']=lj.brand_.str.split('>').str[0]
lj['b2']=lj.brand_.str.split('>').str[1]
lj['b3']=lj.b2.str.split('<').str[0]
lj['b2']=lj['b2'].fillna(lj['b3'])
lj['brand']=lj['b2'].str.split('<').str[0].str.strip()
lj['brand']=lj['brand'].fillna(lj['b1'])
del lj['b1']
del lj['b2']
del lj['b3']
lj['brand'].value_counts()
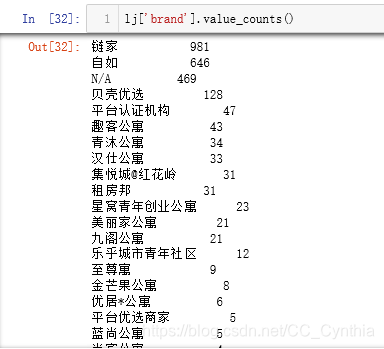
搞定!
存一下
lj.to_csv('C:/Users/xxx/lj_afterwash.csv',index=False, encoding='gbk')
三、数据可视化
工具:power BI
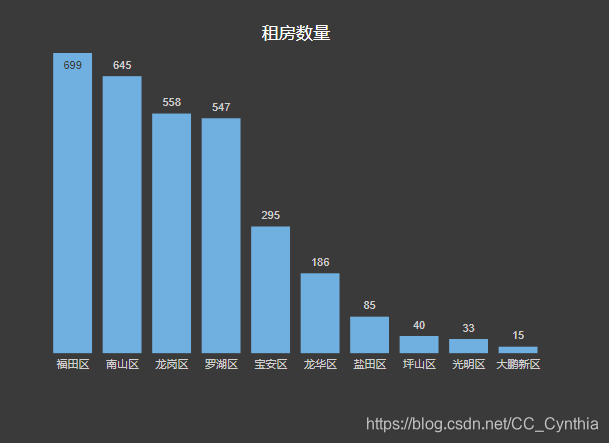
1、不同区的租房数量及价格
链家房源主要集中在福田、南山,龙岗,罗湖四个区域;到宝安区和龙华区房屋数量急剧减少,但也有200-300个左右的房源;其他区发布数量均少于100。
来看下价格:
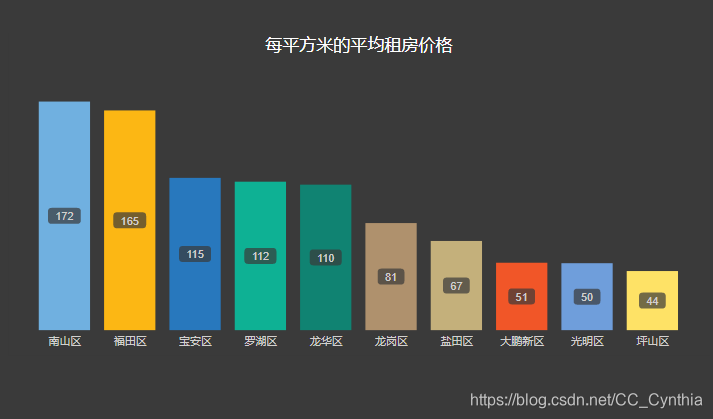
距离深圳中心区域——福田区越远的区,价格越便宜。
值得注意的是,上文提到的房源最多的区域之一——龙岗的价格约为南山福田的一半,似乎是个不错的选择。
不过,龙岗区面积很大,横岗以东到中心区域距离很远,可能存在距离远价格低的房子拉低平均价格的可能性,看下图方差表现:
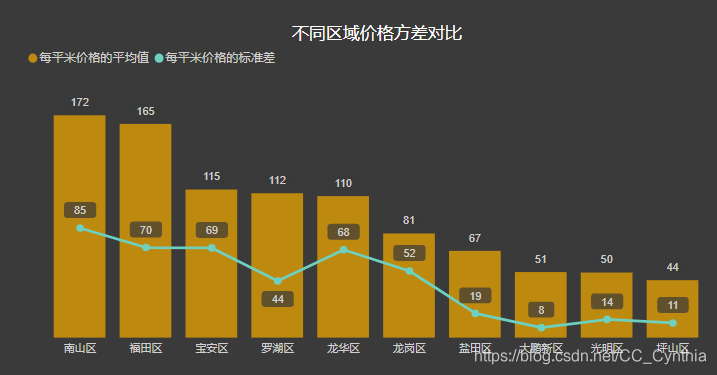
可以得出,相较于南山和福田,龙岗区的价格与平均价格离散程度小,确实是个不错的选择。
另外,深圳的朋友也可以用这个图片测算下自己租的房子性价比如何。
2、租房形式
总的来说,整租的房源是多于合租的房源的,除了盐田区55开之外,基本上都是30%-70%的比例。
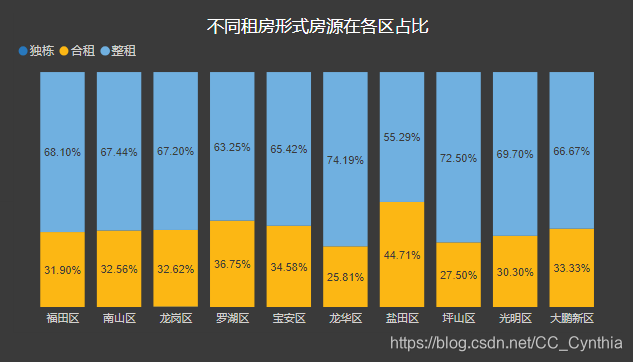
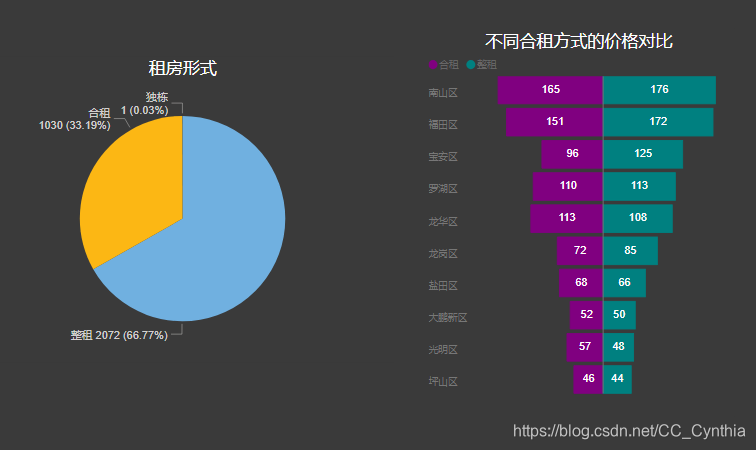
那么,合租和整租,选择哪个呢?
对于房源多的南山,福田,罗湖,龙岗,宝安来说,合租比整租便宜;
其他区域整租比合租便宜。
3、品牌
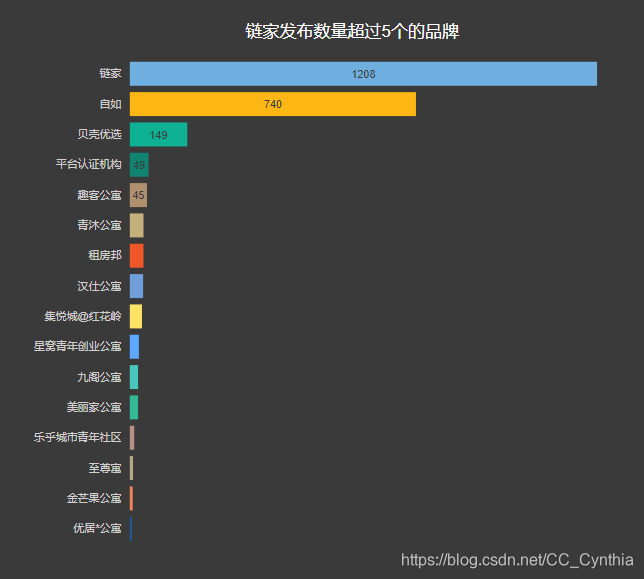
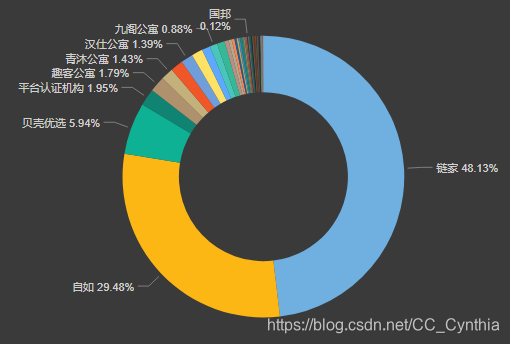
链家网仍以自主品牌为主导,除却链家(48.13%)、自如(29.48%)、贝壳(5.94%)之外,其他平台房源占比不到20%。
4、房子类型(厅室)
单间(1室n厅n卫)的数量最多,其次是4室的户型(数量500+)和2室的小户型(数量300+);
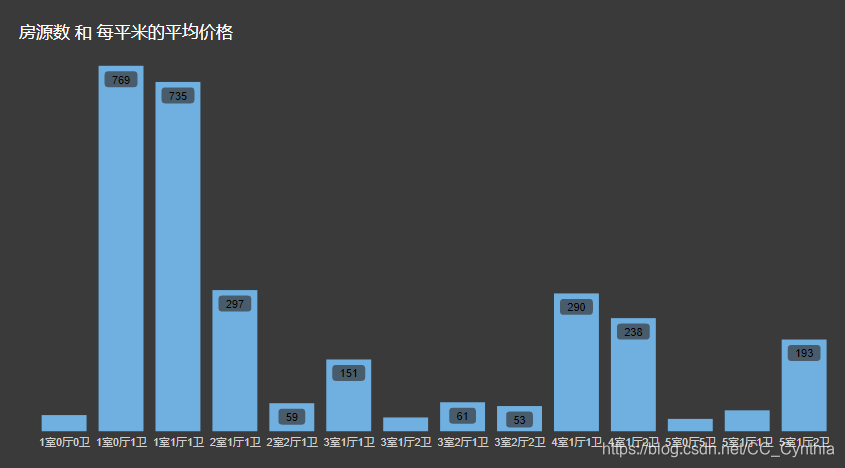
哪种房型价格最优呢?
从整租的形式来看:
小户型(1-2室)和3室除3室1厅1卫外的房型每平米价格低于110元;
价格最的是4室1厅1卫和4室1厅2卫每平米价格是小户型的2倍左右。
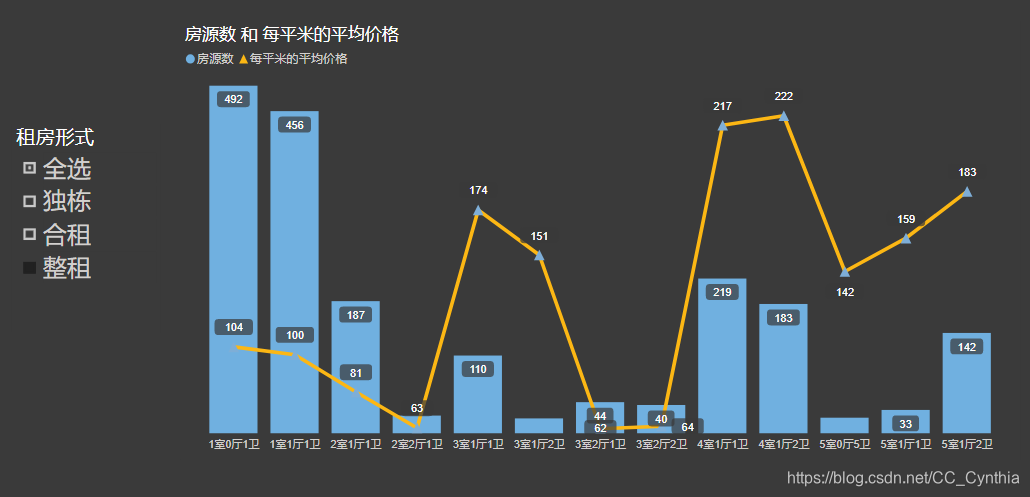
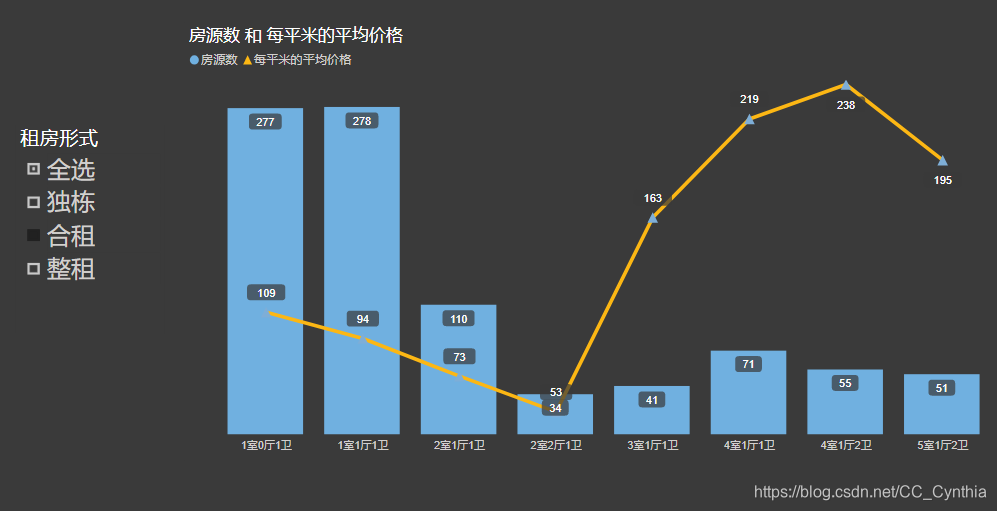
从合租的形式来看:
2居室小户型价格尤为划算,最低至53元/m2,优于整租;
3-5室的合租每平米价格高于整租,在160-240元/m2的区间;
四、文本可视化
工具:python 词云

“随时看房,官方核验,地铁,公寓,精装”字字醒目。这是链家认为用户关注的最核心,即:房子的品牌,质量,管理和交通;
次一级是“阳台,月租,独立卫浴,一付”,这些代表用户次要关注点是房间设施,生活便利,付费方式。
我们也可以反向利用这些标签去评估候选的房子。














 6724
6724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









