







文章目录
6462.最小化字符串长度
给你一个下标从 0 开始的字符串 s ,重复执行下述操作 任意 次:
- 在字符串中选出一个下标
i,并使c为字符串下标i处的字符。并在i左侧(如果有)和 右侧(如果有)各 删除 一个距离i最近 的字符c。
请你通过执行上述操作任意次,使 s 的长度 最小化 。
返回一个表示 最小化 字符串的长度的整数。
示例 1:
输入:s = "aaabc"
输出:3
解释:在这个示例中,s 等于 "aaabc" 。我们可以选择位于下标 1 处的字符 'a' 开始。接着删除下标 1 左侧最近的那个 'a'(位于下标 0)以及下标 1 右侧最近的那个 'a'(位于下标 2)。执行操作后,字符串变为 "abc" 。继续对字符串执行任何操作都不会改变其长度。因此,最小化字符串的长度是 3 。
- 这道题最简单的做法是直接用哈希表map把原字符串塞进去,由于unordered_map本身就有key去重的特性,因此map中的key就是最后的结果。用result存放map中的key即可。
class Solution {
public:
int minimizedStringLength(std::string s) {
unordered_map<char, int> map;
for (int i = 0; i < s.size(); i++) {
map[s[i]]++;
}
string result = "";
for (auto it = map.begin(); it != map.end(); ++it) {
result += it->first;
}
return result.size();
}
};
6424.半有序排列
给你一个下标从 0 开始、长度为 n 的整数排列 nums 。
如果排列的第一个数字等于 1 且最后一个数字等于 n ,则称其为 半有序排列 。你可以执行多次下述操作,直到将 nums 变成一个 半有序排列 :
选择 nums 中相邻的两个元素,然后交换它们。
返回使 nums 变成 半有序排列 所需的最小操作次数。
排列 是一个长度为 n 的整数序列,其中包含从 1 到 n 的每个数字恰好一次。
输入:nums = [2,1,4,3]
输出:2
解释:可以依次执行下述操作得到半有序排列:
1 - 交换下标 0 和下标 1 对应元素。排列变为 [1,2,4,3] 。
2 - 交换下标 2 和下标 3 对应元素。排列变为 [1,2,3,4] 。
可以证明,要让 nums 成为半有序排列,不存在执行操作少于 2 次的方案。
示例 2:
输入:nums = [2,4,1,3]
输出:3
解释:
可以依次执行下述操作得到半有序排列:
1 - 交换下标 1 和下标 2 对应元素。排列变为 [2,1,4,3] 。
2 - 交换下标 0 和下标 1 对应元素。排列变为 [1,2,4,3] 。
3 - 交换下标 2 和下标 3 对应元素。排列变为 [1,2,3,4] 。
可以证明,要让 nums 成为半有序排列,不存在执行操作少于 3 次的方案。
示例 3:
输入:nums = [1,3,4,2,5]
输出:0
解释:这个排列已经是一个半有序排列,无需执行任何操作。
思路
这道题主要是把确定的两个数字1和n分别移动到数组的两侧,假设1的下标是p,n的下标是q,有两种情况:
- p<q,那么1和n只需要分别移动到数组两头即可,操作次数为n-1-q+p
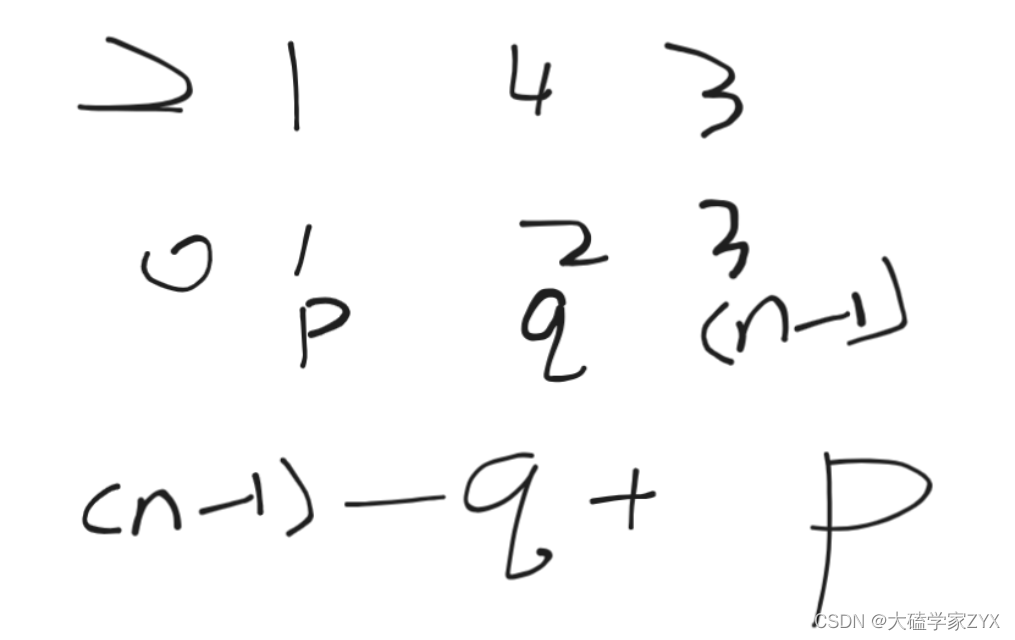
p>q,1和n的移动次数为n-1-q+p-1,因为我们要计算的是移动元素的操作次数,而例子中1和n的大小交换本身就算一次操作次数!
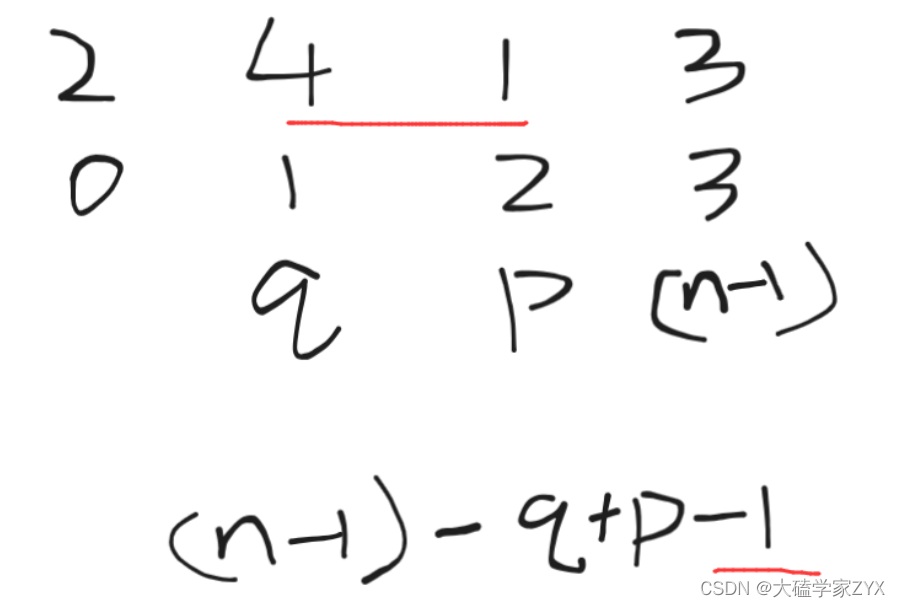
class Solution {
public:
int semiOrderedPermutation(vector<int> &nums){
int n = nums.size();
int flag=0;
//在vector数组中找到1的元素下标
auto p = find(nums.begin(),nums.end(),1);
//vector数组中找到n的元素下标
auto q = find(nums.begin(),nums.end(),n);
if(p<q) flag = 0;
if(p>q) flag = 1;
//注意问题:p和q是迭代器类型!迭代器不能直接作为整型运算,需要用distance做转换!
int result = n - 1 - distance(nums.begin(), q) + distance(nums.begin(), p) - flag;
return result;
}
}
补充1:vector_find()方法返回想要查找的元素下标
在哈希表中了解过find()方法可以用来查找set或者map中key指定的元素,例如:
int main() {
std::unordered_set<int> set;
set.insert(1);
set.insert(2);
set.insert(3);
if(set.find(2) != set.end()) {
std::cout << "2 is in the set" << std::endl;
}
return 0;
}
int main() {
std::unordered_map<std::string, int> map;
map["Alice"] = 18;
map["Bob"] = 20;
if(map.find("Alice") != map.end()) {
std::cout << "Alice is " << map["Alice"] << " years old." << std::endl;
}
return 0;
}
//两个数组的交集题目
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int>result;
unordered_set<int>nums_set(nums1.begin(),nums1.end());
//可以使用数组的begin和end直接放进set容器里
//遍历nums2
for(int i=0;i<nums2.size();i++){
if(nums_set.find(nums2[i])!=nums_set.end()){
result.insert(nums2[i]); //set的insert用法
}
}
//返回result,直接使用vector的容器转换
return vector<int>(result.begin(),result.end());
}
//两数之和题目
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int>map;
for(int i=0;i<nums.size();i++){
int s=target-nums[i];
auto iter = map.find(s); //注意auto这种方式
if(map.find(s)!=map.end()){
return {iter->value,i};
}
map.insert(nums[i],i);
}
return {};//找不到返回空集合
}
find()是一个模板函数,用于在指定范围内查找和目标元素值相等的第一个元素。
find()属于头文件中的算法,可以作用于所有的序列式容器,例如数组,vector,list等。
容器是否可以直接用find(),这要看容器的元素是否支持运算符,因为find()的底层实现就是用运算符将目标元素和范围内的元素逐个进行比较。
需要注意的是,find() 返回的是一个迭代器,而不是元素的下标。在上面的代码中,我们使用 auto 关键字来推断 p 和 q 的类型,它们实际上是迭代器类型。为了将迭代器转换为整型,在进行数值计算之前我们使用了 distance() 函数,该函数返回两个迭代器之间的距离(即它们之间相差的元素个数),从而可以将迭代器转换为整型。
STL算法
参考:STL 算法 - OI Wiki (oi-wiki.org)
STL 提供了大约 100 个实现算法的模版函数,基本都包含在 <algorithm> 之中,还有一部分包含在 <numeric> 和 <functional>。完备的函数列表请 参见参考手册,排序相关的可以参考 排序内容的对应页面。
-
find:顺序查找。find(v.begin(), v.end(), value),其中value为需要查找的值。auto p = find(nums.begin(),nums.end(),1); iterator find(iterator first, iterator last, const T& value); -
find_end:逆序查找。find_end(v.begin(), v.end(), value)。 -
reverse:翻转数组、字符串。reverse(v.begin(), v.end())或reverse(a + begin, a + end)。 -
unique:去除容器中相邻的重复元素。unique(ForwardIterator first, ForwardIterator last),返回值为指向 去重后 容器结尾的迭代器,原容器大小不变。与sort结合使用可以实现完整容器去重。 -
random_shuffle:随机地打乱数组。random_shuffle(v.begin(), v.end())或random_shuffle(v + begin, v + end)。(
random_shuffle自 C++14 起被弃用,C++17 起被移除。在 C++11 以及更新的标准中,可以使用
shuffle函数代替原来的random_shuffle。使用方法为shuffle(v.begin(), v.end(), rng)(最后一个参数传入的是使用的随机数生成器,一般情况使用以真随机数生成器random_device播种的梅森旋转伪随机数生成器mt19937)。)
sort:排序。sort(v.begin(), v.end(), cmp)或sort(a + begin, a + end, cmp),其中end是排序的数组最后一个元素的后一位,cmp为自定义的比较函数。stable_sort:稳定排序,用法同sort()。nth_element:按指定范围进行分类,即找出序列中第 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MdB49Qg2-1685906051953)(data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)] 大的元素,使其左边均为小于它的数,右边均为大于它的数。nth_element(v.begin(), v.begin() + mid, v.end(), cmp)或nth_element(a + begin, a + begin + mid, a + end, cmp)。binary_search:二分查找。binary_search(v.begin(), v.end(), value),其中value为需要查找的值。
补充2:迭代器类型转化为整数
int result = n - 1 - q + p - flag,写法错误,因为p和q是迭代器不能直接投入运算,需要把迭代器转化为对应的整数下标,如:
int result = n - 1 - distance(nums.begin(), q) + distance(nums.begin(), p) - flag;
distance(nums.begin(), q) 返回的是 nums.begin() 和 q 之间的距离,也就是 q 在向量 nums 中的位置(从 nums.begin() 开始算)。因此,它返回的是 q 的下标(整数值),而不是迭代器。在上面的代码中,我们使用 distance(nums.begin(), q) 来获取 q 在向量 nums 中的位置,并将其转换为整数类型,以便进行数值计算。
除了 distance() 函数外,还可以使用迭代器的 operator- 运算符来计算两个迭代器之间的距离。例如,对于迭代器 it1 和 it2,可以使用 it2 - it1 来计算它们之间的距离,返回一个整型值。
std::vector<int> v = {1, 2, 3, 4, 5};
auto it1 = v.begin(); // 指向第一个元素的迭代器
auto it2 = v.end(); // 指向尾后元素的迭代器
int dist = it2 - it1; // 计算迭代器距离
需要注意的是,不是所有类型的迭代器都支持 operator- 运算符。只有随机访问迭代器(如 vector、array 等,也就是序列式容器)才支持该运算符。对于其他类型的迭代器(如 list、set 等),只能使用 distance() 函数来计算距离。
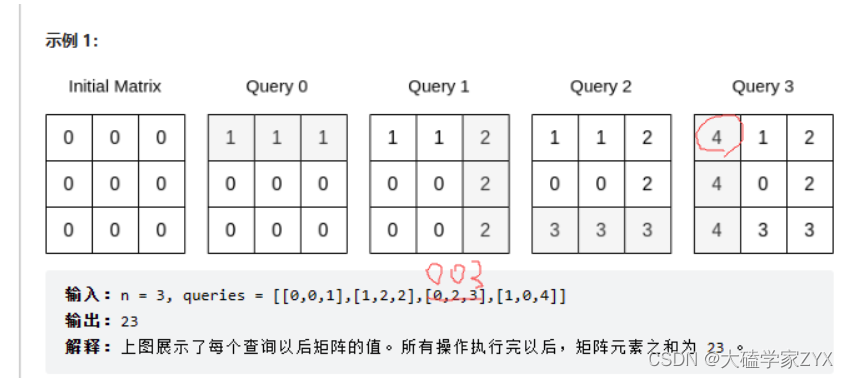
6472.查询后矩阵的和
给你一个整数 n 和一个下标从 0 开始的 二维数组 queries ,其中 queries[i] = [typei, indexi, vali] 。
一开始,给你一个下标从 0 开始的 n x n 矩阵,所有元素均为 0 。每一个查询,你需要执行以下操作之一:
如果 typei == 0 ,将第 indexi 行的元素全部修改为 vali ,覆盖任何之前的值。
如果 typei == 1 ,将第 indexi 列的元素全部修改为 vali ,覆盖任何之前的值。
请你执行完所有查询以后,返回矩阵中所有整数的和。
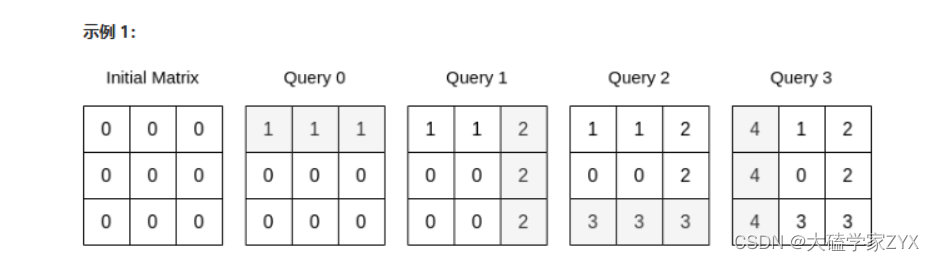
输入:n = 3, queries = [[0,0,1],[1,2,2],[0,2,3],[1,0,4]]
输出:23
解释:上图展示了每个查询以后矩阵的值。所有操作执行完以后,矩阵元素之和为 23 。
思路
-
这道题的思路一个很重要的点是,题目只需要求所有整数的和,不需要矩阵的覆盖是正确的!倒序遍历的做法会导致矩阵的覆盖是错误的,但是我们并不需要考虑最终的矩阵是不是覆盖正确的矩阵,我们只需要求和就可以了。
- 这也是我看题解的时候迟迟不能理解倒序遍历的原因,我没有注意到,这个矩阵并不需要输出的本身是覆盖正确的结果,只需要和正确就可以。
-
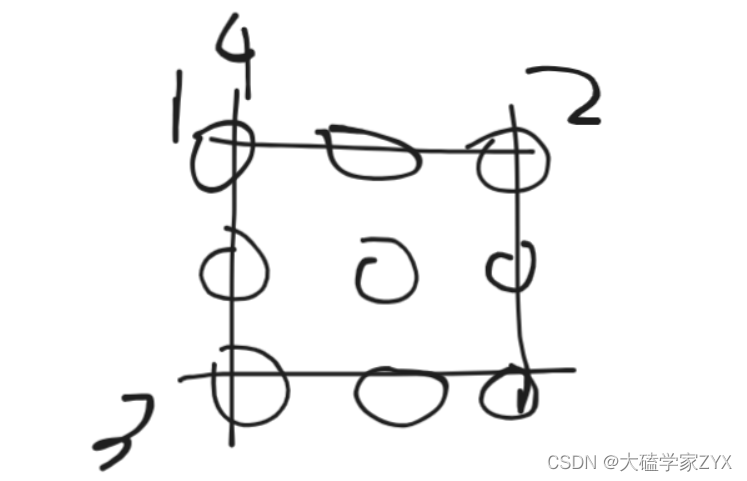
只有后面的修改是生效的,前面的部分即使修改了,也会被覆盖掉,例如下图中
[0][0]位置的元素,会被4覆盖掉。 -
因此,我们可以考虑,如果先遍历queries中的4,也就是从后向前遍历,意味着直接就能得到一个位置上的最终结果。比起每一个位置遍历检查覆盖,时间复杂度大大优化。
-
对于一个倒序遍历到的元素,需要知道:
-
进行的是行操作还是列操作,
queries[k][0]是0还是1 -
这一行之前有没有被处理过(之前指的是大于i的操作),
rowSet.find(queries[k][1])是否存在 -
用两个哈希表记录已经被处理过的行/列号。
-
完整版
class Solution {
public:
long long matrixSumQueries(int n, vector<vector<int>>& queries) {
std::unordered_set<int> rowSet; // 记录操作过的行
std::unordered_set<int> colSet; // 记录操作过的列
int m = queries.size();
long sum = 0; // 计算矩阵和
for (int k = m - 1; k >= 0; k--) { // 倒序遍历
// 当前处理行且行未被处理过
if (queries[k][0] == 0 && rowSet.find(queries[k][1]) == rowSet.end()) {
sum += (n - colSet.size()) * static_cast<long>(queries[k][2]); // 这一行的元素和等于未被处理的列数 * 赋予的值
rowSet.insert(queries[k][1]); // 添加该行已处理
}
// 当前处理列且列未被处理过
if (queries[k][0] == 1 && colSet.find(queries[k][1]) == colSet.end()) {
sum += (n - rowSet.size()) * static_cast<long>(queries[k][2]); // 这一列的元素和等于未被处理的行数 * 赋予的值
colSet.insert(queries[k][1]); // 添加该列已处理
}
}
return sum;
}
};
(n - colSet.size())代表的是该行中未经处理的元素个数。这些元素的值都是矩阵中原来就存在的元素,因此需要将它们乘以该行操作赋予的值queries[k][2],然后将结果累加到sum中。- 同样地,如果当前处理的是列操作且该列未被处理过,那么
(n - rowSet.size())表示该列中未被查询操作覆盖的行数,即该列中未被处理的元素个数。
问题:如果对于同一个元素,查询操作是先对列进行操作,再对行进行操作,那么倒序遍历查询操作的时候,会先遍历到行操作,再遍历到列操作,覆盖错误?
例如下图的情况,对于左上角元素4,是先行操作再列操作,但是倒序遍历会使得4这个元素的位置覆盖是错误的。
覆盖错误是会出现的,但是,这道题目的含义是求解矩阵中所有矩阵的和,并不需要覆盖正确。当求和的时候,4所在的行已经被排除掉了,4的覆盖错误并不会影响最后的求和。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









