







739.每日温度
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
示例 1:
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]
示例 2:
输入: temperatures = [30,40,50,60]
输出: [1,1,1,0]
示例 3:
输入: temperatures = [30,60,90]
输出: [1,1,0]
提示:
1 <= temperatures.length <= 10^530 <= temperatures[i] <= 100
栈数据结构
首先复习一下栈,栈是一种容器适配器,并不属于容器。
STL 容器简介 - OI Wiki (oi-wiki.org)
DAY9:栈和队列(一):栈和队列基础_大磕学家ZYX的博客-CSDN博客

栈基本上能够使用的成员函数只有访问栈顶,插入栈顶元素和弹出栈顶元素。
单调栈思路
单调栈就适用于找某个元素左面或者右面,第一个比它大或者比它小的元素。
也就是说,一维数组内,要寻找任一元素的右侧或左侧,第一个比自身大或者小的元素位置,此时我们就要想到用单调栈。单调栈时间复杂度为O(n)。寻找的方向,第一个元素是大还是小,都是同一个原理。
单调栈原理
那么单调栈的原理是什么?为什么时间复杂度是O(n),就可以找到每一个元素的右边第一个比它大的元素位置呢?
单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素高的元素,优点是整个数组只需要遍历一次。
更直白来说,就是用一个栈来记录我们遍历过的元素。因为我们遍历数组的时候,我们不知道之前都遍历了哪些元素,以至于遍历一个元素找不到是不是之前遍历过一个更小的,所以我们需要用一个容器(这里用单调栈)来记录我们遍历过的元素。
单调栈注意点
在使用单调栈的时候首先要明确如下几点:
- 单调栈里存放的元素是什么?
单调栈里只需要存放遍历过的元素的下标i就可以了,如果需要使用对应的元素,直接T[i]就可以获取。
在进行新元素与栈顶元素的比较时,其实是T[i]和T[st.top()]的比较!st内部存放的是元素下标!
- 单调栈里元素是递增? 还是递减?
注意单调栈中,顺序的描述为从栈头到栈底的顺序,如果是单调递增栈,那么栈顶部是栈内最小元素。
本题中,我们要找到的是元素右侧第一个比它大的元素,因此我们需要使用单调递增栈。因为只有递增的时候,栈里要加入一个元素i时,才知道栈顶元素在数组中右面第一个比栈顶元素大的元素是i。
即:如果求一个元素右边第一个更大元素,单调栈就是递增的;如果求一个元素右边第一个更小元素,单调栈就是递减的。
判断条件
使用单调栈主要有三个判断条件。
- 当前遍历的元素T[i] < 栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i] = 栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i] > 栈顶元素T[st.top()]的情况
工作过程分析
用temperatures = [73, 74, 75, 71, 71, 72, 76, 73]为例,分析单调递增栈的工作过程。
输出应该为[1,1,4,2,1,1,0,0]。
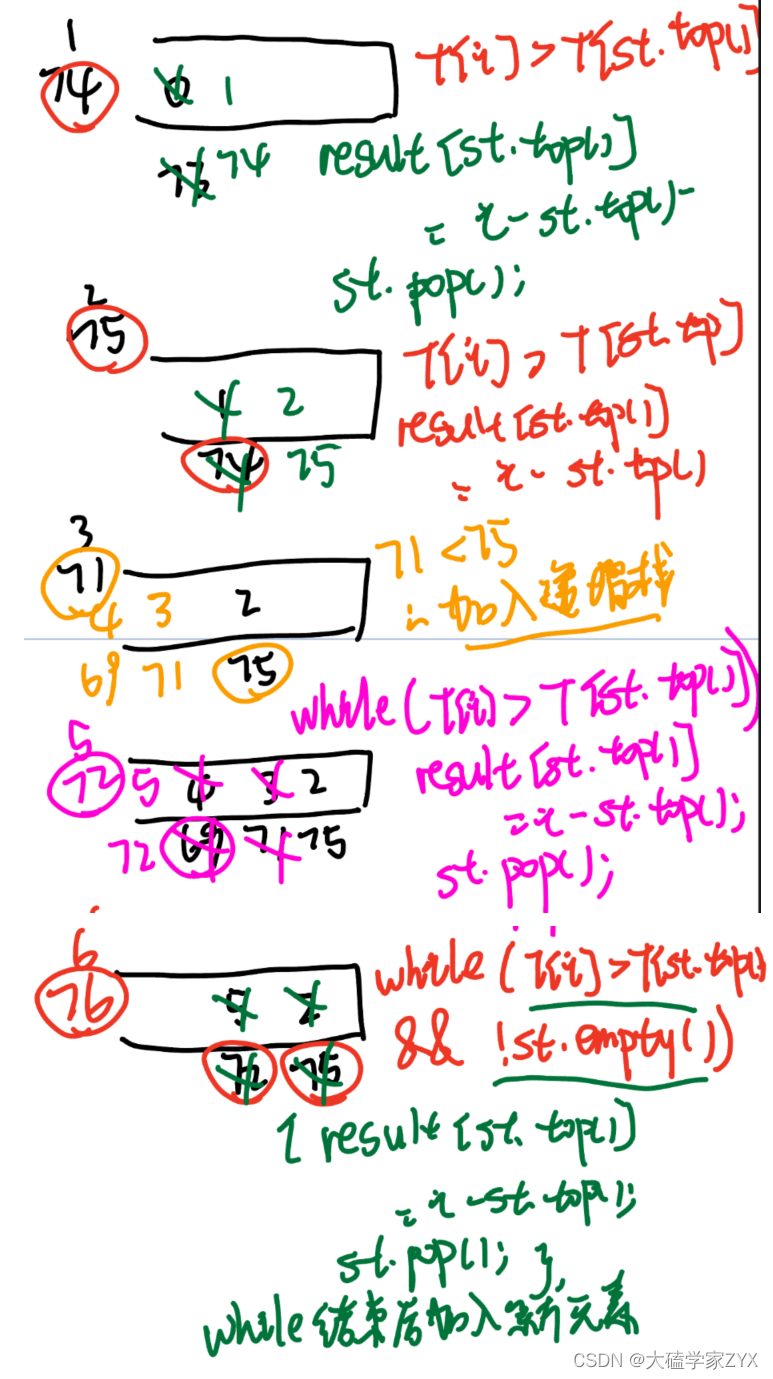
由此可见,当我们找到一个比栈顶元素大的元素时,栈顶元素就会弹出,并且如果下一个栈顶元素还是比当前元素小,会继续弹出,直到当前元素比栈内元素都小,才会加入递增栈中。
这种方法能够找到右侧第一个最大元素,就是因为递增栈的特性,栈内递增所以被弹出的时候,就是找到了第一个比当前元素大的元素!
完整版
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
//建立递增栈
stack<int>st;
st.push(0);//注意栈是存放下标
vector<int>result(temperatures.size(),0);
for(int i=1;i<temperatures.size();i++){
//三种情况
if(temperatures[i]<=temperatures[st.top()]){
st.push(i);
}
else{//大于
while(!st.empty()&&temperatures[i]>temperatures[st.top()]){
result[st.top()]=i-st.top();
st.pop();
}
st.push(i);//while结束之后把新元素放进栈里
}
}
return result;
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
496.下一个更大元素Ⅰ
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
示例 1:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2].
输出:[-1,3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 4 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
- 1 ,用加粗斜体标识,nums2 = [1,3,4,2]。下一个更大元素是 3 。
- 2 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
示例 2:
输入:nums1 = [2,4], nums2 = [1,2,3,4].
输出:[3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 2 ,用加粗斜体标识,nums2 = [1,2,3,4]。下一个更大元素是 3 。
- 4 ,用加粗斜体标识,nums2 = [1,2,3,4]。不存在下一个更大元素,所以答案是 -1 。
提示:
1 <= nums1.length <= nums2.length <= 10000 <= nums1[i], nums2[i] <= 10^4nums1和nums2中所有整数 互不相同nums1中的所有整数同样出现在nums2中
**进阶:**你可以设计一个时间复杂度为 O(nums1.length + nums2.length) 的解决方案吗?
思路
本题和上一题基本相同,区别在于多了两个数组的映射。题目要求,nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
因此我们可以先求nums2中所有元素对应的下一个更大元素,再在结果中,将nums1中的元素值和nums2的key值做映射,nums1中元素值对应的结果,就是nums2的key值对应的value。
映射思路
我们可以利用哈希表将nums2的元素值和该元素值下一个最大元素关联起来。元素值为key,对应的下一个最大元素为value(因为哈希表查找只能查找key)。
实际上,我们也可以用数组来关联nums2的元素值与其下一个最大元素,元素值为下标i,对应下一个最大元素为result[i]。但是,数组内存分布是连续的,如果Nums2里面出现了较大的元素,那么会导致数组下标要开的很大,会浪费大量内存空间。题目中nums2[i]的取值是10^4,说明会有较大的数据,导致数组内存浪费。
如果我们已知元素值的范围并且范围比较小,那么使用数组作为映射可能更优,因为数组提供了更快的访问速度,而且可能更容易实现。但是,如果元素值可能很大,那么数组就不是一个好的选择,因为会浪费大量的内存空间。大多数情况下,如果键和值之间的关系是任意的,那么哈希表通常是更好的选择。
加上题目说了数组内没有重复元素,因此可以用unordered_map(key不可重复)来实现。
完整版
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
stack<int>st;
vector<int>result(nums1.size(),-1);
unordered_map<int,int>umap;//哈希表作为nums2的元素值-结果值映射存储
st.push(0);
for(int i=1;i<nums2.size();i++){
if(nums2[i]<=nums2[st.top()]){
st.push(i);
}
else{
while(!st.empty()&&nums2[i]>nums2[st.top()]){
umap[nums2[st.top()]]=nums2[i];//键值对存放元素值-下一个最大元素
st.pop();
}
st.push(i);
}
}
//遍历第一个数组,找元素值相同的,取其键值作为结果
for(int i=0;i<nums1.size();i++){
if(umap.find(nums1[i])!=umap.end()){
result[i]=umap[nums1[i]];
}
}
return result;
}
};
-
时间复杂度: O(nums1.length + nums2.length)
-
空间复杂度: O(nums2.length)
- 我们使用了一个栈存储 nums2 中的元素,所以空间复杂度是 O(nums2.length)。
- 我们使用了一个哈希表存储 nums2 中元素的值与其下一个更大元素的值的映射,由于 nums2 中的元素都是唯一的,所以最多会有 nums2.length 个映射,所以空间复杂度也是 O(nums2.length)。
所以总的空间复杂度是 O(nums2.length)。
总结
本题只要想明白映射关系,因为nums1元素需要和nums2元素进行对应,对应的结果是nums2元素的下一个最大元素。因此我们可以先把nums2元素的元素值-下一个最大元素进行键值对的对应,再遍历nums1,查找Key值相同的时候,对应的结果值。















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









