






在当今信息爆炸的时代,数据已成为企业决策和个人研究的重要资源。而数据的获取、存储和分析则是整个数据生命周期中的关键步骤。本文将详细介绍如何使用爬虫技术从互联网上抓取数据,如何有效地存储这些数据,以及如何利用数据分析工具和方法对数据进行深入挖掘。
一、爬虫
1. 爬虫简介
爬虫全称为网络爬虫(web crawler),是一种按照一定规则自动地抓取万维网信息的程序或者脚本。它也被称为网页蜘蛛、网络机器人,在FOAF社区中间,更经常的称为网页追逐者。通俗来说,爬虫是用一段程序、一个软件来帮助我们把网上的数据给弄下来。这些数据不仅包括文本,还可能包括音频、图片、视频等,总之,只要是浏览器中能看到的,都可以称为数据。爬虫与用户正常访问信息的区别在于:用户是缓慢、少量的获取信息,而爬虫是大量的获取信息。爬虫并不是Python语言的专利,Java、Js、C、PHP、Shell、Ruby等等语言都可以实现爬虫功能。Python爬虫之所以如此受欢迎,是因为相比其他语言,Python的各种库更加完善、上手简单,使得Python爬虫社区活跃,从而促进了Python爬虫技术的发展和成熟。
2. 爬虫原理
爬虫的工作原理大致如下:首先,爬虫从某个初始URL开始,访问这个URL,并获取页面内容;然后,解析页面内容,提取出需要的数据和新的URL;接着,将新的URL加入待爬取队列中,以便后续继续爬取;最后,重复以上过程,直到满足某个停止条件(如爬取到指定数量的数据或所有待爬取URL都被访问过)。
3. 爬虫实现
实现一个爬虫通常需要使用到编程语言(如Python)和相关的库(如Requests、BeautifulSoup、Scrapy等)。以下是一个简单的Python爬虫示例,使用Requests库发送HTTP请求获取页面内容,使用BeautifulSoup库解析页面并提取数据:
概括图:
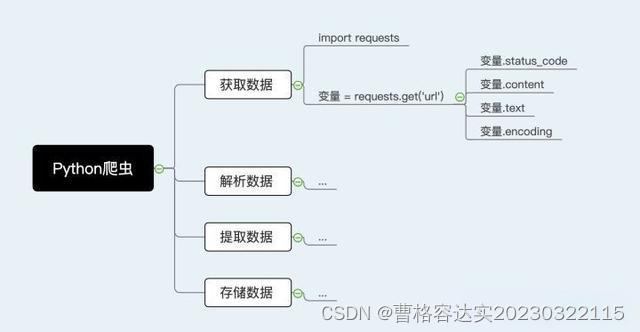
python复制代码
import requests | |
from bs4 import BeautifulSoup | |
url = 'http://example.com' # 目标URL | |
response = requests.get(url) # 发送GET请求获取页面内容 | |
soup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析页面内容 | |
data = soup.select('selector') # 使用CSS选择器提取数据 | |
# 后续处理提取到的数据... |
二、存储
1. 存储方式
获取到数据后,我们需要将其存储起来以便后续分析。常见的存储方式包括关系型数据库(如MySQL、PostgreSQL等)、非关系型数据库(如MongoDB、Redis等)、文件存储(如CSV、JSON、Excel等)以及云存储服务(如Amazon S3、Google Cloud Storage等)。
2. 存储选择
选择何种存储方式取决于数据的类型、规模以及后续分析的需求。例如,如果数据是结构化的且需要支持复杂的查询操作,那么关系型数据库可能是一个更好的选择;而如果数据是非结构化的且需要支持高并发的读写操作,那么非关系型数据库可能更适合。
3. 存储实现
以Python为例,我们可以使用SQLAlchemy库来操作关系型数据库,使用PyMongo库来操作MongoDB等非关系型数据库。同时,我们还可以使用pandas库将数据保存为CSV或Excel文件等。
Python储存示例:

三、数据分析
1. 数据分析简介
数据分析是指对收集到的数据进行处理、分析和解释的过程,以揭示数据的内在规律和趋势。通过数据分析,我们可以更好地理解数据,发现潜在的机会和挑战,并为决策提供有力支持。
2. 数据分析方法
数据分析的方法多种多样,包括描述性统计分析、推断性统计分析、数据挖掘、机器学习等。其中,描述性统计分析主要用于描述数据的基本特征和分布情况;推断性统计分析则用于根据样本数据推断总体特征;数据挖掘则侧重于从大量数据中挖掘出有用的信息和模式;而机器学习则可以通过训练模型来预测未知数据的结果。
3. 数据分析工具
实现数据分析的工具也非常丰富,包括Excel、Python(pandas、matplotlib、seaborn等库)、R语言、Tableau、Power BI等。这些工具各有特点,可以根据具体需求选择合适的工具进行数据分析。
4. 数据分析示例
以下是一个简单的Python数据分析示例,使用pandas库读取CSV文件中的数据,并使用matplotlib库绘制柱状图展示数据的分布情况:
数据展示图:
python复制代码
import pandas as pd | |
import matplotlib.pyplot as plt | |
# 读取CSV文件中的数据 | |
data = pd.read_csv('data.csv') | |
# 对数据进行一些基本的描述性统计分析 | |
print(data.describe()) | |
# 绘制柱状图展示数据的分布情况 | |
data['column_name'].value_counts().plot(kind='bar') | |
plt.show() |
总结
(1).通过本次从爬虫到数据存储与数据分析的实践,我们深刻体会到了数据处理流程中的各个环节的重要性。在爬虫阶段,我们需要关注数据的获取与清洗;在数据存储阶段,我们需要关注数据的存储与备份;在数据分析阶段,我们需要关注数据的挖掘与价值发现。未来,我们将继续优化爬虫策略、提升数据存储效率以及深化数据分析方法,以期在数据处理领域取得更多成果。同时,我们也期待与更多同行交流学习,共同推动数据处理技术的发展与应用。
(2).本文介绍了一个完整的数据处理流程,包括爬虫技术、数据存储以及数据分析。在实际应用中,我们需要根据具体需求选择合适的爬虫实现方式、存储方式和数据分析方法,并结合实际情况进行调整和优化。随着技术的不断发展和数据量的不断增长,数据处理和数据分析将在更多领域发挥重要作用。未来,我们可以期待更先进的爬虫技术、更高效的数据存储方案以及更强大的数据分析工具的出现。
(3).本文介绍了如何使用爬虫技术从互联网上抓取数据,如何有效地存储这些数据,以及如何利用数据分析工具和方法对数据进行深入挖掘。在实际应用中,我们需要根据具体需求选择合适的爬虫实现方式、存储方式和数据分析方法,并结合实际情况进行调整和优化。















 5017
5017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









