






中国男女比例的失衡,再加上广大男同胞们都想着努力为自己的事业而奋斗很少能够接触到女人,使得乎广大男同胞大都选择相亲网站来找到属于自己的另一半,,作为90的我深知广大男同胞的心情,于是乎博主通过对世纪佳缘相亲网站进行详细的可视化分析来为广大男同胞们提供相应的意见
一、爬虫部分
爬虫说明:
1、本爬虫是以面向对象的方式进行代码架构的
2、本爬虫爬取的数据存入到MongoDB数据库中(提供有转换后的.xlsx文件)
3、爬虫代码中有详细注释
4、爬虫爬取的数据以江苏省的小姐姐为例
代码展示
import json
import re
import time
from pymongo import MongoClient
import requests
class JiaYuanSpider(object):
def __init__(self):
self.url_temp = 'https://search.jiayuan.com/v2/search_v2.php'
# 构造请求头 cookie要换成自己浏览器的cookie
self.headers = {
# cookie信息换成自己的cookie
'Cookie': 'guider_quick_search=on; accessID=202103150924595680; SESSION_HASH=1b565df188507bcdbdc052adb330652be6321e18; user_access=1; save_jy_login_name=15251693528; stadate1=272569046; myloc=32%7C3201; myage=21; mysex=m; myuid=272569046; myincome=50; COMMON_HASH=67e0cfc00edcb430489cc9483f1d0cd3; sl_jumper=%26cou%3D17%26omsg%3D0%26dia%3D0%26lst%3D2021-02-19; last_login_time=1615771547; user_attr=000000; pop_sj=0; PROFILE=273569046%3A%25E5%25B0%258F%25E9%25A9%25AC%25E5%2590%258C%25E5%25AD%25A6%3Am%3Aimages1.jyimg.com%2Fw4%2Fglobal%2Fi%3A0%3A%3A1%3Azwzp_m.jpg%3A1%3A1%3A50%3A10%3A3.0; pop_time=1615771579026; PHPSESSID=ae44e627844be5ef649bf6e96cc6962c; pop_avatar=1; main_search:273569046=%7C%7C%7C00; RAW_HASH=wh-OIJDeJy1X8NOMQ3aP1neiZp17TWqyx%2AyWF494yqKobfNsk8Xeysp0EBUwf6Sz6J1rmpU3wkD4PyqHj-YEgF2sPdVBm1SUFtIHk5FN1cXARdU.; is_searchv2=1',
'Host': 'search.jiayuan.com',
'Origin': 'https://search.jiayuan.com',
'sec-ch-ua': '"Chromium";v="88", "Google Chrome";v="88", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin'
}
# 构造请求体数据
self.dat = {
'sex': 'f',
'key':'',
'stc': '1:32,23:1',
'sn': 'default',
'sv': '1',
'p': '1',
'f': 'select',
'listStyle': 'bigPhoto',
'pri_uid': '273569046',
'jsversion': 'v5',
}
# 初始化MongoDB连接
self.client = MongoClient()
self.collection = self.client['test']['jiayuan']
# 请求并解析url
def parse(self,url,page_num):
dat = self.dat
dat['p'] = page_num
time.sleep(1)
resp = requests.post(url,headers=self.headers,data=dat)
return resp.content.decode()
# 获取信息
def get_content_list(self,str_html):
json_html = re.findall(r'##(\{.*?\})##',str_html)[0]
json_html = json.loads(json_html)
user_list = json_html['userInfo']
for user in user_list:
item = {}
item['uid'] = user['uid']
item['nickname'] = user['nickname']
item['sex'] = user['sex']
item['marriage'] = user['marriage']
item['height'] = user['height']
item['education'] = user['education']
item['age'] = user['age']
item['work_location'] = user['work_location']
item['shortnote'] = user['shortnote']
print(item)
self.save(item)
# 数据保存
def save(self,item):
self.collection.insert(item)
# 主程序
def run(self):
resp = requests.post(self.url_temp,headers=self.headers,data=self.dat)
str_html = resp.content.decode()
json_html = re.findall(r'##(\{.*?\})##',str_html)[0]
json_html = json.loads(json_html)
total_page = json_html['pageTotal']
for i in range(1,int(total_page)+1):
html_str = self.parse(self.url_temp,i)
self.get_content_list(html_str)
if __name__ == '__main__':
jiayuan = JiaYuanSpider()
jiayuan.run()
二、数据分析和数据可视化部分
数据分析和数据可视化说明:
1、本博客通过Flask框架来进行数据分析和数据可视化
2、项目的架构图为
代码展示
- 数据分析代码展示(analysis.py)
import pandas as pd
import numpy as np
import jieba
import cv2 as cv
from matplotlib import pyplot as plt
from wordcloud import WordCloud
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
import pymysql
def pre_process(df):
"""
数据预处理函数
:param df:DataFrame类型
:return:df
"""
# 将性别为男的数据去除
df.query('sex != "男"',inplace=True)
x = df.copy()
x.loc[:,'shortnote'] = x.loc[:,'shortnote'].apply(lambda x:x.strip())
return x
def word_cloud(df):
"""
求偶宣言词云图
:param df: DataFrame类型
:return:df
"""
shortnote_list = df['shortnote'].tolist()
pro_shortnote_list = [' '.join(list(jieba.cut(i))) for i in shortnote_list]
cut_text = ' '.join(pro_shortnote_list)
# 读入图片背景
# 对于中文词云首先使用jieba来中文分词,然后还要记得指定font_path设置字体识别
# 想要的话还能设置词云的背景图片
#
background_image = cv.imread(r'../static/images/love.jpeg') # 设置词云形状 默认为矩形
# 排除无用的词汇 将一些常用的动词、谓语、状语去除 只需要形容词
exclude = ['我','的','着','在','有','和'
,'人','我们','这里','而','能','也',
'可以','一直','没有','请','很','这个','哪些'
,'说','想','需要','到','为','已经','是因为'
,'什么','还是','时候','你','是','就','把',
'一个','会','了','那个','那么','还','她','都',
'不','他','不是','更','自己','应该','对','要','看'
,'你们','两个','希望','来','到','只要','为了','不要'
,'让','找','多','吧','哪些','给','呢','但','没','个',
'无','做','一下','还有','如果','过','中','当做','一点']
word_cloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",collocations=False,mask=background_image,
background_color='#fef8ef',scale=1.2,stopwords=exclude,max_font_size=180,min_font_size=15).generate(cut_text)
plt.figure(figsize=(10, 10))
plt.imshow(word_cloud, interpolation="bilinear")
plt.axis("off")
plt.savefig(r'../static/images/wordCount.jpg')
plt.show()
def education_level_count(df):
"""
不同学历的女性数量
:param df: DataFrame类型
:return:df
"""
# 对学历进行分组
grouped = df.groupby('education')['uid'].count().reset_index()
# 修改列索引名称 把uid改成count
grouped.rename(columns={'uid':'count'},inplace=True)
# 构造列表嵌套列表的形式 方便后续批量插入到mysql数据库中
data = [[i['education'],i['count']] for i in grouped.to_dict(orient='records')]
print(data)
return data
def area_count(df):
"""
不同地区的女性数量
:param df: DataFrame类型
:return:df
"""
# 对工作场所进行分组
grouped = df.groupby('work_location')['uid'].count().reset_index()
# 修改列索引名称 把uid改成count
grouped.rename(columns={'uid':'count'},inplace=True)
# 构造列表嵌套列表的形式 方便后续批量插入到mysql数据库中
data = [[i['work_location'],i['count']] for i in grouped.to_dict(orient='records')]
print(data)
return data
def marry_status(df):
"""
女性的婚姻状况
:param df: DataFrame类型
:return: df
"""
# 对婚姻状况进行分组
grouped = df.groupby('marriage')['uid'].count().reset_index()
# 修改列索引名称 把uid改成count
grouped.rename(columns={'uid': 'count'}, inplace=True)
# 构造列表嵌套列表的形式 方便后续批量插入到mysql数据库中
data = [[i['marriage'],i['count']] for i in grouped.to_dict(orient='records')]
print(data)
return data
def height_area_count(df):
"""
不同身高区间的女性数量
:param df: DataFrame类型
:return: df
"""
# 对身高划分区间
low = df['height'].apply(lambda x:'<160' if x <160 else np.nan).dropna()
medium = df['height'].apply(lambda x:'160~170' if all((x>=160,x<170)) else np.nan).dropna()
heigh = df['height'].apply(lambda x:'170~180' if all((x>=170,x<=180)) else np.nan).dropna()
# 合并身高区间
height_area = pd.concat([low,medium,heigh])
grouped = height_area.groupby(height_area).count()
data = [[k,v] for k,v in grouped.to_dict().items()]
print(data)
return data
def age_area_count(df):
"""
不同年龄区间的女性数量
:param df: DataFrame类型
:return: df
"""
# 对年龄划分区间
one = df['age'].apply(lambda x:'20~30' if all((x>=20,x<30)) else np.nan).dropna()
two = df['age'].apply(lambda x:'30~40' if all((x>=30,x<=40)) else np.nan).dropna()
three = df['age'].apply(lambda x:'>40' if x>40 else np.nan).dropna()
# 合并年龄区间
age_area = pd.concat([one,two,three])
grouped = age_area.groupby(age_area).count()
data = [[k,v] for k,v in grouped.items()]
print(data)
return data
def save_to_mysql(cursor,sql,data):
result = cursor.executemany(sql,data)
if result:
print('插入成功')
if __name__ == '__main__':
# 读取xlsx文件
df = pd.read_excel('./jiayuan.xlsx',engine='openpyxl')
print(df.head())
print(df.info())
# 对数据进行预处理
df = pre_process(df)
# 生成词云图
word_cloud(df)
raise Exception
# 不同学历的女性数量
data1 = education_level_count(df)
# 不同地区的女性数量
data2 = area_count(df)
# 不同身高区间的女性数量
data3 = height_area_count(df)
# 不同年龄区间的女性数量
data4 = age_area_count(df)
# mysql存储数据
conn = pymysql.Connect(host='localhost',user='root',password='123456',port=3306,database='jiayuan',charset='utf8')
with conn.cursor() as cursor:
try:
sql1 = 'insert into db_edu_level_count(edu_level,count) values(%s,%s)'
sql2 = 'insert into db_area_count(area,count) values(%s,%s)'
sql3 = 'insert into db_height_area_count(height_area,count) values(%s,%s)'
sql4 = 'insert into db_age_area_count(age_area,count) values(%s,%s)'
save_to_mysql(cursor,sql1,data1)
save_to_mysql(cursor,sql2,data2)
save_to_mysql(cursor,sql3,data3)
save_to_mysql(cursor,sql4,data4)
conn.commit()
except pymysql.MySQLError as e:
print(e)
conn.rollback()
- 数据转换文件MongoDB数据转xlsx(to_excle.py)
import pandas as pd
import numpy as np
from pymongo import MongoClient
def export_excel(export):
# 将字典列表转换为DataFrame
df = pd.DataFrame(list(export))
# 指定生成的Excel表格名称
file_path = pd.ExcelWriter('jiayuan.xlsx')
# 替换空单元格
df.fillna(np.nan, inplace=True)
# 输出
df.to_excel(file_path, encoding='utf-8', index=False)
# 保存表格
file_path.save()
if __name__ == '__main__':
# 将MongoDB数据转成xlsx文件
client = MongoClient()
connection = client['test']['jiayuan_plus']
ret = connection.find({}, {'_id': 0})
data_list = list(ret)
export_excel(data_list)
- 数据库模型文件展示(models.py)
from jiayuan import db
class EducationLevelCount(db.Model):
__tablename__ = 'db_edu_level_count'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
edu_level = db.Column(db.String(20),unique=True)
count = db.Column(db.Integer)
class AreaCount(db.Model):
__tablename__ = 'db_area_count'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
area = db.Column(db.String(20),unique=True)
count = db.Column(db.Integer)
class HeightAreaCount(db.Model):
__tablename__ = 'db_height_area_count'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
height_area = db.Column(db.String(20),unique=True)
count = db.Column(db.Integer)
class AgeAreaCount(db.Model):
__tablename__ = 'db_age_area_count'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
age_area = db.Column(db.String(20), unique=True)
count = db.Column(db.Integer)
- 配置文件代码展示(config.py)
# 基本配置
class Config(object):
# 配置通用密钥
SECRET_KEY = 'msqaidongyuqing'
# 配置Mysql连接
# 指定连接的数据库要提前创建好
SQLALCHEMY_DATABASE_URI = 'mysql://root:123456@localhost:3306/jiayuan'
SQLALCHEMY_TRACK_MODIFICATIONS = True
class DevelopmentConfig(Config):
DEBUG=True
class ProductConfig(Config):
pass
# 创建配置类映射
config_map = {
'develop':DevelopmentConfig,
'product':ProductConfig
}
- 主工程目录代码展示(api_1_0/_init_.py)
from flask import Flask
from config import config_map
from flask_sqlalchemy import SQLAlchemy
import pymysql
pymysql.install_as_MySQLdb()
db = SQLAlchemy()
# 通过工厂模式来创建实例化app对象
def create_app(config_name='develop'):
app = Flask(__name__)
config = config_map[config_name]
app.config.from_object(config)
# 初始化数据库
db.init_app(app)
# 注册蓝图
from .api_1_0 import show
app.register_blueprint(show.api,url_prefix='/show')
return app
- 主程序文件代码展示(manager.py)
from jiayuan import create_app,db
from flask_script import Manager
from flask_migrate import Migrate,MigrateCommand
from flask import render_template
app = create_app()
manager = Manager(app)
Migrate(app,db)
manager.add_command('db',MigrateCommand)
# 首页
@app.route('/')
def index():
return render_template('index.html')
if __name__ == '__main__':
manager.run()
- 视图文件代码展示(api_1_0/views/_init_.py,show.py)
_init_.py
from flask import Blueprint
from jiayuan import db,models
api = Blueprint('api_1_0',__name__)
from . import show
show.py
from . import api
from jiayuan.models import AreaCount,EducationLevelCount,AgeAreaCount,HeightAreaCount
from flask import render_template
# 绘制不同地区的女性数量
@api.route('/drawBar')
def drawBar():
area_count = AreaCount.query.all()
area = [i.area for i in area_count]
count = [i.count for i in area_count]
return render_template('drawBar.html', **locals())
# 绘制不同学历的女性数量
@api.route('/drawPie')
def drawPie():
height_area_count = HeightAreaCount.query.all()
height_area_count_data = [{'name':i.height_area,'value':i.count} for i in height_area_count]
age_area_count = AgeAreaCount.query.all()
age_area_count_data = [{'name':i.age_area,'value':i.count} for i in age_area_count]
return render_template('drawPie.html',**locals())
# 绘制不同身高区间的女性数量&不同年龄区间的女性数量
@api.route('/drawSignlePie')
def drawSignlePie():
edu_level_count = EducationLevelCount.query.all()
edu_level_count_data = [{'name':i.edu_level,'value':i.count} for i in edu_level_count]
return render_template('drawSignalPie.html',**locals())
# 展示词云图
@api.route('/drawWordCloud')
def drawWordCloud():
return render_template('wordCloud.html')
- 主页展示(index.html)
主页简单创建了四个超链接指向对应的图表
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>
世界佳缘可视化分析
</title>
<style>
ul{
width: 800px;
height: 600px;
{#list-style: none;#}
line-height: 60px;
padding: 40px;
margin: auto;
}
ul li{
margin-bottom: 20px;
}
</style>
</head>
<body>
<ul>
<li><a href="{{ url_for('api_1_0.drawWordCloud') }}"><h3>择偶宣言词云图</h3></a></li>
<li><a href="{{ url_for('api_1_0.drawBar') }}"><h3>不同地区的女性数量</h3></a></li>
<li><a href="{{ url_for('api_1_0.drawPie') }}"><h3>不同身高区间的女性数量&不同年龄区间的女性数量</h3></a></li>
<li><a href="{{ url_for('api_1_0.drawSignlePie') }}"><h3>不同学历的女性数量</h3></a></li>
</ul>
</body>
</html>

- 模板文件代码展示(drawBar.html,wordCloud.html,drawSignalPie.html,drawPie.html)
wordCloud.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>择偶宣言词云图</title>
</head>
<body>
<div style="width:800px;margin: auto">
{#此图片路径是根据生成词云图的路径所决定的#}
<img src="../static/images/wordCount.jpg" style="width: 100%">
</div>
</body>
</html>

结论:通过观察词云图,可以看出江苏的求爱小姐姐找对象的一些品质要求,比如说真诚、成熟、责任心、善良的等品质,同时也可以看出江苏省的求爱小姐姐希望能够和喜欢的爱的人一起幸福的生活
drawBar.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>不同地区的女性数量</title>
<script src="../static/js/echarts.min.js"></script>
<script src="../static/js/vintage.js"></script>
</head>
<body>
<div class="cart" style="height: 600px;width: 800px;margin: auto"></div>
<script>
var area = {{ area|tojson }}
var count = {{ count|tojson }}
var MyCharts = echarts.init(document.querySelector('.cart'),'vintage')
var option = {
title:{
text:'不同地区的女性数量',
textStyle:{
fontSize:21,
fontFamily:'楷体'
},
top:5,
left:5
},
xAxis:{
type:'category',
data:area,
axisLabel:{
interval:0,
rotate:30,
margin:20
}
},
yAxis:{
type:'value',
scale:true
},
grid:{
width:640,
height:480,
left: 100
},
legend:{
name: area,
top: 10
},
tooltip:{
trigger:'item',
triggerOn: 'mousemove',
formatter:function(arg)
{
return '地区:'+arg.name+'<br/>'+'人数:'+arg.value
}
},
series:[
{
type:'bar',
data:count,
name:'人数',
showBackground: true,
backgroundStyle: {
color:'rgba(180, 180, 180, 0.2)'
},
label:{
show:true,
position:'top',
rotate:30,
distance:10
}
}
]
}
MyCharts.setOption(option)
</script>
</body>
</html>
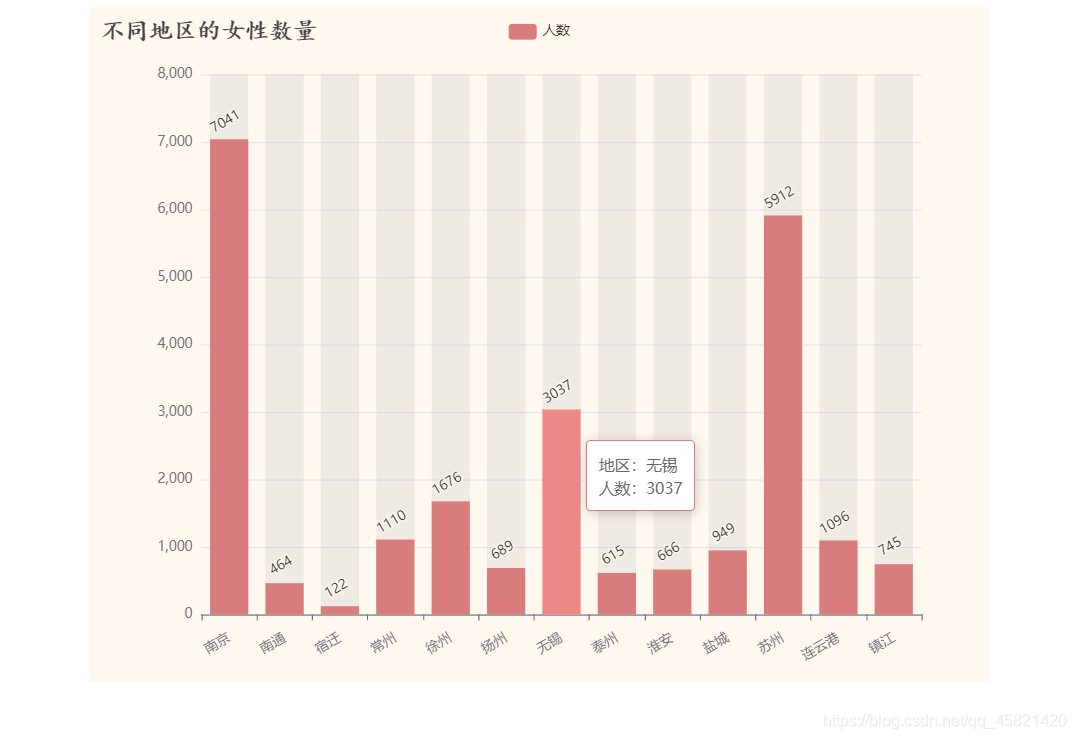
结论:通过观察柱状图可以看出江苏省的求爱小姐姐大都分布在南京、苏州、无锡等一些江苏省较发达的城市,可以从侧面反映出城市越发达对寻找另一半的需求越多。
drawPie.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>不同身高区间的女性数量&不同年龄区间的女性数量</title>
<script src="../static/js/echarts.min.js"></script>
<script src="../static/js/vintage.js"></script>
<style>
.group{
margin: auto;
display: flex;
justify-content: space-between;
width: 1300px;
height: 500px;
}
</style>
</head>
<body>
<div class="group">
<div class="cart1" style="width: 600px;height: 500px;"></div>
<div class="cart2" style="width: 600px;height: 500px;"></div>
</div>
<script>
var data1 = {{ height_area_count_data|tojson }}
var data2 = {{ age_area_count_data|tojson }}
var MyCharts1 = echarts.init(document.querySelector('.cart1'),'vintage')
var MyCharts2 = echarts.init(document.querySelector('.cart2'),'vintage')
function getOption(title_text,data,sign){
var option = {
title:{
text:title_text,
textStyle:{
fontSize:21,
fontFamily:'楷体'
},
left: 'center'
},
legend:{
name:['人数'],
left: 20,
bottom:20,
orient:'vertical'
},
tooltip:{
trigger:'item',
triggerOn:'mousemove',
formatter:function (arg)
{
return sign+':'+arg.name+'<br/>'+'人数:'+arg.value+'<br/>'+'占比:'+arg.percent+'%'
}
},
series:[
{
type:'pie',
name:'人数',
data:data,
label:{
show:true
},
itemStyle:{
borderColor:'white',
borderRadius:10,
borderWidth:5
},
selectedMode:'multiple',
selectedOffset:10,
radius:['50%','80%'],
bottom: -10
}
]
}
return option
}
var option1 = getOption('不同身高区间的女性数量',data1,'身高')
var option2 = getOption('不同年龄区间的女性数量',data2,'年龄')
MyCharts1.setOption(option1)
MyCharts2.setOption(option2)
</script>
</body>
</html>
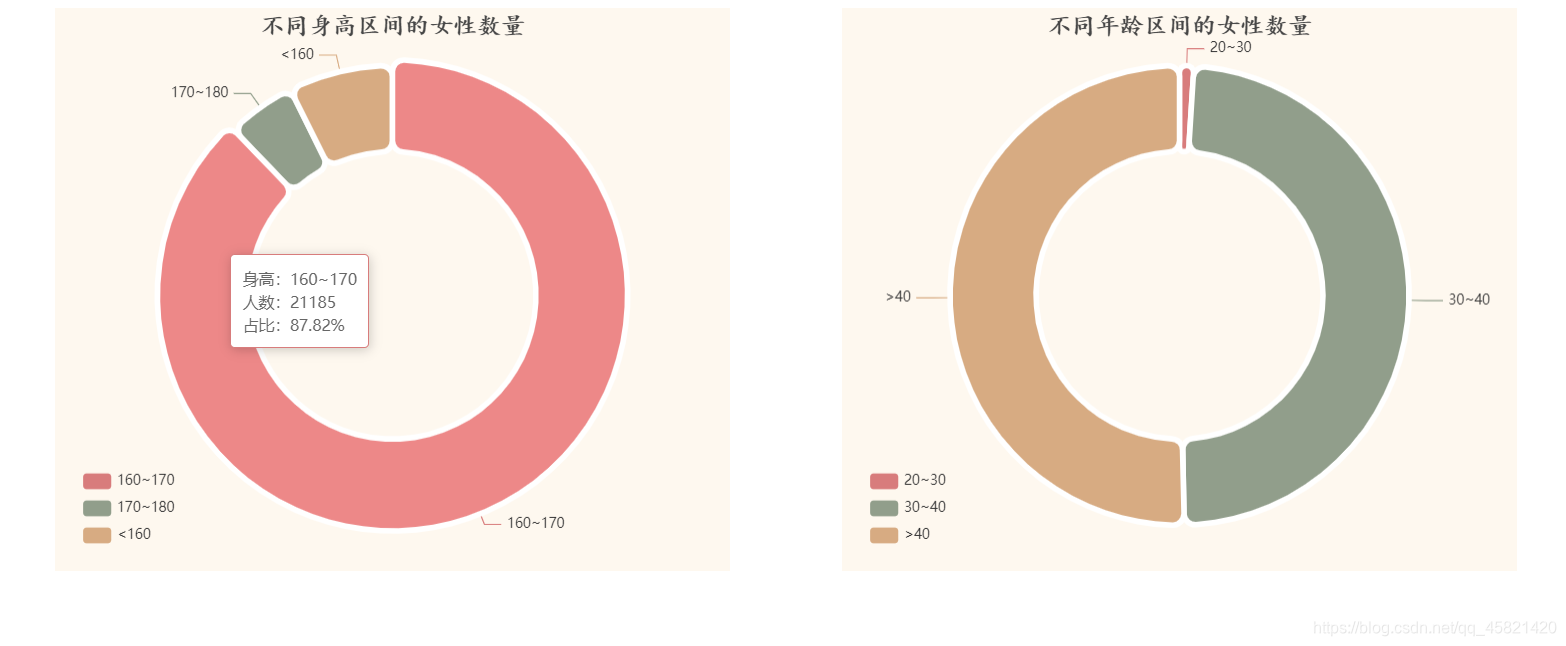
结论:通过观察圆环图可以看出,江苏省的求爱小姐姐身高大都在160-170,同时江苏省的求爱小姐姐大都在30岁以上,这就不能叫小姐姐了,改成大姐姐好了,看来都是人到中年才发现另一半的重要性。
drawSignalPie.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>不同学历的女性数量</title>
<script src="../static/js/echarts.min.js"></script>
<script src="../static/js/vintage.js"></script>
</head>
<body>
<div class="cart" style="height: 600px;width: 800px;margin: auto"></div>
<script>
var edu_level_count_data = {{ edu_level_count_data|tojson }}
var MyCharts = echarts.init(document.querySelector('.cart'),'vintage')
var option = {
title:{
text:'不同学历的女性数量',
textStyle:{
fontSize:21,
fontFamily:'楷体'
},
top:10,
left:10
},
legend:{
name:['人数'],
left:20,
bottom:20,
orient:'vertical',
itemWidth:40,
itemHeight:20
},
tooltip:{
trigger:'item',
triggerOn:'mousemove',
formatter:function(arg)
{
return '学历:'+arg.name+'<br/>'+'人数:'+arg.value+'<br/>'+'占比:'+arg.percent+'%'
}
},
series:[
{
type:'pie',
data:edu_level_count_data,
name:'数量',
label:{
show:true,
},
itemStyle: {
borderRadius: 10,
borderColor: '#fff',
borderWidth: 2
},
labelLine: {
show: false
},
roseType:'radius', // 南丁格尔图玫瑰图
{#radius:['50%','80%'],#}
selectedMode:'multiple',
selectedOffset:20
}
]
}
MyCharts.setOption(option)
</script>
</body>
</html>
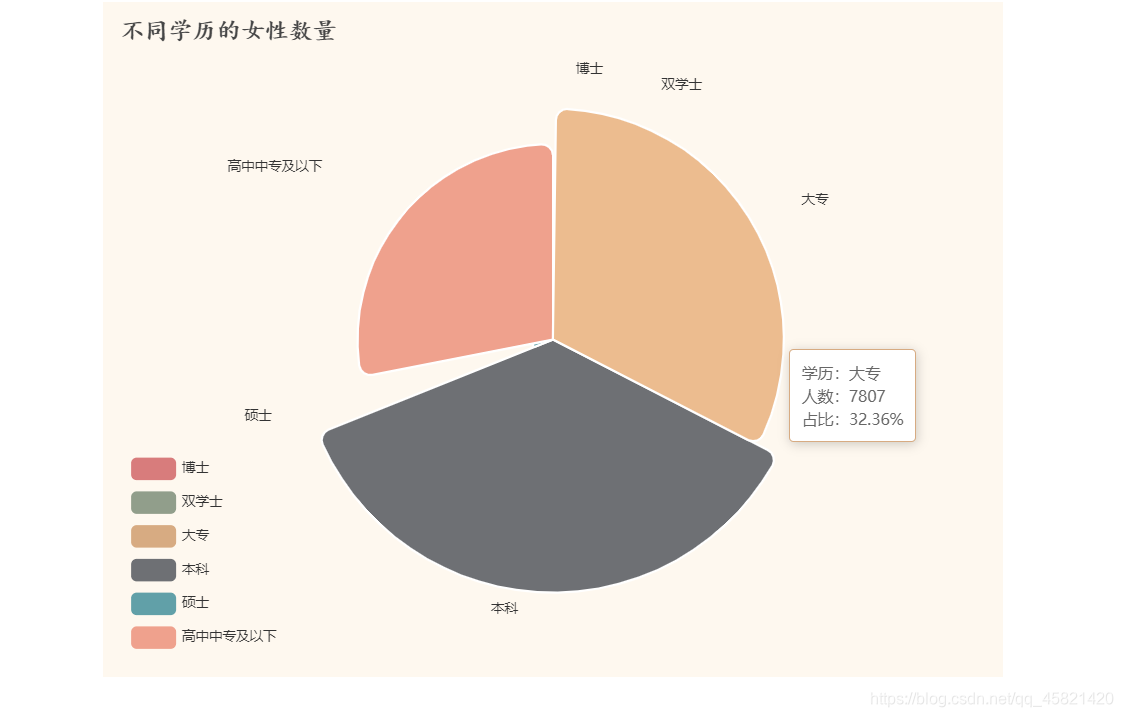
结论:通过观察饼图可以看出,江苏省的求爱大姐姐大学历大都在本科学历或以下,这不禁让我发出这么一个疑问,是不是学历高的江苏大姐姐不需要对象,还是学历高包分配对象,这就不得而知了
以下是项目源码,希望能够帮助你们,如有疑问,下方评论
flask项目代码链接


















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











