







Redis的特性
Redis是一个在内存中存储数据的中间件,用于作为数据库,用于作为数据缓存等
Redis是在内存中存储数据的
对于与MySQL数据库主要是通过”表“的方式存储组织数据的属于”关系型数据库“,而对于Redis而言,主要是通过”键值对“的方式来存储组织数据的,属于”非关系数据库“
针对Redis的操作,可以直接通过简单的交互式命令进行操作,也可以用过一些脚本的方式批量执行一些操作。主要的脚本语言使用”Lua“
可以在原有的Redis功能基础上再进行扩展,Redis提供了一组API,可以使用C/C++/Rust编程语言去编写一些动态链接库作为Redis的扩展。
Redis具有持久化,虽然Redis是将数据存储在内存上的,但是Redis会把数据存储在硬盘上。主要是以内存为主,硬盘为辅,相当于是用硬盘来备份的。如果Redis重启了,就会加载在硬盘中的备份数据,使Redis内存恢复到重启前的状态
Redis支持集群,可以引入多个主机部署多个Redis节点,每个Redis可以存储数据的一部分
Redis支持高可用(冗余/备份),Redis自身指出”主从“结构,从节点就相当于主节点的备份
Redis最大的特点就是快。
- 由于其数据在内存中所以比访问硬盘的数据库要快很多。
- 其核心功能都是比较简单的逻辑,都是简单的操作内存的数据结构。
- 在网络角度上使用了IO多路复用的方式(epoll)。
- 站在线程的角度上,其使用的是单线程模型,这样就减少了不必要的线程之间的竞争开销
Redis客户端
redis也是一个 客户端-服务端 结构的程序,和mysql一样。

客户端和服务器可以在不同的主机上,一个服务器并非是只给一个客户端服务的。
redis 的客户端有很多种形态,例如自带的命令行客户端
redis-cli // 默认命令连接本地redis
redis-cli -h IP地址 -p 端口号 // 指定连接
ctrl + d // 退出
redis也有图形化界面的客户端,但是像这样的图形化程序依赖于windows系统,但是这样子连接到服务器可能会有很多限制,不一定能够连上。
当然redis在工作中最主要的形态 – 基于redis的api自行开发客户端,也就是跟mysql一样在代码里实现连接执行等
redis-cli与服务器交互
这两交互需要涉及到很多的redis的命令。可通过redis官网去查找命令使用方法
Redis虽然整体是键值对结构,key固定是字符串,但是value实际上会有很多种类型
- 字符串
- 哈希表
- 列表
- 集合
- 有序集合
对于不同的数据结构就会有不同的命令,并且某些命令能够搭配任意一个数据结构来使用这种命令称为全局命令
set
把key和value存储进去
set key value (后面会带有一些选项) // key和value为字符串类型

加不加引号都无所谓
get
根据key来取value
get key // 如果key不存在则返回nil,nil与NULL是一个意思

keys
用来查询当前服务器上匹配的key
时间复杂度为O(N),因此一般都不会使用。特别是 keys 因为这相当于查询redis中所有的key,并且redis是一个单线程的服务器,这就会导致key很多的情况下redis服务器被阻塞*
通过一些特殊符号(通配符)来描述key的模样,匹配上述模样的key就能被查询出来
• h?llo 匹配 hello , hallo 和 hxllo
• h*llo 匹配 hllo 和 heeeello
• h[ ae ]llo 匹配 hello 和 hallo 但不匹配 hillo
• h[ ^e ]llo 匹配 hallo , hbllo , … 但不匹配 hello
• h[ a-b ]llo 匹配 hallo 和 hbllo


(?)可以匹配任意一个字符
(*)可以匹配0个或者多个任意字符
( [ XXX ] )代表着只能匹配到方括号里的字符
( [ ^X ] )上尖号代表着排除该字符
( [ X-K ])代表着一个范围 ,例如 a-e 就是a到e都行
exists
判定key是否存在,可以一次判定多个key,返回值:存在的key的个数(注意不是一个key的个数,而是如果判定多个key时,多个key都存在的个数)
时间复杂度为O(1),redis组织这些key是按照哈希表的方式存储的,redis的具体某个值也可以是一些数据结构

那么一次exists两个key 和 分两次exists一个key 有什么区别呢
由于redis是客户端 服务器的程序,所以前者只向服务器发送一次请求,服务器也向客户端回应一次。而后者需要发送两次请求 ,就会产生更多轮次的网络通信。网络通信和直接操作内存来比的话就会显得效率比较低成本又比较高
del
删除指定的key,也可以一次删除多个key,返回值:删除的key的个数(注意不是一个key的个数,而是如果删除多个key成功的个数)

时间复杂度为O(1),删多少个就是O几
这个del和mysql删除的影响是有些区别的,mysql的删除是很危险的,删就没了。但是redis主要作为缓存使用,因此存的都是热点数据,全量数据实在mysql数据库中的,所以删掉几个影响不大。如果作为数据库使用那就影响大了,具体场景具体分析。
expire
给指定key设置过期时间,达到时间后就会被自动删除掉,以秒为单位。pexpire是以毫秒为单位的expire,用法差不多
时间复杂度为O(1),返回值:1 表示设置成功。0 表示设置失败
例如验证码这种场景就会用到了。还有基于redis实现分布锁时,为了避免出现不能正确解锁的情况,通常都会在加锁的时候设置一些过期时间,这也就是给redis里加上一个特殊的key

ttl
获取指定 key 的过期时间,以秒为单位。pttl是以毫秒为单位的ttl
时间复杂度为O(1),返回值:剩余过期时间。-1 表示没有关联过期时间,-2 表示key 不存在

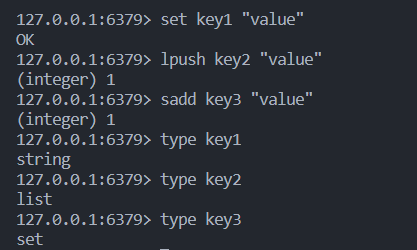
type
返回 key 对应的数据类型,时间复杂度为O(1)
key的过期策略
一个redis中可能同时存在很多key,这些key中可能有很大部分都有过期时间,那么redis怎么知道哪些key已经过期要被删除了,哪些还没过期呢?
首先如果直接遍历所有的key肯定是不行的,效率太低。
redis的策略有并不只有以下两种:
- 定期删除:每次抽取一部分检查过期时间,如果有过期的就删除掉,没有就不管了。这样保证抽取检查的过程比较快
- 惰性删除:假设一个key已经到过期时间了,但是可能还没有删它。直到后面有一次访问到这个key,一旦redis访问这个key时就会直接触发删除这个key,同时返回一个nil。
两种策略结合使用就保证这个时间不会消耗太多。
因为redis时单线程的程序,所以处理每个命令的任务包括检查过期key都是在一个线程完成的,所以在这样的情况下如果检查key消耗太多时间就可能导致正常处理请求命令阻塞了。因此对于过期策略就需要快。
虽然有上述的策略,但是效果并不是完美的也很有可能有过期的key没有被删除掉。
因此redis为了补充这种可能性,还提供了一系列的内存淘汰方式。
redis并没有采用定时器的方式,虽然也可以高效的去实现。可能是因为redis早期就只想着用单线程进行到底,而定时器就得需要多线程。
















 1574
1574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











