






wondertool: 硬字幕提取、文字识别、图片缩放工具 (gitee.com),现在上github越来越麻烦了,转到码云来了
项目中只有推理模型,没有用训练模型
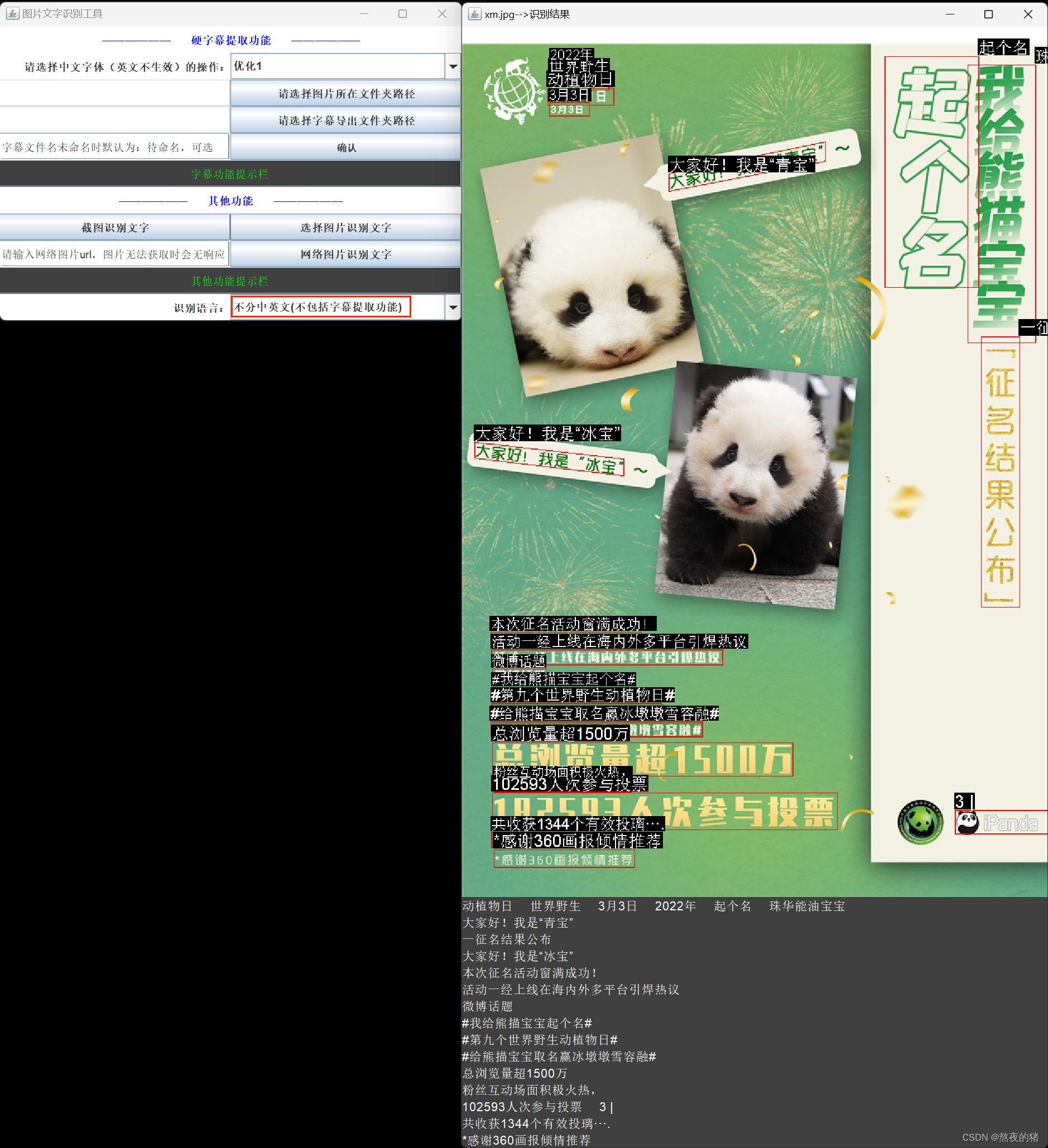
先来看看DJL加PaddleOCR经微改后识别某类图像的效果(选择语言中文就是PaddleOCR识别) DJL的PaddleOCR example官网:https://docs.djl.ai/jupyter/paddlepaddle/paddle_ocr_java_zh.html
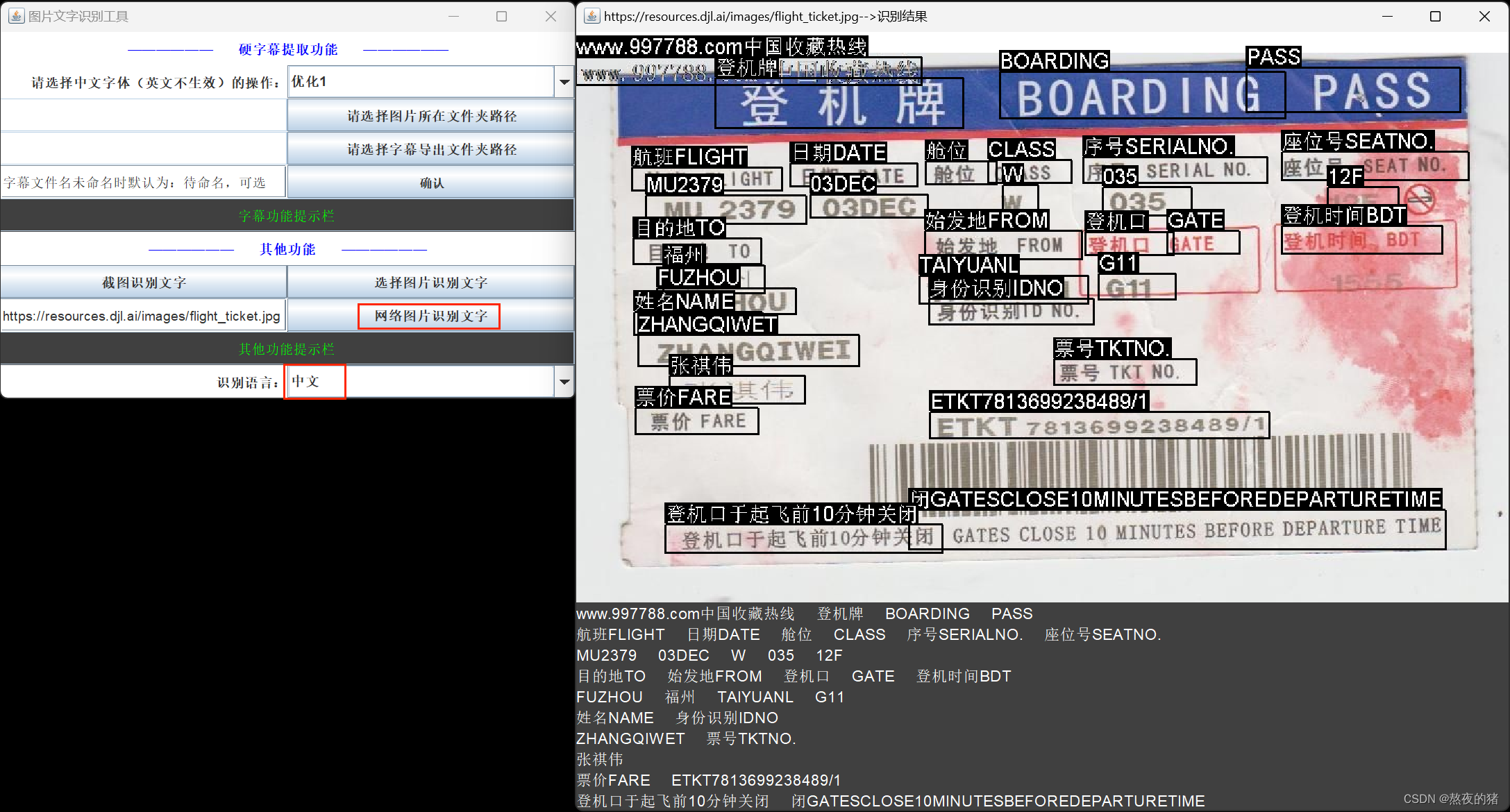
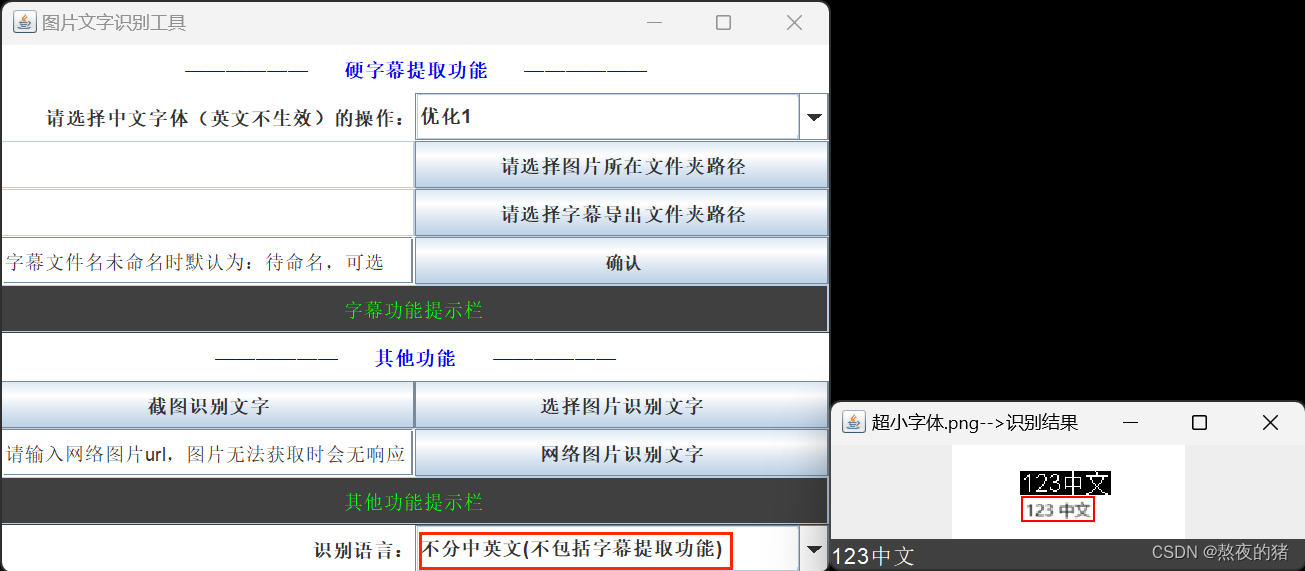
超小字体识别效果
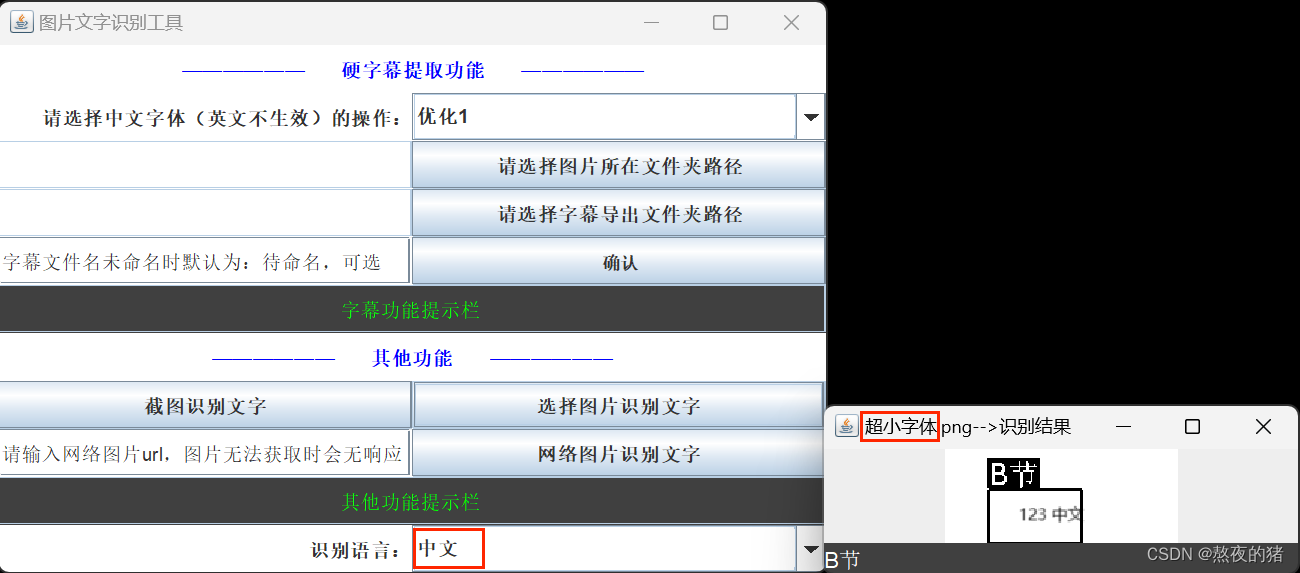
再来看看纯TesseractOCR识别效果
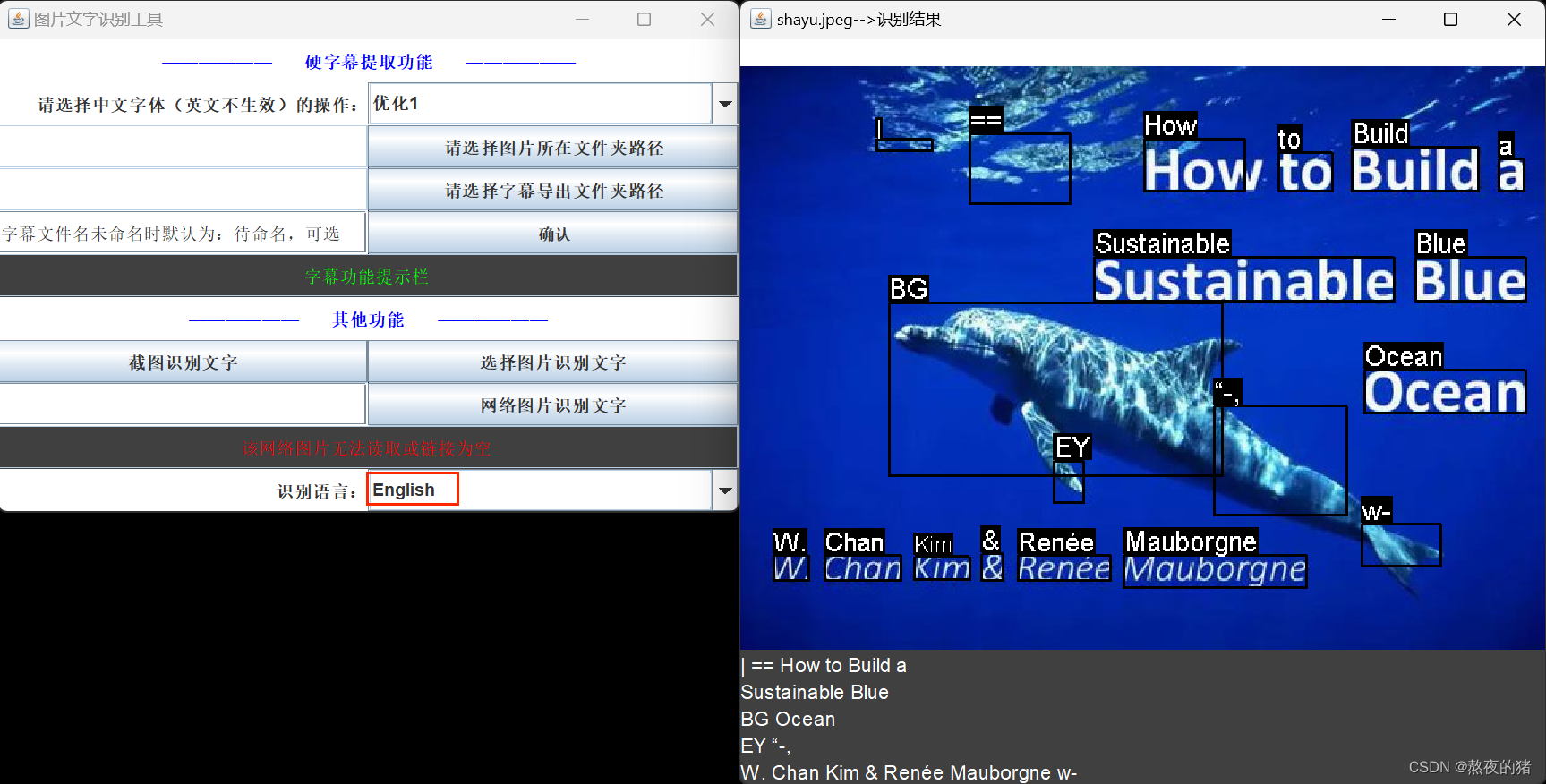
看看文本检测算法DB整合ESPCN超分辨率放大和其他算法和透视变换及微调等后的识别(PaddleOCR和TesseractOCR结合识别)效果, 给识别内容设计排序等。

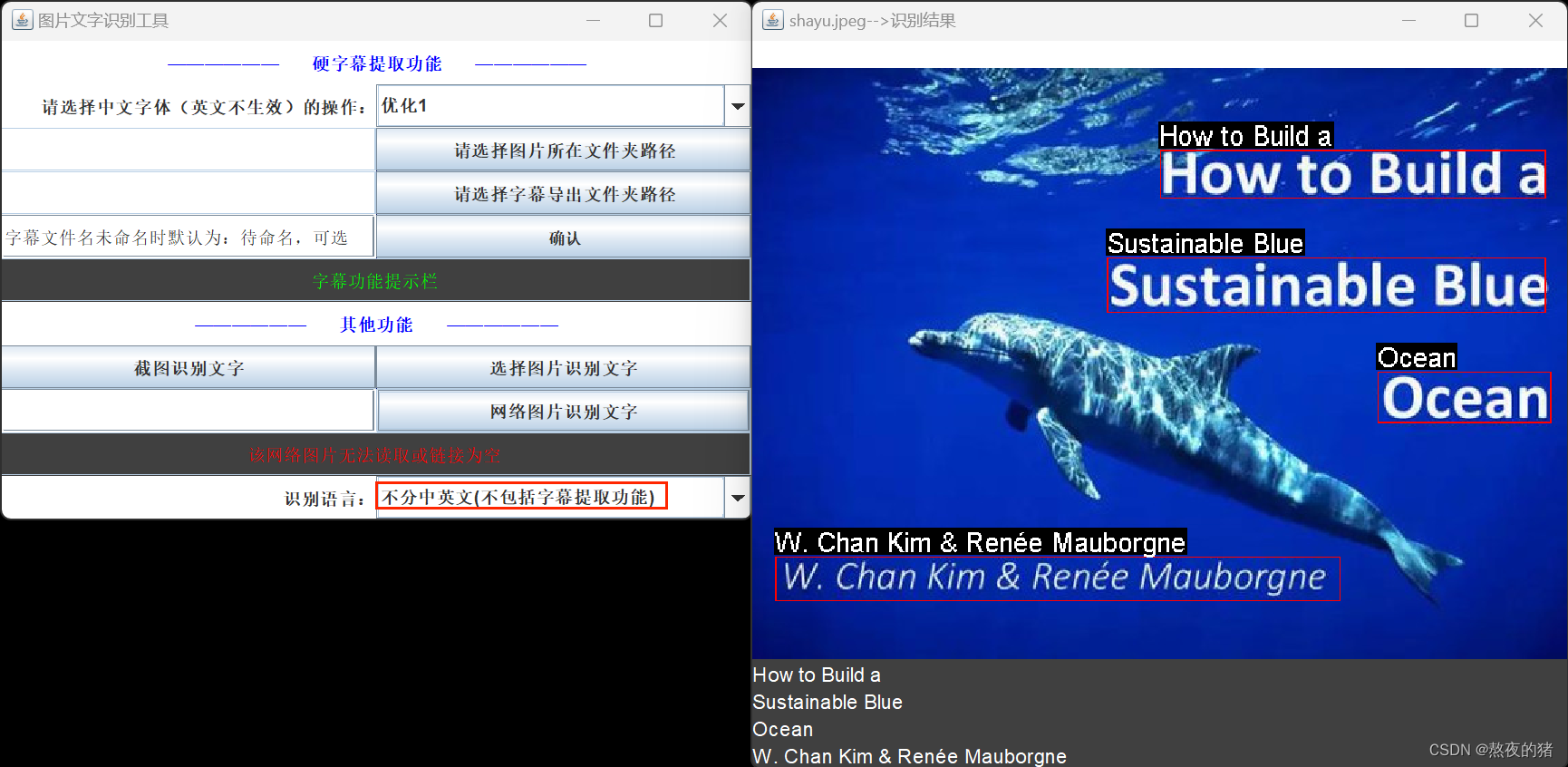
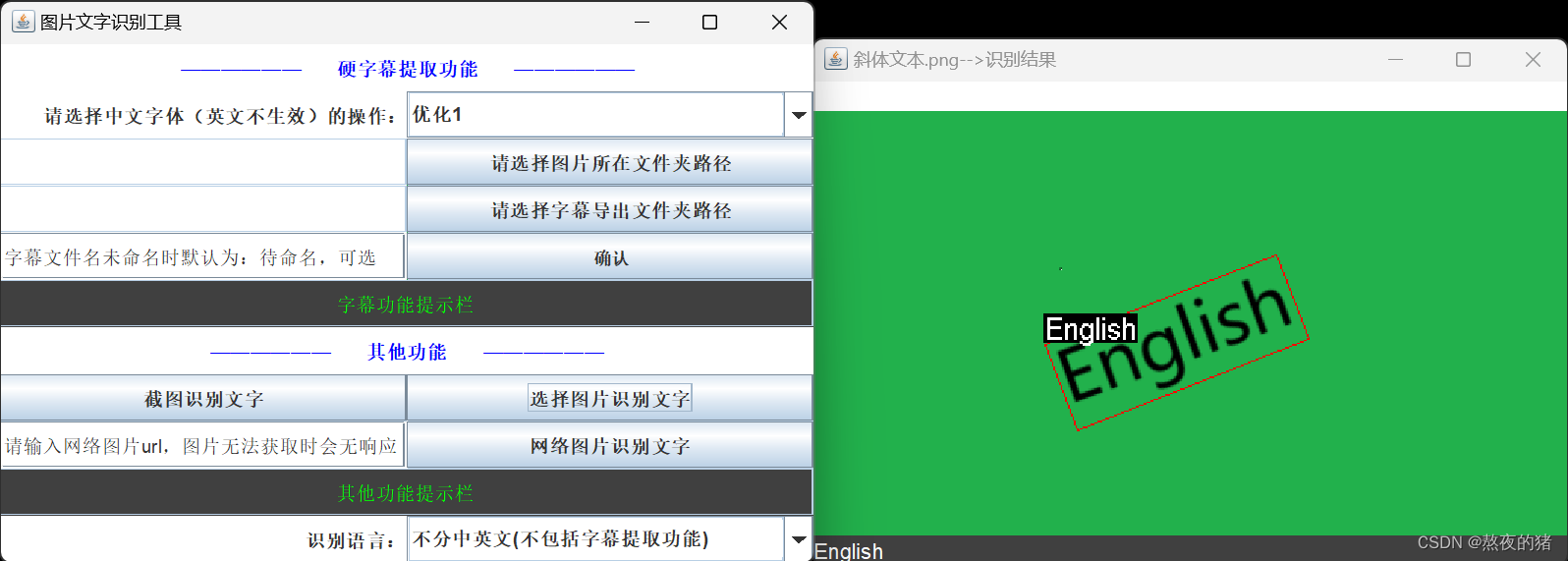
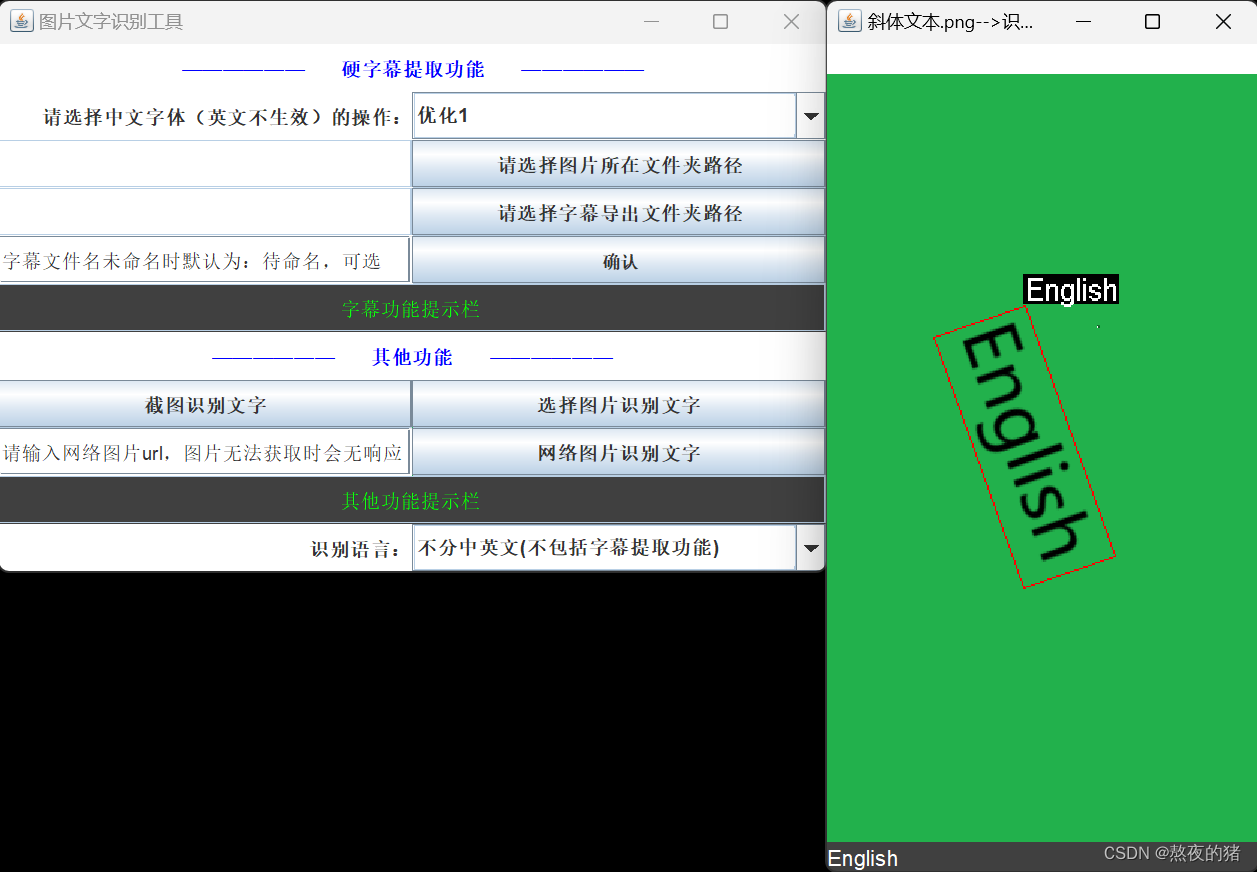
两个倾斜方向
超小字体识别效果
使用教程:
VideoSubFinder拿来做字幕图片截取捕获,这是下载地址:
VideoSubFinder download | SourceForge.net
下载安装完成后,步骤:打开视频框选字幕位置,清空所有图片(之前识别的图片),开始识别。
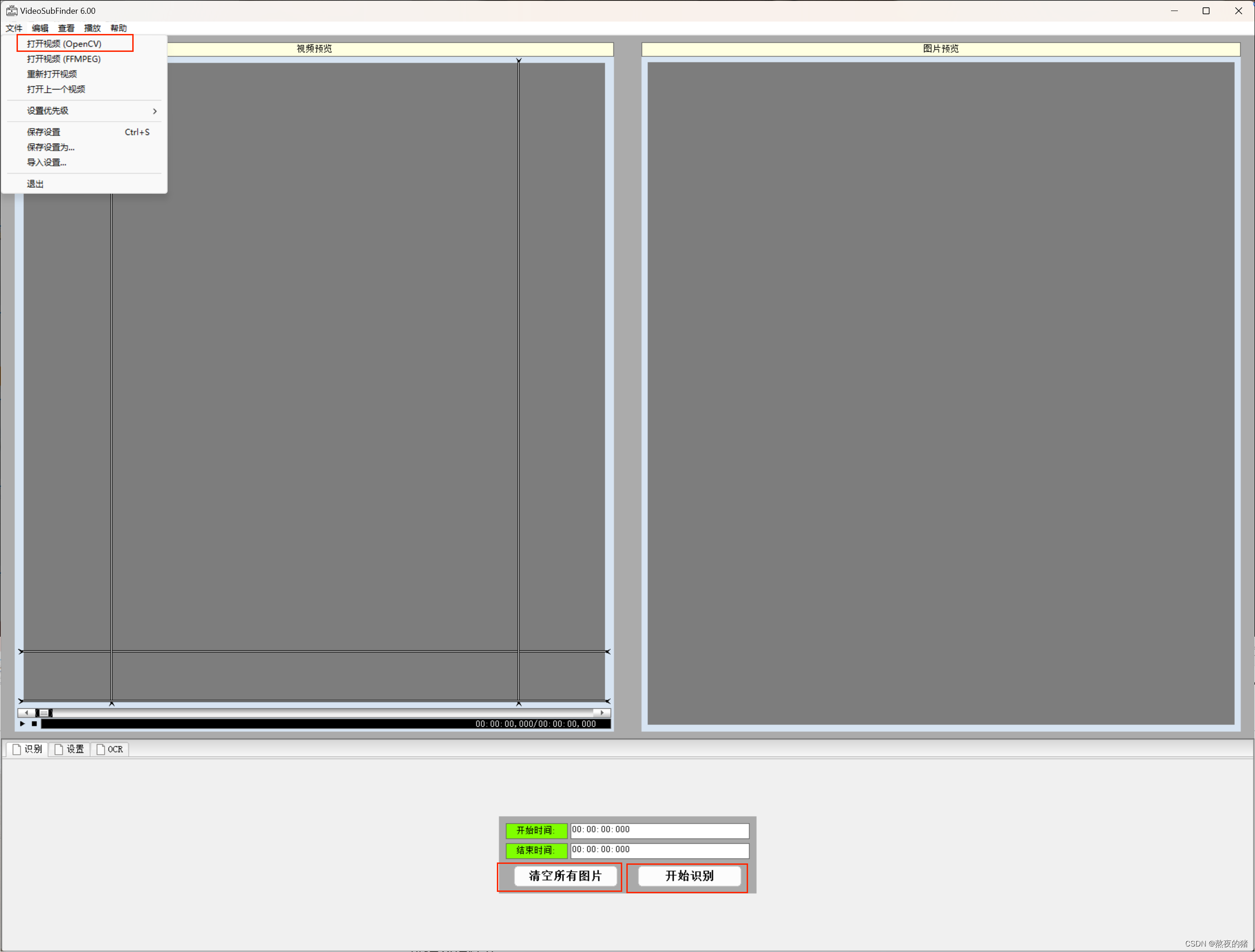
捕获完后的图片在VideoSubFinder安装目录的RGBImages文件夹中

接下来是我开发的小工具:
下载wondertool_win-x64.zip解压后打开wondertool.exe,输入RGBImages文件夹路径和字幕保存路径,确认后,看字幕功能提示栏提示,(这里没有paddleocr(对应非English)和TesseractOCR(对应English)结合识别)。
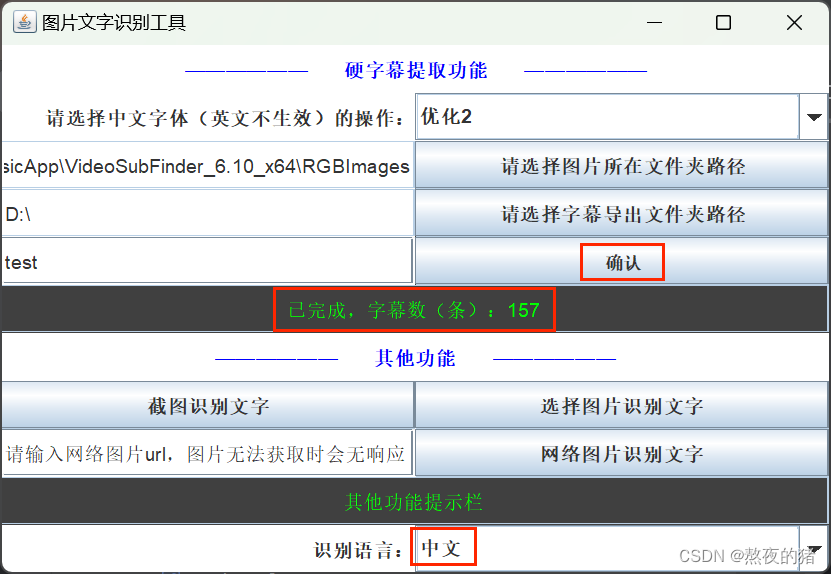
使用其他OCR工具提取硬字幕可以看本人这篇博客,不一定要用本文中的OCR工具,这里也有个辅助小工具视频硬字幕提取方法(可完全离线),开发个小工具辅助一下_硬字幕提取工具_熬夜的猪的博客-CSDN博客
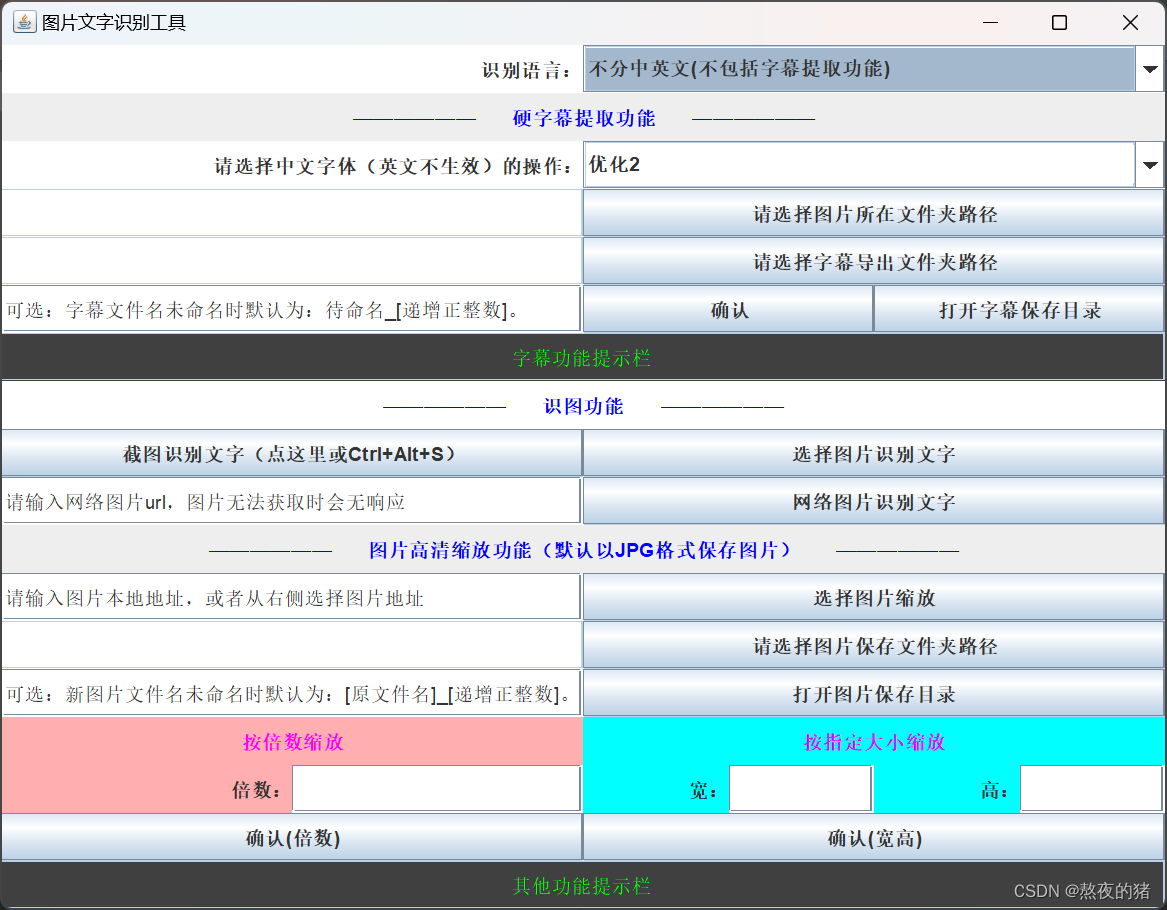
加入了新功能(图片高清缩放):
技术爱好者也可以找本人交流,有什么还可以优化的请指教,本人QQ942467683,很少上来,回复评论的话看缘分。


















 4073
4073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









