








文章目录
🌊 Transformer 模块概述 – 简化版本
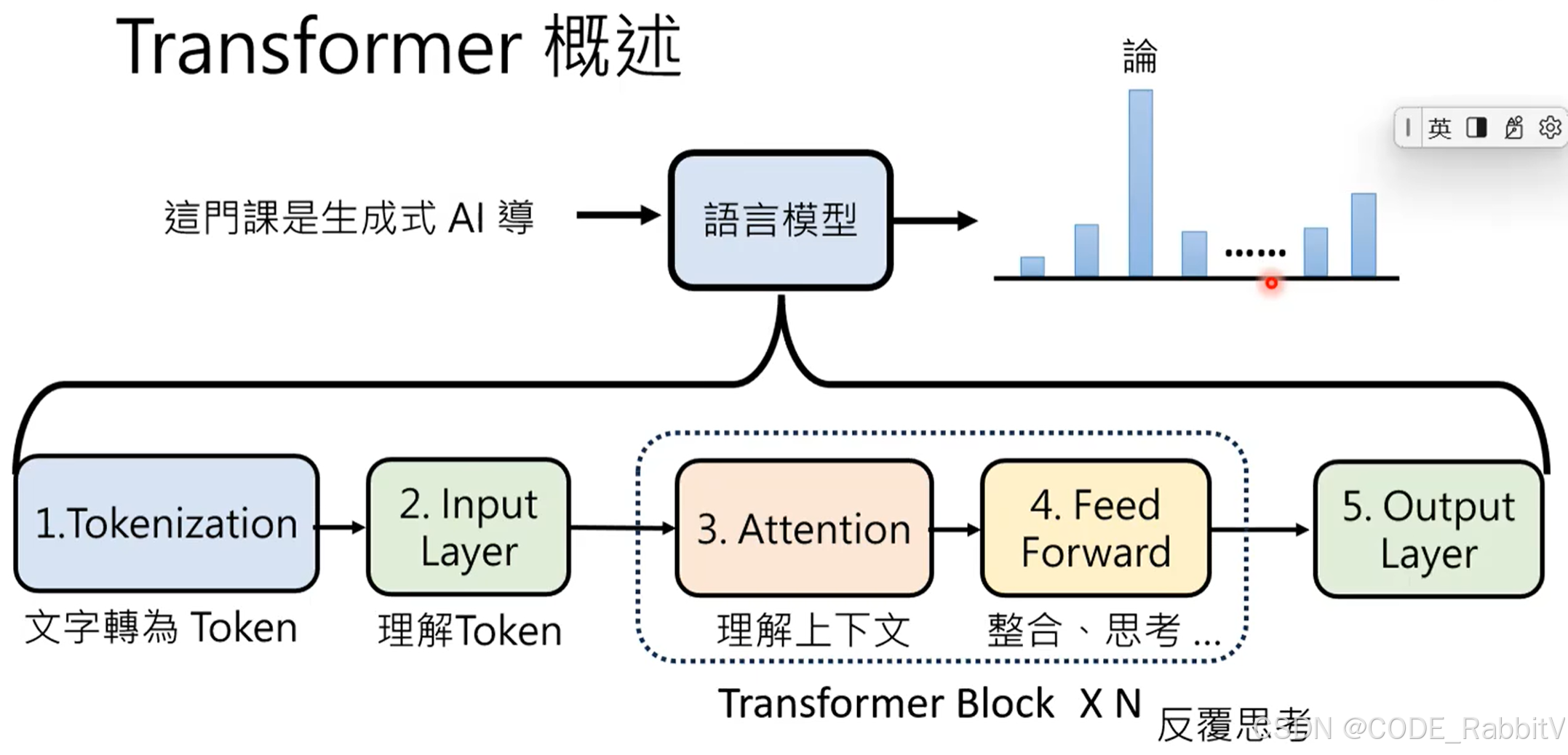
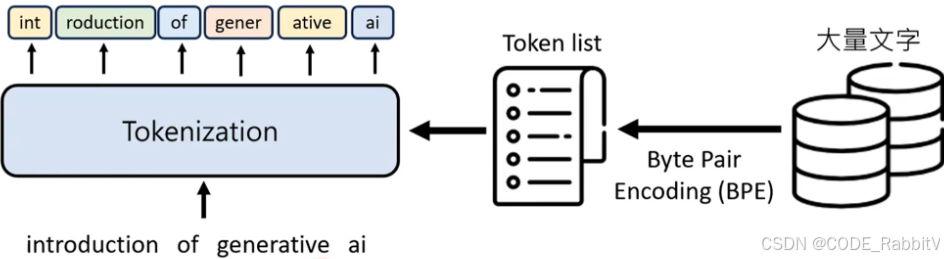
【1. Tokenization】把文字变成 Token ❄️
- https://platform.openai.com/tokenizer
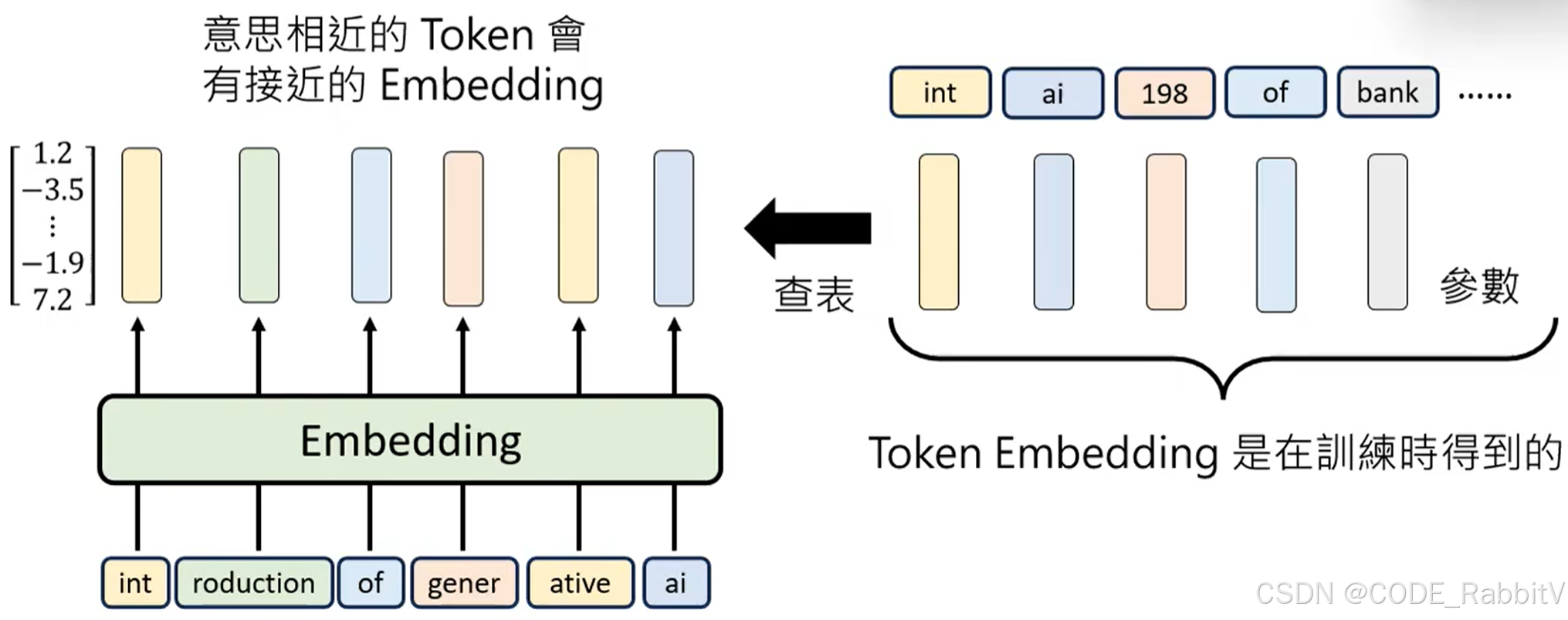
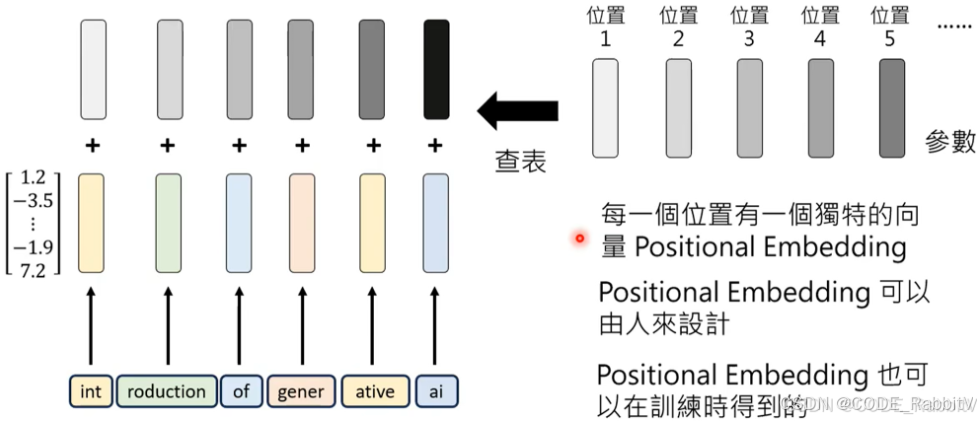
【2. Input Layer】理解每个 Token (从语义和位置上) 🔥
- 意思相近的 Token 会有接近的 Embedding,除了语义,位置上也包含有信息
【3. Attention】考虑 Token 上下文 – contextuallized token embedding
- 如下图的例子,同一个 token –
果在不同的上下文中应该具有不同的理解
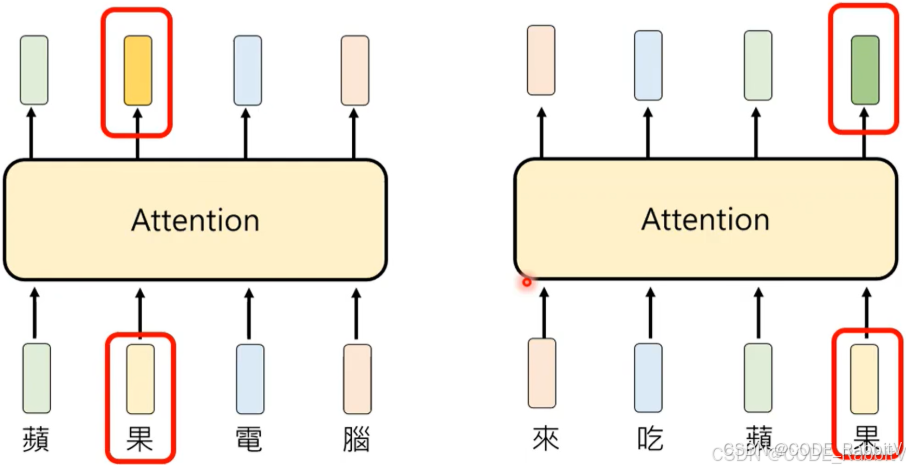
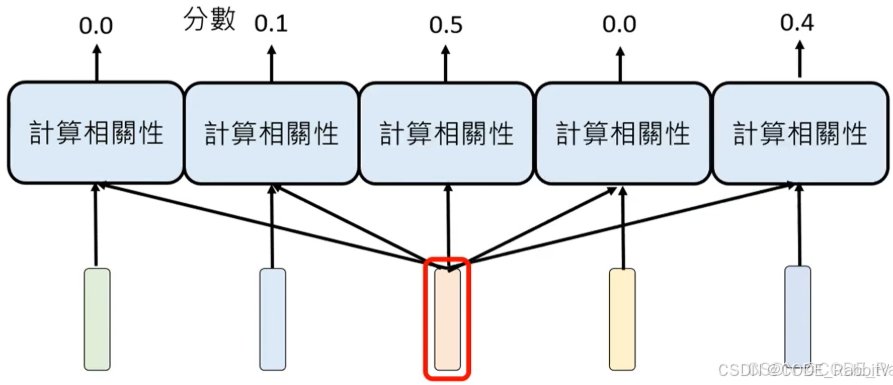
- 步骤一:先找出相关的 token,利用相关性计算程式;可能有不同的相关性存在,所以实际大多使用多个 (16个) 计算相关的程式,也就是常说的 multi-head attention
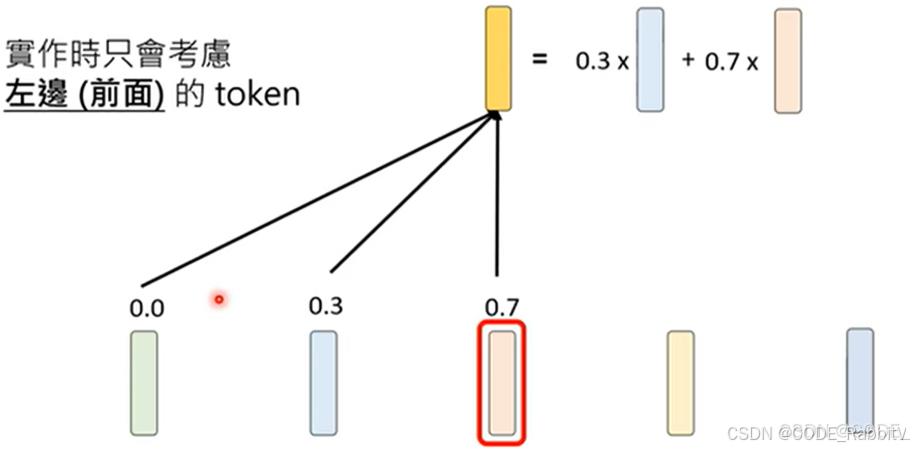
- 步骤二:集合相关的资讯
【4. Feed Forward】整合思考
- 把 multi-head attention 的结果进行汇总,得到一个 embedding 的结果
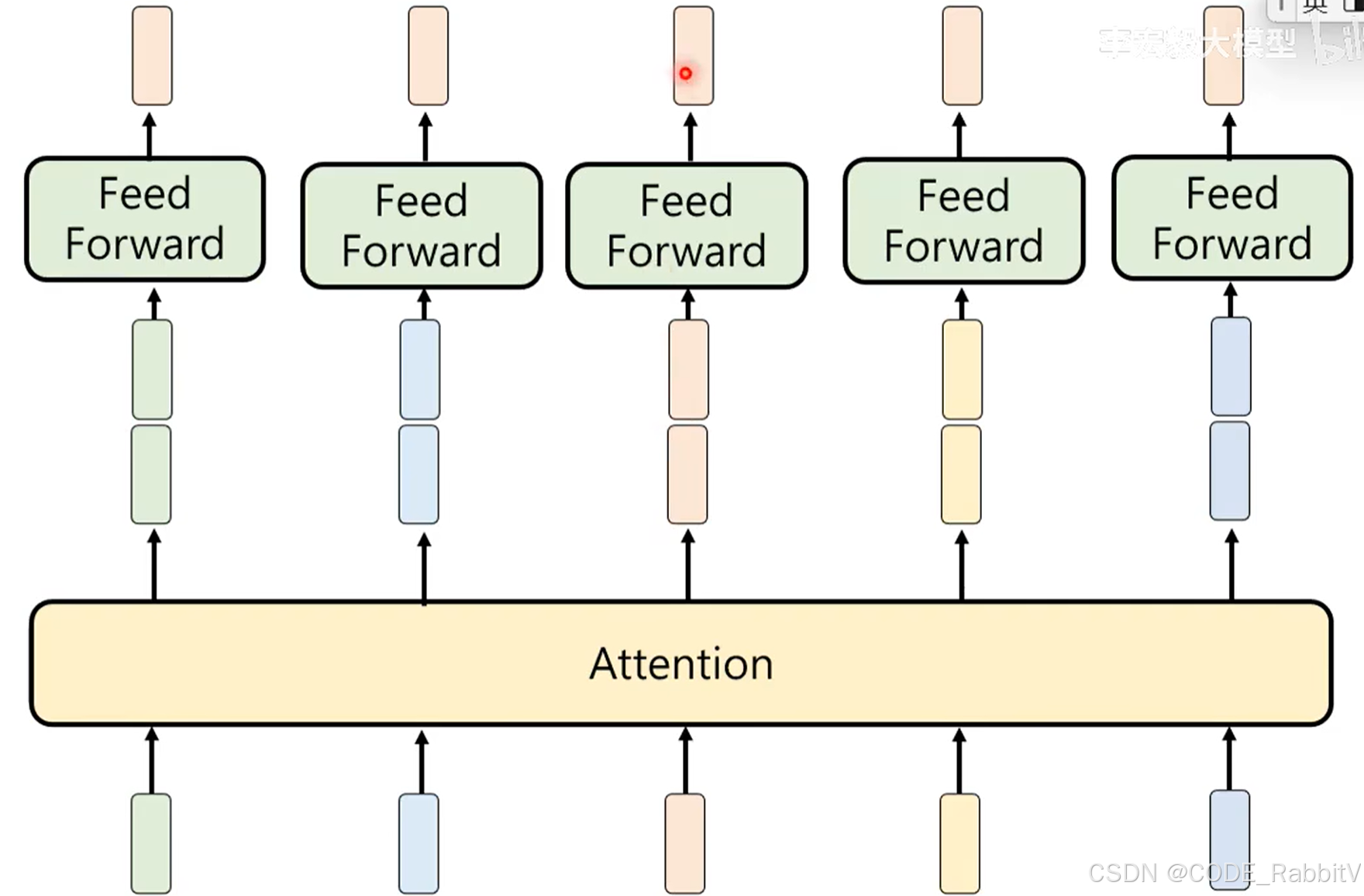
【3 & 4 Transformer Block】反复思考
- Attention + Feed Forward 操作,构成一个 Transformer Block
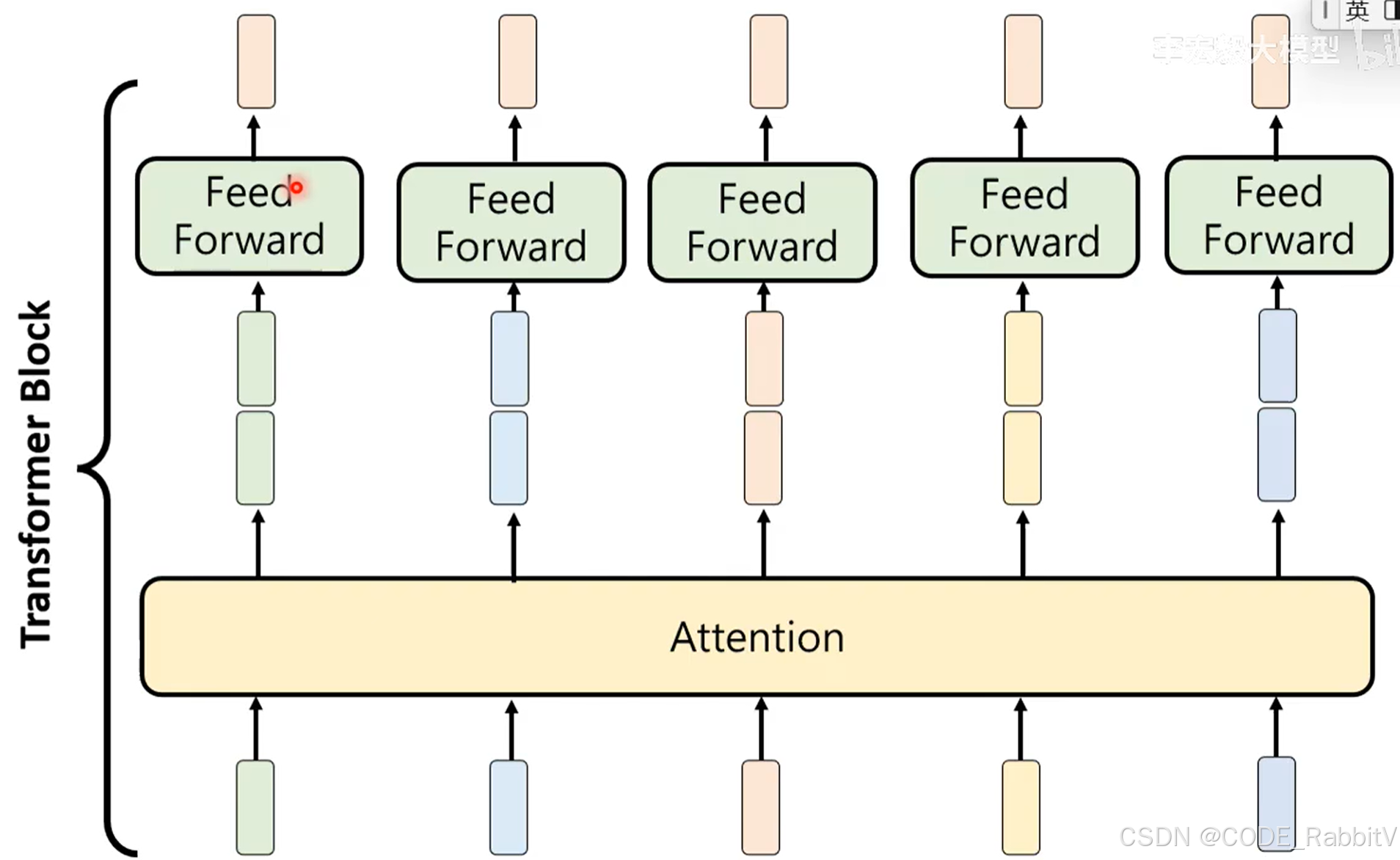
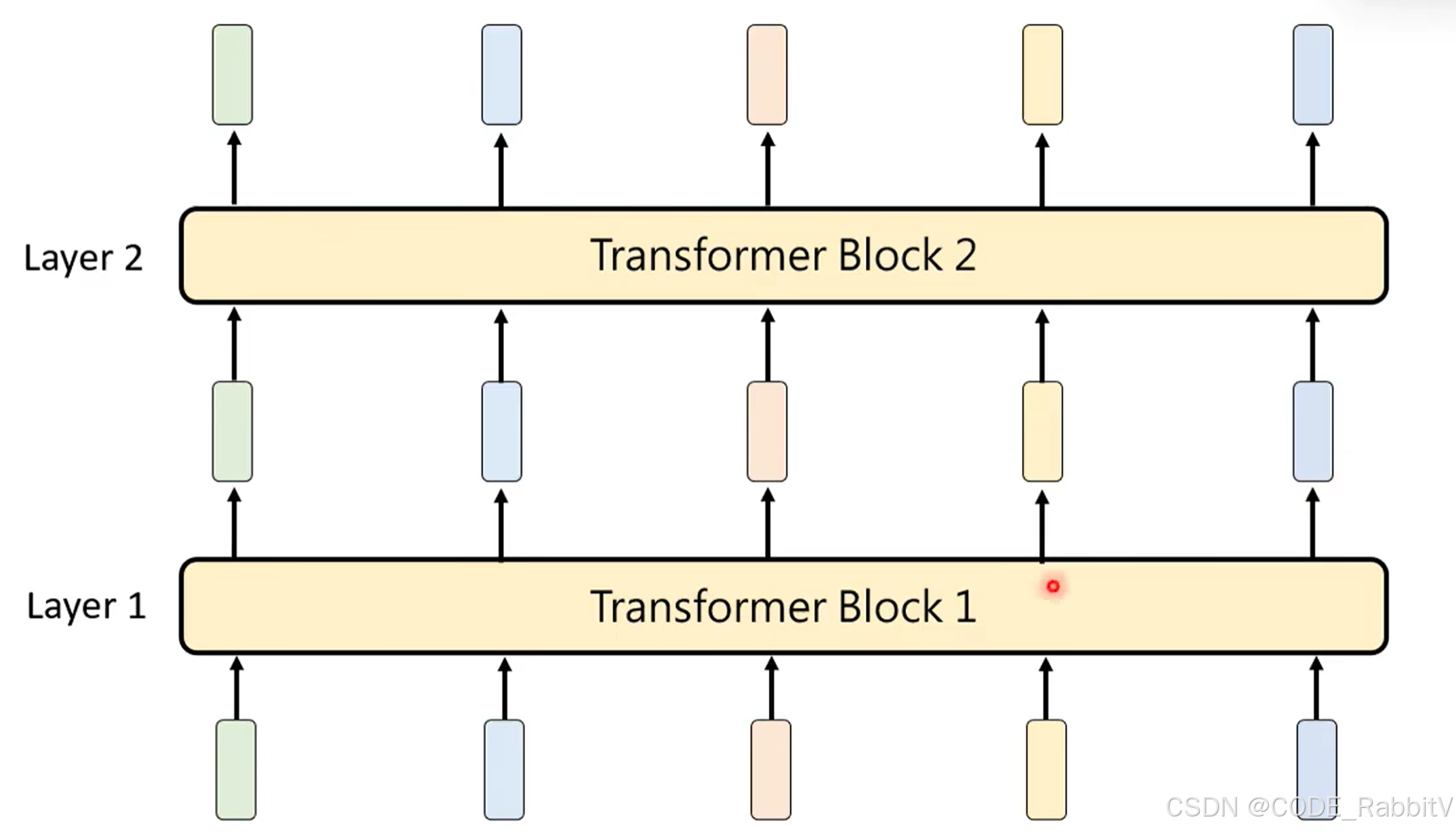
- 构建网络时,会叠加多个 Transformer Block 进行反复思考
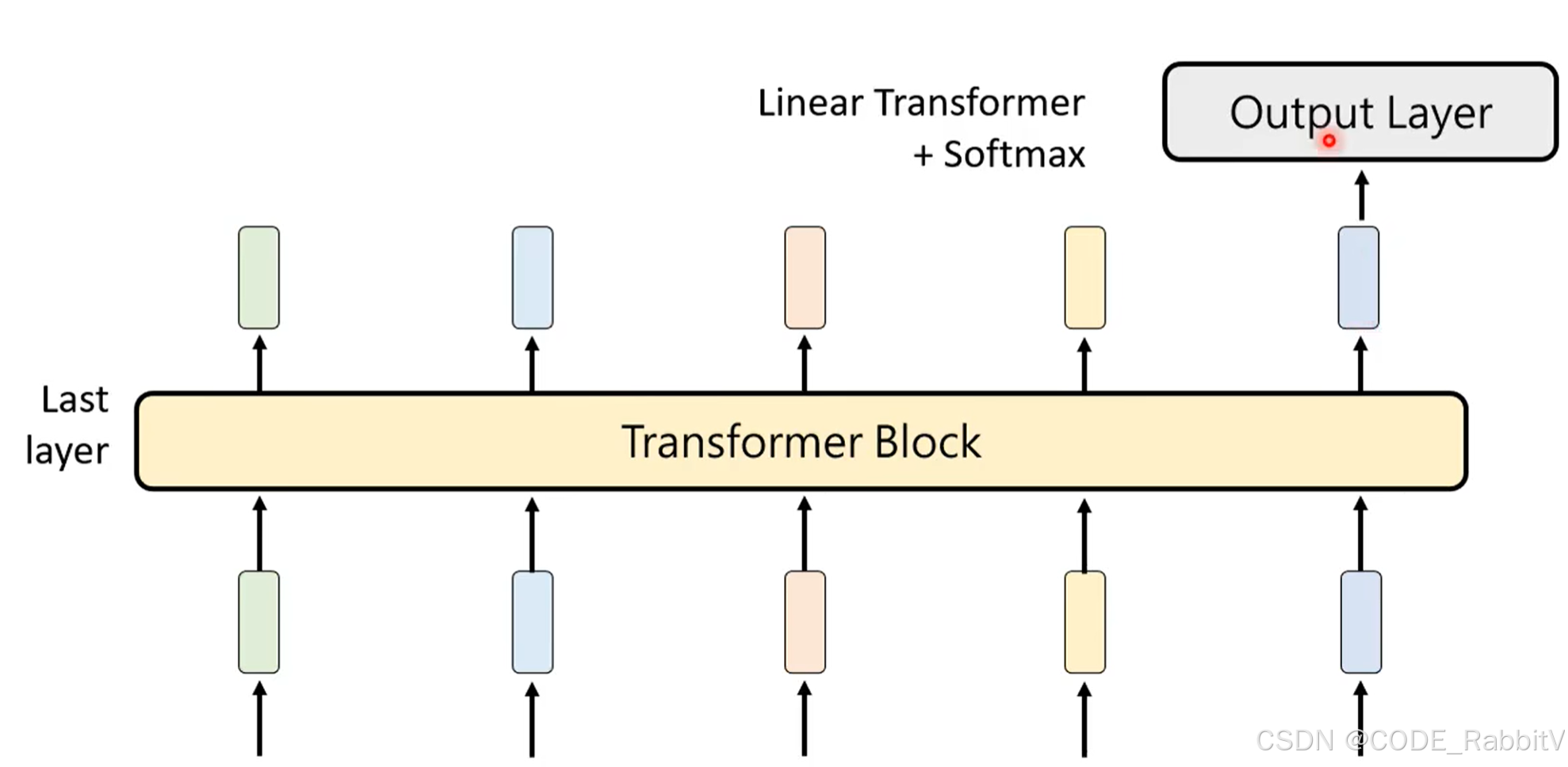
【5 Ouput Layer】输出概率
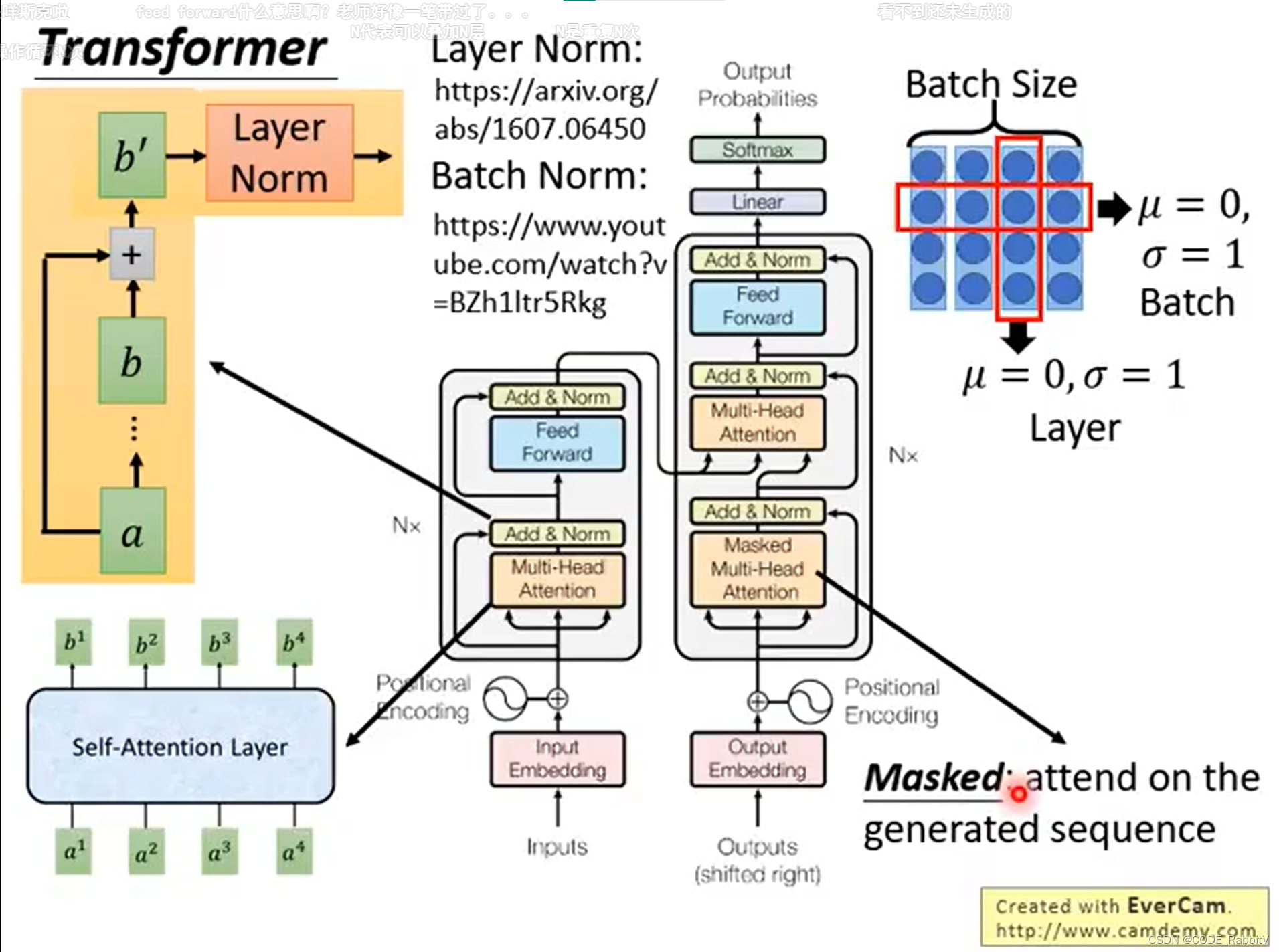
🌊 Transformer 模块详解 – 原始版本
经过简化版本,我们已经梳理清楚了 transformer 的核心思想,接下来,你会更容易理解 Transformer 模块详解
- Transformer :seq2Seq model with
self-attention
- 注意,对于 transformer 输出序列的长度是由模型自主决定的
- Transformer → \to → 【知名应用】BERT (unsupervised trained Transformer)
Self-attention 是 Attention变体,擅长捕获数据/特征的内部相关性
Self-attention 组成 Multi-head Self-attention
Multi-head Self-attention 反复利用组成Transforme
所以 … 后续会主要说明 self-attention
-
【Seq】Sequence:考虑分别用 RNN 和 CNN 处理
 .....
.....
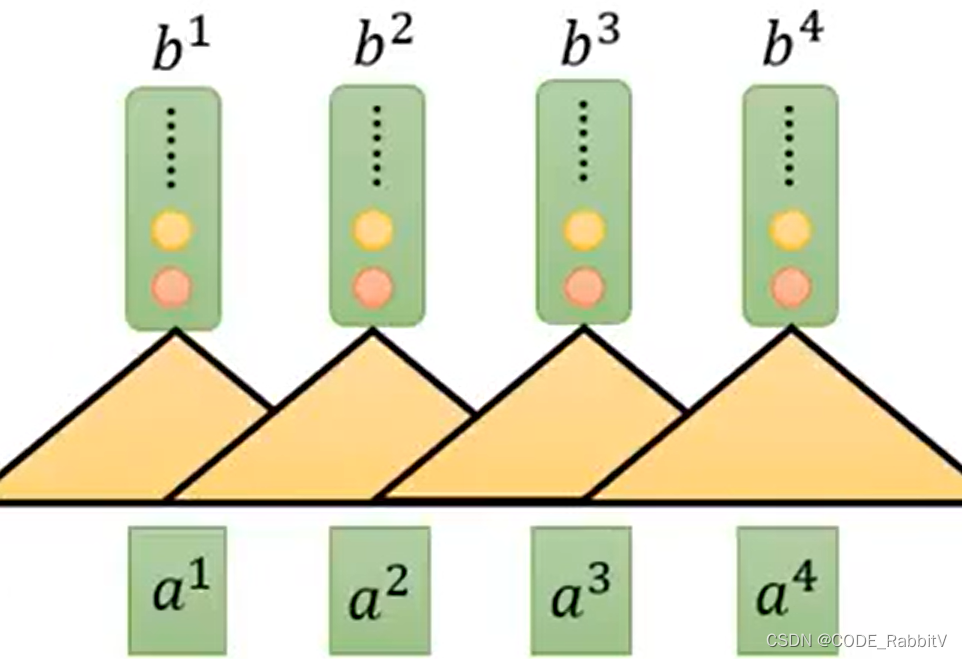
- 【左图】RNN: hard to parallel (需要序列输入进去处理)
- 【右图】CNN: replace RNN (单层覆盖范围有限,需要叠多层来扩展覆盖范围)
-
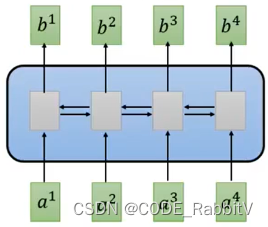
【replace CNN】Self-attention Layer: 类似双向RNN的作用,但是可并行化
- 【STEP-1】计算
qkv: q:query, k:key, v:value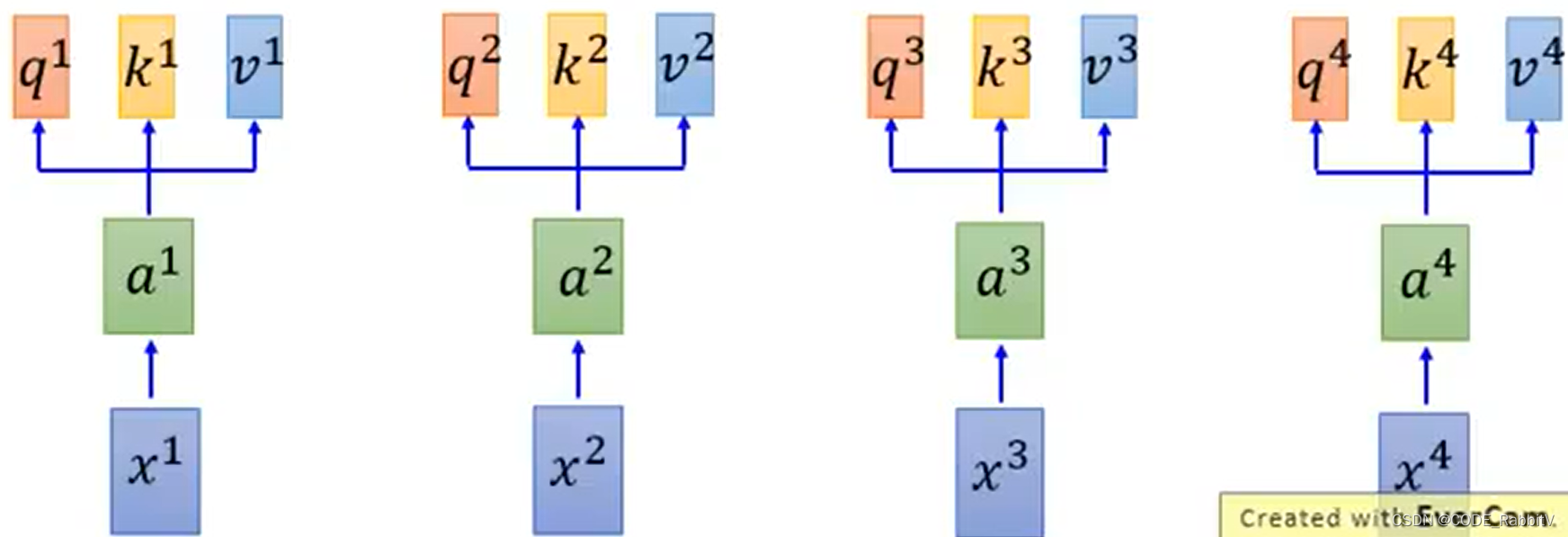 .....
.....

- 【STEP-2】每一个 q 对每一个 k 做 attention: 如 scaled dot-product attention
α i , j = q i ⋅ k j / d , d is the dim of q and k \alpha_{i,j}=q^i \cdot k^j / \sqrt{d}, \text{d is the dim of q and k} αi,j=qi⋅kj/d,d is the dim of q and k
- 【STEP-3】经过
softmaxlayer:
α ^ i , j = exp α i , j ∑ k exp α i , k \hat{\alpha}_{i, j}=\exp{\alpha_{i, j}}\sum_k \exp{\alpha_{i,k}} α^i,j=expαi,jk∑expαi,k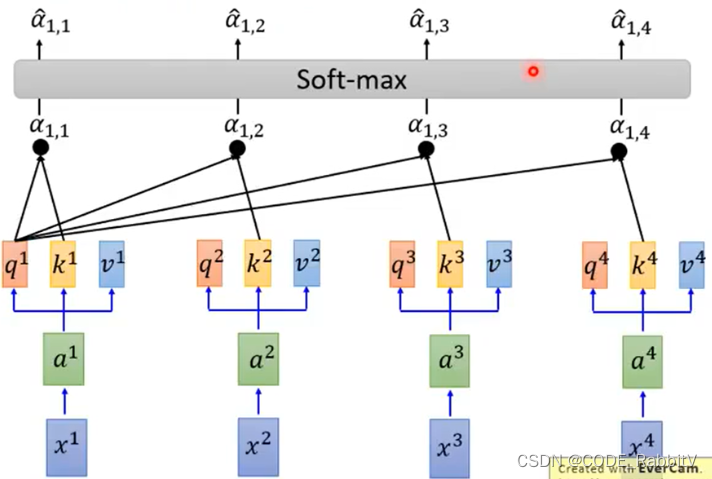
- 【STEP-4】计算输出
b:
b i = ∑ j α ^ i , j v j b^i = \sum_j \hat{\alpha}_{i,j}v^j bi=j∑α^i,jvj
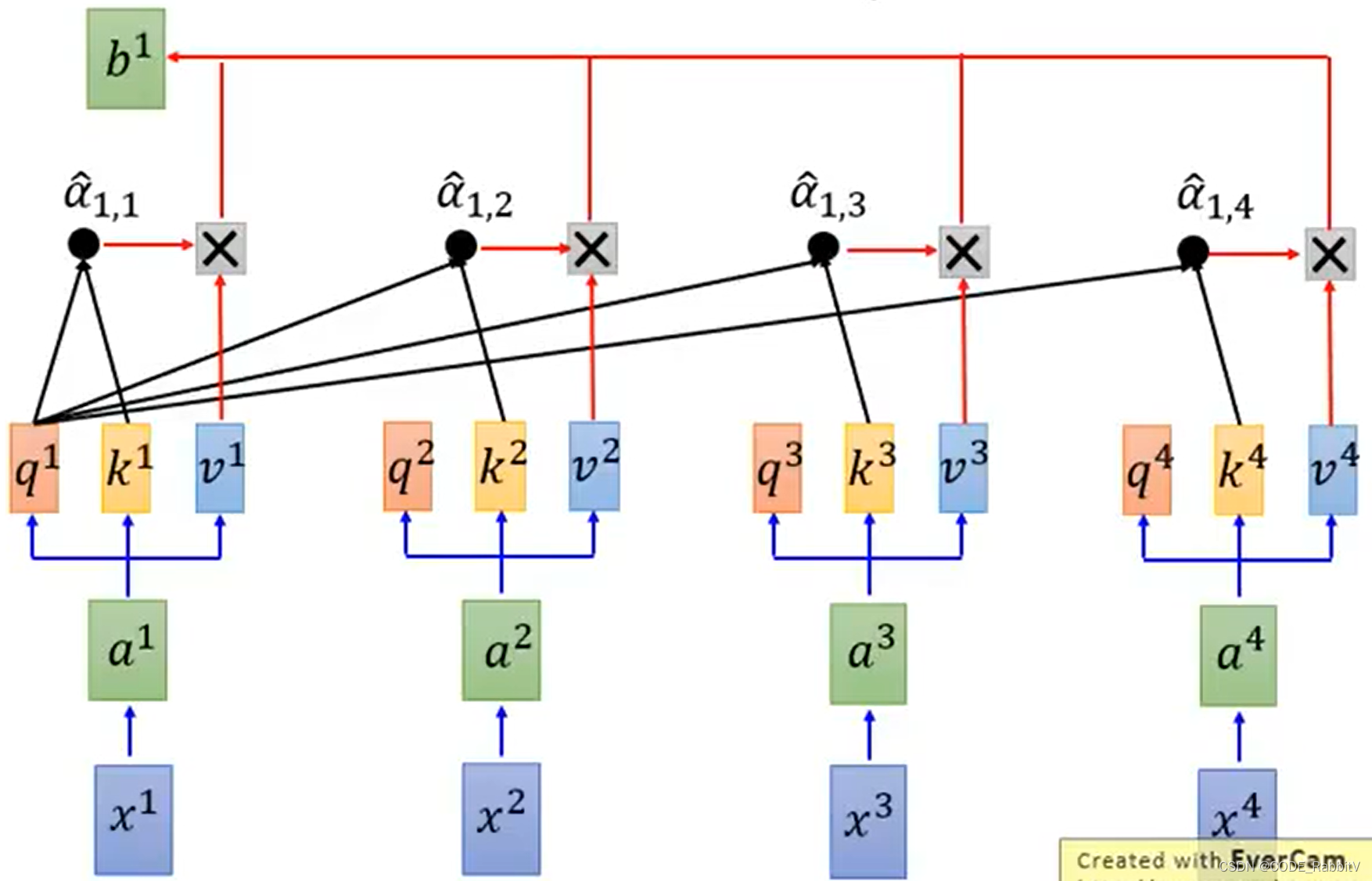
- 【STEP-1】计算
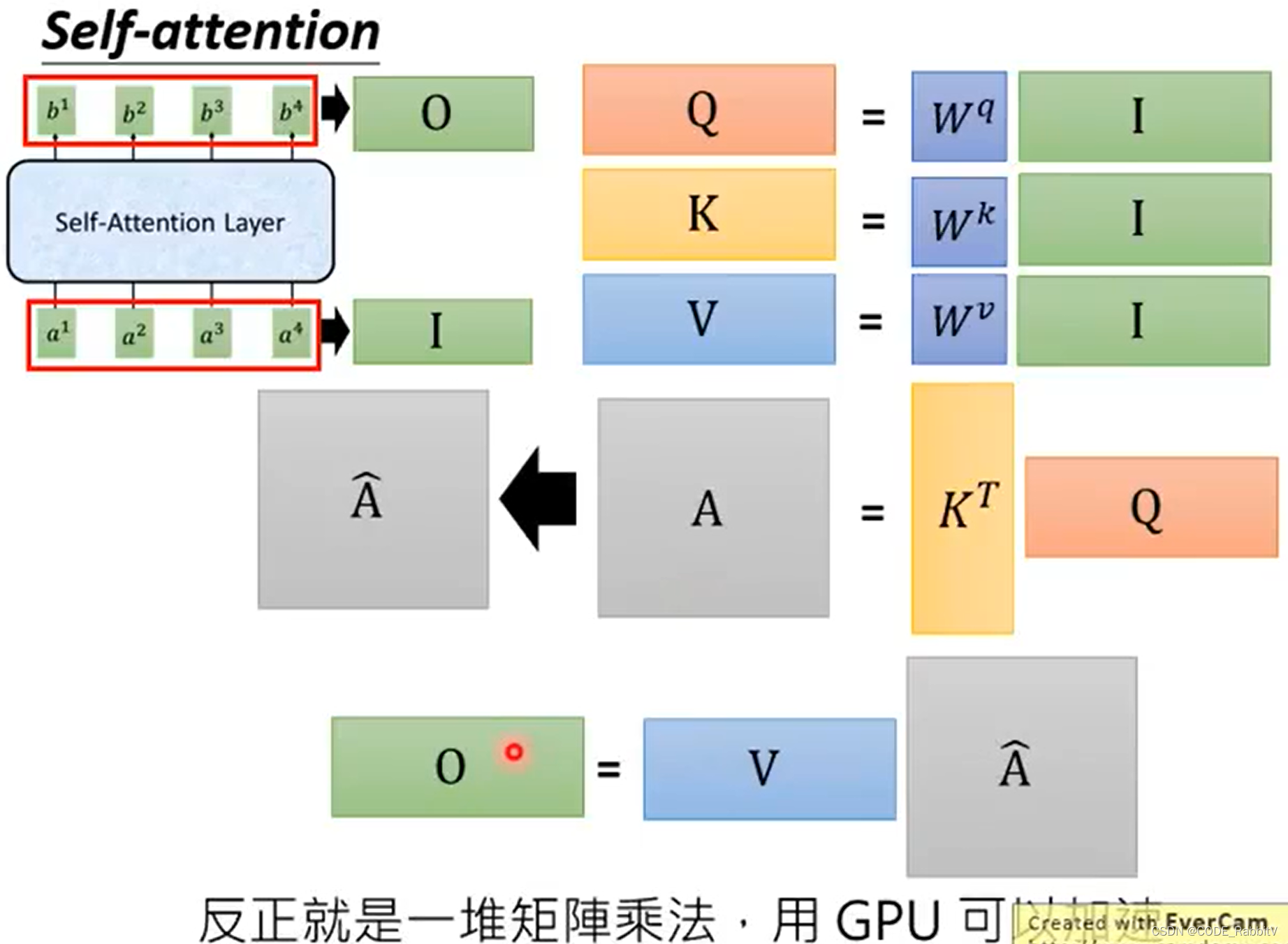
- 矩阵计算版本总结
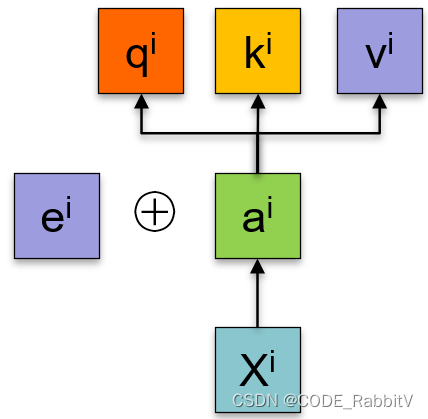
- 拓展:
- multi-head Self-attention: 多组 qkv 来关注不同信息

- positional encoding: α i \alpha^i αi += e i e^i ei, 可以引入位置信息 e i e^i ei
参考资料:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









