







From http://www.magesblog.com/2013/03/how-to-use-optim-in-r.html
A friend of mine asked me the other day how she could use the function optim in R to fit data. Of course there are built in functions for fitting data in R and I wrote about this earlier. However, she wanted to understand how to do this from scratch using optim.
The function optim provides algorithms for general purpose optimisations and the documentation is perfectly reasonable, but I remember that it took me a little while to get my head around how to pass data and parameters to optim. Thus, here are two simple examples.
I start with a linear regression by minimising the residual sum of square and discuss how to carry out a maximum likelihood estimation in the second example.
Minimise residual sum of squares
I start with an x-y data set, which I believe has a linear relationship and therefore I’d like to fit y against x by minimising the residual sum of squares.
dat=data.frame(x=c(1,2,3,4,5,6),
y=c(1,3,5,6,8,12) Next, I create a function that calculates the residual sum of square of my data against a linear model with two parameter. Think of y = par[1] + par[2] * x.
min.RSS <- function(data, par) {
with(data, sum((par[1] + par[2] * x - y)^2))
}Optim minimises a function by varying its parameters. The first argument of optim are the parameters I’d like to vary, par in this case; the second argument is the function to be minimised, min.RSS. The tricky bit is to understand how to apply optim to your data. The solution is the … argument in optim, which allows me to pass other arguments through to min.RSS, here my data. Therefore I can use the following statement:
result <- optim(par = c(0, 1), min.RSS, data = dat)
# I find the optimised parameters in result$par
# the minimised RSS is stored in result$value
result
## $par
## [1] -1.267 2.029
##
## $value
## [1] 2.819
##
## $counts
## function gradient
## 89 NA
##
## $convergence
## [1] 0
##
## $message
## NULLLet me plot the result:
plot(y ~ x, data = dat, main=”Least square regression”)
abline(a = result$par[1], b = result$par[2], col = “red”)
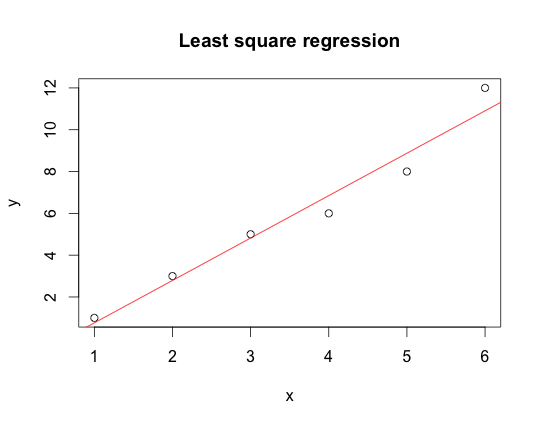
Great, this looks reasonable. How does it compare against the built in linear regression in R?
lm(y ~ x, data = dat)
##
## Call:
## lm(formula = y ~ x, data = dat)
##
## Coefficients:
## (Intercept) x
## -1.27 2.03Spot on! I get the same answer.
Maximum likelihood
In my second example I look at count data and I would like to fit a Poisson distribution to this data.
Here is my data:
obs = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 17, 42, 43)
freq = c(1392, 1711, 914, 468, 306, 192, 96, 56, 35, 17, 15, 6, 2, 2, 1, 1)
x <- rep(obs, freq)
plot(table(x), main="Count data")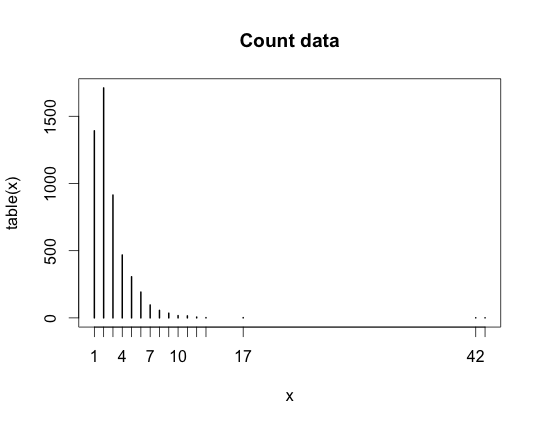
To fit a Poisson distribution to x I don’t minimise the residual sum of squares, instead I maximise the likelihood for the chosen parameter lambda.
The likelihood function is given by:
lklh.poisson <- function(x, lambda) lambda^x/factorial(x) * exp(-lambda)and the sum of the log-liklihood function is:
log.lklh.poisson <- function(x, lambda){
-sum(x * log(lambda) - log(factorial(x)) - lambda)
}By default optim searches for parameters, which minimise the function fn. In order to find a maximium, all I have to do is change the sign of the function, hence -sum(…).
optim(par = 2, log.lklh.poisson, x = x)
## Warning: one-diml optimization by Nelder-Mead is unreliable: use "Brent"
## or optimize() directly
## $par
## [1] 2.704
##
## $value
## [1] 9966
##
## $counts
## function gradient
## 24 NA
##
## $convergence
## [1] 0
##
## $message
## NULLOk, the warning message tells me that I shoud use another optimisation algorithm, as I have a one dimensional problem - a single parameter. Thus, I follow the advise and get:
optim(par = 2, log.poisson, x = x, method = "Brent", lower = 2, upper = 3)
## $par
## [1] 2.704
##
## $value
## [1] 9966
##
## $counts
## function gradient
## NA NA
##
## $convergence
## [1] 0
##
## $message
## NULLIt’s actually the same result. Let’s compare the result to fitdistr, which uses maximum liklihood as well.
library(MASS)
fitdistr(x, "Poisson")
## lambda
## 2.70368
## (0.02277)No surprise here, it gives back the mean, which is the maximum likelihood parameter.
mean(x)
## [1] 2.704For more information on optimisation and mathematical programming with R see CRAN Task View on this subject















 1594
1594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









