









异常
先回忆一下C语言中处理错误的方式:
1.终止程序:如assert、exit(0)。缺点:暴力,对用户不是很友好。
2.返回错误码。(常用,错误码是Windows操作系统提供的)
若用VS编译器,用GetLastError() 来获取最近一次发生错误的错误码。并且可以通过VS工具–错误查找的选项,来输入对应的错误码,来看对应的错误描述。但是仅限于一部分错误码描述,若要查特别大的错误码的描述,可上网查。
#include<stdio.h>
#include<Windows.h>
void test()
{
FILE* fp = fopen("1.txt", "r");
if (NULL == fp)
{
int error=GetLastError();
printf("%d\n", error);
return;
}
fclose(fp);
}
缺点:需要程序员自己去找错误。
3.C标准库中setjmp和longjmp组合。
功能:发生错误,跳转到指定的位置去执行。若要长跳转,或者函数之间跳转用此函数。
下面通过代码来看看函数怎么用?
jmp_buf buff;//由setjmp来设置buff信息,
void test()
{
char* p = (char*)malloc(0xffff);
if (NULL == p)
{
//一旦申请空间失败时,longjmp会跳转到buff指定的位置。就是setjmp,第二个参数,交给istate。
longjmp(buff, 1);
}
//操作
free(p);
}
void test2()
{
FILE* fp = fopen("2.txt", "r");
if (NULL == fp)
{
longjmp(buff, 2);
}
//操作
fclose(fp);
}
int main()
{
//setjmp设置longjmp函数的跳转到什么地方。
//注意:setjmp在首次调用时,一定会返回0
int istate = setjmp(buff);
if (0 == istate)//正常处理流程,没发生错误,为0
{
//进行正常操作
test();
test2();
}
else//istate不是0,说明程序遇到非法情况,longjmp跳转到此位置
{
//写的是程序的错误处理代码
switch (istate)//对istate的值,进行对应的处理
{
case 1://根据longjmp的第二个参数,来分析错误
cout << "malloc申请失败" << endl;
case 2:
cout << "文件打开失败" << endl;
default:
cout << "其他错误" << endl;
}
}
return 0;
}
注意:若要用longjmp必须在longjmp调用之前,先设置程序的跳转点。否则程序崩溃。
补充:
与setjmp类似的是goto,也可以跳转,但是goto只能在函数体内跳转,而setjmp可以任意跳转。(不建议用goto)
void test()
{
FILE* fp = fopen("1.txt", "r");
if (NULL == fp)
{
goto L;//越过goto L和L:之间的部分。
}
L:
fclose(fp);
}
扩展:
为什么下面代码可以编译成功:
void test()
{
https://www.baidu.com;
return;
}
因为https:编译认为是标签,类似于goto中的L:。//后面就是注释,所以可以编译。
C++中有自己的处理异常的操作:
在C++中当函数有异常就会抛出异常,让函数的直接或者间接的调用者在外部接收异常,最后来解决错误。
对应的关键字:
throw:抛出异常
catch:捕获异常
try:C++中对于有可能抛出异常的代码,必须要放在try里,代表尝试捕捉。
看一段代码:
void test2()
{
FILE* fp = fopen("2.txt", "r");
if (nullptr == fp)
{
throw 1;//当出现错误,抛出异常1。此1放在throw后则代表整形类型1号异常。
//异常不是每次都发生,只是个小概率的事情。
//throw后不一定要加整形,也可以是其他类型。
//若抛出异常,且本函数没有捕获异常的操作,异常就会往外跳,直到跳到有捕获异常的操作的地方。并且本函数下面的代码就会忽略,因此可能造成申请的空间没释放,造成内存泄漏。所以就需要在catch内进行释放。
}
fclose(fp);
}
int main()
{
try//C++中对于有可能抛出异常的代码,必须要放在try里,代表尝试捕捉。
//并且try不能单独使用,必须和catch搭配使用。
{
test2();
}
catch (int e)//根据抛出异常的类型,来写出对应的catch,捕获抛出异常
{
//处理抛出错误,
cout << e << endl;
}
//当catch中处理完错误时,代码继续向下执行。
//注意:这里不是回到抛出异常的函数中继续执行代码,而是继续执行catch后的代码。
//继续执行常规文件操作
return 0;
}
异常的抛出和匹配的原则:
1.根据抛出异常对象的类型,来找到对应的catch进行捕获,并且异常对象之间基本不会发生类型转化。
2.抛出的异常,遵循离抛出位置最近的且类型相同的catch捕获的原则。
3.因为函数内异常对象是栈上申请的临时对象,所以在出函数作用域时要被销毁。因此抛出异常对象时,会发生一个对抛出异常对象的拷贝,抛出的是这个对象的拷贝。然而抛出的拷贝对象在捕获位置中被销毁。
用代码理解一下:
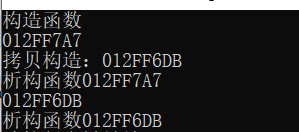
class A//用类的对象,可以清晰地证明此原则
{
public:
A()
{
cout << "构造函数" << endl;
}
A(const A&a)
{
cout << "拷贝构造:" <<this<< endl;
}
~A()
{
cout << "析构函数" <<this<< endl;
}
};
void test1()
{
A a;
cout << &a << endl;
//因为a是栈上的对象,所以在出函数作用域时要被销毁,所以要抛出一个拷贝。
throw a;//因为实际抛出的是a的拷贝,所以此处要调用拷贝构造。
}
int main()
{
try
{
test1();
}
catch (A& ra)
{
cout << &ra << endl;
}
return 0;
}
4.catch(…)的用法
(1)是一种万能捕获,也就是任意类型的异常都可以用catch(…)的方式进行捕获。
(2)用来实现异常的重新抛出。
用代码来理解异常的重新抛出:
void test1()
{
FILE* fp = fopen("1.txt", "r");
if (nullptr == fp)
throw 1;
fclose(fp);
}
void test2()
{
int* p = new int[10];
try
{
test1();
}
catch (...)
{
//1.假设test2不知道test1抛出异常的类型,则无法处理异常。
//2.假设test2知道test1抛出异常的类型,但是test2没有责任必须要解决test1抛出的异常,test2可以继续向外抛从test1中捕获的异常。这就是异常的重新抛出。
delete[] p;
throw;//向外继续抛test1中的异常,如果不知道从test1中捕获的异常是什么,则不写即可。
}
delete[] p;
}
int main()
{
try
{
test2();
}
catch (int e)
{
//处理异常
//在最后一个捕获中,不许将之前的所有的异常全部处理,否则会造成很大问题。
}
return 0;
}
- 一般情况下,异常不会抛出上述的代码中的异常对象,一般采用继承的方式进行捕获。
在函数调用链中异常栈展开匹配原则:
我们通过下图来理解栈展开。

异常安全
下面来说说异常的安全使用方式
1.最好不要在构造函数中抛异常,有可能造成对象构造不完整或者没有完全初始化对象。
2.同时,也最好不要在析构函数中抛异常,因为异常本来就是清理资源的,若抛出异常就有可能导致资源泄漏(内存泄漏)。
3.C++中异常经常会导致资源泄漏的问题,比如在new和delete中抛出异常,会导致内存泄漏。在lock和unlock中抛出异常,会导致死锁,C++使用RAII来解决这些问题。
异常规范
如果没有对异常进行规范,那么抛出的异常将会有很多种,若要对应的捕获异常,这显然很麻烦。所以这就需要我们来指定函数可抛出异常的类型,这就需要异常规范。
异常规范的方法:
在函数后跟throw(类型)来指明可以抛出异常的类型。
void test1()throw(int,char)//指明可抛出异常的类型,若抛出其他类型在编译阶段报错。
//例:如果抛异常,只能抛出整形和字符类型的异常。否则,在编译阶段就会报错。
{
throw 2;
}
void test2()throw()//不能抛出异常。否则,在编译阶段就会报错。
{}
void* operator new (std::size_t size) throw (std::bad_alloc);
// 这里表示这个函数只会抛出bad_alloc的异常















 1551
1551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









