







HUE版本:3.12.0
Hive版本:2.1.0
前言
通过浏览器访问ip:8888登陆HUE界面,首次登陆会提示你创建用户,这里使用账号/密码:hue/hue登陆。
一、业务场景
执行Hive SQL脚本查询mytable表数据前10条,field以”\t”分割,并输出到HDFS指定路径。
二、创建mytable表
create table if not exists mytable(sid int ,sname string)
row format delimited fields terminated by ' ' stored as textfile;
三、创造数据
样例数据mytable.txt,将其放到HDFS路径的/tmp/目录下
1 张三
2 李四
3 王五
4 李六
5 不告你
将数据导入mytable中,执行以下命令:
load data inpath "/tmp/mytable.txt" into table mytable;
四、创建Hive SQL脚本
在HDFS路径/user/hue/learn_oozie/mazy_hive_1下,创建mazy_hive_1.sql,sql中的参数使用${hivevar:参数}展示,内容如下:
INSERT overwrite directory '${hivevar:outputpath}'
row format delimited fields terminated by "\t"
SELECT sid,sname FROM mytable LIMIT 10;
五、创建Workflow
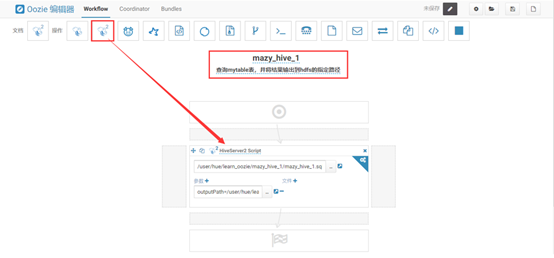
将HiveServer2移动到箭头处,添加sql脚本,添加参数:
outputpath=/user/hue/learn_oozie/mazy_hive_1/output
如下图所示:
六、设置Workflow并执行
点击“设置”,如下图所示:
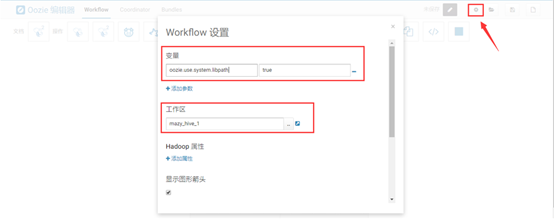
默认配置oozie.use.system.libpath为true,这样会在工作区目录下默认新建lib包,如果需要jar包依赖的话,可以放在lib目录下。
工作区的目录HUE会默认生成,也可以自定义设置,lib文件会生成在该工作区内。
这里将工作区设为:/user/hue/learn_oozie/mazy_hive_1。
设置完毕后,执行该Workflow。
七、查看结果
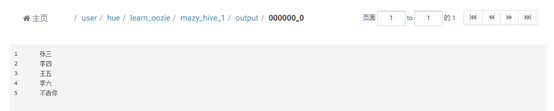
执行Workflow后,会生成一个job作业,job所属用户为登陆HUE Web的用户。 等Workflow执行成功后,在HDFS路径上查看/user/hue/learn_oozie/mazy_hive_1/output/00000-0文件,如下图所示:
八、总结
在HUE上通过Oozie调用Hive SQL任务流:
- 需要先创建好Hive SQL语句,
- 然后在Oozie Workflow里面选择Hiveserver2;
- 选择之前创建好的Hive SQL语句,设置变量;
- 设置工作区及依赖的jar包路径
- 执行Workflow
码字不易,如果您觉得文章写得不错,请扫码关注公众号支持作者~ 您的关注是我写作的最大动力?

















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











