







HUE版本:3.12.0
Ambari版本:2.6.1.0
HDP版本:2.6.4
Spark版本:2.2.0
前言
通过浏览器访问
ip:8888登陆HUE界面,首次登陆会提示你创建用户,这里使用账号/密码:hue/hue登陆。
本篇文章再给大家讲述一下如何配置并使用Spark Notebook。
一、修改hue.ini
1. 配置Spark
打开hue.ini文件,找到【yarn_clusters】【default】,修改spark_history_server_url值。
spark_history_server_url=http://liuyzh2.xdata:18081
如下图所示:
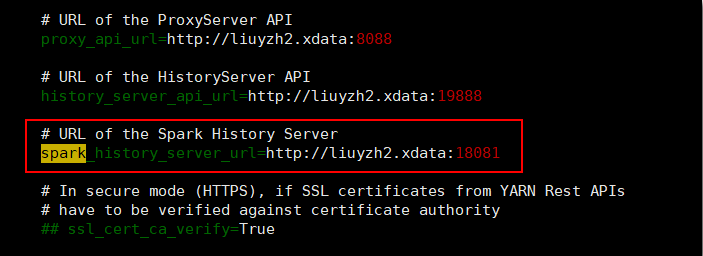
其中
liuyzh2.xdata是Spark2 History Server所在机器的主机名18081端口是Spark2的spark.history.ui.port属性值
HUE是通过livy server来连接的Spark,Spark依赖于Hive,配置如下图所示:
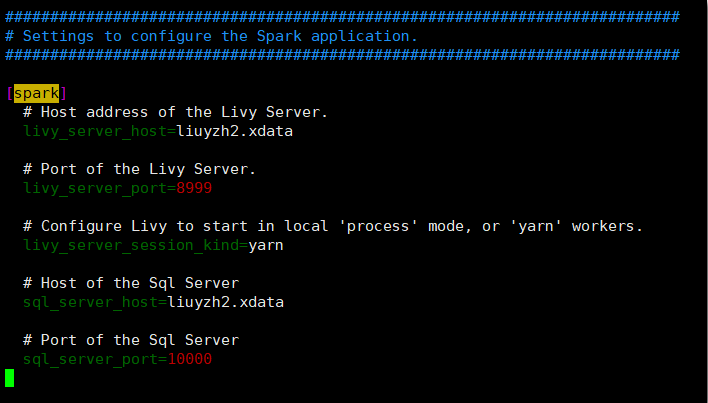
上述配置值都可以去Spark和Hive的配置文件中找到答案,这里就不赘述了。
2. 配置Notebook
打开hue.ini文件,找到【notebook】,如下图所示:
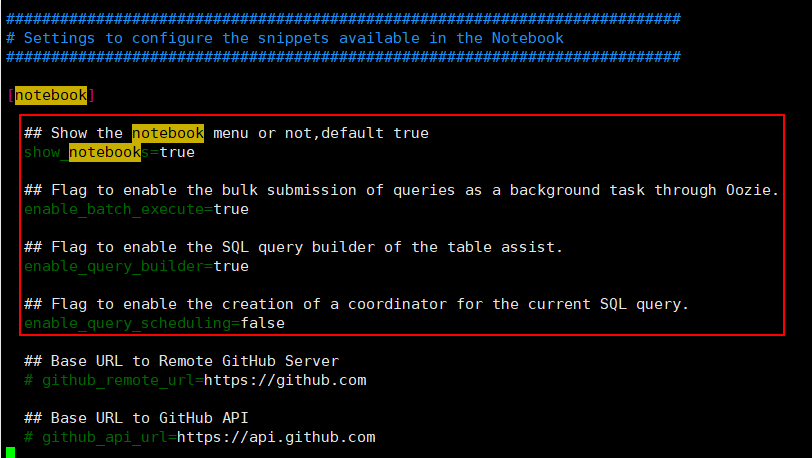
其中:
- show_notebooks:显示或不显示笔记本菜单 默认值: true
- enable_batch_execute:此标记用于通过 Oozie 以后台任务的形式批量提交查询。 默认值: false
- enable_query_scheduling:启用当前 SQL 查询 Coordinator 创建的标记。 默认值: false
- enable_query_builder:启用表帮助 SQL 查询生成器的标记。 默认值: true
Notebook支持很多种语言,比如:Hive、Impala、SparkSql、Scala、PySpark、R、Spark Submit Jar、Pig、Sqoop1、Shell等很多种语言。我们可以将某些语言给注释掉,不让其在页面上展示。比如,将Impala注释。如下图所示:
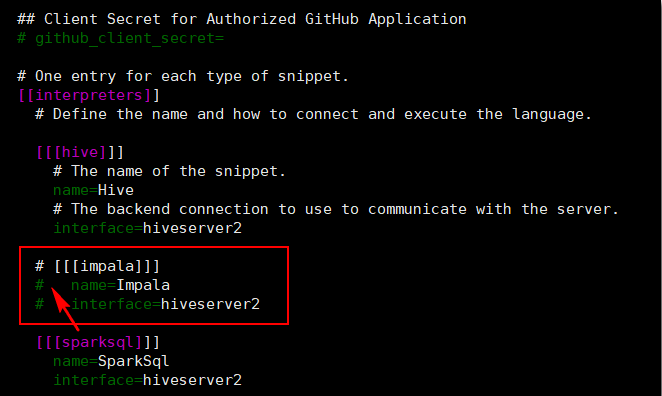
这样在页面上的Notebook就不支持Impala了。
备注: 保存修改的配置并重启HUE服务。
二、修改Spark配置
打开ambari页面,集群安装的是Spark2服务,所以进入Spark2配置;配置选项中选择高级livy2-conf,如下图所示:
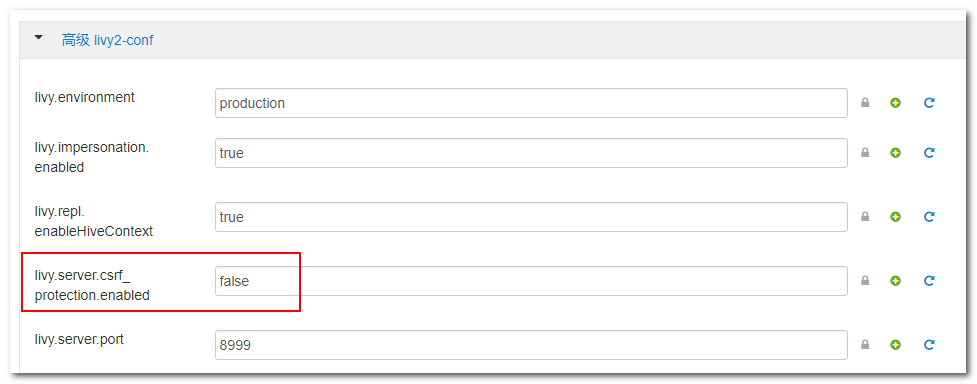
将livy.server.csrf_protection.enabled的值修改为false。保存修改后的配置并重启Spark2服务。
**备注:**如果不修改为false的话,在使用Notebook的Spark语言时,会报csrf的相关错误。
三、新建Spark Notebook
Spark分很多种语言,有pySpark、Scala、Spark SQL等。本章以pySpark为例,来介绍如何使用Spark Notebook。
通过浏览器访问ip:8888登陆HUE界面,首次登陆会提示你创建用户,这里使用账号/密码:hue/hue登陆。
点击页面的笔记本,点击+笔记本来新建笔记本,如下图所示:

我们可以在Notebook里面选择使用很多类型的编程语言,如下图所示:
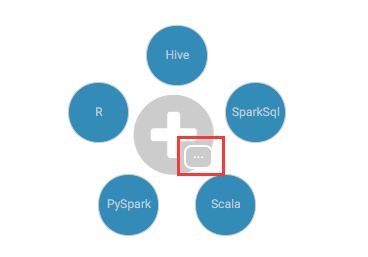
在上图,这里我们可以点击红框,来选择更多的编程语言,这里我们选择pySpark来跑一个wordCount程序。
当新建了一个pySpark Notebook后,后台会以登陆HUE系统页面的用户身份(比如hue)新建一个livy-session-xx的Spark应用程序,如下图所示:

同时在会话左侧也会出现一个圆圈,表示正在初始化一个livy session会话,如下图所示:

当圆圈消失,出现执行按钮时,我们就可以执行代码了。
四、执行wordCount任务
首先使用hue上面的HDFS功能直接在/tmp路径下新建wordCount.txt,文件内容如下:
My English teacher has a big house.
It has a living room, a big dining room, two bedrooms, a study, two bathrooms and a big kitchen.
In the living room, there is a big picture, four brown sofas, white fans and blue walls. The TV set is big. There is a big Chinese knot on the wall. There are lanterns below the lights. I like them.
This is my English teacher’s house.
我们使用pySpark读取wordCount.txt文件内容:
file = sc.textFile("/tmp/wordCount.txt")
word = file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
for row in word.collect():
print row
执行的结果:
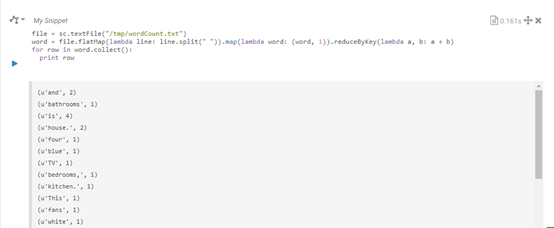
wordCount任务执行成功。
五、关闭Session会话
当使用完pySpark Notebook之后,不要忘记关闭livy session,如果session过多,就会导致yarn内存使用率过大。
Spark livy session空闲过期时间默认为1小时,可在spark2-conf.xml内修改livy.server.session.timeout值。今天我们主要说明一下如何主动关闭Session会话。
关闭的方式有很多种,可以点击Notebook页面的”右上角>上下文”来关闭会话,如下图所示:
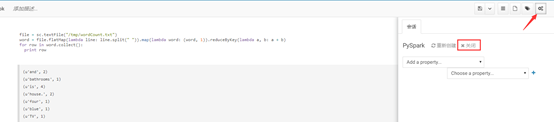
稍等一会,在hue的作业浏览器页面,就会发现该livy-session已成功结束。

也可以去hue的作业浏览器页面手动kill掉session进程,如下图所示:

嗯,可以通过这两种方式主动关闭session会话,以避免Yarn内存长时间无效使用。
六、总结
使用Spark Notebook需要经过如下几个步骤:
- 修改
hue的配置文件,主要修改Spark与Noytebook的相关配置项。 - 修改
Spark的配置文件,避免出现csrf错误。 - 使用
Spark Notebook。 - 用完之后,记得及时关闭
Spark livy session。
推荐阅读
码字不易,如果您觉得文章写得不错,请扫码关注公众号支持作者~ 您的关注是我写作的最大动力?

















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











