









 本文介绍了如何通过配置Hue来使用Livy执行Spark任务,包括解决SparkSubmitJar执行时出现的NullPointerException错误的方法。
本文介绍了如何通过配置Hue来使用Livy执行Spark任务,包括解决SparkSubmitJar执行时出现的NullPointerException错误的方法。
为执行Spark Job,Hue提供了执行服务器Livy,加强了Hue notebook对spark的支持。它类似于Oozie hadoop工作流服务器,对外提供了Rest Api,客户端将spark jar以及配置参数传递给livy,livy依据配置文件以及参数执行jar。
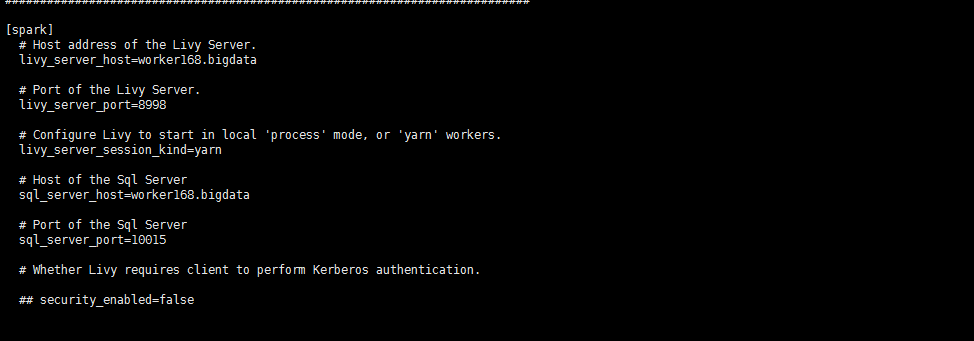
hue配置文件*.ini中配置如下:

2.测试Spark Submit Jar 点击“数据分析”-Spark Submit Jar,粘贴 点击运行
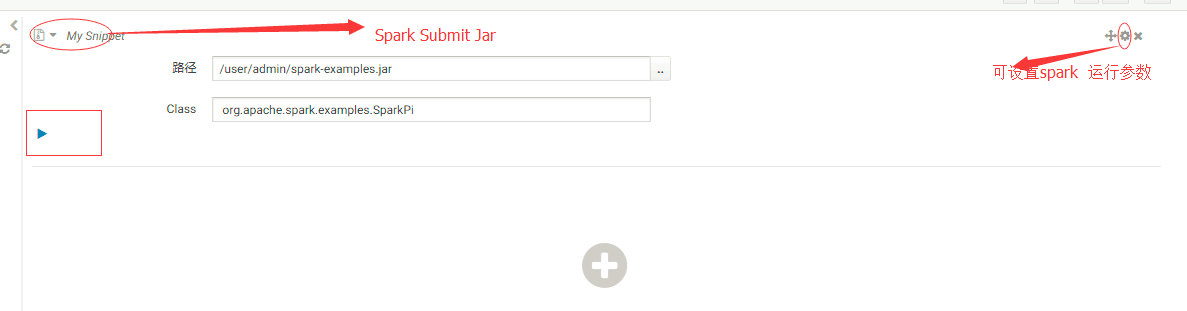
会报错: "java.lang.NullPointerException"(500)
需修改Hue中文件:desktop/libs/notebook/src/notebook/connectors/spark_batch.py,文件已放入附件中,删除35行-80行原来的代码,替换为附件中的代码,之后执行spark自带的example可执行成功。+表示增加行,-表示删除行
def execute(self, notebook, snippet):
api = get_spark_api(self.user)
- properties = {
- 'file': snippet['properties'].get('app_jar'),
- 'className': snippet['properties'].get('class'),
- 'args': snippet['properties'].get('arguments'),
- 'pyFiles': snippet['properties'].get('py_file'),
- 'files': snippet['properties'].get('files'),
- # driverMemory
- # driverCores
- # executorMemory
- # executorCores
- # archives
- }
+ if snippet['type'] == 'jar':
+ properties = {
+ 'file': snippet['properties'].get('app_jar'),
+ 'className': snippet['properties'].get('class'),
+ 'args': snippet['properties'].get('arguments'),
+ }
+ elif snippet['type'] == 'py':
+ properties = {
+ 'file': snippet['properties'].get('py_file'),
+ 'args': snippet['properties'].get('arguments'),
+ }
+ else:
+ properties = {
+ 'file': snippet['properties'].get('app_jar'),
+ 'className': snippet['properties'].get('class'),
+ 'args': snippet['properties'].get('arguments'),
+ 'pyFiles': snippet['properties'].get('py_file'),
+ 'files': snippet['properties'].get('files'),
+ # driverMemory
+ # driverCores
+ # executorMemory
+ # executorCores
+ # archives
+ }
response = api.submit_batch(properties)
return {


















 2596
2596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











