







基础知识点整理
1 什么是IR information retrieval
1.1 定义相关
- 1.1.1 结构相关
- 1.1.2 信息项
1.2 信息需求 information need
- 1.2.1 4阶段
- 1.2.2 查询query
1.3 IR作用功能
1.3.1 相关定义
- 1.3.1.1 具体
- 1.3.1.2 补充
1.3.2 相关性 Relevance
1.3.3 问答相关 Qustion Answering 非IR
1.3.4 信息提取 information extraction 非IR
2 有关查询
2.1 矩阵相关
- term-document incidence matrix
2.2 索引 indexing
2.2.1 inverted index
- 大纲
- 具体
- 代码相关
2.3 查询优化
2.3.1 skip pointers
- 2.3.1.1 相关代码
3 预处理 processing
3.1 引言,开始流程
3.2 方法措施,提高效率
stopwords 停词
stemming 提取词干
- 相关代码,使用porter提取法
lemmatisation 词形还原
3.3 phrase query 短语查询
- biword index 双字索引
- positional index 位置索引
4 向量模型的使用 vector space
4.1 introduction
4.2 权重 term weighting
TF-IDF
- 计算方式
4.3 优点和缺点
4.4 步骤
5 BM25 模型
- 5.1 TF
- 5.2 IDF
- 5.3 综合结果
- 5.4 俩变种
6 Evaluation 评估
6.1 引言
- 小概念
- 例子
6.2 Precision/Recall 精确度和召回率
6.3 Single value metric 单值度量 基于RelRet
- P@n
- R-precision
- MAP
6.4 bpref
6.5 NDCG
6.6 结果
7 IR pipelines和现代IR
8 Fusion
8.1 introduction
8.2 overlap 语料重叠
- 8.2.1 三种效应
- 8.2.2 三种融合技术
8.3 Rank-Baesd 基于排名的融合技术
- 8.3.1 interleaving 交错法
- 8.3.2 Borda-Fuse
- 8.3.3 Reciprocal Rank Fusion 倒数排名融合
- 8.3.4 其他
8.4 Score-Based
- CombSUM 方法
- 分数标准化(Score Normalisation)
- CombMNZ 方法
- 线性组合(Linear Combination)
8.5 Probability-Based Fusion
- ProbFuse 方法
- SegFuse 方法
- SlideFuse 方法
- 结论
9 PageRank
- 简介
- 文档重要性
- PageRank算法
- PageRank的工作原理
- PageRank的简化公式
- PageRank的问题和改进
- PageRank的计算示例
- PageRank的收敛性
- PageRank的影响
- 总结
10 相关性反馈(Relevance Feedback)
- Rocchio算法
- 向量空间中的质心(Centroids)
- Rocchio算法的实践应用
- 权重(Weights)的影响
- 相关性反馈的假设
- 伪相关性反馈(Pseudo Relevance Feedback)
- 相关文档的聚集性假设
- 伪相关性反馈(Pseudo Relevance Feedback)
- 间接相关性反馈(Indirect Relevance Feedback)
- 总结
11 查询扩展(Query Expansion)
- 交互式查询扩展
- 自动查询扩展
- 查询扩展的资源
- 基于词库的查询扩展
- 自动词库创建
- 自动生成的词库示例
- 词嵌入用于查询扩展
- 搜索引擎查询扩展(查询日志挖掘)
- 总结
12 Web Crawler 网络爬虫
- 12.1 引言(Introduction)
- 12.2 如何找到信息(How do we find information?)
- 12.3 典型的网络爬虫工作流程(Typical Web Crawler Workflow)
- 12.4 礼貌的爬虫(Polite Crawlers)
- 12.5 机器人排除标准(The Robots Exclusion Standard)
- 12.6 找到信息 - 机器人排除规则(Finding Information - the Robots Exclusion Rules)
- 12.7 一些网站所有者在创建robots.txt文件时的常见错误
- 12.8 礼貌的爬虫:noindex和nofollow
- 12.9 一些Web特定挑战(Some Web-Specific Challenges)
- 12.10 找到信息:挑战(Finding information: challenges)
- 12.11 网络有多大?(How big is the web?)
- 12.12 深网(The Deep Web)
13 对抗性信息检索(Adversarial IR)
- 13.1 搜索引擎优化(SEO)
- 13.2 对抗性IR:元标签(Meta Tags)
- 13.3 对抗性IR:隐藏文本(Hidden Text)
- 13.4 对抗性IR:伪装(Cloaking)
- 13.5 对抗性IR:狡猾的JavaScript(Sneaky JavaScript)
- 13.6 对抗性IR:利用PageRank
- 13.7 对抗性IR:门页(Doorway Pages)
- 13.8 对抗性IR:总结
1 什么是IR information retrieval
1.1 定义相关
简单描述
- efficiency和scalability是关键
- 利用query在网络上找到自己想要的内容
- 就是搜索自己想要的内容,包括查找关键字等
简单定义
Information Retrieval (IR) deals with the representation, storage, organization of, and access to information items.
The representation and organization of the information items should provide the user with easy access to the information in which he is interested.
简而言之就是对于数据的存储和访问
1.1.1 结构相关
-
非结构化
- 自然语言书写的自由格式的文本 free-form text 英语汉语等
- keyword query/concespt query
- 大多数文档是semi-structured,标题、内容
-
结构化
- 更多类似于表格性质,有题头,内容等区别
- 查询时利用表头来把内容都找到
-
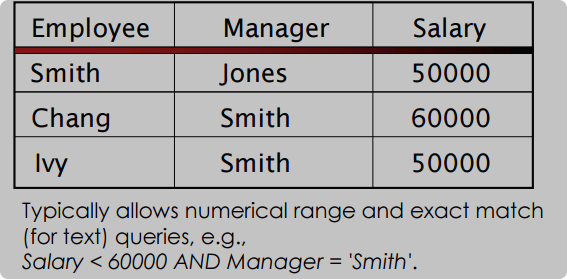
1.1.2 信息项
information item:非结构化形式的内容,比如书籍文档或书写的材料等,在IR系统中,使用document来指代信息项,而且不仅仅包含文字内容,还有音频图片等
在本pdf中所有文档或document的表述都是有关信息项的
representation
为了方便进行query,所以有某种表示方式
利用数学相关内容加速搜索:原始文本太多会非常慢,数学计算很快,以向量、集合、位串等形式来表示文档
1.2 信息需求 information need
1.2.1 4阶段
- the actual, but unexpressed need for information (visceral need): “a vague sort of dissatisfaction … probably inexpressible in linguistic terms”. 本能需求,难以表达
- the conscious within-brain description of the need (conscious need): “an ambiguous and rambling statement”. i.e. “I know what I’m looking for but I don’t know how to say it”. 有意识的需求,知道在找啥但是不好说
- the formal statement of the question (formalised need) 正式需求,换言之就是设定好的搜索的问题,比如北京工业大学都柏林学院的哪个老师好
- the question as presented to the information system (compromised need) 妥协需求,会因为要求查询到的内容的精准性和范围来不断改变
1.2.2 查询query
query是提供给IR系统的对于信息需求的表达,用于解释需要什么样的信息
- Keyword-based query:提供一个关键字或关键字列表,最常见
- Context query:上下文查询,有semantic价值,查询在文档中应该紧挨着出现的单词序列
- Boolean query:布尔查询,和关键字搭配,利用AND OR NOT配合关键字进行查询 e.g. “information AND (retrieval OR extraction) NOT data”.
- natural language query:自然语言查询
补充
上下文查询和关键字查询是信息检索和搜索引擎中的两种不同查询方式,它们的区别主要体现在以下几个方面:
查询依据:
- 上下文查询:依赖于查询的上下文环境,例如用户的搜索历史、个人偏好、地理位置、时间信息等。这种查询方式试图理解用户的查询意图,并据此提供更为准确和个性化的搜索结果。
- 关键字查询:基于用户输入的具体关键词进行搜索,搜索引擎会匹配数据库中的内容与这些关键词,返回最相关的结果。
查询目的:
- 上下文查询:更多地关注于提供与用户当前需求高度相关的信息,它试图理解查询背后的“为什么”,而不仅仅是“是什么”。
- 关键字查询:目的是找到与用户输入的关键词直接相关的信息,它侧重于关键词的匹配度。
查询结果:
- 上下文查询:可能会返回一系列多样化的结果,这些结果是根据用户可能的多种需求综合判断得出的。
- 关键字查询:通常返回与关键词直接相关的结果,这些结果可能不如上下文查询那样个性化。
技术实现:
- 上下文查询:需要更复杂的算法来分析用户的查询上下文,包括自然语言处理、用户行为分析等。
- 关键字查询:实现相对简单,主要是文本匹配和相关性排序算法。
用户交互:
- 上下文查询:可能需要用户在首次查询后进行一系列的交互来进一步明确需求。
- 关键字查询:用户输入关键词后,系统直接返回结果,用户交互通常较少。
在实际应用中,现代的搜索引擎和推荐系统往往结合了上下文查询和关键字查询的优点,以提供更加智能和用户友好的服务。
1.3 IR作用功能
1.3.1 相关定义
IR系统不告知相关内容,而是告诉existence和whereabouts,就是告诉存不存在相关内容,如果存在需要去哪找,就类似搜索引擎搜出来的实际上是一个个的超链接。用户如果想知道具体内容就需要点进去了解
1.3.1.1 具体
- 提供一个list of documents that are relevant with information need
- 不会直接展示具体信息内容
- 大多数的IR会排序list,更相关的在上面
1.3.1.2 补充
- 当今时代有 information overload,信息过载。信息量越来愈大不可能会被完全吸收,所以IR会帮助人找到最需要的内容
1.3.2 相关性 Relevance
如果document的内容非常符合用户需求,那么相关性就很高。然后用户根据超链接读取具体内容。理论上来说这是主观概念,取决于人的判断。query只是对于information need的表达
判断IR好不好就可以从relevance的程度上来决定,但是主体上还是由人判断,而且如果想智能一些的话需要机器学习等
1.3.3 问答相关 Qustion Answering 非IR
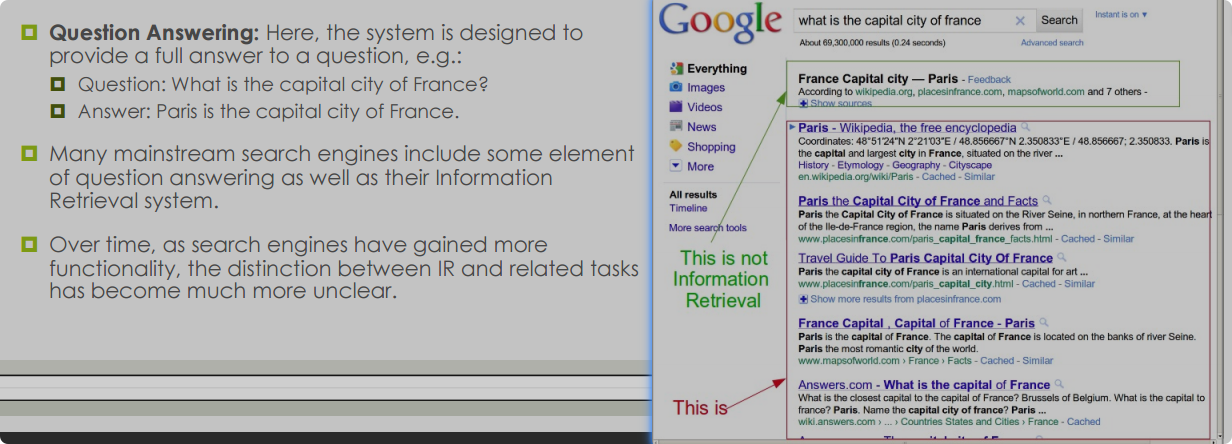
1.3.4 信息提取 information extraction 非IR
通过提供的非结构化文本来创建结构化数据
2 有关查询
比如要查询 a AND b NOT c,此时会先把有关ab的都找到,然后去除c。这样不好,非常慢,而且复数过去式等会影响查询
2.1 矩阵相关
term-document incidence matrix
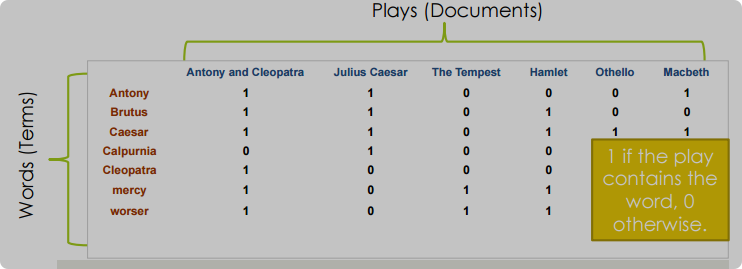
然后可以得到关联向量incidence vector,然后进行与或运算从而找到合适的document,但是对于更大的文本来说非常麻烦,难以扩展,矩阵非常大而且很sparse稀疏
而且会出现ambiguous query模糊查询,因为一个词有多个意思,不知道具体想找啥
2.2 索引 indexing
2.2.1 inverted index
term:术语,就是所需的词
大纲
- 是一种数据结构,每个t都被反映到存在哪些doc中。docID是文档的唯一标识符。每一个列表是按照docID排序的
- 多数情况下索引大小写不敏感,从而可以确保不会错过相关doc
-
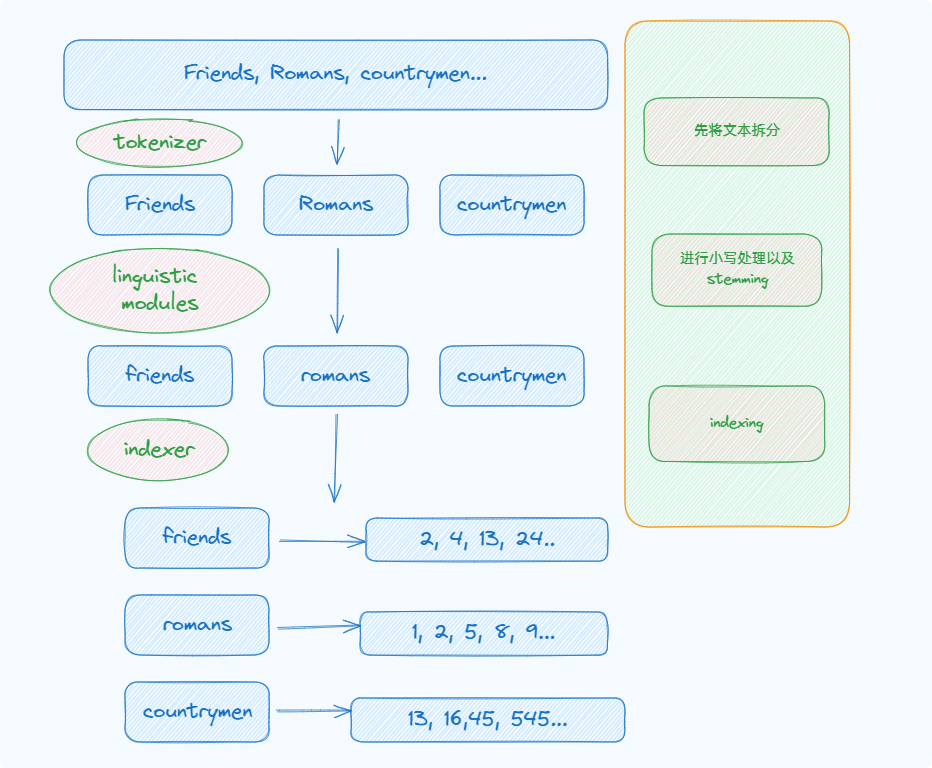
具体
-
先把文档里的terms都拆开,重复的也拆开,然后按照顺序排,一个term对应一个dicID,从上到下应该是以docID为次序
-
按照term按照abcd进行排序
-
进行字典化然后展示相关doc list,同时记住frequency,也就是list的长度
-
排序在倒排索引中非常重要,因为它允许快速查找和比较。字典中的词汇是按字母顺序排列的,这使得查找特定词汇变得高效。同样,倒排列表中的文档也是有序的,这有助于在执行查询时快速定位到包含特定词汇的文档。排序是合并过程中的关键,因为它允许我们通过简单的比较操作来确定哪些文档是两个词汇共同出现的。如果没有排序,我们需要对每个词汇的所有文档进行配对检查,这将大大降低效率。排序将提高效率
-
此时想找a AND b NOT c就可以直接通过ab的list里共同的部分,然后在c去掉c的list的内容,就可以了
-
AND是交集,OR是并集,NOT是包含a自身去掉a and b
-

-
代码相关
# 老师的
def mergeAND(list1, list2):
i, j = 0 , 0
merged = []
while i < len(list1) and j < len(list2):
if list1[i] < list2[j]:
i += 1
elif list1[i] > list2[j]:
j += 1
else:
merged.append(list1[i])
i += 1
j += 1
return merged
def mergeOR(list1, list2):
i, j = 0, 0
merged = []
while i < len(list1) or j < len(list2):
if i < len(list1) and j == len(list2):
merged.append(list1[i])
i += 1
elif j < len(list2) and i == len(list1):
merged.append(list2[j])
j += 1
elif list1[i] < list2[j]:
merged.append(list1[i])
i += 1
elif list2[j] < list1[i]:
merged.append(list2[j])
j += 1
else:
merged.append(list2[j])
i += 1
j += 1
return merged
def mergeNOT(list1,list2):
i, j = 0 , 0
merged = []
while i < len(list1) and j < len(list2):
if list1[i] < list2[j]:
merged.append(list1[i])
i += 1
elif list1[i] > list2[j]:
j += 1
else:
i += 1
j += 1
while i < len(list1):
merged.append( list1[i] )
i += 1
return merged
# 自己的
def mergeAND(list1, list2):
answer = []
i = 0
j = 0
while i < len(list1) and j < len(list2):
if list1[i] == list2[j]:
answer.append(list1[i])
i += 1
j += 1
elif list1[i] < list2[j]:
i += 1
else:
j += 1
return answer
# print(mergeAND(words_map["a"], words_map["aa"]))
def mergeOR(list1, list2):
answer = set()
i = 0
j = 0
while i < len(list1):
answer.add(list1[i])
i += 1
while j < len(list2):
answer.add(list2[j])
j += 1
answer = sorted(list(answer))
# answer = set(list1) | set(list2)
return answer
# print(mergeOR(words_map["a"], words_map["aa"]))
def mergeNOT(list1, list2):
answer = mergeAND(list1, list2)
for num in answer:
list1.remove(num)
# answer = list(set(list1) - set(list2))
return list1
2.3 查询优化
会有一个term列表,每个term屁股后面都跟着一个docID的list,就很像图的邻接表一样。一般来说要是找AND, OR啥的会先从小的list一个个遍历到大的list,是一位一位的向后找
2.3.1 skip pointers
在常规的list里,就和链表结构一样,前一个指向后一个,此时可以通过引用一种skip pointer来跳过一些没必要的节点从而节省时间
Tradeoff
注意权衡的使用,如果跳的多,跳跃跨度小,会让结果更准确,但是会有更多的跳跃次数;如果跳的少,跳跃跨度大,可能会错失一些正确的结果,但是耗时少。所以如何选择合适的跳跃幅度是很重要的
一般采取 L \sqrt{L} L 的作为跳跃间距 L是list的长度
决定跳过指针的位置需要在跳过频率、跳过指针比较的成本以及I/O成本之间找到一个平衡点。在实际应用中,可能需要根据具体的数据集特性、硬件性能和查询模式来调整跳过指针的策略。此外,随着技术的发展,比如固态硬盘(SSD)的普及,I/O成本可能会降低,这可能会影响跳过指针策略的有效性。
2.3.1.1 相关代码
#!/usr/bin/env python3
import math
import timeit
from unittest import skip
# define a class called "SkipList"
class SkipList:
def __init__( self, elements ):
size = len(elements)
self.start = None
self.length = 0
sorted_elements = sorted( elements, reverse=True )
skip_frequency = round( math.sqrt( size ) )
for elem in sorted_elements:
self.start = SkipNode( elem, self.start )
if self.length == 0:
skip_to = self.start
elif self.length % skip_frequency == 0:
self.start.skip = skip_to
skip_to = self.start
self.length += 1
if skip_to != self.start:
self.start.skip = skip_to
# define the nodes that a SkipList will store
class SkipNode:
def __init__( self, elem, next_node ):
self.element = elem # element stored in this node
self.next_node = next_node # reference to the next node in the list
self.skip = None # skip pointer: None if it doesn't have a skip pointer, otherwise it's a reference to another node
def intersect( list1, list2 ):
answer = [] # a list to store the answer (for now: we will return a SkipList at the end)
p1 = list1.start # start the first reference (p1) at the beginning list 1
p2 = list2.start # start the second reference (p2) at the beginning list 2
# haven't reached the end of either list
while p1 is not None and p2 is not None:
# if p1 and p2 point to the equal elements, add it to the answer and move both pointers
if p1.element == p2.element:
answer.append( p1.element )
p1 = p1.next_node
p2 = p2.next_node
# p1's element is smaller, so move p1
elif p1.element < p2.element:
p1 = p1.next_node
# p2's element is smaller, so move p2
else:
p2 = p2.next_node
return SkipList(answer)
def intersect_skip( list1, list2 ):
answer = []
p1 = list1.start
p2 = list2.start
while p1 is not None and p2 is not None:
if p1.element == p2.element:
answer.append( p1.element )
p1 = p1.next_node
p2 = p2.next_node
elif p1.element < p2.element:
if p1.skip is not None and p1.skip.element < p2.element:
p1 = p1.skip
else:
p1 = p1.next_node
else:
if p2.skip is not None and p2.skip.emement < p1.element:
p2 = p2.skip
else:
p2 = p2.next_node
return SkipList(answer)
# good idea to define a function to print the contents of a skip list
# i've included an option to include printing details of where the skip pointers are (if include_skips is True)
def print_skip_list( skiplist, include_skips=False ):
n = skiplist.start
while n is not None:
print( n.element, end=' ' )
if include_skips and n.skip is not None:
print( '(skip to {})'.format( n.skip.element ) )
elif include_skips:
print()
n = n.next_node
print()
# This is the code that will run when you execute this file with Python.
if __name__=='__main__':
list1 = SkipList( range( 0, 100000 ) )
list2 = SkipList( [ 2, 3, 46, 70, 7222, 999999 ] )
# check that the output is ok
print( 'Output for intersect(...)' )
print_skip_list( intersect( list1, list2 ) )
print( 'Output for intersect_skip(...)' )
print_skip_list( intersect_skip( list1, list2 ) )
# measure the time to run the intersect(...) function
time_taken = timeit.timeit( 'intersect( list1, list2 )', number = 10, globals = globals() )
print( 'Execution took {:.4f} seconds'.format( time_taken ) )
print('Execution took {:.4f} seconds'.format( timeit.timeit( 'intersect_skip( list1, list2 )', number = 10, globals=globals() ) ) )
3 预处理 processing
之前的步骤
3.1 引言,开始流程
-
tokenization
- 就是把完整的一段话的各个单词单独提出来,此时提出的每一个单词叫做一个token,但是不一定此时就是我们需要的term
- 提取token的时候会根据不同的情况做出不同的操作,比如Finland‘s,你此时就不知道是保留’s还是去掉‘还是只保留Finland,New York是两个词还是一个,aaa-bb-ccc-dddd是作为整体还是区分开,对于时间数字或者索引来说怎么处理等
- 而且对于不同的语言来说如何区分也是不同的,英语是一种方法,法语是一种,汉语是一种等等。
- 总的来说,分词的决策通常取决于你的应用场景和目标。例如,如果你正在处理一个需要理解语法结构的任务,那么保持单词的完整性可能很重要。而如果你的任务是信息检索,那么可能需要更细粒度的分词。在实际应用中,你可能需要根据具体需求来调整分词策略,以达到最佳的处理效果。
-
normalization
- 使用归一化,确定好一定的规则。比如全改为小写,记住一些特定的词语作为一个整体,去掉符号,比如U.S.A = USA, anti-circle=anticircle
-
thesauri soundex
- 同义词可以作为一种,不同写法的单词也可以作为一种。car=automobile,color=colour。形成等价类
- 当拼写错误的时候可以尝试根据发音来检索到合适的内容
3.2 方法措施,提高效率
stopwords 停词
是一些很常见的词语,比如a the of 等,而且不会影响内容含义等的单词,所以预处理的时候可以直接去掉避免影响
- 删除停词的时候同样需要tradeoff,不一定所有的停词都需要删除,比如to be or not to be,这里面的就不可以删除。解决方法包括先不全部删除,而是先判断意义再考虑删除
- 一般采取 Zipf’s Law
stemming 提取词干
- 一个单词的不同时态,单复数等,其实指的是同一个单词,所以此时需要尽可能还原成一种词干再来提取
- stemming是将这些terms变成common root的过程。stem不一定是真正的单词,而是便于管理的公共根
- 一般来说单词的后缀是不同的,所以stemming也叫suffix stripping 后缀剥离
- 但是一味的利用后缀剥离可能导致 overstemming 过度提取。它指的是在词干提取(stemming)过程中,从一个单词中移除后缀,但这个过程可能会导致不同的单词被错误地转换成相同的词干。这种情况通常发生在单词的后缀被移除后,原本不同的单词变得相同,这可能会影响文本分析的准确性。而且也可能造成homographs,因为一个单词会有多个意思,此时就需要在语境中判断了
相关代码,使用porter提取法
import porter
import time
# 初始化词干提取器
p = porter.PorterStemmer()
start_time = time.process_time()
# 读取停用词列表
with open('stopwords.txt', 'r') as f:
stopwords = set(f.read().split())
# 读取文档集合
documents = []
with open('npl-doc-text.txt', 'r') as f:
for line in f:
if line.strip().isdigit():
doc_id = line.strip()
sentence = []
while True:
line = next(f).strip()
if line.startswith('/'):
break
sentence.extend(line.split())
documents.append((doc_id, sentence))
# 计算每个文档中每个词的频率
def findF(sentence):
f = {}
for word in sentence:
if word not in stopwords:
word = p.stem(word)
f[word] = f.get(word, 0) + 1
return f
# 对每个文档进行词干提取和词频统计
doc_freqs = []
for doc_id, sentence in documents:
f = findF(sentence)
doc_freqs.append((doc_id, f))
# 按要求打印每个文档的词频
for doc_id, f in doc_freqs:
if any(freq > 1 for freq in f.values()):
print(doc_id + ':', end=' ')
for word, freq in sorted(f.items(), key=lambda d: d[1], reverse=True):
if freq > 1:
print(word + ' (' + str(freq) + ')', end=' ')
print()
end_time = time.process_time()
print(f'Total time: {end_time - start_time:.2f} seconds')
lemmatisation 词形还原
- 是一种NLP技术,就是把一个单词转化成字典里的样子,比stemming慢,但是更精准更有效
- 需要判断词性,所以需要更多的文本分析,所以如何处理比stemming更复杂困难

3.3 phrase query 短语查询
biword index 双字索引
将文本中连续的词对作为短语进行索引。abcdefg -> ab,bc,cd,de,ef,fg。但是这样做虽然可能搜到我们提供的查询语句的内容,但是只是盲目的匹配到了目标短语,实际上内容含义不一定符合需求。而且所需内存很大,占用空间
positional index 位置索引
存储某个term被多少doc包含,在每个doc里的位置是多少
一般双字和位置搭档使用
4 向量模型的使用 vector space
4.1 introduction
之前提到的是布尔查询相关,只会看doc有没有包含所需的term,只有相关和不相关,而且没有部分匹配的概念,而且没有根据相关性进行ranking,所以不大好,接下来将介绍向量模型来优化
- 集合中包含一组doc,每个doc有多个term。集合中的term实际上都是唯一的,都是从各doc里提取出来的,对于某个doc来说,自己的term是属于集合的一部分的。如果对于集合中的某个term,当前doc有,那么就是一个值,叫term weight(简单情况下是1),否则就是0。基于对应的向量的值可以得到相似度评分。就是某doc和查询语句的点乘除以模的积 -> sim(q,d)
-

- 注意事项就是全部小写,然后去掉停词后全部拉下来成为集合中的一份子,然后转换成向量,然后计算cosine值即可
- 原理很简单,cos越大说明夹角越小越相似,而cos的值就可以点乘除以模长来得到
4.2 权重 term weighting
TF-IDF
info
TF:是term frequency,术语频率。term在某一个doc出现的次数越多,则越相关
IDF:是逆文档频率。在越多的doc中出现的term越像停词,所以需要IDF来消除出现次数过多的情况
TF-IDF是TF和IDF的乘积,每个doc里的每个term都有这个值,是特定的
TF: 对于每一个doc,其中的每一个term都有自己的TF。同一个doc里出现次数更多的term更重要。是独有的,依赖于term在单个doc出现的频率
IDF: 出现在全部doc中次数更少的term更重要。对于整个集合来说,每个term都有自己的IDF。是公共的,依赖于term在所有doc中的分布情况
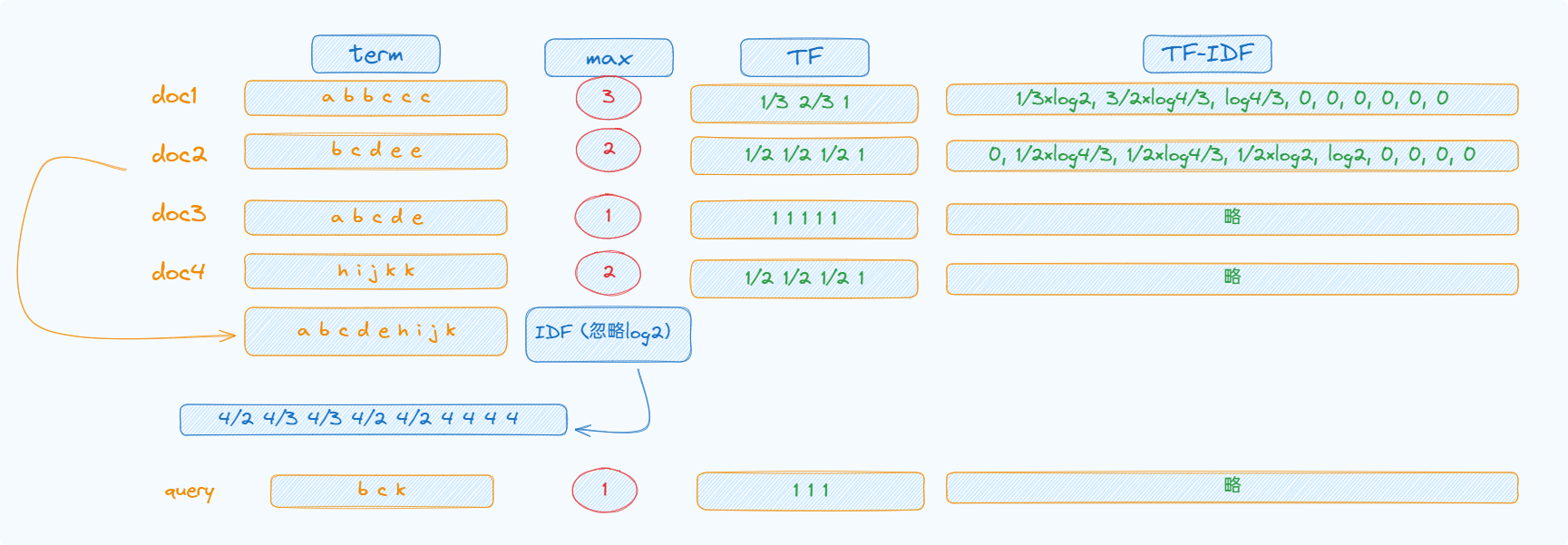
计算方式
t f i , j = f r e q i , j m a x f r e q j tf_{i,j}=\frac{freq_{i,j}}{maxfreq_{j}} tfi,j=maxfreqjfreqi,j
i d f i = l o g 2 ( N n i ) idf_i=log_2\left(\frac{N}{n_i}\right) idfi=log2(niN)
分子是某个term出现的次数,分母是在此doc中所有的频率中最大的那一个
N是doc总数,ni是包含此term的doc的数量
warn
为什么要除以最大频率呢? 是为了确保长文档中的术语不会因为出现次数多而获得不合理的优势。如果只计算词频,那么在长文档中频繁出现的术语可能会比在短文档中偶尔出现的术语具有更高的权重,这可能导致检索结果的不准确性。通过除以最大频率,我们可以使词频在不同的文档之间达到一个平衡点,从而更准确地反映每个术语的重要性。最大频率是某个文档去除所有停词后的拥有最大相同词的数量 a a a b b c的就是3
如何计算还是类似上面的vector的做法,但是把01的值换成TF×IDF即可
4.3 优点和缺点
TF-IDF会让某doc中出现次数更多的term产生更大的影响;同时减少整体集合中出现次数过多的term的影响
- 加权方案可以提高检索性能;部分匹配会得到实现;cos会提供排序
- term相对独立,损害性能
4.4 步骤

import math
import time
# 导入porter词干提取模块
import lab4.porter as porter
# 创建Porter词干提取器
p = porter.PorterStemmer()
start_time = time.process_time()
# 读取并设置停用词
with open('../lab4/stopwords.txt', 'r') as f:
stopwords = set(f.read().split())
# 初始化文档
docs = {
'd1': ['Shipment', 'of', 'gold', 'damaged', 'in', 'a', 'fire'],
'd2': ['Delivery', 'of', 'silver', 'arrived', 'in', 'a', 'silver', 'truck'],
'd3': ['Shipment', 'of', 'gold', 'arrived', 'in', 'a', 'large', 'truck']
}
# 查询向量
query = ['gold', 'silver', 'truck']
# 读取文档集合
documents = {} # 初始化一个空列表,用来存储文档数据
with open('../lab4/npl-doc-text.txt', 'r') as f:
for line in f: # 遍历文件中的每行
if line.strip().isdigit(): # 如果行内容去除空格后全部由数字组成
doc_id = line.strip() # 将该行内容设置为当前文档的ID,去除首尾空格
sentence = [] # 初始化一个空列表,用来存储当前文档的句子
while True: # 使用一个无限循环来读取文档内容,直到遇到特定的结束标记
line = next(f).strip() # 读取下一行并去除首尾空格
if line.startswith('/'): # 如果行内容以'/'开头
break # 则结束当前文档内容的读取
sentence.extend(line.split()) # 否则,将行内容按空格分割成单词列表,并添加到当前文档的句子列表中
documents[doc_id] = sentence # 将当前文档的ID和句子列表存储到文档数据中
# 总文档数
total_docs = len(documents)
# 存的是所有词和对应词干的键值对
stem_cache = {}
# 存的是所有的词干
tf_max = {}
# 存的是每个词在文档中出现的次数
idf_count = {}
# 存的是每个文档各自的词频
doc_freqs = {}
# 每个单词对应的idf
idfs_term = {}
# 计算每个文档中每个词的tf-idf
tfidf_docs = {}
# 查询语句的词频和tf-idf
query_freqs = {}
query_tfidf = {}
# 结果
result = {}
# 计算每个文档中每个词的频率
# 同时把每个文档里能影响到的词干和idf也表示出来了
def process_document(did, sentence):
tf_max[did] = 0 # 当前文档的最大词频
term_freq = {} # 当前文档对应的词和词频
had_terms = set() # 确保同一个文档多次出现的词只计算一次
for word in sentence: # 遍历文档中的每个词
word = word.lower() # 转换为小写
if word not in stopwords: # 如果不是停词的话
stemmed = stem_cache.get(word) # 从缓存中获取词干
if not stemmed: # 如果没有提取到,那么就相当于直接提取然后存到缓存
stemmed = p.stem(word)
stem_cache[word] = stemmed
if stemmed: # 如果提取到了词干
term_freq[stemmed] = term_freq.get(stemmed, 0) + 1 # 词频要加一
tf_max[did] = max(tf_max[did], term_freq[stemmed])
if stemmed not in had_terms: # 如果没出现重复的话
idf_count[stemmed] = idf_count.get(stemmed, 0) + 1
had_terms.add(stemmed)
return term_freq
def cos_result(v1, v2):
common = set(v1.keys()) & set(v2.keys())
sum = 0
sum1 = 0
sum2 = 0
for x in common:
sum += v1[x] * v2[x]
for y in v1.values():
sum1 += y * y
for z in v2.values():
sum2 += z * z
sum3 = math.sqrt(sum1) * math.sqrt(sum2)
return sum / sum3
# 存的是每个文档各自的词频
for doc_id, text in documents.items():
doc_freqs[doc_id] = process_document(doc_id, text)
for term, df in idf_count.items():
idfs_term[term] = math.log2(total_docs / df)
for doc_id, freqs in doc_freqs.items():
tfidf_docs[doc_id] = {}
for term, freq in freqs.items():
tfidf_docs[doc_id][term] = freq / tf_max[doc_id] * idfs_term[term]
# print(idf_count)
query_freqs = process_document('query', query)
for term, freq in query_freqs.items():
query_tfidf[term] = (freq / tf_max['query']) * idfs_term.get(term, 0)
for doc_id in doc_freqs:
result[doc_id] = cos_result(tfidf_docs[doc_id], query_tfidf)
sorted_result = sorted(result.items(), key=lambda x: x[1], reverse=True)
# 获取前十个结果
top_ten_results = sorted_result[:10]
# 打印前十个结果
print(top_ten_results)
end_time = time.process_time()
print(f'Total time: {end_time - start_time:.2f} seconds')
# print(stem_cache)
# print(doc_freqs)
# print(total_docs)
# print(idfs_term)
# print(tf_max)
# print(tfidf_docs)
# print(query_freqs)
# print(query_tfidf)
# print(sorted_result)
5 BM25 模型
BM
和TF-IDF流程很像,只不过一些计算上有区别。相对于TF-IDF表现更好。简称为best match。
其中的IDF和TF很类似,但是多了一个doc长度规范化,这个保证较长的doc在查询的时候不会获得不公平的优势
5.1 TF
在BM25模型中,如果一个词在文档中出现的频率很高,那么它的评分提升会逐渐饱和,也就是说,这个词的频繁出现不会带来评分上的显著优势。在评估文档与查询的相关性时,一个词在文档中出现的次数确实很重要,因为它表示了该词与文档内容的关联程度。然而,如果一个词在文档中过于常见,那么它可能是一个常用词或停用词,对区分文档内容的作用不大。因此,BM25通过调整TF的计算方式,使得高频词的评分提升逐渐饱和,从而更准确地评估文档与查询的相关性。
- 就是和普通的模型相比,从
t
f
i
,
j
=
f
r
e
q
i
,
j
m
a
x
f
r
e
q
j
tf_{i,j}=\frac{freq_{i,j}}{maxfreq_{j}}
tfi,j=maxfreqjfreqi,j变成了
t
f
i
,
j
=
f
r
e
q
i
,
j
m
a
x
f
r
e
q
j
+
k
tf_{i,j}=\frac{freq_{i,j}}{maxfreq_{j} + k}
tfi,j=maxfreqj+kfreqi,j。分母多了一个常数k,k可以保证最高词频的词的TF会趋于饱和而不是达到1
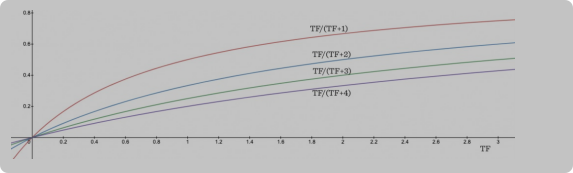
- 如果一个文档里对于某个查询匹配的内容越多,就越相关。比如有俩文档,k设1,一个是aaaaa,一个是aab,搜索的是ab,那么第一个的TF就是5/6,第二个是2/3 + 1/2,
就算你第一个文档包含查询的某部分超级多,那也不如其他的文档只包含一次更多部分的查询的评分高。奖励完全匹配 - BM25评分函数会优先选择完全匹配查询的文档,而不是只部分匹配查询但查询词频相同的文档。这意味着,如果一个文档包含了查询中的所有词,即使这些词的出现频率不如另一个文档高,BM25也会认为这个文档更相关。完全匹配查询中所有词的文档更可能比只包含部分查询词的文档更相关。因此,BM25通过这种方式来调整搜索结果的相关性排序,使得更符合用户查询意图的文档得到更高的排名。
- 如果有一系列的doc,BM25会得出每个doc的长度从而算出平均长度,对于长度更长的doc来说会增加k的大小,长度的小的减小,但k>=1恒成立
- 但是不一定会根据长度来修改k的值,BM25系统同时有个b参数,b取值0-1,b越大则调整k的幅度越大,如果为0就不调整,k是一样的
5.2 IDF
- 由
l
o
g
2
(
N
n
i
)
log_2\left(\frac{N}{n_{i}}\right)
log2(niN)变成了
l
o
g
2
(
N
−
n
i
+
0.5
n
i
+
0.5
)
log_2\left(\frac{N-n_{i}+0.5}{n_{i}+0.5}\right)
log2(ni+0.5N−ni+0.5)
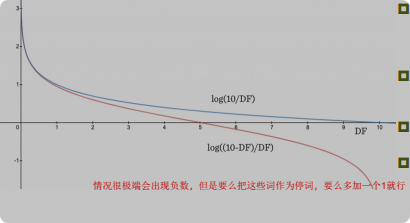
- 可以保证对于出现次数很多的term,其IDF会下降非常快甚至小于0,但是我们又不希望得到负权重,所以要么是把出现次数过多的词作为新的停词去掉,要么分子分母同时加上0.5保证不小于0
5.3 综合结果
s i m B M 25 ( d j , q ) ∼ ∑ k i ∈ d j ∧ k i ∈ q f i , j × ( 1 + k ) f i , j + k ( ( 1 − b ) + b × l e n ( d j ) a v g _ d o c l e n ) × l o g 2 ( N − n i + 0.5 n i + 0.5 ) sim_{BM25}(d_{j},q)\sim\sum_{k_{i}\in d_{j}\wedge k_{i}\in q}\frac{f_{i,j}\times(1+k)}{f_{i,j}+k\left((1-b)+\frac{b\times len(d_{j})}{avg\_doclen}\right)}\times log_2\left(\frac{N-n_{i}+0.5}{n_{i}+0.5}\right) simBM25(dj,q)∼ki∈dj∧ki∈q∑fi,j+k((1−b)+avg_doclenb×len(dj))fi,j×(1+k)×log2(ni+0.5N−ni+0.5)
k一般取1,b取0.75
5.4 俩变种
- BM25F:让doc不同位置有不同权重,比如标题,底部,正文的都不一样
- BM25+:不会让过短的文章得分过高
6 Evaluation 评估
6.1 引言
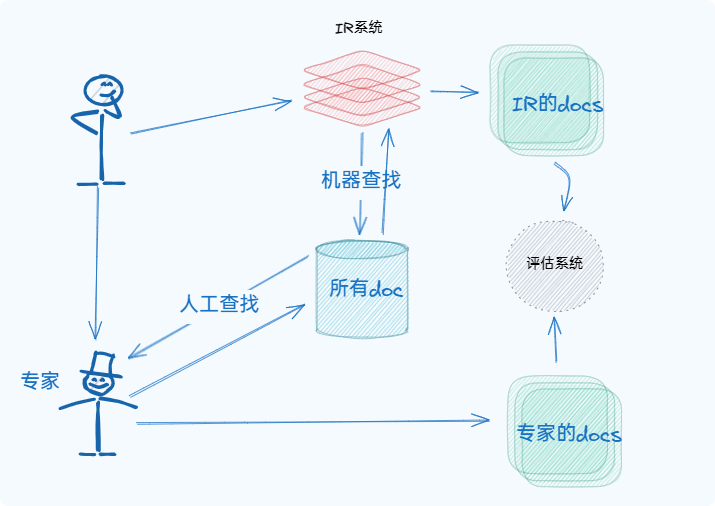
Cranfield Paradigm
relevant docs是相关的文档,但是相不相关由主观决定,所以需要专家来判断系统的有效性,从而产生了standard text collections:标准语料库,标准查询,相关性判断
小概念
- C:所有的docs. collection/corpus
- Rel:相关的docs,由专家提供.relevant sets
- Ret:检索出来的docs,IR提供. answer set/retrieved set
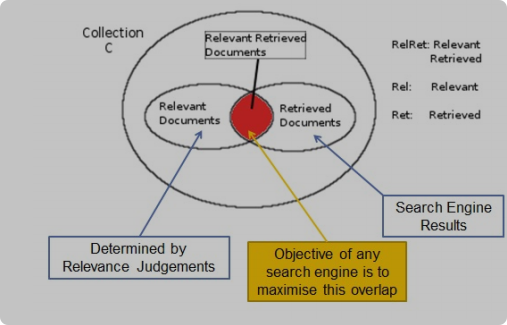
一般来说Ret的结果是ranked后的结果
例子

6.2 Precision/Recall 精确度和召回率
这是最基本最广泛的评估指标,是许多其他指标的基础
P = R e l R e t R e t P=\frac{RelRet}{{Ret}} P=RetRelRet, 就是交集除以IR的结果
R = R e l R e t R e l R=\frac{RelRet}{{Rel}} R=RelRelRet, 是交集除以专家的结果对照上面的结果就是 P = 5/15,R = 5/10
The two metrics of precision and recall are often inversely related: as one
increases the other decreases.Precision will be high whenever a system is good at avoiding non-relevant documents.
- A system can achieve very high precision by retrieving very few documents.
Recall will be high whenever a system finds many relevant documents.
- A system can achieve 100% recall simply by retrieving all the documents in the collection.
保证精度更重要目前,对于IR来说
虽然基础精确度是一个不考虑排名的指标,但大多数信息检索系统实际上返回的是排序后的列表,而不是无序的文档集合。因此,用户更有可能首先查看列表的顶部,这意味着排名靠前的结果的精确度尤为重要。
6.3 Single value metric 单值度量 基于RelRet
P@n
简单来说就是对于前n个结果的精度的值,就是在前n个中,有多少是相关的。
对照上面的结果就是 P@1=1, P@3=2/3, P@10=4/10, P@15=5/15
性能受到Rel的值的影响更大,因为Rel越大,找出来的结果越多,查到的机会越大
R-precision
R-precision 是一个相对于查询相关文档集合大小的指标,它考虑了所有相关文档。
P@n 是一个固定的指标,它只考虑前 n 个文档,而不考虑查询相关文档集合的大小
R-precision 更能反映检索系统在整个相关文档集合上的性能,而 P@n 则更关注检索系统在最前面的几个结果上的性能
R-precision的结果和P@n挂钩,因为此时Rel一共有10个,所以R-precision=P@10, 如果有13个那就=P@13
MAP
是IR最常用的指标,Mean Average Precision 最小平均精度指标。对于list中前部的doc会有所奖励,增加对应的某种权重,对于排名靠后的doc的权重设计的较低
先计算AP,结果是所有相关的P的值之和/Rel的数量
MAP就是在多次查询后的各AP的平均结果

6.4 bpref
binary preference
由于资源限制和评估方法的局限性,我们通常只能对检索结果的一部分进行人工相关性判断,而不是对所有可能相关的文档进行判断。这种不完整的判断可能导致一些实际上相关的文档被遗漏。
上面的数据是基于完整的相关性判断的,但是对于更大的collection,完整的判断会越来越困难越来越不常见,会出现不完整的判断,这意味着存在一些doc是没有被判断相关性的,所以需要一种新方法来计算精度
作用体现在如果存在大量的未被判断相关性的doc,会有更稳定和精确的结果
由于上图里面的所有内容都是基于全部Rel都有所判断,但是要是有一个没有被判断,那么AP的结果会有改变。解决方法是忽略掉没有被判断的doc,只看被成功判断的doc。

如果要加强判断,可以采取bpref10,就是分母变成10+R,R不变
6.5 NDCG
Normalised Discounted Cumulated Gain
归一化贴现累计增益由bpref可以知道doc可以被判断为rel和non-rel,但是rel也分为相关程度,NDCG的作用就是来分级的
rel-doc在list的前方;越rel的越靠前
和上面P@n那几个有类似的做法,只不过Rel里面的内容会有一个rank值表示相关程度
-
有一个G列表表示收益,各位置对应的值就是rank值
-
有一个CG列表表示累计收益,各位置对应的值就是自己的rank加上上一层的CG值。 C G [ i ] = { G [ 1 ] , i = 1 ; G [ i ] + C G [ i − 1 ] , i > 1 CG[i]=\begin{cases}G[1],&i=1;\\G[i]+CG[i-1],&i>1\end{cases} CG[i]={G[1],G[i]+CG[i−1],i=1;i>1但是有一个弊端,就是CG越累积肯定是越大的,所以越往后越大,但是后面那些相关性不大的因此收获更大的rank,不大好,所以要加一个新list DCG discounted cg
-
DCG的值就是改进后的,第一层的值是本身,以后的值都是自己的值除以log2i加上上一层的DCG。 D C G [ i ] = { G [ 1 ] , i = 1 ; G [ i ] l o g 2 i + D C G [ i − 1 ] , i > 1 DCG[i]=\begin{cases}G[1], & i=1;\\ {\frac{G[i]}{log_2i}}+DCG[i-1], & i>1\end{cases} DCG[i]={G[1],log2iG[i]+DCG[i−1],i=1;i>1
- 考虑了两个因素:相关性(relevance)和排名(position)。DCG 越高,说明系统返回的结果越符合用户的需求。然而,DCG 的值依赖于查询和文档的数量,因此很难在不同查询之间进行比较。
- 相关doc越多,收益越大,越早期的doc贡献越大
- 但是不好比较,最好变成0-1的结果,所以NDCG应运而生
- 但是变成NDCG前,有一个新指标IDCG即理想DCG
-
IDCG的值应该是根据Rel的rank从大到小往后排列,如果Rel的长度小于Ret的话,后面的就补0

6.6 结果

用于IR评估的collection包括:docs,标准query,标准query的相关性判断
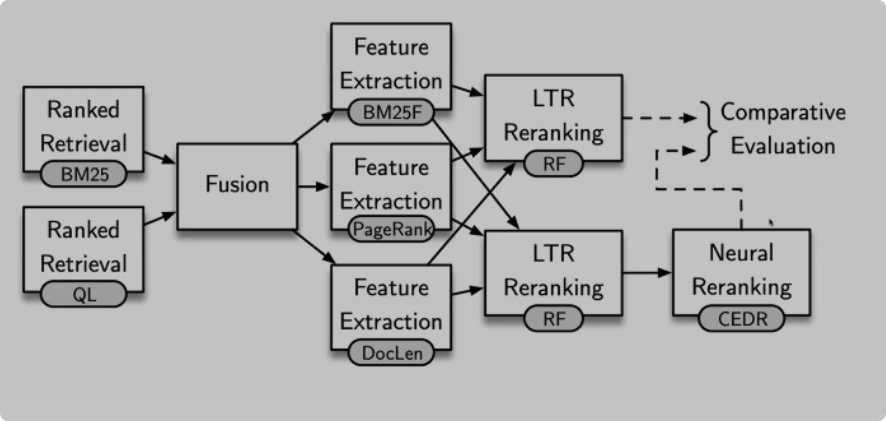
7 IR pipelines和现代IR

一系列问题:
-
一词多义,如何解决
-
多次同义,如何找出我们需要的所有的内容
-
是否可以使用多个modal帮助我们建立良好的IR系统
-
如何保证IR的运行速度。很小的模型可以采用AI或大语言模型帮助我们,中等的可采用BM25,再大型的就只能boolean query了,因为最快…
-
经典信息检索管道:涵盖预处理、建立索引、排序等步骤。这种管道存在词汇不匹配、歧义、同义等问题。
-
经典管道的问题:仅考虑文档内容,没有利用网络链接结构、URL等信息。同时,也没有利用机器学习和深度学习等最新进展。
-
更复杂的IR管道:包括伪相关反馈、查询扩展、融合、学习排序等步骤,用于提高检索效果。
-
特征学习排序:介绍了一些特征,如文本特征、PageRank、URL深度等,用于学习排序模型。
-
神经网络语言模型:提及了BERT等模型,并介绍了其优势。然而,大语言模型的速度较慢。
-
ChatGPT等大语言模型:用于生成式回答,但存在缺乏知识、无法引用来源等问题,不太适合直接用于信息检索。
-
结论:经典IR管道存在局限,现代IR利用了更多技术来提高检索质量,但响应时间也是一个重要考量。
-
经典IR流程:接着,文档介绍了传统IR系统的基本流程,包括文档预处理(如分词、语言处理)、索引创建、查询处理和排名方法(例如BM25算法)。这个流程是一个线性的管道模型,每个阶段的输出成为下一个阶段的输入。
-
经典IR流程的问题:文档指出了传统IR流程存在的问题,如词汇不匹配、多义性和同义词问题。此外,还提出了对检索模型选择的疑问,是否应该使用单一模型还是多种模型的组合。
-
现代IR的挑战:讲义进一步讨论了传统IR流程未能充分利用现代技术,如机器学习、自然语言处理(NLP)和自然语言理解(NLU)的问题。特别提到了大型语言模型(LLMs)如BERT、T5和GPT-4在NLP、NLU和机器翻译任务中的巨大进步,但也指出了这些模型速度慢的问题。
-
更复杂的IR流程:为了解决上述问题,文档提出了一个更复杂的IR流程,包括伪相关反馈、查询扩展、融合和学习排名等技术。这些技术旨在通过不同的方法改进检索结果,提高相关文档的匹配概率。
-
PageRank和文档重要性:文档还介绍了PageRank算法,这是一种根据网页链接结构来衡量文档重要性的方法,由Google的创始人开发。如果一个内容越重要,那么会有更多的其他连接链接到此内容的链接,会让此内容被更多知道
-
学习排名:学习排名是一种利用机器学习技术对初步检索结果进行重排的方法,目标是将最相关的文档放在排名列表的顶部。这一过程会考虑比初始排名分数更多的信息,如文本特征、非文本特征、查询清晰度等。
-
神经语言模型:文档提到了基于Transformer的神经语言模型,如BERT,以及由OpenAI发布的ChatGPT。这些模型通过学习大量文本中词语和短语之间的模式和关系来进行文档理解。
-
ChatGPT的问题:尽管ChatGPT等大型语言模型在NLP任务中取得了巨大成功,但在信息检索领域,它们还存在一些问题,如不能提供确切的知识来源,输出可能是错误的,并且不能引用其信息来源。
-
结论:最后,讲义总结了传统IR流程在现代IR方面的局限性,并指出了提高检索质量的多种技术,但响应时间是关键,因为涉及的数据量巨大。
伪反馈: query drift是指在使用伪相关反馈(Pseudo-Relevance Feedback)时可能出现的问题。伪相关反馈是一种技术,它假设排名靠前的文档是相关的,并据此调整检索算法的权重,以期望找到更多与用户认为相关的文档相似的文档。然而,如果这个过程没有得到适当的控制,可能会导致查询的主题逐渐偏离用户最初的意图,从而使得检索结果与用户的实际需求不再匹配。Query drift(查询漂移)是一个信息检索领域的概念,它描述了在进行多次检索或者在检索过程中不断调整查询时,查询的语义和方向可能发生偏离的现象。这种偏离可能会导致检索结果不再与用户最初的信息需求紧密相关。例如,如果用户最初查询的是关于“苹果”(水果)的信息,但是系统根据伪相关反馈主要返回了关于“苹果公司”的信息,那么随着时间的推移和多次迭代,查询可能会逐渐漂移,最终主要返回与苹果公司相关的信息,而不是关于水果的信息。这就是query drift的一个例子。为了避免query drift,信息检索系统需要采用一些策略来确保查询的稳定性和准确性,例如限制迭代次数、引入用户反馈机制、使用更复杂的查询理解技术等。这样可以确保检索结果始终与用户的实际需求保持一致。
查询扩展:
查询扩展(Query Expansion)是信息检索(IR)中的一种技术,旨在通过增加与原始查询词相关的其他术语来提高检索系统的性能。这种方法的目的是扩大检索范围,以便更全面地覆盖用户的信息需求,并提高检索到相关文档的概率。
在文档中提到的查询扩展方法有以下几种:
-
使用手动构建的词典:例如WordNet,它是一个大型的英语词典数据库,可以用来找到与原始查询词同义或相关的术语。通过这种方式,查询可以被扩展为包含更多可能与用户需求相关的词汇。
-
自动生成的词典:通过从外部语料库(如网络爬取的数据或维基百科)中提取数据来构建词典。这种方法可以捕捉到更广泛和更新的词汇使用情况。
-
词嵌入:利用词嵌入技术(如word2vec、GloVe、ELMo和基于BERT的嵌入)将词语表示为向量。这些向量能够捕捉词语之间的语义关系,从而帮助找到与查询词在语义上相近的其他词汇。
-
查询日志挖掘:搜索引擎可以通过分析之前用户对于相同查询词的使用行为来挖掘相关术语。这种方法基于用户实际的搜索行为,可能更贴近用户的真实需求。
-
目标语料库基础的技术:基于正在搜索的文档集合,这类技术可以分为两类:
- 基于分布的方法:比较伪相关文档中术语的分布(频率)与整个语料库的分布。
- 基于关联的方法:根据术语与查询词的共现关系来选择相关术语。
查询扩展的好处在于能够提高检索系统的查全率(recall),即使用更广泛的词汇覆盖来捕获更多可能相关的文档。然而,这也可能导致查准率(precision)的下降,因为扩展的查询可能会检索到一些不相关的文档。因此,查询扩展需要谨慎使用,以确保在提高查全率的同时,不会过多地牺牲查准率。
Fusion:
- 由排名检索系统计算的分数:不同系统可能会为相同的文档分配不同的分数,融合时可以考虑这些分数的加权和。
- 文档在每个结果列表中的排名:除了分数,文档在不同系统中的排名位置也可以作为融合的依据。
- 基于过去表现的文档相关性概率:如果有历史数据表明某些文档类型或来源的文档更可能是相关的,这些信息也可以用于调整融合策略
- 由多个IR输入,但是只输出一个
8 Fusion
8.1 introduction
data fusion,collection fusion results aggregatio越来越流行
combining the outputs of multiple 不同的IR系统或算法,把他们的结果合并成一个排序结果集,在响应式查询的时候显示给用户。大家希望这种组合出来的结果集比单个结果集的质量更好,higher precision higher recall…
过程大概是用户输入查询,fusion引擎利用多个IR系统进行查询,然后再对结果进行整合输出
返回的结果列表是根据每个doc的分数排序的,和内容无关,得分是根据每个IR自己的逻辑来得到的。算法之间的主要区别在于它们在分配分数时考虑了哪些信息。
- Metasearch:由自主的完整的搜索引擎返回的结果集的融合
- Distributed IR:多个小IR设计成co-operate的,每个IR处理collection的不同子集
- Internal Metasearch:许多算法对同一个collection进行搜索
8.2 overlap 语料重叠
开发fusion算法的时候要考虑到doc集合(corpora)有多少重叠,重叠的程度会让处理最终结果的时候有所影响。有三种类型
-
disjoint database 不相交的数据库。搜索的内容是独立的doc集合,互相之间没有共同文档。同一个doc不会被多个不同的IR返回。分布式IR采用这个实现。此形态的语料库被称作Collection Fusion
-
identical database 相同数据库。每个IR接收到的查询集合都是同一组doc,所以结果doc会出现在多个结果集里,同时出现在结果集里的doc会更被认为具有相关性Rel。Internal Metasearch更常用这个。这是重点方法,也被乘坐Data Fusion
-
overlapping database 重叠数据库。这个是每个IR使用的doc集合有一定程度上的重叠,doc同样会出现在多个结果集中,但是重复出现的doc不一定是高度相关的。External Metasearch更多的涉及到这种。
- 此算法的特点是对于出现在多个结果集中的doc会给出更高的分数。都没出现的doc会被认为是0,每个结果集出现的doc会被认为都相关,在一部分结果集出现,在另一部分没出现不好判断
8.2.1 三种效应
-
Skimming effect
- 一般来说最相关的doc会出现在结果集的顶部附近,但是skimming认为在每个结果集中skim最重要的doc,然后fusion他们会有更好的表现。被多种fusion算法所使用。就是只用最顶部的一部分doc
-
Chorus effect
- 如果多个IR都认为一个doc是相关的,那么chorus认为此doc在最终结果集中应该更靠前,但是适用程度取决于语料库的overlap程度。这是一个需要被考虑的重要因素,但是对于disjoint database来说就没有考虑性了
-
-
Dark Horse 黑马effect
- 某个结果集和其他结果集的内容相差太大,从而失去可用性
8.2.2 三种融合技术
- Rank-Based fusion:只检查每个doc在其结果集中占据的排名和位置
- Score-Based fusion:根据IR给出的相关性分数来作为其相关性信心的度量
- Segment-Based fusion:将结果集划分为文档组,而不是使用个别的排名或分数
8.3 Rank-Baesd 基于排名的融合技术
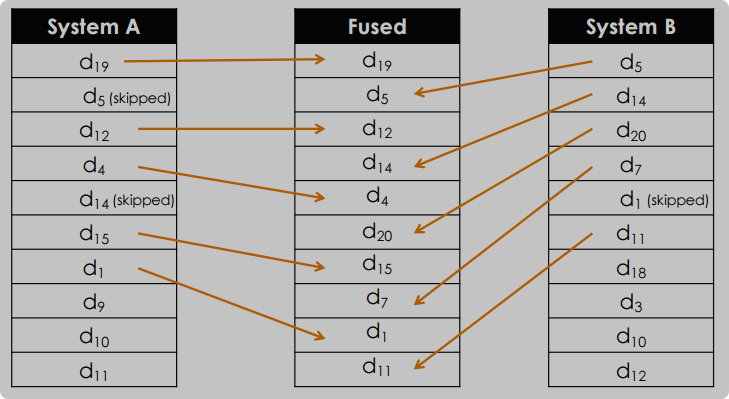
8.3.1 interleaving 交错法
采取round robin的方法从每个input set的顶部取出一个doc,然后把他加到fusion的结果集中,选择的文档是尚未包含在fusion结果集中的排名最高的doc,但是效率比较低,因为它假设每个不同的结果集的质量是相等的,但是好的结果集的结果可能会被削弱
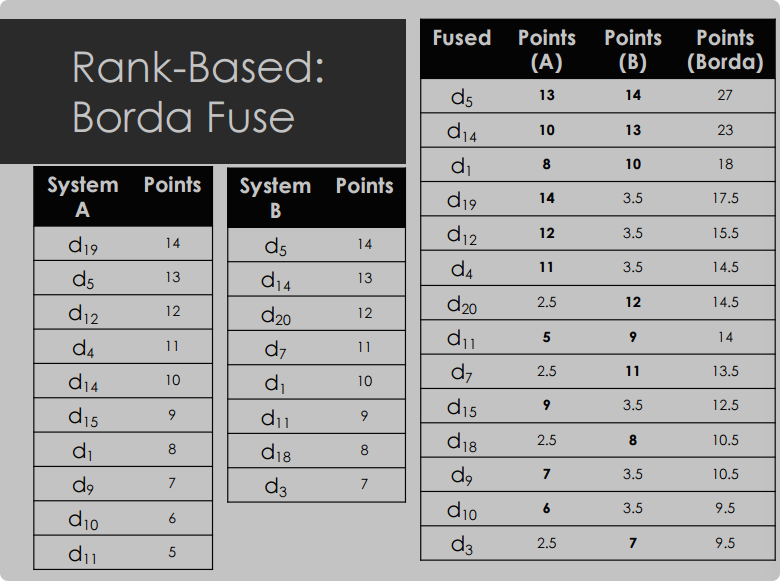
8.3.2 Borda-Fuse
-
Borda-Fuse是基于一个选举系统,当少数投票者(输入系统)为许多候选人(文档)投票时使用。
-
每个投票者按偏好顺序对一组候选人进行排名。
-
对于每个投票者,排名第一的候选人获得c点,排名第二的获得c-1点,以此类推。
-
如果候选人没有被投票者排名,投票者的剩余点数将平均分配给未排名的候选人。
-

8.3.3 Reciprocal Rank Fusion 倒数排名融合
- 倒数排名融合是一种简单的基于排名的方法,在实践中已被证明是有效的。
- 对于要排名的文档集D和结果集R,每个文档的得分计算如下: R R F s c o r e ( d ∈ D ) = ∑ r ∈ R 1 k + r ( d ) RRFscore(d\in D)=\sum_{r\in R}\frac{1}{k+r(d)} RRFscore(d∈D)=∑r∈Rk+r(d)1
- 其中r(d)是文档d在结果集r中的排名,k是一个通过实验设定的常数(在这里是60)。
8.3.4 其他
- 交错法的一个变体是使用历史数据来估计哪个输入系统倾向于表现得更好。
- 然后使用加权的交错法,以便从更好的系统中获取更多的文档。
- 同样基于选举的方法是Condorcet-Fuse算法,这是Borda-Fuse算法的另一种选举基础方法。
- 还提出了Borda-Fuse的加权版本,其中每个输入系统的点数乘以某个权重。
8.4 Score-Based
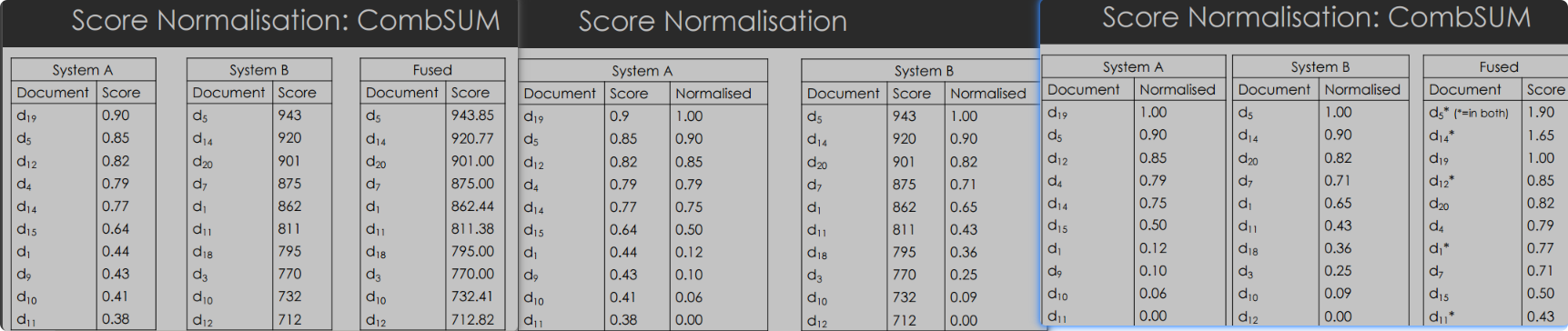
CombSUM 方法
- 定义: CombSUM 是一种流行的分数融合算法,它使用输入的IR系统为每个文档分配的相关性分数。
- 计算方法: 在融合后的结果集中,文档的最终分数是通过将每个输入结果集中给予它的个别分数相加得出的。
- 效果: 高分数的文档会被带入融合后的结果集,利用了“浏览效应”(Skimming Effect)。同时,因为分数是相加的,出现在多个结果集中的文档也会获得提升,利用了“合唱效应”(Chorus Effect)。
-

分数标准化(Score Normalisation)
- 必要性: 不同的IR系统可能会在不同的分数范围内计算分数,因此直接相加原始分数会有问题。
- 解决方法: 通过分数标准化,使每个文档的分数处于可比较的范围内。
- 标准标准化: 最常见的方法是通过下列公式进行标准化:
n o r m a l i s e d _ s c o r e = u n n o r m a l i s e d _ s c o r e − m i n _ s c o r e m a x _ s c o r e − m i n _ s c o r e normalised\_score=\frac{unnormalised\_score-min\_score}{max\_score-min\_score} normalised_score=max_score−min_scoreunnormalised_score−min_score - 应用: 在每个文档的分数被标准化后,可以应用CombSUM算法。每个结果集中排名第一的文档的标准化得分为1,排名最低的文档的标准化得分为0。
-
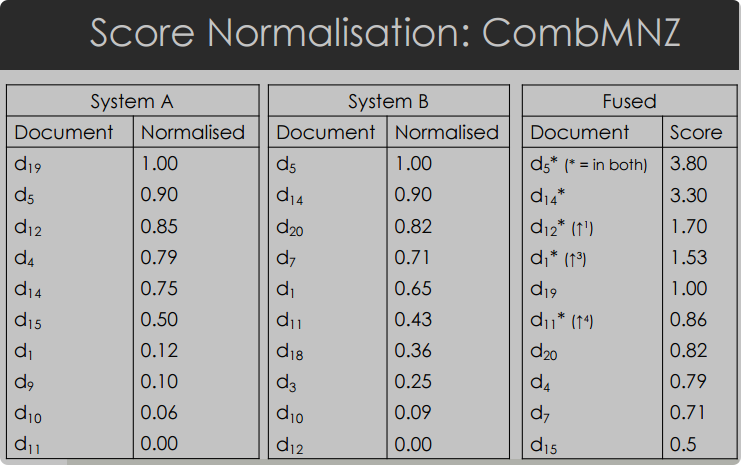
CombMNZ 方法
- 定义: CombMNZ 是 CombSUM 的一种变体,通过乘以非零分数的数量来进一步强调合唱效应。
- 计算方法: 将每个文档的CombSUM分数乘以它所包含的结果集数量(即给它非零分数的输入系统数量)。和CombSUM几乎一个样
- 效果: CombMNZ 非常简单且在实践中被证明相当有效,因此它通常是研究人员比较新算法时的基准技术。
-

- 归一化的时候是对应的doc在多个sys里的值相加再乘存在这个doc的sys的数量,比如下面的A,B,d19不存在于B,所以值就是(1+0)×1,d11虽然在A中是0,但是结果是(0+0.43)×2
-
线性组合(Linear Combination)
-
定义: 线性组合模型通过为每个输入系统应用权重来解决CombMNZ和CombSUM假设每个输入结果集质量相同的问题。
-
计算方法: 类似于CombSUM,但每个文档的标准化分数乘以与其返回的输入系统的权重,然后将它们相加。
-

-
权重计算: 有多种方法计算权重,文档中提到了两种:
- CORI算法: 依赖于对每个输入系统使用的文档集合的详细信息的访问。通常用于分布式IR,基于DF和ICF。Document Frequency: number of documents in the
document collection that contains a term. Inverse Collection Freqency: based on the number of collections that contain the term - LMS: 使用结果长度来计算合并分数,实践中效果出人意料地好
- CORI算法: 依赖于对每个输入系统使用的文档集合的详细信息的访问。通常用于分布式IR,基于DF和ICF。Document Frequency: number of documents in the
8.5 Probability-Based Fusion
ProbFuse 方法
-
动机: 使用单一权重来反映每个系统的整体平均性能可能无法捕捉到我们可能想要利用的某些特征,如系统的精确度和召回率。单一权重只能反映整体性能的优越性,而不能反映具体某个特征值的优劣。
- 例如,一个系统可能只在结果的开始部分返回少量相关文档,导致精确度和召回率都不理想。
- 另一个系统可能具有较好的召回率,但在将相关文档排在前面方面表现不佳。
-
设计: ProbFuse 旨在考虑这些信息,在训练过程中通过分析历史数据来构建一系列权重,这些权重取决于文档在结果集中出现的位置。
-
每个输入内容会被分为x个大小相等的segment,最终用于对文档进行排名的分数是基于文档相关的概率,假设它是由特定输入系统在特定段中返回的。
-
训练阶段: 基于具有相关性判断的历史查询来估计每个输入系统的权重。
-
融合阶段: 使用这些概率来计算每个文档的排名分数,并用于最终输出结果集的排名。
-

-
要计算每一段k中返回的d是相关的概率,即k中相关数除以k中总数,然后计算所有k的平均值
-
在单次训练查询中,同一个 𝑘k 值的段内所有文档的概率是一致的,基于该段内相关文档的比例。
-
不同的训练查询可能会产生不同的 𝑘k 值段的概率。
-
最终,每个 𝑘k 值的段的概率是所有训练查询中该段概率的平均值。
-
在融合阶段,每个文档的分数是基于它在所有系统和所有段的平均相关概率的累加。
-

-
评分: 每个底层输入系统为文档分配的分数是它在被返回的段中相关概率除以该段的编号。
-
浏览效应: 通过段编号的除法,高排名的文档会获得额外的提升,利用了浏览效应。
-
合唱效应: 文档的最终排名分数是通过将每个系统赋予的个别分数相加得到的,利用了合唱效应(即出现在多个结果集中的文档会获得更高的分数)。
-
适用性: ProbFuse 只适用于数据融合任务,因为它给予在多个结果集中出现的文档更高的排名。
-
在ProbFuse方法的融合阶段,目标是利用从训练阶段得到的概率来计算每个文档的最终排名分数。以下是融合阶段的详细步骤:
融合阶段步骤
- 计算相关概率: 对于每个输入系统和每个查询,根据文档在结果集中的段 ( k ),使用训练阶段得到的概率来评估文档的相关概率。
- 应用浏览效应: 为了增强排名靠前的文档,将每个文档的相关概率除以它所在段的编号 ( k )。这意味着来自靠前段的文档(即 ( k ) 值较小的文档)会得到更高的加权分数。
- 计算每个系统的文档分数: 对于每个输入系统,将上述计算得到的加权概率应用到该系统中返回的每个文档上。这样,每个文档在每个系统中都会有一个分数。
- 累加分数: 对于每个文档,将其在所有输入系统中得到的分数累加。这个总和分数将作为文档的最终排名分数。
- 文档排名: 根据计算出的最终排名分数,对所有文档进行排序,生成最终的融合结果集。
公式表示
假设 ( P(d, k) ) 是在训练阶段计算得到的,表示文档 ( d ) 在段 ( k ) 中是相关的概率。在融合阶段,每个文档 ( d ) 在输入系统 ( i ) 中的分数 ( S(d, i) ) 可以通过以下公式计算:
[ S(d, i) = \sum_{k=1}^{x} \left( \frac{P(d, k)}{k} \right) ]
其中 ( x ) 是结果集被分割成的段数,( k ) 是当前考虑的段的编号。
合唱效应
通过将来自不同输入系统的分数累加,ProbFuse利用了所谓的“合唱效应”,即如果一个文档在多个结果集中返回,它可能会获得更高的最终分数,因为每个系统都会为其贡献分数。
结果
最终,所有文档根据它们的累加分数进行排序,形成融合后的结果集。这个结果集旨在比单一系统的结果集提供更好的相关性和排名质量。
例子
假设我们有一个文档 ( d ),在两个输入系统中的不同段返回:
- 在系统 ( A ) 的第 1 段返回,相关概率为 ( P(d, 1) = 0.8 )。
- 在系统 ( B ) 的第 3 段返回,相关概率为 ( P(d, 3) = 0.3 )。
根据ProbFuse,文档 ( d ) 在系统 ( A ) 的分数将是 ( \frac{0.8}{1} = 0.8 ),在系统 ( B ) 的分数将是 ( \frac{0.3}{3} \approx 0.1 )。文档 ( d ) 的最终分数将是这两个分数的总和,即 ( 0.8 + 0.1 = 0.9 )。
通过这种方式,ProbFuse结合了不同输入系统的优势,同时考虑了文档在结果集中的位置,以期望生成一个更准确和相关的最终结果集。
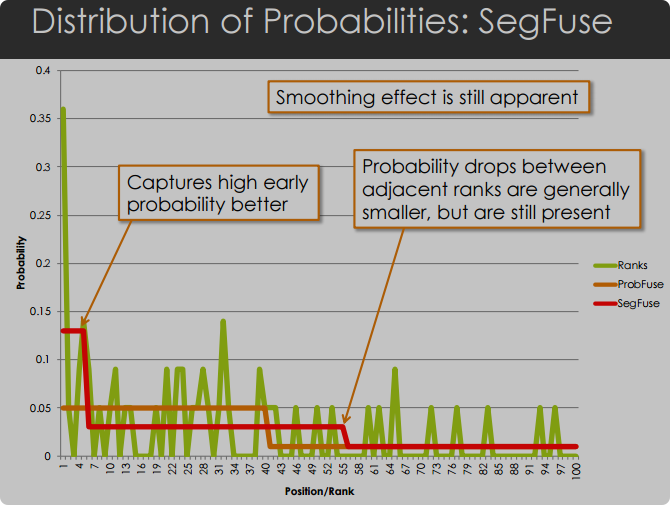
SegFuse 方法
- 动机: ProbFuse 将结果集划分为等大小的段,但实验表明,对k于某些数据集,这种方法可能不是最优的,因为相关文档更有可能在早期位置找到。
- 设计: SegFuse 通过将段的大小指数增加来改进 ProbFuse,同时使用标准化分数来增强浏览效应。
- k的大小: S i z e k = ( 10 x 2 k − 1 ) − 5 Size_{k}=(10\mathrm{~x~}2^{k-1})-5 Sizek=(10 x 2k−1)−5
SlideFuse 方法
-
动机: SegFuse 将结果集划分为不同大小的段,但相邻文档可能会被非常不同地处理。
-
不希望因为很小的概率或情况把某个相关度很大的doc的概率变成0或者令某个相关度很小的变得很大
-
概率分布情况
-

-

-
-
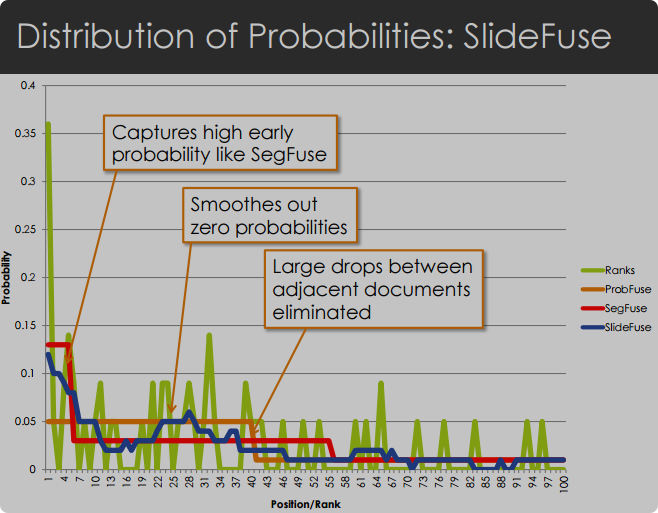
-
-
设计: SlideFuse 算法通过使用滑动窗口来估计每个排名的概率,从而平滑概率分布图,避免了“仅排名”分布中出现的锯齿状峰值,以及 ProbFuse 和 SegFuse 中相邻排名之间概率值的突然下降。
-
结论
- SlideFuse 在使用 TREC-2004 网络跟踪数据时,相较于 CombMNZ、ProbFuse 和 SegFuse,取得了更好的结果。
- SlideFuse 在 MAP 和 P@10 的 5 次运行中显示出统计学上显著的性能提升,在 bpref 的 3 次运行中也有所提升。
- 在所有其他情况下,平均差异小于 1%。
SlideFuse 是一种改进的基于概率的数据融合方法,旨在解决传统ProbFuse方法中出现的一些问题,如相邻文档可能被非常不同地处理。SlideFuse 通过使用滑动窗口的概念来平滑概率分布,从而避免在结果集中相邻文档之间的处理差异过大。以下是SlideFuse方法的详细解释:
SlideFuse 动机
- 在ProbFuse和SegFuse方法中,结果集被划分为固定大小或指数增长大小的段,这可能导致相邻文档(如文档20和文档21)被分到不同的段,并以非常不同的方式处理。
- SlideFuse旨在平滑处理相邻文档,以避免这种突然的变化。
SlideFuse 概览
- 滑动窗口: SlideFuse 不是将结果集划分为固定的段,而是使用滑动窗口来考虑每个文档及其相邻文档的相关概率。
- 训练阶段: 计算每个排名 ( r ) 的相关概率,即在排名 ( r ) 返回的相关文档数量除以总的训练查询数量。
- 融合阶段: 对于每个文档,计算其周围滑动窗口内的平均相关概率,并用这个平均概率作为文档的分数。
SlideFuse 训练
- 在训练阶段,对于每个输入系统,首先计算每个排名 ( r ) 的相关概率。
SlideFuse 融合
- 在融合阶段,每个文档的最终分数是它从输入系统中获得的分数的总和。
- 对于每个输入系统,计算围绕文档的滑动窗口内的平均相关概率。
SlideFuse 的概率分布
- SlideFuse 通过考虑文档的相邻文档来平滑概率分布图,避免了“仅排名”分布中的锯齿状峰值。
- 与ProbFuse和SegFuse相比,SlideFuse 能够更好地捕捉到早期排名的高概率,并且消除了相邻文档之间概率值的大幅下降。
SlideFuse 的效果
- SlideFuse 在处理大规模任务时特别有用,因为在这些任务中,可能只有少量的相关文档被判别出来。
- 通过使用滑动窗口,SlideFuse 避免了给那些在训练期间没有返回相关文档的确切排名赋予零概率。
结论
- SlideFuse 在TREC-2004网络跟踪数据上相比于CombMNZ、ProbFuse和SegFuse取得了更好的结果。
- 在使用MAP和P@10测量时,SlideFuse显示出统计学上显著的性能提升。
SlideFuse 通过其滑动窗口的概念,提供了一种更为细致和平滑的方法来处理文档的相关概率,从而提高了数据融合的效果和最终结果集的质量。
9 PageRank
简介
- 传统信息检索模型(如向量空间模型和BM25)将每个文档视为独立的实体,仅根据文档内容计算排名分数。
- PageRank算法考虑了文档的重要性,并将其作为搜索结果排名的一个因素。
文档重要性
- 学术写作中,引用次数可以作为衡量文档重要性的指标。
- Web上的文档通过超文本链接相互连接,因此可以应用类似引用计数的原则来评估网页的重要性。
- Circular references - in academic publishing, a paper canonly cite a paper that has already been published. Later papers are not cited by earlier ones. On the web, two pages can link to one another.
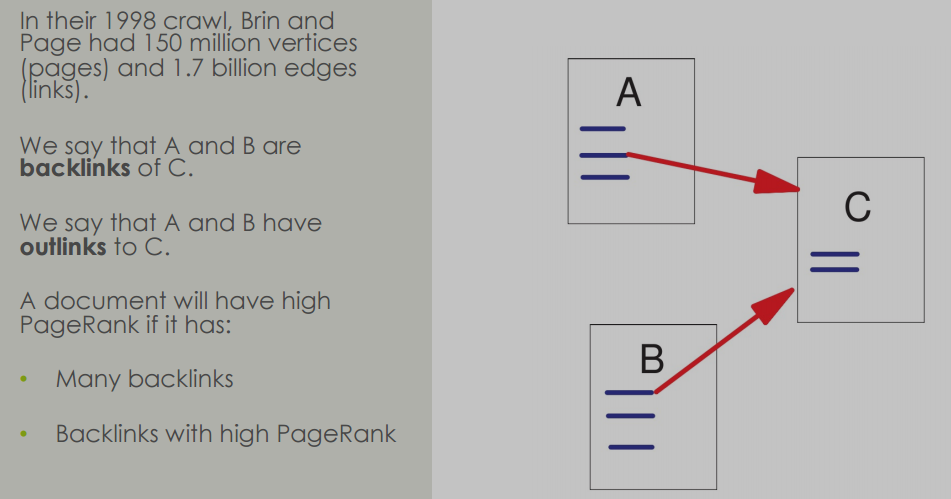
PageRank算法
- PageRank基于这样一个前提:被许多其他文档链接的文档是重要的,应该在搜索引擎排名中获得提升。
- 一个文档如果被许多文档链接,或者被具有高PageRank分数的文档链接,将倾向于拥有高PageRank分数。
- 在网页的上下文中,反向链接就是其他网页通过HTML中的
<a>标签创建的指向当前网页的链接。 - 就是当前文章或网页,被其他网页调用引用的意思
PageRank的工作原理
- Web可以被视为一个有向图,其中HTML页面是顶点,超链接是边。
- 一个文档的PageRank分数是其所有反向链接(backlinks)的PageRank分数的加权和。
- 初始的PageRank分数可以是任意的,然后通过迭代计算新分数,直到分数收敛(即再次计算分数时变化很小或不变)。
PageRank的简化公式
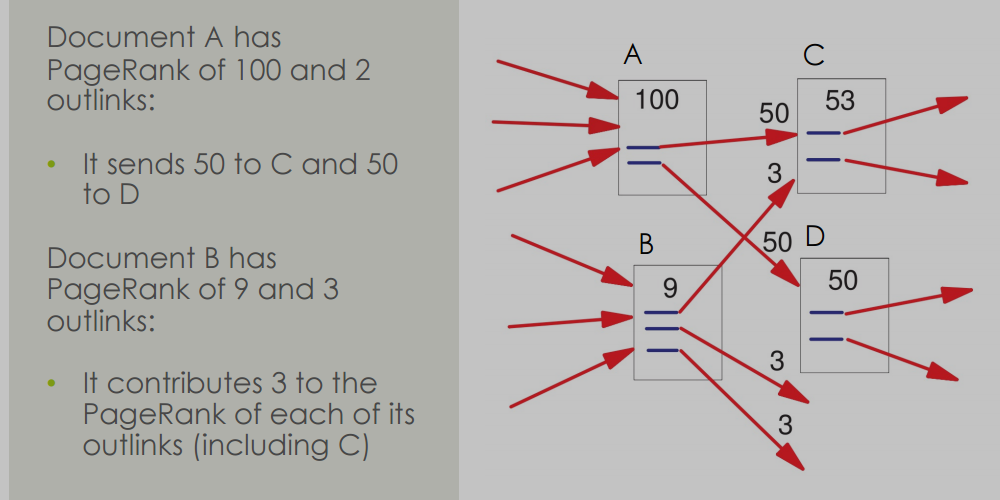
-
R ( u ) = ∑ v ∈ B u R ( v ) N v R(u)=\sum_{v\in Bu}\frac{R(v)}{N_v} R(u)=∑v∈BuNvR(v)
- 𝑅(𝑢)是文档 𝑢的PageRank分数。
- 𝐵𝑢是文档 𝑢的所有反向链接集合。
- 𝑅(𝑣)是文档 𝑣的PageRank分数。
- 𝑁𝑣是文档 𝑣的出链数量。
-
出链(outlinks)和反向链接(backlinks)是两个不同的概念,它们在PageRank算法和网络链接分析中扮演不同的角色。让我们来澄清一下这两个术语:
-
反向链接(Backlinks) :
- 反向链接是指指向特定网页或文档的其他网页或文档的链接。换句话说,如果网页A有一个链接指向网页B,那么网页A就是网页B的一个反向链接。在您的例子中,如果A和B都有链接指向C,那么A和B就是C的反向链接。
- 就是被引用了的链接,C被A,B引用了,所以叫反向链接
-
出链(Outlinks) :
- 出链是指从特定网页或文档指向其他网页或文档的链接。一个网页的出链数量是指该网页上所有指向其他网页的链接的总数。在您的例子中,如果A和B都链接到C,那么C是A和B的出链。
因此,使用您提供的示例:
- 对于网页C,其反向链接是A和B(因为A和B链接到C)。
- 对于网页A和B,它们的出链是C(因为A和B都链接到C)。
在PageRank算法中,一个网页的PageRank值部分取决于其反向链接的数量和质量。同时,一个网页的出链数量会影响它对其他网页PageRank值的贡献程度。如果一个网页有大量的出链,那么它的PageRank值会在这些出链之间分散,意思就是自己本身是调用了很多其他的内容的,自身的真正的权威性会下降,从而减少每个出链所获得的PageRank值的比例。
-
-
-
反向链接的重要性:
- 一个网页的反向链接数量多,意味着有更多的网页认为该网页是值得链接的,这通常被解释为该网页具有较高的权威性或重要性。在PageRank算法中,这会正面地影响该网页的PageRank值。
-
出链对PageRank的影响:
- 一个网页的出链数量确实会影响它对其他网页PageRank值的贡献。如果一个网页链接到很多其他网页(即有很多出链),那么它的PageRank值会被这些链接所“稀释”。这是因为PageRank算法假设一个网页的“信任和权威”是有限的,如果一个网页将这个“信任”分给太多的其他网页,那么每个链接所传递的“信任”就会减少。
-
PageRank贡献度的分配:
- 在PageRank算法中,一个网页的PageRank值不是简单地平均分配给所有出链,而是根据出链的数量进行比例分配。如果一个网页有n个出链,那么它对每个链接的网页的PageRank贡献是其PageRank值除以n。这样做是为了模拟一个网页将“权威”分给所有它认为值得链接的网页。
-
阻尼因子的作用:
- 阻尼因子(damping factor)的引入是为了解决一些特定的问题,如排名汇聚(rank sinks),并模拟用户浏览行为的随机性。它确保了一个网页不会将其所有PageRank值通过出链传递出去,而是保留一部分。
因此,一个网页的反向链接数量多确实表明它可能很重要,但是它对其他网页的PageRank贡献度会根据它的出链数量进行调整,以确保PageRank值的分配既公平又准确。
-
-
PageRank的问题和改进
-
排名汇聚(Rank Sinks) :当一组页面只内部相互链接而不链接到外部时,会导致PageRank分数异常高。
-
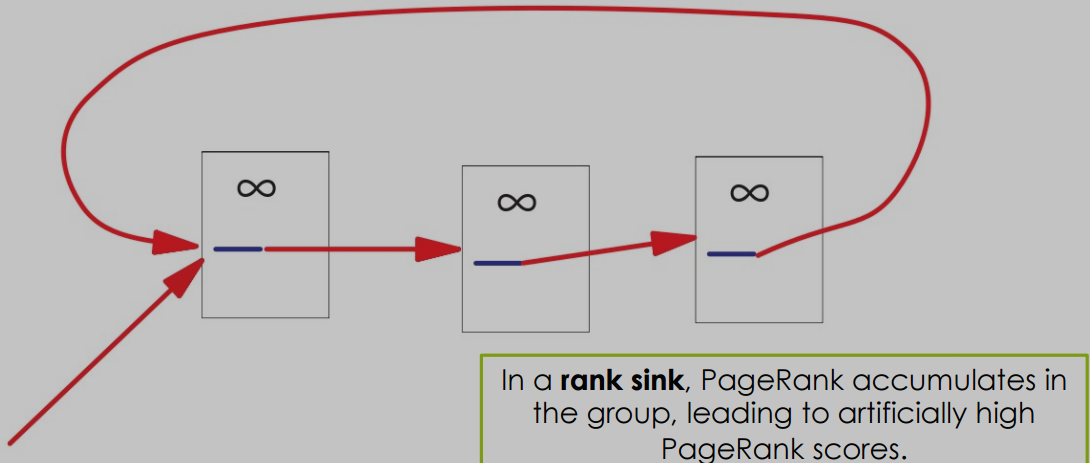 死循环了
死循环了
-
-
阻尼因子(Damping Factor) :引入阻尼因子 𝑑 来解决排名汇聚问题,确保文档的部分PageRank分数不会通过出链传递。
PageRank的计算示例
-
R ( u ) = ( 1 − d ) + d × ∑ v ∈ B u R ( v ) N v R(u)=(1-d)+d\times\sum_{v\in B_u}\frac{R(v)}{N_v} R(u)=(1−d)+d×∑v∈BuNvR(v)
-
文档A、B、C、D的简单链接结构,以及如何使用阻尼因子计算每个文档的PageRank分数。
-
一般情况下初始为1,d为0.85
-

PageRank的收敛性
- PageRank算法在大规模数据集上具有良好的收敛性,即使数据集规模加倍,所需的迭代次数增加也很小。
PageRank的影响
- Google使用PageRank帮助排名文档,从而在英语世界的网络搜索中占据主导地位。
- Google的搜索技术还包括其他信息检索技术(如全文搜索、标题搜索、邻近搜索等),并通过融合过程将这些不同类型搜索的结果合并。
- 由于在线搜索业务的竞争性,Google的具体搜索细节不再公开。
总结
PageRank算法是一个革命性的网络排名系统,它通过分析网页之间的链接关系来评估网页的重要性。这个算法不仅影响了Google的成功,也对整个互联网搜索技术产生了深远的影响。尽管PageRank算法的基本思想保持不变,但Google对其细节进行了调整以应对恶意利用,并与其他搜索技术相结合以提供更准确的搜索结果。
10 相关性反馈(Relevance Feedback)
-
定义:用户参与检索过程以改善最终结果集。用户对初始结果集中的文档的相关性给出反馈,系统根据这些反馈重新处理查询并提供更新的结果集。
-
过程:
- 用户提供查询(通常简短简单)。
- 系统返回初始结果集。initial set of results
- 用户标记一些相关和不相关的文档。
- 系统根据反馈计算更好的信息需求表示。
- 系统返回修订后的结果集。
- 可能重复上述过程。
Rocchio算法
- 背景:Rocchio算法是最著名的相关性反馈算法之一。
- 基本思想:基于文档和查询以向量表示(例如使用TF-IDF,尽管任何向量表示都可以工作)。目的是找到一个查询向量,使其与相关文档的相似度最大化,与不相关文档的相似度最小化。
- 目标:找到最优的查询向量,该向量与相关文档集的相似度与不相关文档集的相似度之间的差异最大。
- q ⃗ o p t = arg max [ s i m ( q ⃗ , C r ) − s i m ( q ⃗ , C n r ) ] \vec{q}_{opt}=\arg\max[sim(\vec{q},C_{r})-sim(\vec{q},C_{nr})] qopt=argmax[sim(q,Cr)−sim(q,Cnr)]
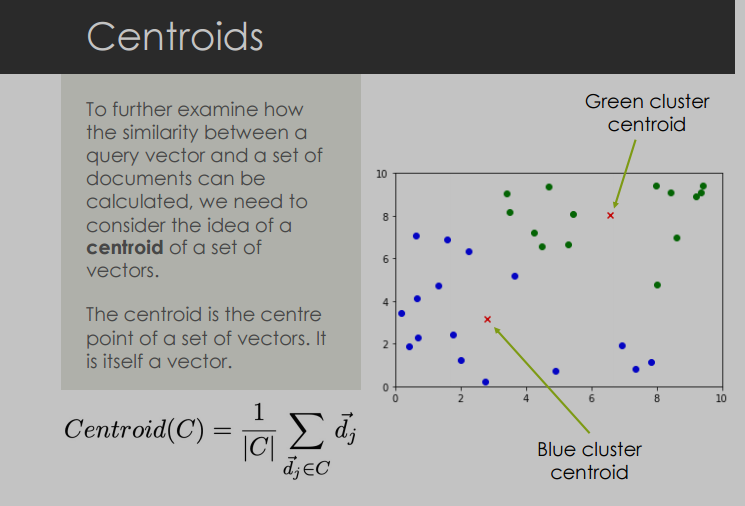
向量空间中的质心(Centroids)
- 定义:质心是一组向量的中心点,它本身也是一个向量。
-
Rocchio算法的实践应用
-
q ⃗ o p t = 1 ∣ C r ∣ ∑ d ⃗ j ∈ C r d ⃗ j − 1 ∣ C n r ∣ ∑ d ⃗ j ∈ C n r d ⃗ j \vec{q}_{opt}=\frac{1}{|C_{r}|}\sum_{\vec{d}_{j}\in C_{r}}\vec{d}_{j}-\frac{1}{|C_{nr}|}\sum_{\vec{d}_{j}\in C_{nr}}\vec{d}_{j} qopt=∣Cr∣1∑dj∈Crdj−∣Cnr∣1∑dj∈Cnrdj.由相关质心减去非相关质心
-
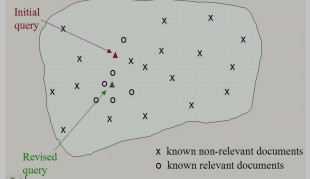
实际应用:在相关性反馈情况下,我们可以获得用户已识别的相关和不相关文档的子集。Rocchio算法利用这些信息计算修改后的查询向量(或“修订查询向量”),然后重新运行检索。意思就是初始查询和修订查询是不一致的,会越来越好
-
-
-
q ⃗ m = α q ⃗ 0 + β 1 ∣ D r ∣ ∑ d ⃗ j ∈ D r d ⃗ j − γ 1 ∣ D n r ∣ ∑ d ⃗ j ∈ D n r d ⃗ j \vec{q}_{m}=\alpha\vec{q}_{0}+\beta\frac{1}{|D_{r}|}\sum_{\vec{d}_{j}\in D_{r}}\vec{d}_{j}-\gamma\frac{1}{|D_{nr}|}\sum_{\vec{d}_{j}\in D_{nr}}\vec{d}_{j} qm=αq0+β∣Dr∣1dj∈Dr∑dj−γ∣Dnr∣1dj∈Dnr∑dj
- q ⃗ 0 \vec{q}_{0} q0其是用户原始查询,
- D r D_{r} Dr和 D n r D_{nr} Dnr分别是用户识别的相关和不相关的文档
- 𝛼, 𝛽和𝛾是影响公式行为的权重。
权重(Weights)的影响
-
作用:权重控制了对已判断的相关和不相关文档集的信任程度与对原始查询的信任程度之间的平衡。
-
设置:在许多已判断文档的情况下,𝛽和𝛾可能较高。修改后的查询将原始查询从非相关文档的质心(𝛾)移开一定距离,并向相关文档的质心(𝛽)靠近一定距离。
-
正反馈比负反馈更有用,所以大部分系统中γ小于β
-
一般情况下α=1,β=0.75,γ=0.15
- 只有正反馈的系统的γ是0
相关性反馈的假设
-
用户知识:用户必须有足够的知识来做出接近相关文档的初始查询。
-
问题:相关性反馈本身无法解决的问题包括拼写错误、跨语言IR和词汇不匹配。
- misspelling,cross-language,vocabulary mismatch
伪相关性反馈(Pseudo Relevance Feedback)
-
聚集性:在信息检索中,通常假设相关的文档在向量空间中会彼此靠近,形成“聚集”或“簇”。
-
问题:然而,有时相关文档可能分散在不同的聚集中,这可能是由以下原因造成的:
- 不同的词汇:文档可能使用不同的词汇来描述相同的事物,例如,“宇航员”(astronaut)和“太空人”(cosmonaut)。
- 组合不同事物的查询:查询可能结合了两个非常不同的事物,例如,“在UCD学习过的足球运动员”。
- 泛化概念:一些广泛的主题可能包含许多更具体的子主题,例如,“猫科动物”(felines)既包括野生动物也包括家养宠物。
-

-
定义:用户通常不愿意提供反馈(称为显式explicit反馈)。相反,可以使用伪相关性反馈:假设排名最高的k个文档是相关的,然后应用相关性反馈算法。
-
效果:在实践中相当成功,尽管在某些情况下可能会有问题。
相关文档的聚集性假设
假设我们正在寻找有关“太空探索”的文档。根据聚集性假设,我们可能会期望所有关于太空探索的文档在向量空间中彼此接近,形成一个紧密的“太空探索”聚集。然而,实际情况可能更复杂:
-
不同词汇:
- 文档A可能使用“宇航员”一词,而文档B可能使用“太空人”。尽管它们讨论的是相同的主题,但由于使用了不同的词汇,它们可能不会聚集在一起。
-
组合不同事物的查询:
- 如果我们搜索“在UCD学习过的足球运动员”,我们可能会得到一些关于UCD的文档,以及一些关于足球运动员的文档。这些文档可能分散在不同的聚集中,因为它们结合了两个不同的主题。
-
泛化概念:
- 如果我们搜索“猫科动物”,我们可能会得到关于老虎、狮子等野生动物的文档,以及关于家猫的文档。这些文档可能不会聚集在一起,因为它们涵盖了广泛的子主题。
伪相关性反馈(Pseudo Relevance Feedback)
假设用户在搜索引擎中输入了“太空探索”这个查询。搜索引擎返回了一系列结果,但没有用户反馈来告诉搜索引擎哪些结果是最相关的。在这种情况下,搜索引擎可能会采用伪相关性反馈:
-
假设排名:
- 搜索引擎可能会假设排名最高的前5个文档是最相关的(例如,基于它们的流行度、网站权威性等因素)。
-
应用算法:
- 然后,搜索引擎会使用这些假设为相关的文档来调整原始查询,可能会增加与这些文档相关的关键词的权重。
-
改进搜索结果:
- 通过这种方式,搜索引擎希望能够改进后续的搜索结果,使其更加贴近用户的实际需求。
例子:
- 用户搜索“最佳太空探索书籍”。
- 搜索引擎返回了10个结果,但没有用户反馈。
- 搜索引擎假设前3个结果是最相关的,并分析这些文档中常见的关键词。
- 搜索引擎调整原始查询,增加了如“宇航员”、“太空船”等关键词的权重。
- 用户再次进行搜索,这次得到了更加精确和个性化的搜索结果。
间接相关性反馈(Indirect Relevance Feedback)
- 定义:如果用户不通过积极标记文档为相关或不相关来提供显式反馈,可以从其他来源收集证据以获得隐式implicit反馈。例如:用户点击了哪些文档?用户查看文档的时间有多长?用户浏览结果的时间有多长?
总结
-
相关性反馈:允许用户通过告知系统相关和/或不相关的结果参与检索。
-
示例:基于向量表示的Rocchio算法。
-
实践:在实践中不受欢迎,因此使用其他方式来模拟反馈或从其他来源获取反馈:
- 伪相关性反馈(或“盲目相关性反馈”:假设前k个文档是相关的)。
- 隐式相关性反馈(来自其他来源的证据:点击和用户行为)。
11 查询扩展(Query Expansion)
- 定义:查询扩展是信息检索中的一个过程,它通过选择并添加与用户查询相关的术语,目的是最小化查询与文档之间的不匹配,并提高检索性能。
- 作用:通常通过增加召回率(即匹配比原始查询更多的文档)来工作。
- 方式:可以自动进行,也可以交互式进行(需要用户参与,类似于相关性反馈)。
- 就是提供扩展,比如搜索掘金,就可能是掘金西决,掘金vs森林狼这种
交互式查询扩展
- 例子:在搜索查询“palm”的结果中,Google为用户提供了一些查询扩展选项供选择。
自动查询扩展
- 例子:PubMed医学搜索引擎展示了一个自动扩展的查询。原始查询“cancer”已被自动扩展为包括几个相关搜索术语。
查询扩展的资源
-
同义词资源:主要使用的是同义词synonymy(或近义词),即具有相同或相似含义的词语。
-
词库:thesaurus 收集同义词(或近义词)的数据库类型。
- 人工维护的手册词库。
- 自动派生的词库。
-
词嵌入:使用词嵌入实现类似效果,而不使用词库。
-
查询日志挖掘:基于其他用户先前提交的查询。
基于词库的查询扩展
-
方法:对于查询中的每个术语,通过添加词库中类似的词语来扩展查询。
- 例如,“cancer”扩展为“cancer, cancerous, neoplasms”等。
-
效果:通常增加召回率,但可能会显著降低精确度。
-
问题:例如,“interest rate”扩展为“interest fascinate rate”。
-
应用:在科学和工程的专业搜索引擎中广泛使用。
-
挑战:创建和维护手动词库成本高昂且工作量大。
自动词库创建
-
方法:通过分析文档中词语的分布来自动创建词库。
-
相似性定义:
- 如果两个词与相似的词共现,则它们是相似的(例如,“car”和“truck”可能相似,因为它们都与“road”, “driver”, “license”等词共现)。
- 如果两个词与相同的词在特定的语法关系中出现,则它们是相似的(例如,你可以“harvest”, “peel”, “eat”, “prepare”苹果和梨,所以苹果和梨可能相似)。
自动生成的词库示例
- 最近邻词:给出了一些词及其最近的邻居词,以展示如何通过词的共现来确定相似性。
词嵌入用于查询扩展
-
技术:近年来,研究人员使用神经网络方法创建词嵌入:将词表示为n维空间中的向量。
- word2vec可能是最著名的:300维向量。
- 其他较新的包括GloVe、ELMo或来自像BERT这样的语言模型的嵌入。
-
优势:由于词被表示为向量,可以轻松计算词之间的相似性。
- 假设在向量空间中彼此接近的词具有相似的含义。
搜索引擎查询扩展(查询日志挖掘)
-
查询日志:存储有关先前查询和用户行为的详细信息。
- 例如:在搜索“palm”之后,许多用户接下来搜索“palm oil”。
- 例如:搜索“football”和“soccer ball”的用户经常在搜索结果中点击相同的URL。因此,这些是彼此的潜在扩展。
总结
- 查询扩展:是向查询添加术语的过程,以增加召回率。
- 局限性:这不是一个完美的过程,也可能有负面影响。
- 手动词库:是最可靠的方法,但成本高且难以维护。
- 自动方法:因此,提出了几种自动方法
12 Web Crawler 网络爬虫
12.1 引言(Introduction)
- 信息检索(IR)的许多技术和评估方法在万维网(WWW)普及之前就已经发展起来。
- 目前,WWW是最大的信息来源,网络搜索成为使用网络的极其重要方面。
- 随着IR向新环境的转变,出现了一些重大挑战。
12.2 如何找到信息(How do we find information?)
- 网络爬虫(Web Crawlers) :自动在网络上查找文档的程序,以便在索引中包含这些文档,使用户在搜索时能找到它们。
- 超链接提取:通过从每个页面提取超链接来指向新的页面进行索引。
- 爬虫策略:使用广度优先搜索(Breadth-First Search)策略可能会找到更高质量的页面(根据PageRank衡量)。也会减少服务器负载
12.3 典型的网络爬虫工作流程(Typical Web Crawler Workflow)
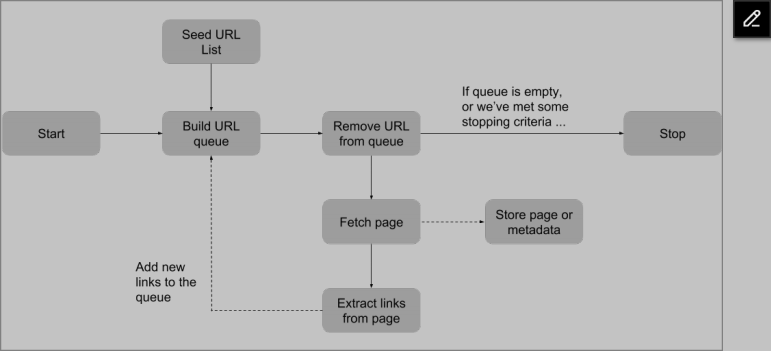
-
广度优先搜索(Breadth-first spider search):
- 手动添加一系列“种子”URL到爬虫的待访问页面队列。
- 只要队列中还有URL,就从队列中移除第一个URL并下载页面。
- 从文档中提取链接。
- 如果这些链接尚未被访问且不在队列中,则将它们添加到待访问页面队列。
-
-
深度优先搜索(Depth-first search)类似,但使用栈(stack)代替队列(queue)。
-
通常并行运行,以避免等待网站响应浪费时间。
12.4 礼貌的爬虫(Polite Crawlers)
-
网络爬虫可能会通过发送过多请求而损害网站。
-
爬虫应该遵守以下“礼貌”规则:
- 遵守robots.txt文件和其他给爬虫的指令。
- 不要超载网站(遵守Crawl-Delay)。
- 不要消耗太多带宽。
- 明确身份和所属(例如“Googlebot”,“Baiduspider”)。
12.5 机器人排除标准(The Robots Exclusion Standard)
- 一种请求网络爬虫不要索引网站某些部分的方法。
- 这是一个自愿标准,没有技术障碍阻止忽略标准的爬虫访问相关页面。
- 良好行为的爬虫访问Web服务器时,首先会检查根目录中的robots.txt文件。
12.6 找到信息 - 机器人排除规则(Finding Information - the Robots Exclusion Rules)
-
允许一个机器人(Allow one bot):
-
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ -
User-agent: Googlebot Disallow: -
User-agent: * Disallow: /
-
12.7 一些网站所有者在创建robots.txt文件时的常见错误
- robots.txt文件必须位于根目录。
- 每行只指定一个不允许的路径。
- “Disallow”部分没有通配符(尽管一些爬虫支持)。
- 错误拼写希望排除的爬虫名称。
- 尝试使用不存在的“Allow”命令(尽管一些爬虫支持)。
12.8 礼貌的爬虫:noindex和nofollow
- 忽略带有
<meta name="robots" content="noindex" />的页面。 - 不跟踪带有
<meta name="robots" content="nofollow" />的页面中的任何链接。 - 也可以标记个别链接为nofollow。
12.9 一些Web特定挑战(Some Web-Specific Challenges)
- 存在多种方式找到相同页面,使用不同的URLs。
- 动态文档问题:网页是动态环境,新页面不断添加,许多现有页面可能频繁变化。
12.10 找到信息:挑战(Finding information: challenges)
- 设计用于阻碍自动访问尝试的页面(例如,通过使用CAPTCHAs)。
12.11 网络有多大?(How big is the web?)
- Google声称他们的索引包含“数千亿网页”。
- 技术上,网络的大小可能是无限的,因为动态页面根据它们接收到的信息给出不同的结果。
12.12 深网(The Deep Web)
- 指网络爬虫无法轻易访问特定在线资源的事实。
- 一些页面或页面组可能没有来自其他地方的链接。
- 异步获取的内容爬虫一般很难访问到
13 对抗性信息检索(Adversarial IR)
- 传统信息检索(IR)和网络搜索的一个关键区别在于,传统作品的发布并没有考虑到IR系统。
- 网页发布与此不同,出现了一个名为搜索引擎优化(Search Engine Optimisation, SEO)的整个行业。
- SEO涉及采取措施使您的页面在搜索引擎排名中更高。
- 动机是:更高的排名 → 更多点击 → 更多收入。
13.1 搜索引擎优化(SEO)
-
为了提高搜索引擎排名,有许多技术可用,可以分为两类:
-
白帽SEO(White Hat SEO):道德操作,遵循搜索引擎的规则和指南以获得更高的排名。
优化关键字,针对移动设备创建网站,满足用户的信息需求,描述性和相关的URL, 标题,meta描述
-
黑帽SEO(Black Hat SEO):违反搜索引擎的指南和规则,试图获得人为优势,即对抗性IR。这是网站的策略,而不是黑客。本质上是欺骗爬虫从而获得更高的利益
-
13.2 对抗性IR:元标签(Meta Tags)
- HTML允许页面作者使用
<meta>标签描述他们页面的内容。 - 这些设计用于以标准化的方式指定页面的描述、关键词和作者等信息。
- 由于滥用,如不诚实的网站管理员试图针对某些搜索查询,元关键词标签现在大多被搜索引擎忽略。元描述标签仍在一定程度上使用。
13.3 对抗性IR:隐藏文本(Hidden Text)
-
隐藏文本是一种操纵手段,通过将文本与背景颜色设置为相同,使得文本对肉眼不可见。
-
主要功能:
- 为搜索引擎添加页面内容中尚未包含的额外关键词(称为“关键词填充”)。
- 提高重要搜索词的词频。
- 在不影响用户视觉的情况下,偷偷加强自己网站的相关性,谋取利益
13.4 对抗性IR:伪装(Cloaking)
- 伪装是指向网络爬虫提供与用户不同的内容的做法。
- 服务器(或运行在其上的脚本)可以配置为根据用户代理字符串提供不同的内容。
- 这种技术通常用于合法地为手机用户提供移动优化的网站。
- 目的是向爬虫提供高度针对性的文本,以在特定搜索中获得高排名。
13.5 对抗性IR:狡猾的JavaScript(Sneaky JavaScript)
- 网络爬虫(和旧版浏览器)通常无法执行JavaScript代码。
- 使用
<noscript>标签可以为无法运行JavaScript的用户提供文本内容。 - 这可以像伪装一样被利用:网络爬虫索引
<noscript>标签的内容,而真实用户将被重定向到不同的页面。
13.6 对抗性IR:利用PageRank
- 高PageRank(或类似)会在搜索结果中获得高排名,因此有商业利益。
- 这导致了“链接农场”的创建:网站(或网站网络)的唯一目的是链接到其他网站以提高它们的PageRank。
- 另一种方法是“评论垃圾邮件”,在允许第三方评论的页面上发布广告链接,以获得PageRank。
13.7 对抗性IR:门页(Doorway Pages)
- 有时创建单独的“门页”,而不是尝试将所有期望的搜索查询包含在单个页面上。
- 这些页面针对特定搜索查询进行优化,然后将用户引导到同一目的地。
13.8 对抗性IR:总结
- 一些网站所有者可能会违反搜索引擎的规则和指南以获得更高的搜索引擎排名(“黑帽SEO”)。
- 这可能难以检测,但搜索引擎会对被发现违反规则的网站进行处罚或禁止。
- 搜索引擎创建者的工作是确保使用这些策略的网页不被包含在索引中,因为它们不太可能满足用户的信息需求。
















 6629
6629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









