







case_study-Twitter
CASE STUDY - Twitter
The contents of this case study mainly comes from the Internet and guidinghttps://blog.twitter.com/engineering/en_us blogs. I have divided the characteristics of each part of the Twitter distributed system into sections to express the overall structural characteristics more clearly
1 Introduction
1.1 Overview
- Twitter, a major social media platform, has transformed global information exchange with its unique “tweet” format. The platform facilitates instantaneous sharing of diverse content across various domains, including politics and entertainment. Central to its operation is an advanced distributed system architecture, critical for program stability and quality service delivery. Twitter’s journey through numerous technological advancements and challenges provides invaluable insights into the application, management, and evolution of distributed systems. This case study aims to dissect and analyze these aspects, shedding light on how Twitter’s distributed system architecture supports its vast, dynamic network while navigating the complexities of data management, scalability, and security.
1.2 Reason
- Technological Innovation: Twitter’s distributed system epitomizes the forefront of social media technology. Its adept handling of voluminous real-time data and the simultaneous processing of highly concurrent requests make it a paragon in the field. Delving into the intricacies of its technical architecture will not only foster a profound understanding of distributed systems but also enhance competency in this domain.
- Technical Challenges: The challenges confronted by Twitter, encompassing data management, scalability, and security, present a comprehensive case study for distributed systems. These challenges underscore the complexities and exigencies of managing a high-traffic, data-intensive platform, providing a practical context for academic exploration.
2 Technology
2.1 System Architecture
Twitter uses a microservices architecture as its primary distributed system to separate all tasks, which splits a single application into many smaller, loosely coupled, and independently deployable services, which will allow teams to develop the entire product at different paces, skills, and components. It also uses some of Kafka’s architecture content to help with message queue construction
-
Microservices architecture : Twitter’s application is broken down into multiple independent microservices, which will improve the system’s flexibility and maintainability. Each service corresponds to a specific function processing, such as authentication, tweet processing, favorites processing, this strategy enhances system scalability and agility.
-
Front-end architecture:The front-end architecture of Twitter is called Twitter Frontend (TFE), whose functions include reverse proxy, API Gateway, and router.
-
Storage system:Many different technologies are used to help store information, including MySQL, Cassandra, and Memcached. Each technology stores data for specific needs, because different storage technologies have different priorities, such as Cassandra for timeline data and Memcached for cache data.
-
Search query:Using Lucene reverse indexing query technology. In Stability and scalability for search, Elasticse is put forward The arch API provides an excellent low-latency, customizable search experience, and by adding guardraines such as proxies, Ingestion Services, and Backfill services to Elasticsearch, We’ve been able to maintain uptime, prevent crashes, and keep search running in the Twitter product.
-
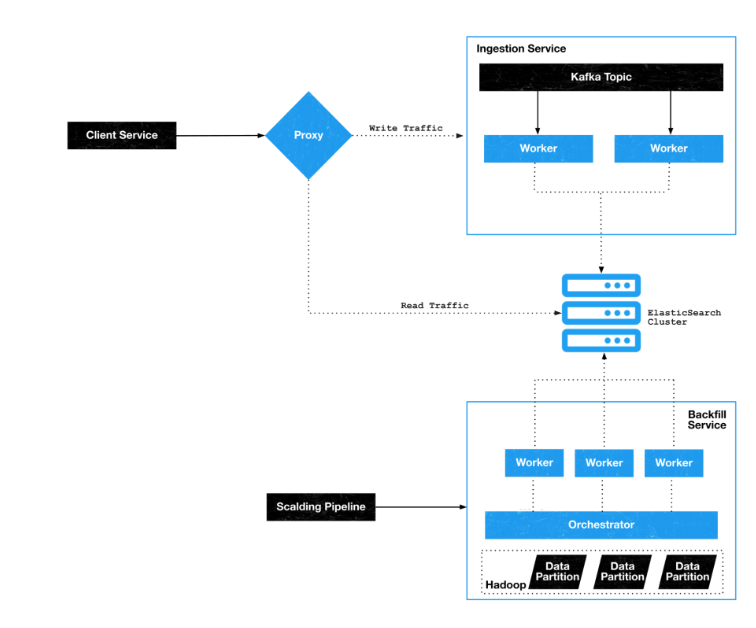
-
-
Employs graph databases and caching layers to efficiently manage relationships and provide quick access to relevant content. This will allow users to follow others, subscribe to other accounts and personalize tweets.
-
Uses indexing and caching strategies to deliver a personalized, responsive experience. This will allow the user to view their own timeline and realize a chronological view of the user’s tweets and retweets.
-
Applies distributed systems and real-time data processing to curate and deliver a dynamic stream of content. This will allow users to view their home page timeline and constantly provide a live feed of tweets.
2.1.1 scalability
-
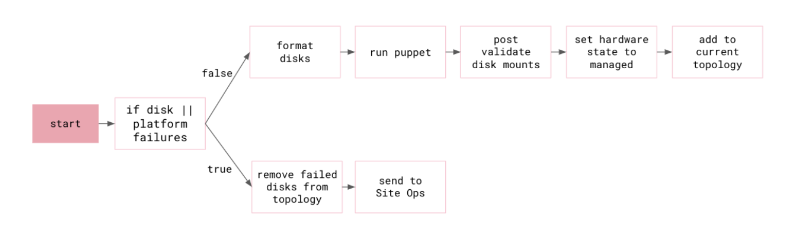
Load balancing:A load balancer is used to ensure that Twitter distributes traffic across multiple servers.*Twitter’s Blobstore Hardware Lifecycle Monitoring and Reporting Service*mentioned that Blobstore checks server response, monitors server status, and allocates resources
- This is the sequence of monitor
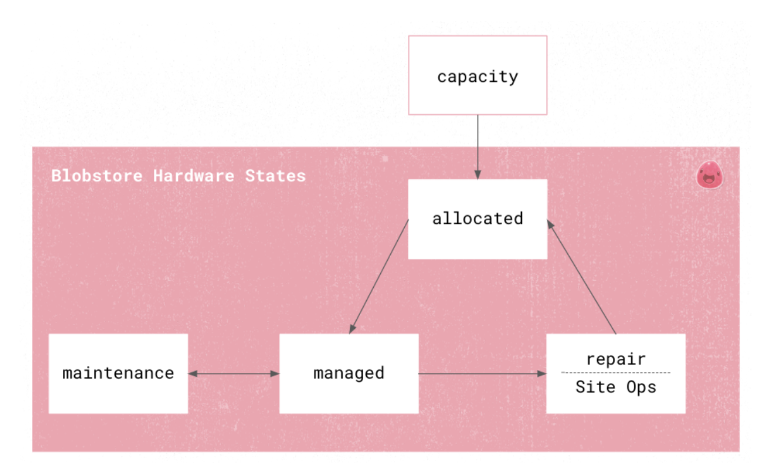
- This is the sequence of monitor
-
Message Queue : Using technologies such as Apache Kafka, different services can exchange information in a high-throughput environment, improve the performance of the architecture, and ensure the real-time and consistent data.
-
Horizontal scaling and data partitioning: Twitter can continue to expand and add more servers to meet the needs of users, ensuring the growth of users and stored data; Twitter’s distributed system splits the data into multiple partitions, each of which is stored on a different server, allowing more information to be processed
-
By using a Redis cluster to cache frequently accessed data, the load on the primary database is reduced.
2.1.2 availibility
-
Real-time processing and analysis:The platform implements a complex real-time data processing and analysis system, using tools such as Storm and Heron for real-time data streaming to quickly respond to and analyze tweet data. In Measuring the impact of Twitter network latency with CausalImpact mentioned that Google’s CausalImpact technology can be used to help filter random network addresses to improve data flow interruptions or errors caused by poor network performance, which will help the system improve the user experience.
-
Failure recovery mechanism: Twitter’s system design includes an efficient failback mechanism that ensures a quick return to service in the event of a hardware failure or network outage. This mechanism usually involves data replication and real-time data synchronization between multiple data centers to ensure that even if one center fails, the other centers can still provide services.
-
Redundant data is retained to avoid crashes caused by component failures. Sparrow technology used by Tuitter is proposed to ensure that the application always has a low-latency communication pipeline, so that the data transmission is more efficient, thus ensuring the reliability which is mentioned in article*Twitter Sparrow tackles data storage challenges of scale*
-
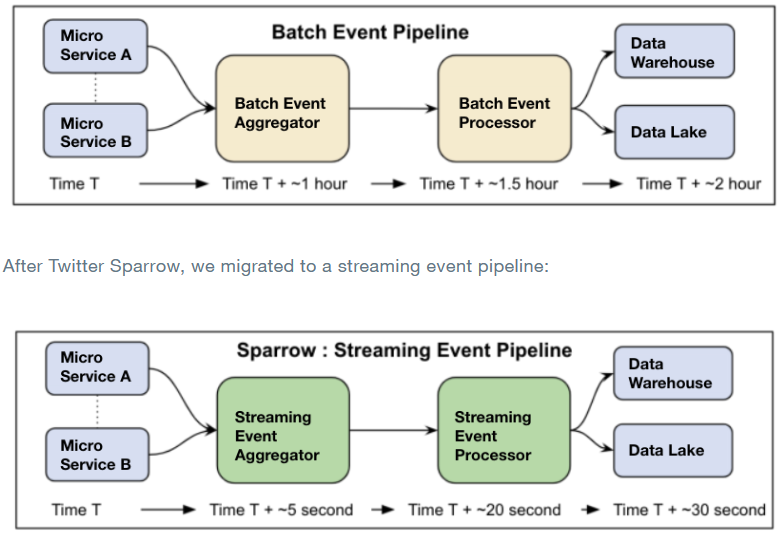
-
-
By employing synchronization techniques between tables, eventual consistency of information is maintained over time, even in the face of network partitions and failures.
2.1.3 security
-
As mentioned in article*Kerberizing Hadoop Clusters at Twitter*, Kerberizing will make authentication more reliable and users will use KDC to secure their accounts. Data is encrypted when differentiating Hadoop data sets, and API gateway security management provides access to users. Each user and service shares a secret key with the KDC. KDC generates a session key - securely distributes it to the communicating parties communicating parties prove to each other that they know each other. When authentication is performed, KDC will query the library for a match, which guarantees that the information will not be leaked
-
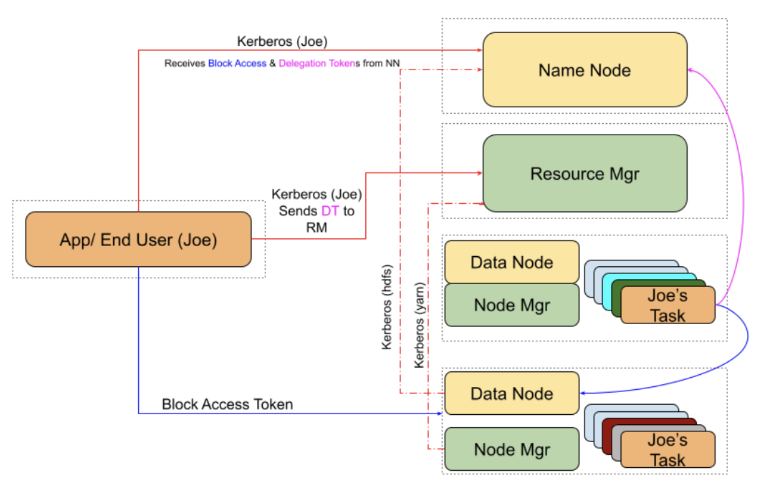
-
-
When it comes to data transmission and storage, Twitter uses advanced encryption technology. This includes encrypting the transmission of data between clients and servers using SSL/TLS protocols, as well as encrypting sensitive data, such as user personal information and communications, when stored to prevent data leakage.
2.2 Distributed File System
-
**Twitter uses the HDFS system within the Hadoop framework. Twitter uses Hadoop mainly to process and analyze its massive user data, such as tweets and user behavior data. HDFS provides a distributed environment capable of efficiently processing and analyzing large data sets. In **Measuring the impact of Twitter network latency with CausalImpact a proposed in this paper, the Twitter use/Apache Hadoop (https://hadoop.apache.org/) to create automation and management tools to improve the operational efficiency of the SRE, provide technical support for the data center of the cluster, It simplifies the operation of managing and maintaining Hadoop clusters and makes the system more robust.
-
**Twitter also leverages Blobstore as a low-cost, high-performance, easy-to-use, scalable storage system. It stores photos, videos, and other binary large objects. **Twitter’s Blobstore Hardware Lifecycle Monitoring and Reporting Service presents the life cycle of Blobstore and briefly introduces how it ensures data reliability.
-
-
-
These two solutions are used to handle large-scale analysis of data and storage of media files respectively, and together provide an excellent data storage mechanism for Twitter.
2.3 Communication protocol
- Twitter uses HTTP and HTTPS as communication protocols for data transfer between clients and servers. For real-time data flow and messaging functions, Twitter uses WebSocket technology as a two-way communication protocol to ensure real-time performance.
- **To optimize the user experience and reduce the impact of network latency,Measuring the impact of Twitter network latency with CausalImpact mentioned that using BSTS model components to calculate the causality of network delay, and using reasonable signal base transmission sites to transmit network data, greatly reducing the inconvenience caused by delay.
3 Critical evaluation
3.1 Contribution
- Twitter’s self-developed technologies offer valuable insights for similar products, showcasing efficient handling of real-time data and concurrency and ensure data consistency and integrity
- Faced with a lot of data management and high concurrency, Twitter has made its own solution, using horizontal scaling and data partitioning to ensure that the client’s data is perfect.
- The Kerberizing security method works to make user information secure so that other businesses can fully learn from Twitter’s security practices to protect users.
- The microservices and modular design adopted by Twitter improve the flexibility and responsiveness of the system; Using multiple distributed file systems to handle different types of data is a good measure. Other companies can use these technologies to maintain their products, and users will have a better experience.
3.2 Disadvantage
- Some technologies can be challenging, how to maintain all modules and update existing technologies is extremely complex.
- The reliance on open-source products for development may pose data security risks.
- All technologies focus on improving data processing, response processing and other application technical issues, although these will improve user experience, but the design of the product may not fully meet user expectations, should be based on the specific needs of users to develop a series of technologies.
3.3 Mutified viewpoint
- While microservices architecture enhances system agility, it complicates operational maintenance.
- The technology focus on data processing and response improvement does not necessarily align with user expectations, suggesting a need for user-centered development.
- Although all technologies are developed to promote the development of products, how to update the iteration is also a tedious thing
4 Conclusion
This analysis of Twitter’s distributed system reveals its adept handling of vast data and real-time communication, showcasing the benefits of scalability, flexibility, and efficiency in modern distributed architectures. However, it also brings to light the challenges in maintenance complexity and performance optimization. Twitter’s case underlines the importance of balancing performance, reliability, and maintainability in such systems. It offers crucial insights for designing and managing distributed systems, especially in scenarios with extensive user engagement and data management. This case study thus serves as a valuable resource for understanding and advancing distributed system architectures in the digital era.
5 Reference
- Twitter’s Blobstore Hardware Lifecycle Monitoring and Reporting Service
- *The data platform cluster operator service for Hadoop cluster management*.
- Stability and scalability for search
- Measuring the impact of Twitter network latency with CausalImpact
- Kerberizing Hadoop Clusters at Twitter
- Twitter Sparrow tackles data storage challenges of scale
- Twitter Structure
We should use Strategy Pattern. It defines a series of algorithms, encapsulating each one and making them interchangeable. The Strategy Pattern lets the algorithm vary independently of the client using it. In the Strategy Pattern, we define a set of algorithms, encapsulate them and make them interchangeable. The Strategy Pattern allows the algorithm to vary independently of the client using it. Therefore, the client can achieve different results by using different algorithms. By using the Strategy Pattern, we can make the system more flexible and easy to extend and maintain, because we can add new strategy classes or modify existing ones at any time without changing the code of the context. We need context, interface, concrete strategy.















 3367
3367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









