







注释
注释就是程序中对代码进行解释说明的文字

生效范围: 注释不影响程序执行, 因为运行的字节码文件中不保留注释
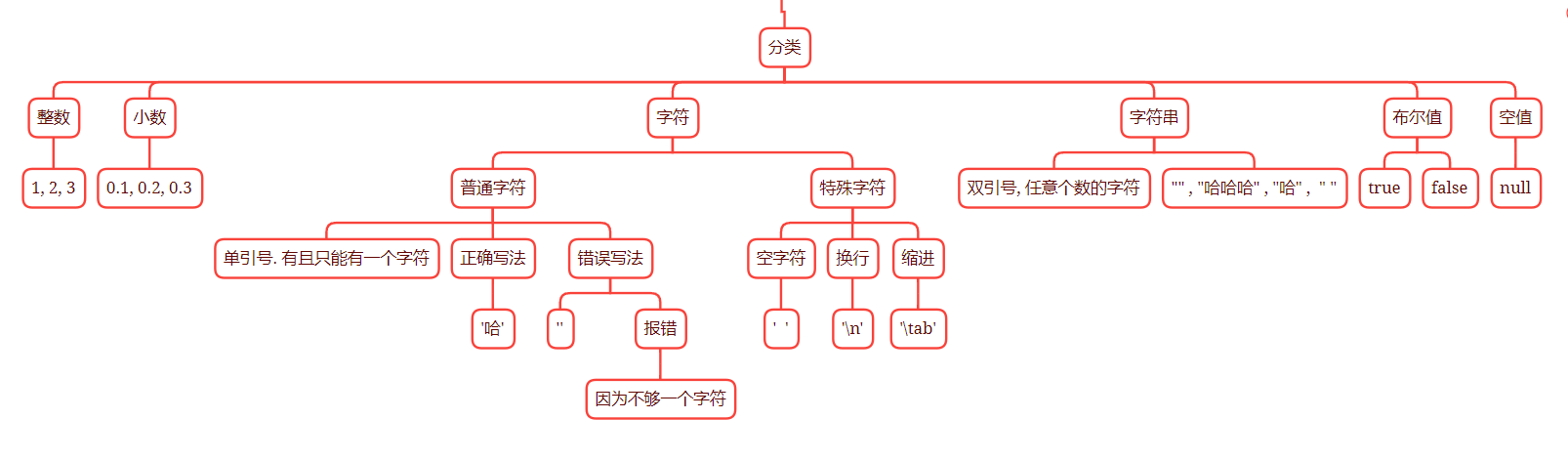
字面量
数据在程序中的书写格式称为字面量
变量
在内存中开辟一块区域, 用来存储数据, 这块空间称为变量
定义变量
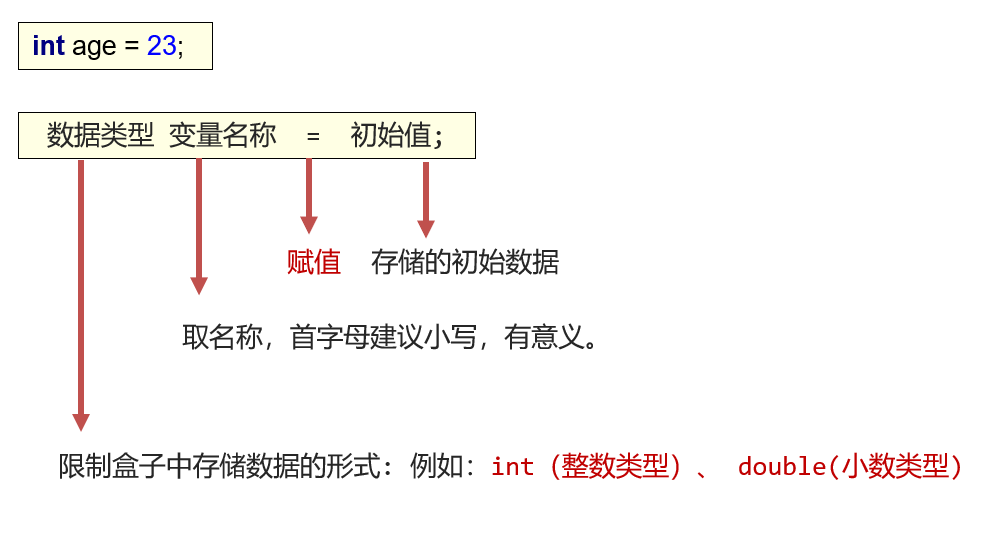
使用变量
变量的优势
- 便于数据的扩展和维护
- 一次定义,多处使用,统一操作
变量的特点
- 变量的数据可以被替换
注意事项
- 先声明再使用
- 变量定义的类型要和数据的类型一致
- 变量的有效范围是从定义开始到 "}" 结束
- 定义变量的时候可以不赋值, 但是使用的时候必须有值, 不然报错
原理补充
1.整数存储


2.文本存储

3.图片储存

4.音频存储

5.视频存储

关键字/标志符
关键字: java官方定义的一些有特殊作用的名字, 如public class int ...... 官方已经占用, 我们就不能使用了
标志符: 我们给变量/函数的命名, 就是标志符
基本要求
- 由数组,字母,下划线和$符号组成
- 不能以数字开头, 不能使用关键字, 区分大小写
建议规范
- 变量名称: 建议英文, 有意义, 首字母小写, 小驼峰
- 类名称: 建议英文, 有意义, 首字母大写, 大驼峰
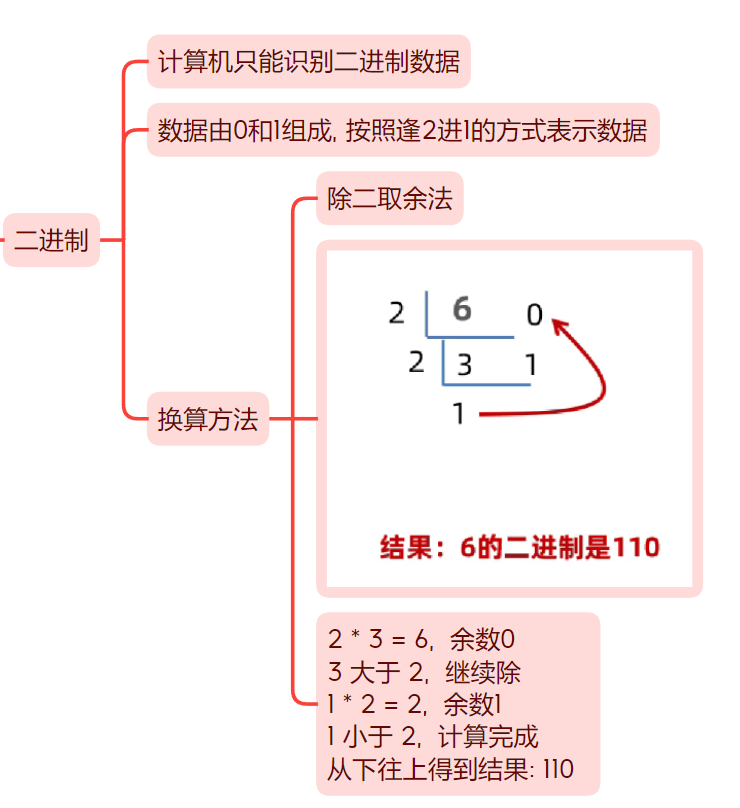
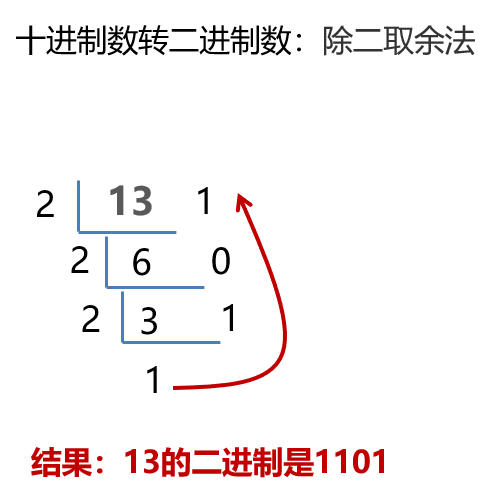
进制转换
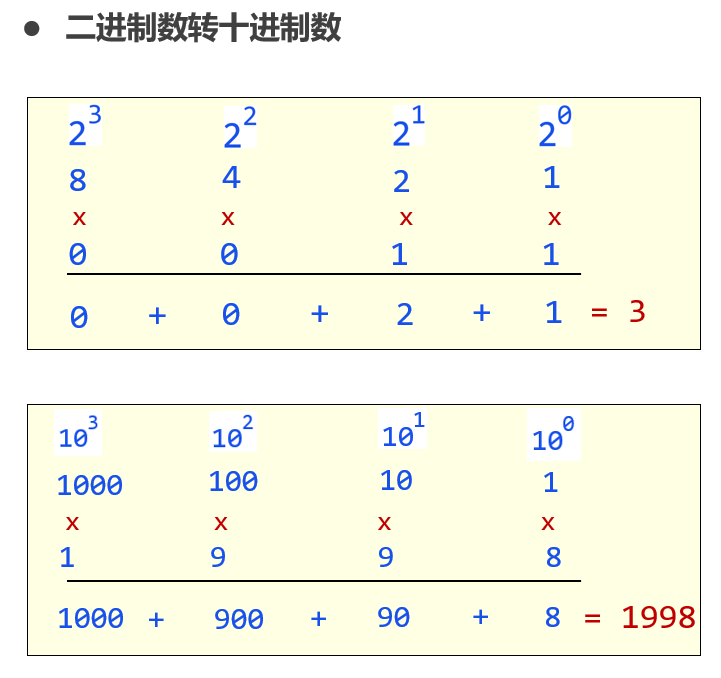


数据单位
计算机最小组成单元是: 字节, 在B的基础上, 发展出了KM, MB, GB, TB等单位
数据单位转换:
- 1B = 8b
- 1MB = 1024KB
- 1GB = 1024MB
- 1TB = 1024GB
- 1KB= 1024B
数据类型
作用: 数据类型就是约束变量存储数据的形式 (4大类8小种)
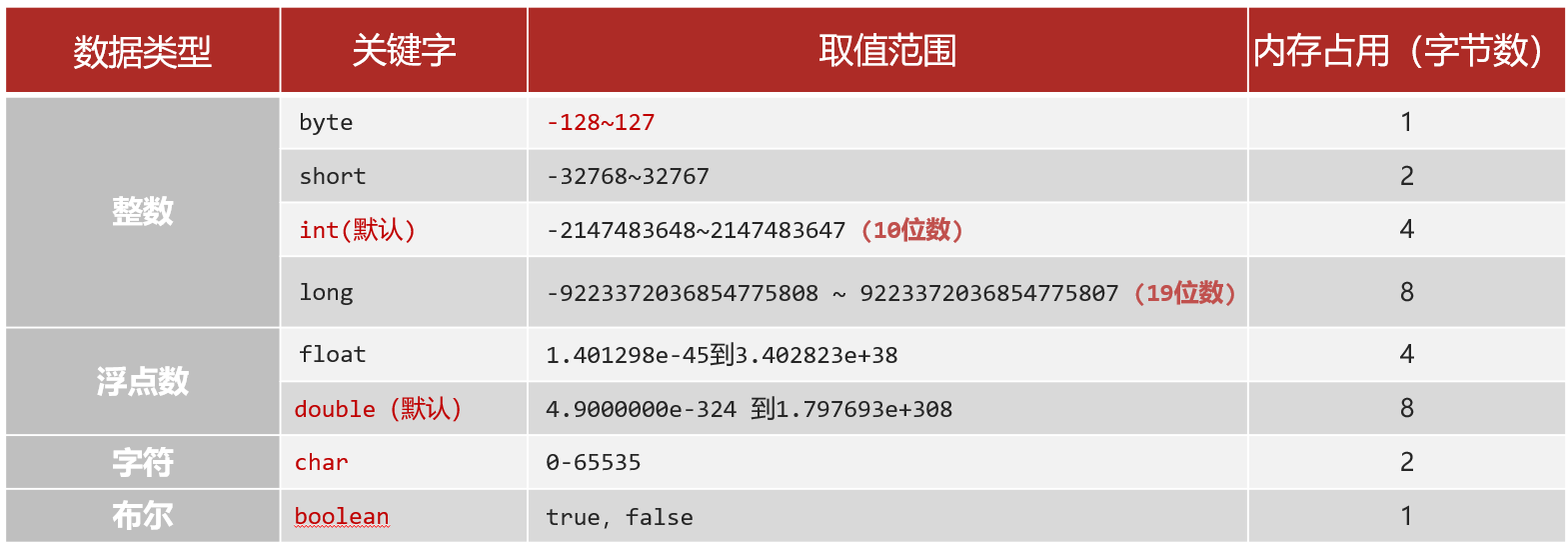
- long num = 44444444L
- 默认是int类型的数据, 加上L/l 就是long类型的数据
- float f = 3.14F
- 默认是double类型的数据, 加上F/f 就是float类型的数据
数据类型转换
1.自动类型转换
定义: 类型范围小的变量, 可以直接赋值给类型范围大的变量
规则: byte -> short / char -> int -> long -> float -> double
byte a =12;
int b = a;2.表达式的自动类型转换
定义: 在表达式中, 小范围类型的变量, 会自动转换成表达式中较大范围的类型, 再参与运算
规则
- byte / short / char -> int -> long -> float -> double
- 表达式的最终结果类型是由表达式中的最高类型决定
- 在表达式中, byte / short / char 是直接转成int类型参与运算的
- byte等类型的范围太小, 很容易出现运算结果超出范围的情况, 所以官方决定在运算时直接转换成int
3.强制类型转换
定义: 强行将类型范围大的变量赋值给类型范围小的变量, 就是强制类型转换
原理

执行原理: 截取大范围类型的一部分赋值给小范围类型
示例
// 语法:
// 数据类型 变量2 = (数据类型)变量1
int a = 20;
byte b = (byte)a;- 快捷键: ALT + Enter => 快速类型强制转换
- 注副作用: 可能会造成数据丢失 / 小数强转整数会截断小数, 保留整数
运算符
算数运算符
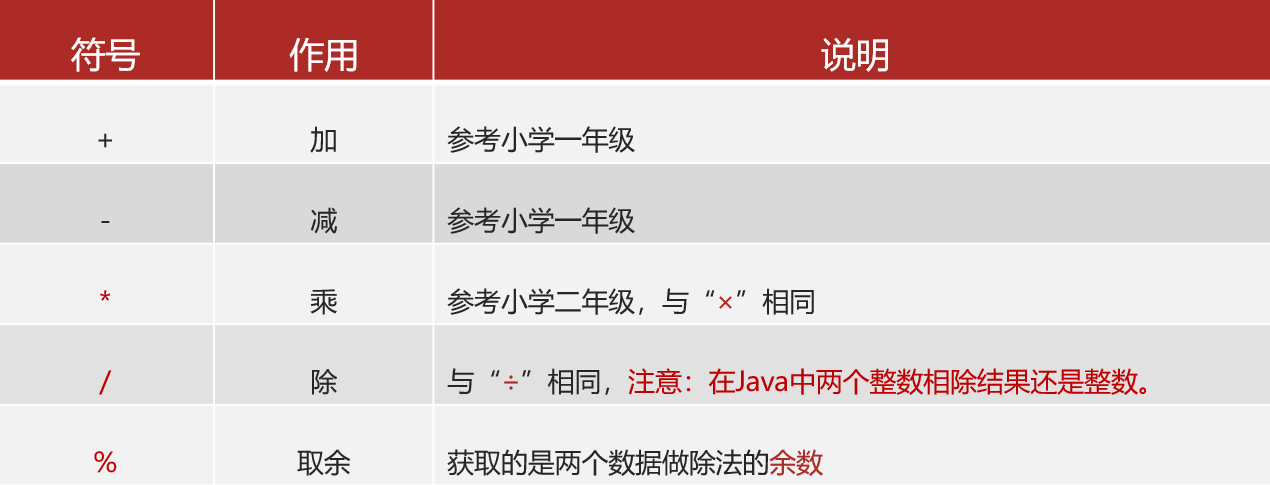
// 除了求和也可以用来拼接, 规则是: 能算则算, 不能算就拼接
// b的结果是 102heima, 因为字符a会被转成97
int a = 5;
int b = a + 'a' + "heima"// 两个变量运算: 先乘 1.0, 再运算
int a = 1;
int b = 2;
double c = 1.0 * a / b
// 两个字面量运算
// 改成小数, 再运算
double a = 5.0 / 2 // 数值拆分
// 个位 :数值 % 10
// 十位 :数值 / 10 % 10
// 百位 :数值 / 10 / 10 % 10
// 千位 :数值 / 10 / 10 / 10 % 10;
int num = 1234;
int g = num % 10; // 1
int g = num / 10 % 10; // 2
int g = num / 100 % 10; // 3
int g = num / 1000 % 10; // 4自增自减运算符

- 如果不是单独使用, 运算符放在变量前后会有明显区别
- 前置自增(自减) / 后置自增(自减)

赋值运算符
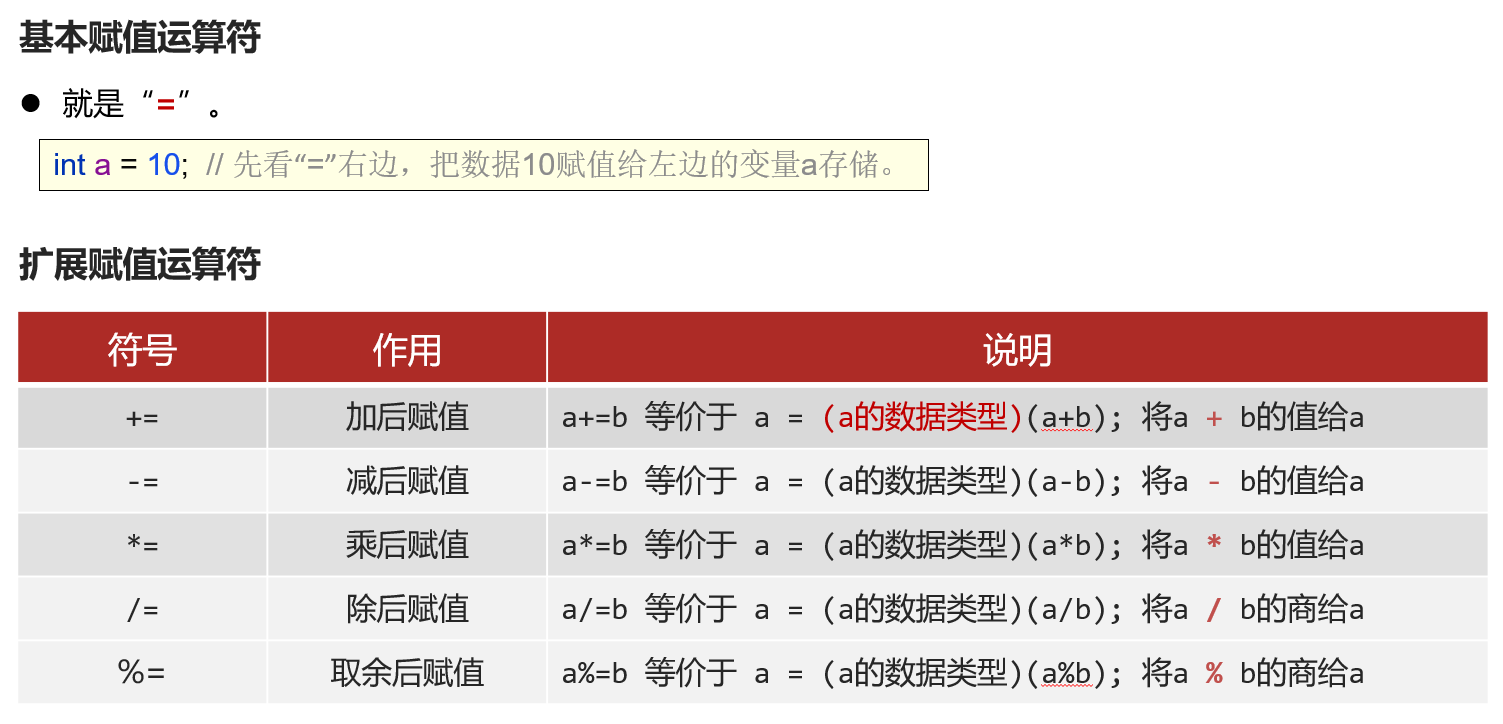
// 扩展运算符除了运算赋值的作用外, 还具有强制类型转换的作用
// 这个类型转换有时候能够帮助我们避免程序错误
// 正常代码
a = a + b
// 实际运行
a = (a类型)(a+b)关系运算符

最终返回一个判断结果, true / false
逻辑运算符

作用: 可以把多个条件的布尔结果放在一起运行, 最终返回一个布尔结果
短路逻辑运算符

短路运算符的效率更高, 更加常用
三元运算符
语法: 条件表达式 ? 值1 : 值2
执行流程: 首先计算表达式的值, 如果为true, 返回值1, 如果为false, 返回值2
运算符优先级
运算符的执行顺序由运算符的优先级决定

- 乘除的优先级高于加减
- 小括号的优先级最高
流程控制
控制程序执行的顺序

分支结构
作用: 通过条件判断选择执行的代码
if分支

switch分支

- 表达式类型只支持byte, short, int, char, 枚举, String,
- 不支持double, float, long类型
- case给出的值不允许重复,且只能是字面量,不能是变量。
- 不要忘记写break,否则会出现穿透现象。
循环结构
作用: 控制代码重复执行
for循环:


while循环:


do while循环:


死循环


嵌套循环

概念: 循环中又包含循环
特点: 外部循环执行一次, 内部循环执行全部
跳出关键字
break: 跳出并结束当前所在循环
continue: 跳出当前循环, 进入下次循环
随机数
作用: 在程序中获取随机数
import java,util.Random; // 导包
Random r = new Random(); //创建随机数对象
int number = r.nextInt(10); //生成随机数 0-9
- 语法: nextInt(n)
- 规则 生成0-n之间的随机数, 不包含n
生成指定区间的随机数
// 需求: 生成5-20之间的随机数
// 1: 先把起始值减到0 => 起始值和最大值同时减5 => 0-15
// 2. 再把减去的值加回来 => (0-15) + 5
// 3, 带入随机数 => 生成0-15的随机数, 写16
int number = r.nextInt(16) + 5
数组
数组就是用来储存一批同类型数据的容器
静态初始化数组
定义数组的时候直接给数组赋值
// 完整格式
// 数据类型[] 数组名 = new 数据类型[] {元素1, 元素2, 元素3}
int[] ages = new int[]{12, 24, 36}
// 简写格式
// 数据类型[] 数组名 = {元素1, 元素2, 元素3}
int[] ages = {12, 24, 35}数组的储存原理
数组属于引用数据类型, 因为数组变量名中储存的是数组在堆内存中的地址, 而不是具体的值
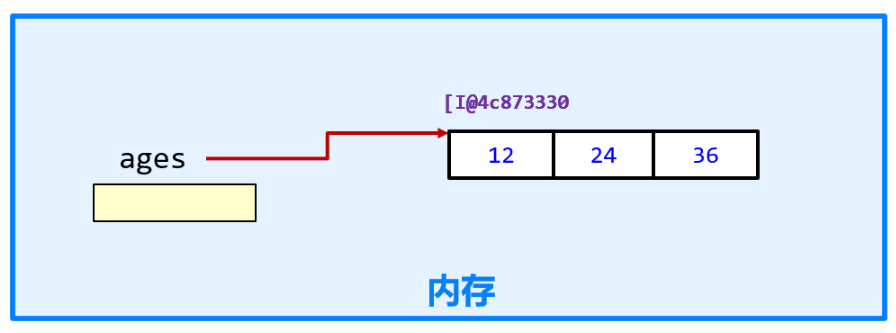
// 代码执行流程
// 1.先创建变量 ages,
// 2.在创建一个数组对象,
// 3.往数组对象中存放数组元素
// 4,把数组对象的地址赋值给变量
// 代码
int[] ages = { 12, 13, 14 }数组的访问
// 取值
数组名[索引]
// 赋值
数组[索引] = 100;
// 数组长度
数组.length
// 数组的最大索引
// 空数组会返回 -1
数组.length - 1注意事项
数据类型[] 数组名 等价于 数据类型 数组名[]

数组的类型和成员的类型必须一致

数组一旦定义出来, 程序执行的过程中, 长度/类型就固定了
动态初始化数组
定义数组的时候, 只确定元素的类型和数组的长度, 需要的时候再赋值
// 定义数组
// 数据类型[] 数组名 = new 数据类型[长度]
int[] arr = new int[5]
// 数组赋值
arr[0] = 10;元素的默认值

注意事项
- 静态初始化数组和动态初始化数组都很常用
- 定义时知道要存入的数据, 就静态初始化
- 定义时不确定要存入的数据, 就动态初始化
- 两种定义数组的方式是独立的, 不要混用

数组的遍历
通过循环的方式拿个数组的所有元素
int[] ages = {1,2,3,4,5,6}
for (int i = 0; i < ages.length; i++) {
System.out.println(ages[i]);
}数组的内存图
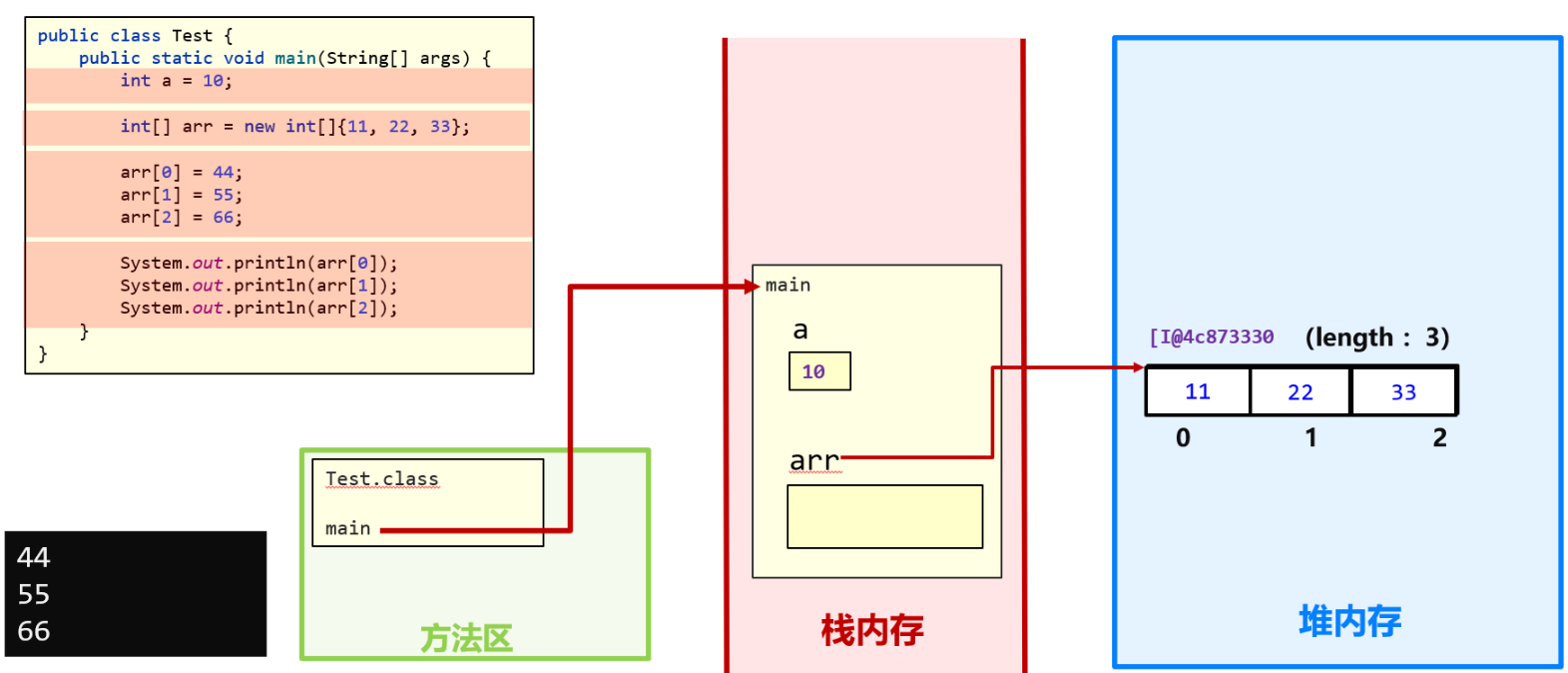
内存分配介绍

- java程序运行在虚拟机中, 虚拟机是运行在内存中
- 虚拟机把内存划分为3块区域, 分为方法区/栈内存/堆内存
- 虚拟机首先把字节码文件放在方法区里加载
- 加载到方法的时候, 把方法放到栈内存中执行, 变量也在这里
- 所有new出来的东西, 都会存放在堆内存中
了解程序执行流程
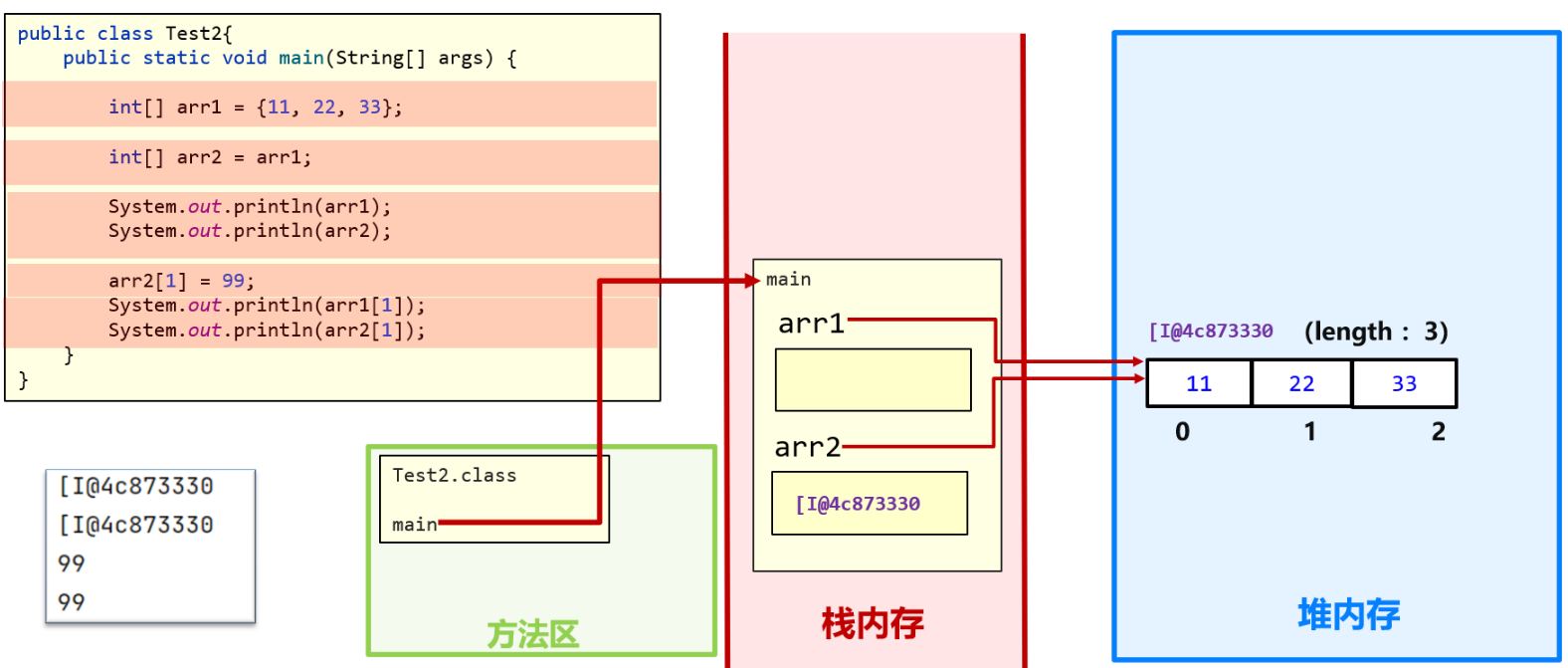
两个数组变量指向同一个数组对象
常见问题
- 如果访问的元素位置超过最大索引, 执行时就会出现数组索引越界异常 (ArrayIndexOutOfBoundsException)

- 如果数组变量中没有储存数组的地址, 而是null, 访问数组时会出现空指针异常(NullPointerException)

Debug工具
IDEA自带断点调试工具, 可以控制代码一行一行的执行, 帮助我们了解程序运行和排查问题
- 在需要控制的代码左侧, 点击一下, 添加断点
![]()
- 选择使用Debug方式启动程序, 程序启动后会在断点处暂停
![]()
- 代码往下执行, 但是跳过方法

- 代码往下执行,不跳过方法
![]()
- 跳出当前方法

- 全部放行
![]()
键盘录入
java官方开发好了一些程序, 供我们使用, 官方程序的API文档(技术使用说明书), 可以帮助我们快速上手

键盘录入功能
- 导包

- 创建扫描器对象

- 等待用户输入
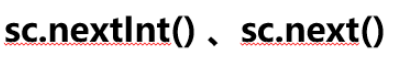
方法
方法是一种语法结构, 可以把一段代码封装成一个功能, 以方便重复调用
定义和调用



补充说明
- 方法的修饰符: 暂时都使用public static修饰
- 如果方法声明了返回值类型, 就必须通过return返回对应的数据
- 如果方法没有返回值, 可以声明成void, 就无需使用return返回数据了
- 形参列表可以有多个数据, 多个数据用逗号分隔, 且不能给初始化值
- 形参列表不是必须的, 不需要就不用写, 调用时也不用传
常见问题
- 方法的编写顺序无所谓
- 方法和方法是平级, 不能嵌套定义
- retuen语句后面的代码不会执行
- 方法不调用就不会执行
- 方法的调用有3种方式: 直接调用/输出(打印)调用/接收结果调用
- 定义方法主要考虑 [有无返回值] 和 [是否需要参数]
执行原理
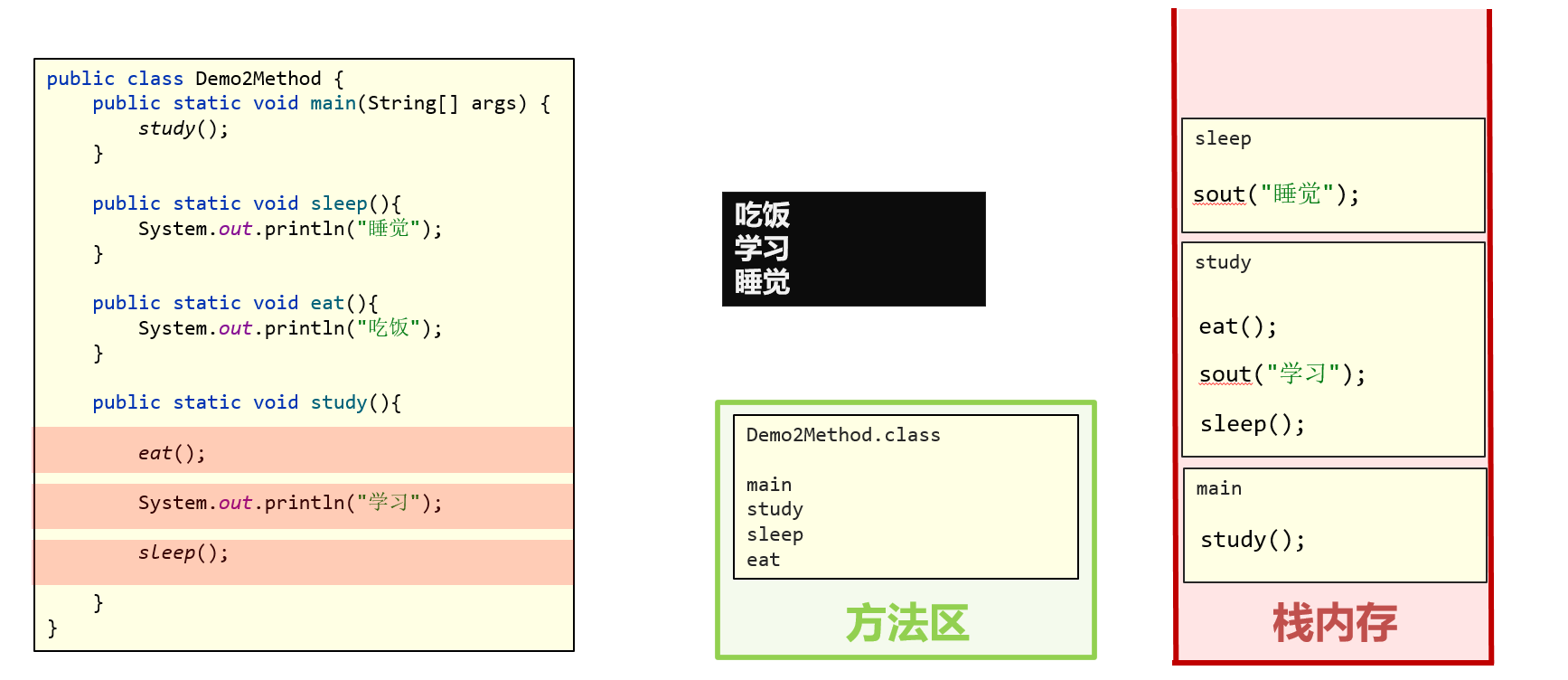
- 虚拟机在方法区中加载class文件
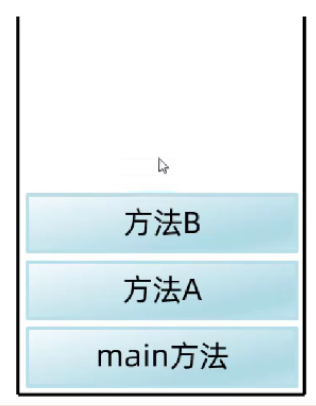
- 遇到方法调用后把方法提取到栈内存中执行
- 栈内存的特点是先进后出
- 方法执行完成后, 会被清理掉, 防止方法过造成多内存溢出
- 栈内存先进后出的特点可以保证, 后一个方法完成后会返回前一个方法
- 栈内存的方法全部执行完成后, 程序也就执行完成了
传参机制
参数传递机制都是值传递, 方法传递实参时, 传递过去的并不是变量, 而是变量中的值
- 基本数据类型的传参是传递数据的副本, 修改形参不影响原数据
- 引用数据类型的传参是传递数据地址的副本, 修改形参会影响原数据
方法重载
一个类中, 多个方法的名称相同, 但是形参列表不同, 就是方法重载
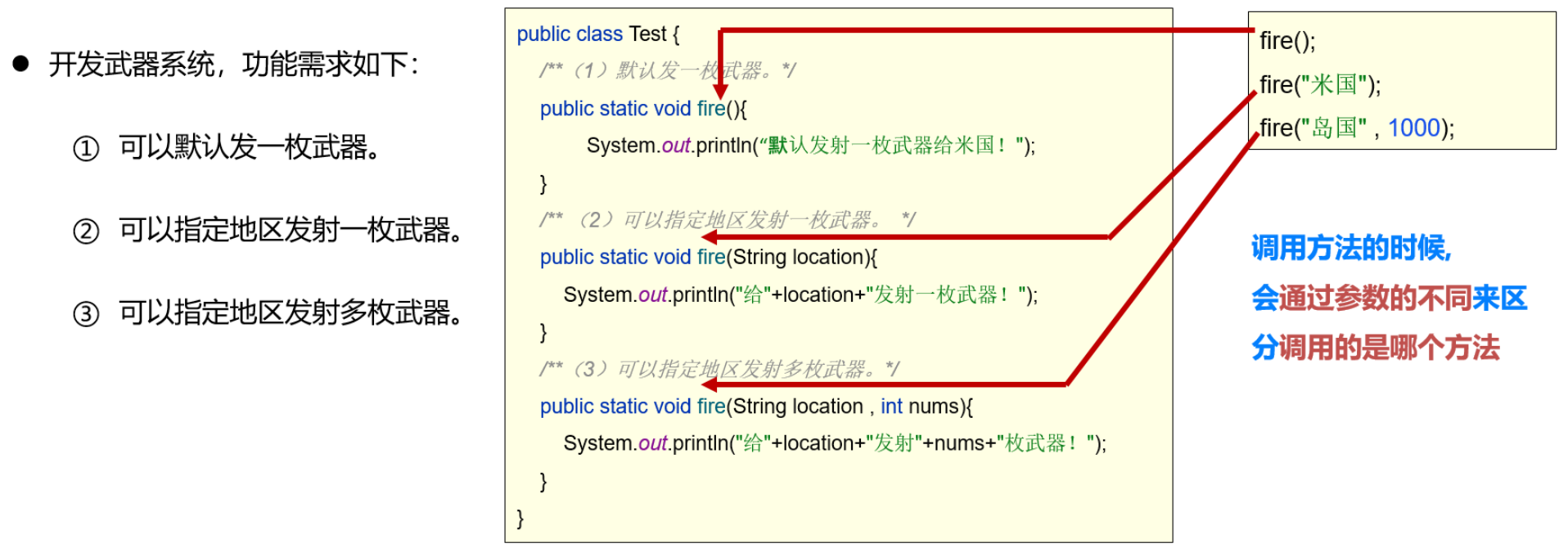
- 可读性好, 方法名称相同表示是同一类功能, 但是参数不同, 又可以实现功能的差异化选择, 非常优雅!
- 只有是同一个类中, 方法名称相同, 参数列表不同就是方法重载, 与修饰符, 返回值无关
- 形参列表不同指的是: 形参的个数, 类型, 顺序不同, 与形参的名称无关
return关键字
在方法中可以使用 return 关键字结束当前方法的执行
- return: 可以结束所在方法的执行
- break: 可以结束所在循环的执行
- continue: 结束当次循环,执行下一次
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









