







程序如下
程序如下,判断输出多少个’_’ 【运行环境:Linux】
./a.out
int main(){
for(int i = 0; i < 2; ++i){
fork();
printf("_");
}
}
熟悉fork的话,这里很容易就能知道,一共产生了3个子进程,还有一个父进程,所以一共是四个进程;每次fork之后都会输出一个’_‘,那么在这里应当的输出是6个’_’
但是实际输出却是 8个’_'; 但是如果在printf(“_”)之后使用fflush(stdout),或者使用printf(“\n”)清空输出缓冲区来输出则结果就是6个了,这就不得不再返回来谈一谈printf的输出机制。
- 标准I/O对待缓存的数据采用3种不同的策略,全缓冲、行缓冲、无缓冲。
- 对于没有交互的终端,例如块设备文件,系统采用全缓冲;(比如输出到文件)
- 对于标准输入,标准输出这样交互设备采用行缓冲;(输出到屏幕或控制台)
- 对于需要立即响应的设备,例如标准错误采用无缓冲;
printf函数只有当缓冲区被刷新的时候才会输出数据,在此之前只是将数据存放到缓冲区。
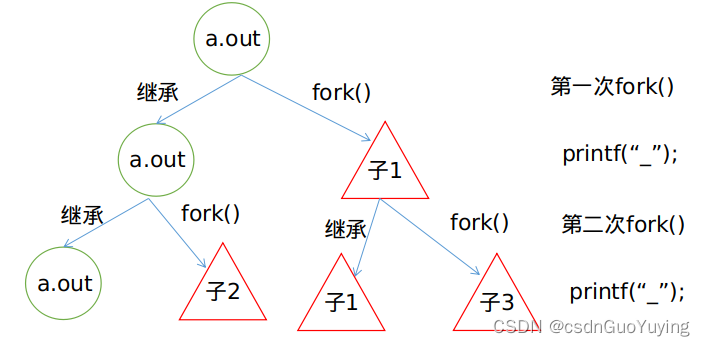
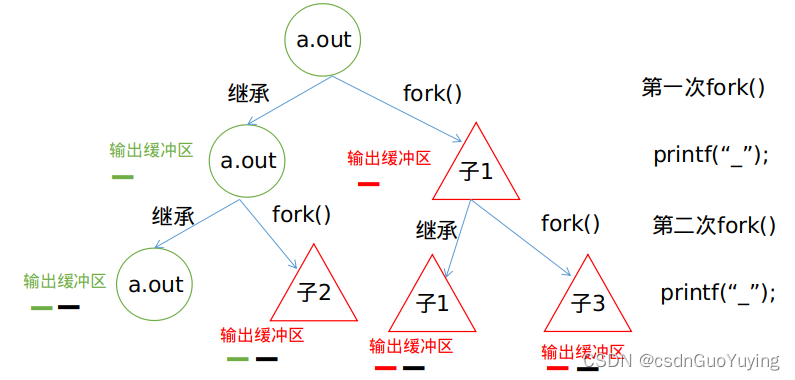
理解了这点后,再去分析上述代码;首先只有一个进程a.out,缓冲区为空;第一次fork()后,父进程a.out产生了一个子进程“子1”,子进程复制父进程的缓冲区(此时为空),然后printf将"_“先放入缓冲区内,a.out与"子1"的缓冲区内各有一个”_";
第二次fork()后,a.out产生了一个子进程"子2",“子1”产生了一个子进程“子3”,“子2”和“子3”均从各自的父进程复制了缓冲区的“_”,此时,a.out,“子1”,“子2”,“子3”各自的缓冲区内均有一个“_”,接下来的printf语句又将”_“分别放入了四个进程的缓冲区内(图中用黑色标识的_),此时,循环结束,四个进程的各自缓冲区内都分别有两个"_“,总共8个,特殊之处在于,”子2“与”子3“的缓冲区内的第一个”_“是复制各自的父进程缓冲区得到的,a.out与"子1"的缓冲区内的第一个"_"是printf累积”_“的结果。如此一来,循环结束后,程序就要结束了,此时缓冲区刷新输出了8个”_".
到这里,这道题已经讲的很明白了,为了深入理解,再通过几个代码详细理解一下缓冲区的刷新机制:
int main(){
printf("hello"); //fflush(stdout);
sleep(5);
int m = 5;
m = 7;
while(m-->0){
printf("*");
}
//printf("\n");
sleep(3);
printf("world");
}
这个程序将如何输出呢?如果去掉注释输出结果又是什么?先思考一下吧。
理想中的输出应该是先输出 “hello”,等待5秒,输出7个’*',再等待3秒,输出"world";但是实际情况却是等待 8秒,一瞬间输出”hello*******world“.
如果去掉注释呢?就是我们所期盼的第一种情况了;造成这种现象的原因上面已经提到了,就是printf并非直接输出,而是先攒到缓冲区里,等待缓冲区刷新再输出;这段程序中的两条注释语句均可以刷新行缓冲策略的缓冲区(行缓冲与全缓冲在文章末尾)。
那么来看一下缓冲区刷新的时机吧
- 1.遇到“\n”,立即刷新缓冲区。(行缓冲)
- 2.程序调用fflush函数刷新缓冲区
- 3.程序以exit结束,缓冲区会刷新。如果以_exit结束,缓冲区数据会被直接清空。
- 4.缓冲区满,也会将缓冲区数据刷新出来。
这样子便不难理解了吧。可惜刚开始学习printf的时候总是习惯性在后面加一个’\n’,所以这么久了这么重要的一个缓冲区机制居然才知道。
最后再用一个例子补充一下行缓冲与全缓冲的区别
int main(){
printf("hello world\r\n");
if(0 == fork()){
printf("son\r\n");
}else{
printf("father\r\n");
}
}
先普通执行一下输出结果为一条"hello world",一条"son",以及一条"father";
再将输出位置重定向到文件,输出结果多了一条"hello world"
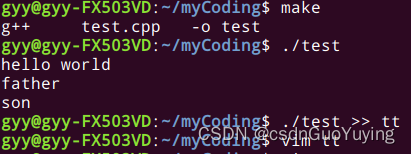
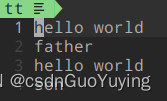
同样的程序,只因为输出位置的不同,结果也就不同,这是因为第一种使用了标准输出也就是控制台和屏幕,采用行缓冲策略;第二种将标准输出重定向到文件,采用的是全缓冲策略;行缓冲策略中的’\n’对全缓冲无效;所以又回到了文章开始的那道面试题的缓冲区复制。由于是全缓冲,并不会刷新缓冲区,因此fork时子进程复制了父进程的缓冲区,里面有一条”hello world“,此时父子进程再各自往缓冲区中攒了"father"和’son’;因此就呈现出最终的输出结果啦。
(这种缓冲区机制在C++中的cout也是一样的)















 1497
1497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











