






词频统计WordCount
大数据框架经典案例:词频统计WordCount,从文件读取数据,统计单词个数。
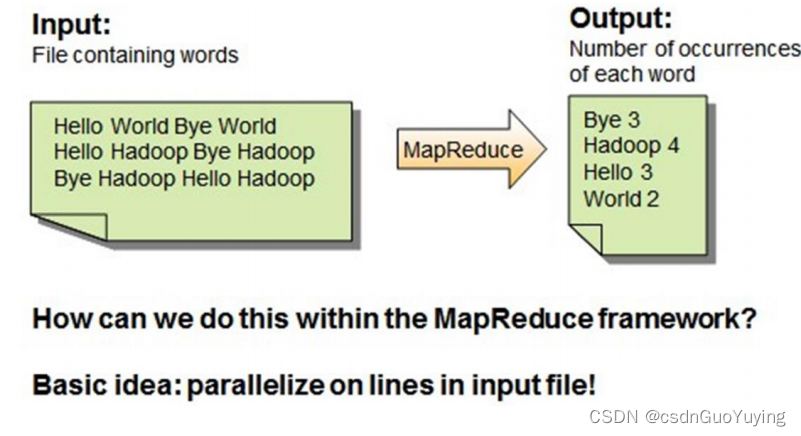
MapReduce WordCount
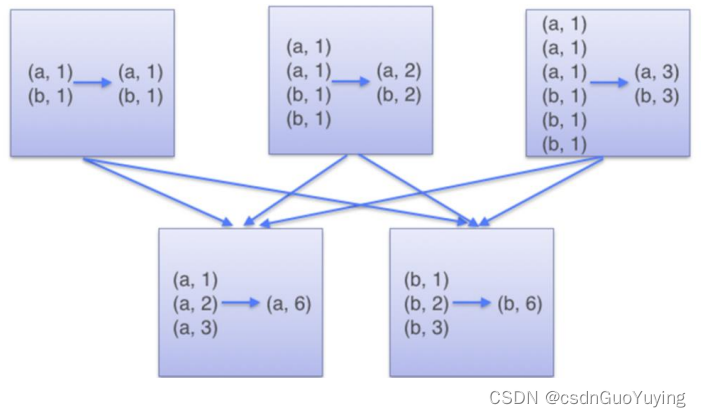
首先回顾一下MapReduce框架如何实现,流程如下图所示:
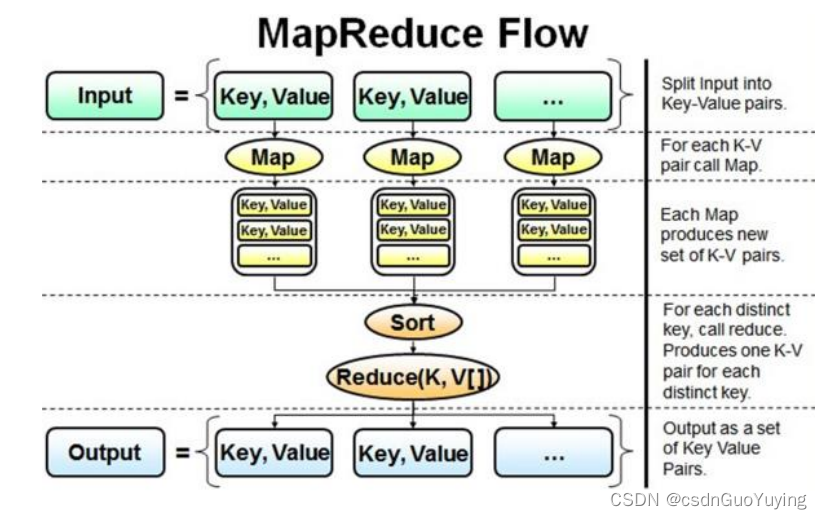
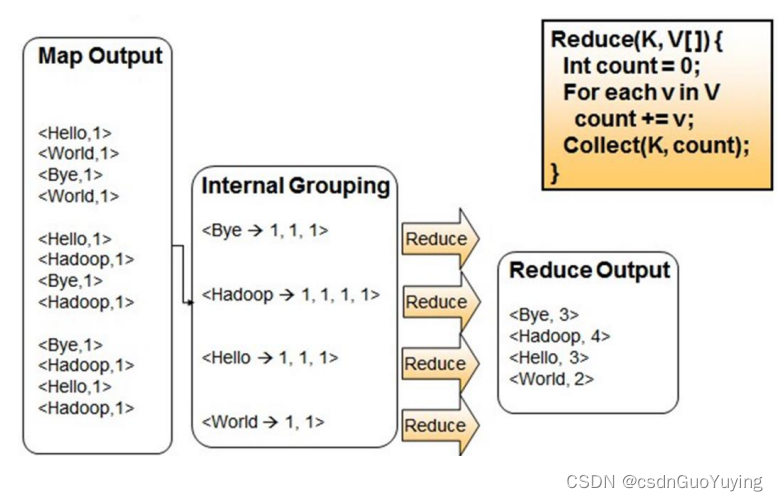
第一步、Map阶段:读取文件数据,分割为单词,出现次数为1

第二步、Reduce阶段:对map阶段输出的数据分组聚合,将相同Key的Value放在一起,聚合每个单词出现的总次数。
Spark WordCount
使用Spark编程实现,分为三个步骤:
-
第一步、从HDFS读取文件数据,sc.textFile方法,将数据封装到RDD中
-
第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
-
第三步、将最终处理结果RDD保存到HDFS或打印控制台
首先回顾一下Scala集合类中高阶函数flatMap与map函数区别,
map函数:会对每一条输入进行指定的func操作,然后为每一条输入返回一个对象;
flatMap函数:先映射后扁平化;
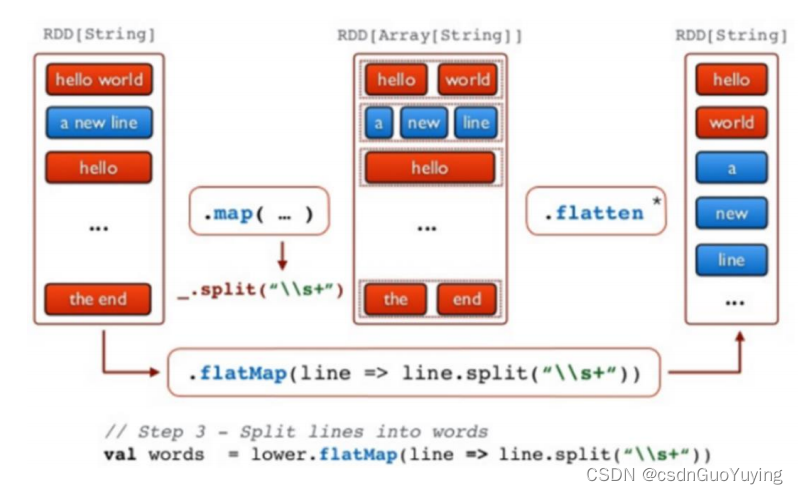
Scala中reduce函数使用案例如下:

在Spark数据结构RDD中reduceByKey函数,相当于MapReduce中shuffle和reduce函数合在一起:按照Key分组,将相同Value放在迭代器中,再使用reduce函数对迭代器中数据聚合。
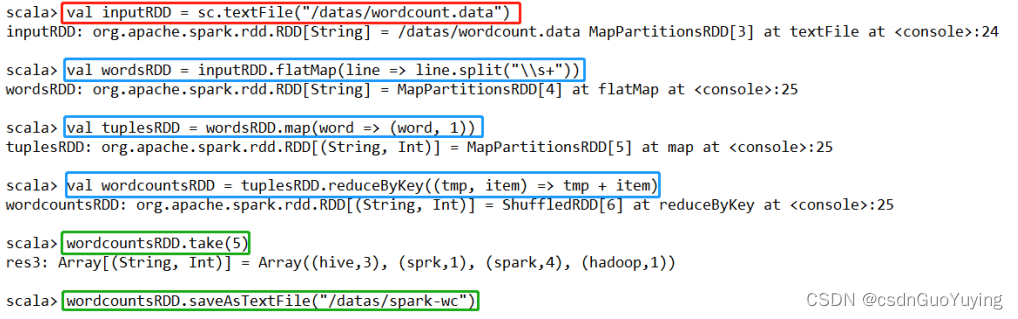
编程实现
准备数据文件:wordcount.data,内容如下,上传HDFS目录【/datas/】
## 创建文件
vim wordcount.data
## 内容如下
spark spark hive hive spark hive
hadoop sprk spark
## 上传HDFS
hdfs dfs -put wordcount.data /datas/
编写代码进行词频统计:
## 读取HDFS文本数据,封装到RDD集合中,文本中每条数据就是集合中每条数据
val inputRDD = sc.textFile("/datas/wordcount.data")
## 将集合中每条数据按照分隔符分割,使用正则:https://www.runoob.com/regexp/regexp-syntax.html
val wordsRDD = inputRDD.flatMap(line => line.split("\\s+"))
## 转换为二元组,表示每个单词出现一次
val tuplesRDD = wordsRDD.map(word => (word, 1))
# 按照Key分组,对Value进行聚合操作, scala中二元组就是Java中Key/Value对
## reduceByKey:先分组,再聚合
val wordcountsRDD = tuplesRDD.reduceByKey((tmp, item) => tmp + item)
## 查看结果
wordcountsRDD.take(5)
## 保存结果数据到HDFs中
wordcountsRDD.saveAsTextFile("/datas/spark-wc")
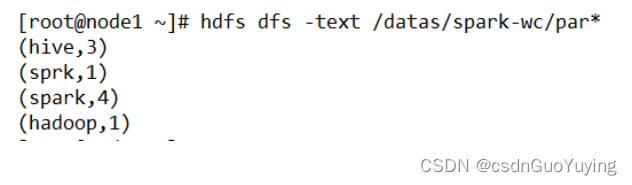
## 查结果数据
hdfs dfs -text /datas/spark-wc/par*
截图如下:
查看保存结果:
监控页面
每个Spark Application应用运行时,启动WEB UI监控页面,默认端口号为4040,使用浏览器打开页面,如下:
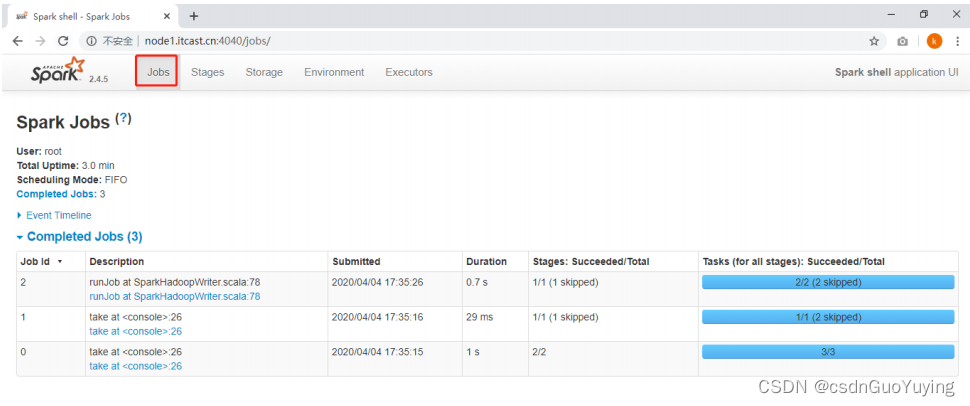
点击【Job 0】,进入到此Job调度界面,通过DAG图展示,具体含义后续再讲。

大多数现有的集群计算系统都是基于非循环的数据流模型。即从稳定的物理存储(如分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的 DAG(Directed AcyclicGraph,有向无环图),然后写回稳定存储。 DAG 数据流图能够在运行时自动实现任务调度和故障恢复。
运行圆周率
Spark框架自带的案例Example中涵盖圆周率PI计算程序,可以使用【$SPARK_HOME/bin/spark-submit】提交应用执行,运行在本地模式。
-
自带案例jar包:【/export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar】
-
提交运行PI程序
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit
–master local[2]
–class org.apache.spark.examples.SparkPi
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar
10
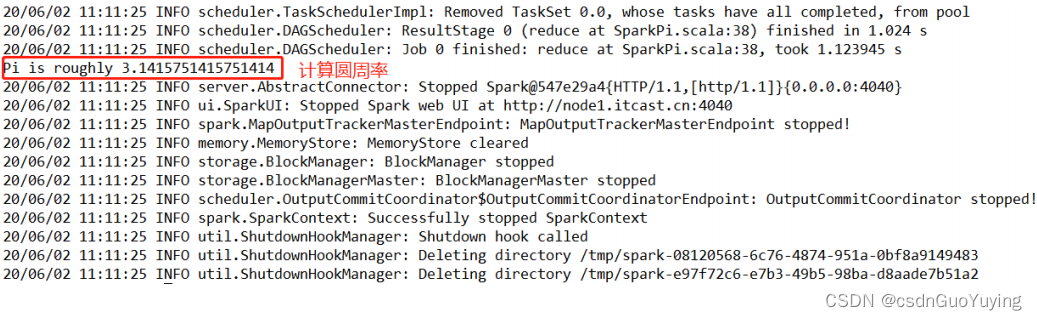
扩展:圆周率计算方式,采用蒙特卡洛算法
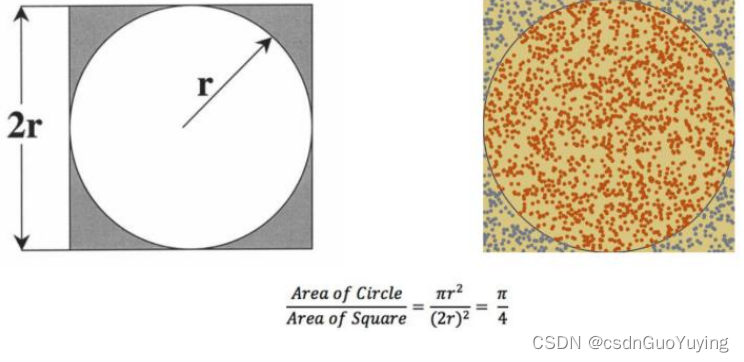
1)、在一个正方形中, 内切出一个圆形
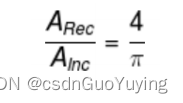
2)、随机向正方形内均匀投 n 个点, 其落入内切圆内的内外点的概率满足如下
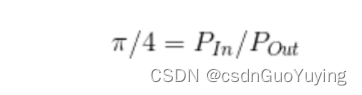
以上就是蒙特卡洛的大致理论, 通过这个蒙特卡洛, 便可以通过迭代循环投点的方式实现蒙特
卡洛算法求圆周率。
















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











