







阅读规范:
- 本文以重点为主,零碎知识点/相对不够重要的为辅助阅读内容,以脚注形式给出,点击脚注即可快速跳转。
- 助解题目通常是为了帮助理解给出的题目,考试不考,若已理解可直接跳过。
- 文中提到的课本是陈火旺的《编译原理第三版》。
- 习题的答案也统一用脚注给出(脚注位于习题后),点击脚注即可快速跳转,建议先自己思考,再看答案。
- 每章节后面会有综合题型,涵盖了本章节重点知识及算法,请完全掌握。
脚注使用:单击正文后的脚注标记即可跳转到详细,再次点击脚注详细内容后的返回箭头可以返回至正文阅读处
本文已开启Latex数学公式支持
正则文法:描述单词语法的文法
基本定义
-
正则文法,3型文法,分为右线性文法和左线性文法,重点掌握右线性文法。【快速跳转链接:3型文法1、左线性文法1】
右线性文法:产生式形式为 U → x V ∣ y U→xV|y U→xV∣y 且 U , V ∈ V N , x , y ∈ V T ∗ U,V ∈V_N,x,y∈V_T^* U,V∈VN,x,y∈VT∗
-
右线性文法
G[S]的状态转换图(TG)表示- G[S]中的非终结符
V
N
V_N
VN作为TG的节点(用⚪表示)
- G[S]的开始符号S对应状态转换图的开始状态S;(每个TG用
→
→
→指向开始状态)
- 增加一个新状态
Z
Z
Z,作为状态转换图的终止状态(用双圈表示);
- G[S]中形如
U
→
x
V
U→xV
U→xV的每条产生式,画一条从状态U到状态V的方向弧,弧上的标记为x;
- 对于G[S]中形如
U
→
y
U→y
U→y的每条产生式,画一条从状态U到终态Z的方向弧,弧上的标记为y
【快速跳转链接:左线性文法的状态转换图表示2】
- G[S]中的非终结符
V
N
V_N
VN作为TG的节点(用⚪表示)
-
助解题目:给出与正则文法G(S)等价的状态转换图。【图】
正规式与正规集
-
正规式(正则表达式),对于字符集 ∑ ∑ ∑,仅在 ∑ ∑ ∑上包含
()、|、*、·四种运算的正规式所表示的集合是 ∑ ∑ ∑上的正规集【快速跳转链接:
()、|、*、·四种运算运算规则 3 】 -
助解题目: ∑ = a , b ∑={a, b} ∑=a,b,其上的正规式与对应的正规集的例子:
| 正规式 | 正规集 |
|---|---|
| a ∣ b a|b a∣b |
{
a
,
b
}
\{a, b\}
{a,b} |
| ( a ∣ b ) ∗ (a|b)^* (a∣b)∗ | { a , b } ∗ 即 a 和 b 所能构成的所有串的集合, { ϵ , a , b , a a , a b , b a , b b , a a a , . . . } \{a,b\}^*即a和b所能构成的所有串的集合,\{\epsilon, a, b, aa, ab, ba, bb, aaa, ...\} {a,b}∗即a和b所能构成的所有串的集合,{ϵ,a,b,aa,ab,ba,bb,aaa,...} |
| a ∗ a^* a∗ | { ϵ , a , a a , a a a , . . . } 即 0 或多个 a 的串组成的集合 \{\epsilon, a, aa, aaa, ...\}即0或多个a的串组成的集合 {ϵ,a,aa,aaa,...}即0或多个a的串组成的集合 |
| ( a ∣ b ) ( a ∣ b ) (a|b)(a|b) (a∣b)(a∣b) | { a a , a b , b a , b b } \{aa, ab, ba, bb\} {aa,ab,ba,bb} |
【快速跳转链接:等价正规式 & 正规式等价变换 4】
- 例子1: a ∣ b ∗ c a|b^*c a∣b∗c,它所表示的正规集为:串a或者是零个或多个b后跟随一个c,即 { a , c , b c , b b c , b b b c , . . . } \{a, c, bc, bbc, bbbc, ...\} {a,c,bc,bbc,bbbc,...}
- 例子2:求“每个1都有0直接跟在右边”的正规式:
(
0
∣
10
)
∗
(0|10)^*
(0∣10)∗
- 思考方式:上述描述的基本结构是 10 10 10, ( 10 ) ∗ (10)^* (10)∗表示的是 { ϵ , 10 , 1010 , . . . } \{\epsilon, 10, 1010,...\} {ϵ,10,1010,...},在这个基本结构之上,0的位置是任意的,因此也就变成了“ 10 10 10与 0 0 0的所有组合”,即 ( 0 ∣ 10 ) ∗ (0|10)^* (0∣10)∗。
- 习题:(选择/填空),课本 p64 8(1-4)
根据描述给出正规式
(1)以01结尾的二进制数串 5
(2)能被5整除的十进制整数 6
(3)包含奇数个1或奇数个0的二进制数串 7
(4)英文字母组成的所有符号串,要求符号串中的字母按照字典序排列 8
有限自动机(DFA、NFA)
DFA(确定的有限自动机)
-
五元组表示法
- M = ( S , Σ , f , S 0 , Z ) M=(S, \Sigma, f, S_0, Z) M=(S,Σ,f,S0,Z)
-
S
S
S是一个非空有限集,它的每个元素称为一个状态
-
Σ
Σ
Σ是一个有限的输入字母表,它的每个元素称为一个输入字符
- f是转换函数集,形如
f
(
k
i
,
a
)
=
k
j
(
k
i
∈
S
,
k
j
∈
S
,
a
∈
Σ
)
f(k_i,a)=k_j(k_i∈S, k_j∈S,a∈Σ)
f(ki,a)=kj(ki∈S,kj∈S,a∈Σ):当前状态为
k
i
k_i
ki,输入字符为a时,将转换到下一个状态
k
j
k_j
kj,
f
f
f值唯一
-
S
0
∈
S
S_0 ∈S
S0∈S是唯一的一个初始状态;
-
Z
⊆
S
Z\subseteq S
Z⊆S,是终止状态(终态)集合
- 注意:初始状态只有一个、终态可以多个、f值唯一
-
状态转换图表示法
-
状态矩阵表示法
矩阵的行表示当前状态,列表示输入字符,矩阵元素表示相应状态行和输入字符列下的新状态。
- 助解题目:五元组与状态转换图互换ppt 3.3 23页】
NFA(非确定的有限自动机)
-
五元组表示法
- M = ( S , Σ , f , S 0 , Z ) M=(S ,Σ,f,S_0,Z) M=(S,Σ,f,S0,Z)
-
S
,
Σ
,
Z
S,\Sigma,Z
S,Σ,Z的意义与DFA相同
-
f
f
f与DFA中
f
f
f的区别在于,对某个当前状态,对于输入字符a,可能有多个次态
- S 0 S_0 S0表示的是初态集合, S ⊂ 0 S\subset 0 S⊂0
- 注意:初始状态可以有多个、终态可以多个,f值不唯一
-
状态转换图表示法
-
状态矩阵表示法
NFA与DFA联系与区别
- 区别:
初态:DFA只有一个,NFA有多个
状态转换函数 f f f:DFA每个 f f f值唯一确定,NFA每个 f f f值可以有多个(次态集合)
有向弧:DFA中无 ϵ \epsilon ϵ弧,NFA中可能存在 ϵ \epsilon ϵ弧
- 联系:DFA是NFA的特例
NFA转DFA(NFA确定化)——子集构造法
-
NFA确定化:通过某些操作消除NFA中 f f f的多值性
-
必须掌握的三种运算,对于状态集 I I I
ε − c l o s u r e ( I ) ε-closure(I) ε−closure(I)——状态集的 ε ε ε闭包
m o v e ( I , a ) move(I, a) move(I,a)——状态集的 a a a弧转换
I a = ε − c l o s u r e ( m o v e ( I , a ) ) I_a = ε-closure( move(I, a) ) Ia=ε−closure(move(I,a))——状态集的 a a a弧转换的闭包 I a I_a Ia-
ε − c l o s u r e ( I ) ε-closure(I) ε−closure(I)
- 状态集
I
I
I中的每个元素经过
0
或
n
条
ϵ
弧
0或n条\epsilon弧
0或n条ϵ弧 能到达的所有状态的集合
- 注:经过0条 ϵ \epsilon ϵ弧所能到达的状态即自己本身
- 状态集
I
I
I中的每个元素经过
0
或
n
条
ϵ
弧
0或n条\epsilon弧
0或n条ϵ弧 能到达的所有状态的集合
-
m o v e ( I , a ) move(I, a) move(I,a)
- 状态集
I
I
I中的每个元素经过
1
条
a
弧
1条a弧
1条a弧 能到达的所有状态的集合
- 注意:仅经过1条a弧
- 状态集
I
I
I中的每个元素经过
1
条
a
弧
1条a弧
1条a弧 能到达的所有状态的集合
-
I a = ε − c l o s u r e ( m o v e ( I , a ) ) I_a = ε-closure( move(I, a) ) Ia=ε−closure(move(I,a))
- 先求 m o v e ( I , a ) move(I, a) move(I,a) , 记所得集合为 M M M
- 再求 ε − c l o s u r e ( M ) ε-closure(M) ε−closure(M)
-
习题:NFA的状态转换图如下,状态集 I = { 2 , 3 } I=\{2, 3\} I={2,3},求 ε − c l o s u r e ( I ) ε-closure(I) ε−closure(I)和 I 2 I_2 I2、 I 3 I_3 I3
- 【图】
- 答案9
-
-
方法论
-
核心:构造状态转换矩阵, 形如
I I I I a I_a Ia I b I_b Ib … T 0 T_0 T0 ε − c l o s u r e ( m o v e ( T 0 , a ) ) ε-closure( move(T_0, a) ) ε−closure(move(T0,a)) ε − c l o s u r e ( m o v e ( T 0 , a ) ) ε-closure( move(T_0, a) ) ε−closure(move(T0,a)) … T 1 T_1 T1 ε − c l o s u r e ( m o v e ( T 1 , a ) ) ε-closure( move(T_1, a) ) ε−closure(move(T1,a)) ε − c l o s u r e ( m o v e ( T 1 , a ) ) ε-closure( move(T_1, a) ) ε−closure(move(T1,a)) … … … … … -
( 1 ) (1) (1) T 0 = ε − c l o s u r e ( X ) T_0 = ε-closure( X ) T0=ε−closure(X), X X X是NFA的唯一初态。NFA的初态可能有多个,因此分以下两种情况讨论:
- NFA初态唯一,且为 S 0 S_0 S0, X = S 0 X = S_0 X=S0
- NFA初态不唯一,则构造一个新状态 X X X作为NFA的唯一初态,并通过一条 ϵ \epsilon ϵ弧指向初态集合 S 0 S_0 S0中的任意初态
- 若NFA终态不唯一,则构造一个新状态 Y Y Y作为NFA唯一终态,并将NFA中任意终态节点通过 ϵ \epsilon ϵ弧指向 Y Y Y
-
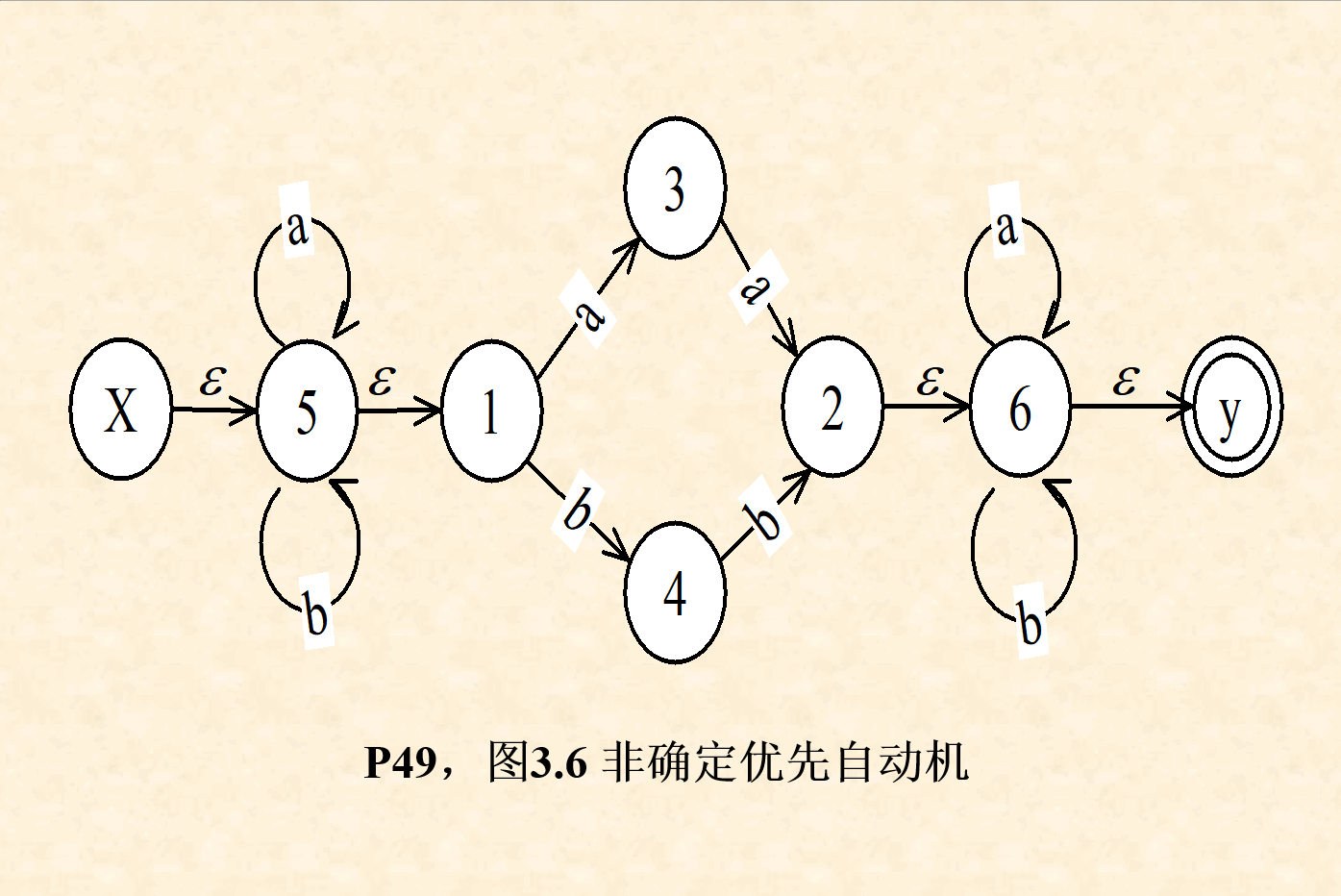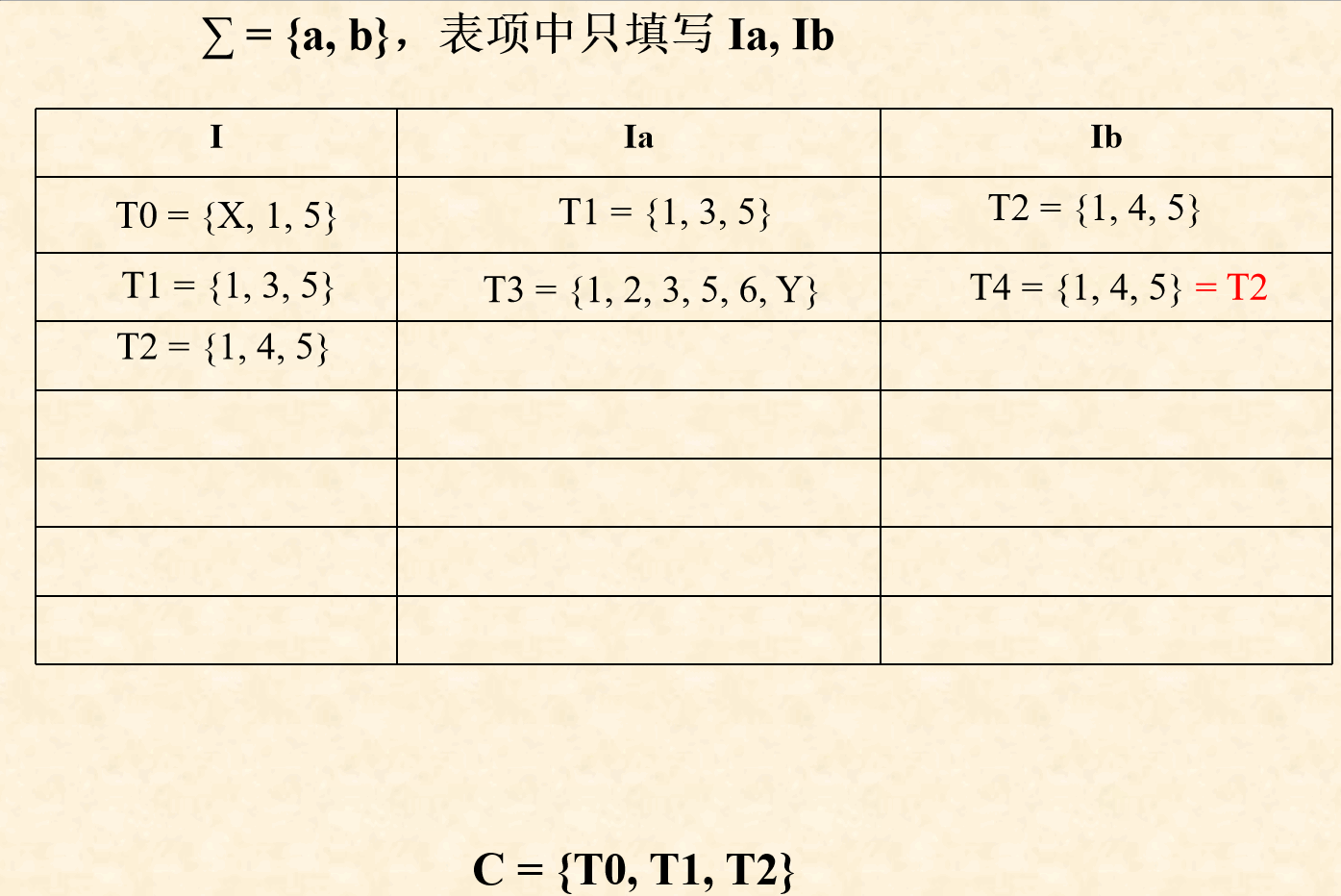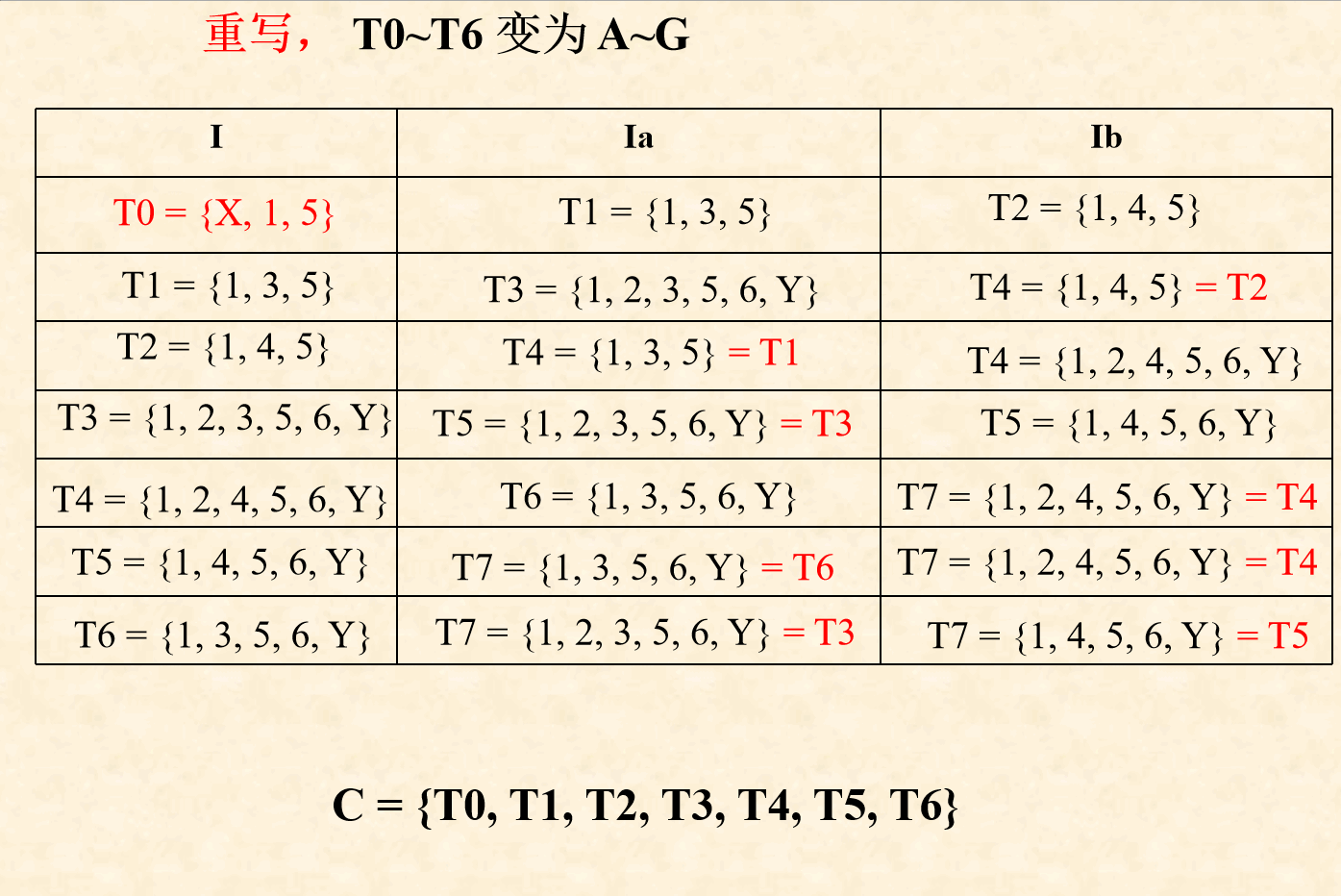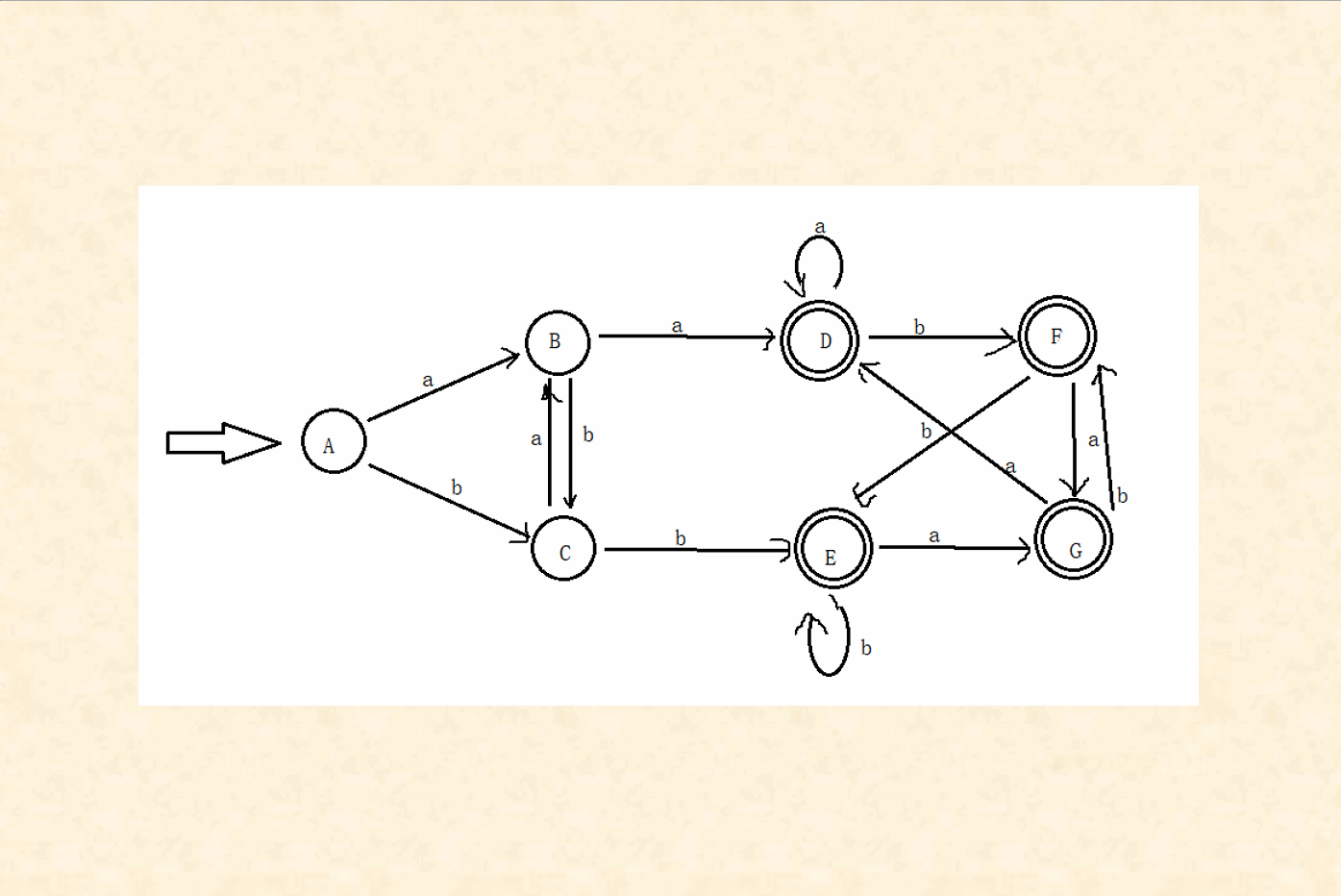
( 2 ) (2) (2)对NFA的状态转换图做如下等价变化:【图】【书p50】
-
( 3 ) (3) (3)用 C C C表示新状态集合,开始构造状态转换矩阵时, C = { T 0 } C = \{T_0\} C={T0}
-
( 4 ) (4) (4)根据上表构造状态转换矩阵,对每个 T j = ε − c l o s u r e ( m o v e ( T i , a ) ) T_j = ε-closure( move(T_i, a) ) Tj=ε−closure(move(Ti,a))
- 若 T j ∉ C T_j\notin C Tj∈/C,则 C = { T 0 , T j } C = \{T_0, T_j\} C={T0,Tj}, 且 T j T_j Tj作为新状态加入到状态转换矩阵的新行中
- 若 T j ∈ C T_j\in C Tj∈C,跳过
- 若 T j = ϕ T_j = \phi Tj=ϕ, T j T_j Tj不添加新行(原因: T j T_j Tj属于无关状态中的死状态,具体见DFA的化简)
-
( 5 ) (5) (5)记最后一个状态为 T n T_n Tn,对 T 0 ∼ T n T_0 \sim T_n T0∼Tn进行状态重命名,并根据新状态名称重写状态转换矩阵,重写规则如下
- 若 原初态 X ∈ T i 原初态X \in T_i 原初态X∈Ti, T i T_i Ti对应的新状态名就是新DFA的初态 S 0 S_0 S0
- 若 原终态 Y ∈ T i 原终态Y \in T_i 原终态Y∈Ti, T i T_i Ti对应的新状态名加入新DFA的终态集合 Z Z Z
- 对矩阵中的所有 T i T_i Ti都重命名后,所得的状态转换矩阵就是确定化后的DFA状态矩阵
- I I I表示当前状态s, I a I_a Ia表示输入字母为 a a a,矩阵 M [ s , i ] M[s,i] M[s,i]的值就是状态s下输入a的次态o
-
( 6 ) (6) (6)根据新状态转换矩阵画状态转换图,此时的状态转换图就是确定化之后的DFA图(未化简)
-
-
例题 ppt3.3-35(书p50 ex3.3 书图×,看ppt图)、 ppt3.3-37
【gif动图–NFA的确定化】
DFA的化简

综合题型 & 课后习题
- 给出文法求DFA(求NFA–>转DFA–>DFA化简)
- NFA与正规式的互换
左线性文法的状态转换图表示 ↩︎
()、|、*、·四种运算运算规则 ↩︎正规式等价&正规式等价变换 ↩︎
以01结尾的二进制数串: ( 0 ∣ 1 ) ∗ 01 (0|1)^*01 (0∣1)∗01 ↩︎
能被5整除的十进制整数: ( 1 ∣ 2 ∣ 3 ∣ 4 ∣ 5 ∣ 6 ∣ 7 ∣ 8 ∣ 9 ) ( 0 ∣ 1 ∣ 2 ∣ 3 ∣ 4 ∣ 5 ∣ 6 ∣ 7 ∣ 8 ∣ 9 ) ∗ ( 0 ∣ 5 ) (1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)^*(0|5) (1∣2∣3∣4∣5∣6∣7∣8∣9)(0∣1∣2∣3∣4∣5∣6∣7∣8∣9)∗(0∣5) ↩︎
包含奇数个1或奇数个0的二进制数串: ( 1 ∗ 0 ) ( 1 ∗ ∣ 0 1 ∗ 0 ) ∣ ( 0 ∗ 1 ) ( 0 ∗ ∣ 1 0 ∗ 1 ) (1^*0)(1^*|01^*0)|(0^*1)(0^*|10^*1) (1∗0)(1∗∣01∗0)∣(0∗1)(0∗∣10∗1)。解释:奇数个0与奇数个1的正规式类似,以求奇数个0为例,。。。。 ↩︎
英文字母组成的所有符号串,要求符号串中的字母按照字典序排列:以a~z为例: a ∗ b ∗ c ∗ . . . z ∗ a^*b^*c^*...z^* a∗b∗c∗...z∗ ↩︎
答案: ↩︎















 2305
2305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











