






3.1 DataFrame是什么
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。

使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行针对性的优化,最终达到大幅提升运行时效率。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
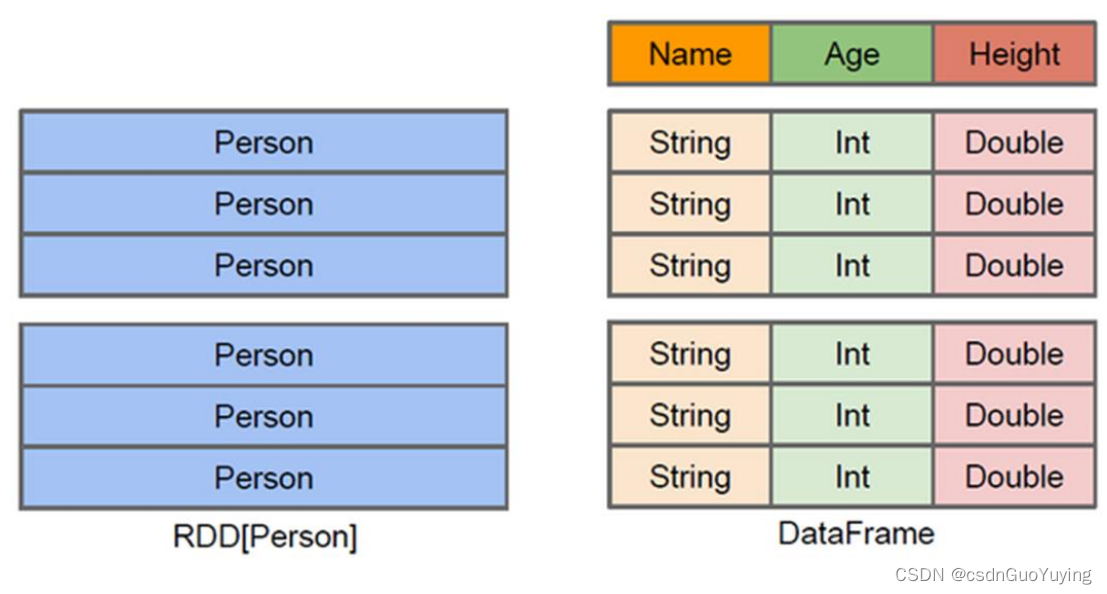
上图中左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。了解了这些信息之后,Spark SQL的查询优化器就可以进行针对性的优化。后者由于在编译期有详尽的类型信息,编译期就可以编译出更加有针对性、更加优化的可执行代码。
官方定义:
- Dataset:A DataSet is a distributed collection of data. (分布式的数据集)
- DataFrame: A DataFrame is a DataSet organized into named columns.(以列(列名,列类型,列值)的形式构成的分布式的数据集,按照列赋予不同的名称)
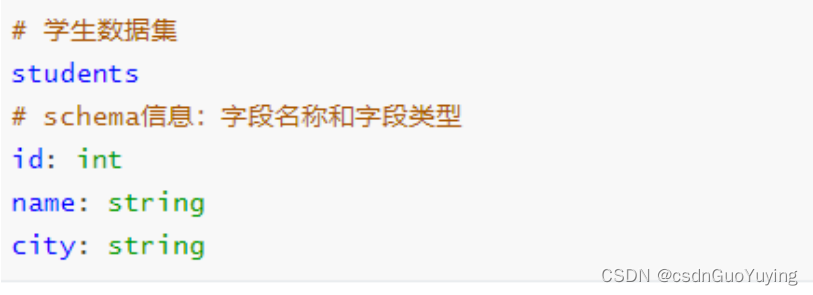
DataFrame有如下特性:
1)、分布式的数据集,并且以列的方式组合的,相当于具有schema的RDD;
2)、相当于关系型数据库中的表,但是底层有优化;
3)、提供了一些抽象的操作,如select、filter、aggregation、plot;
4)、它是由于R语言或者Pandas语言处理小数据集的经验应用到处理分布式大数据集上;
5)、在1.3版本之前,叫SchemaRDD;
范例演示:加载json格式数据
第一步、上传官方测试数据$SPARK_HOME/examples/src/main/resources至HDFS目录/datas

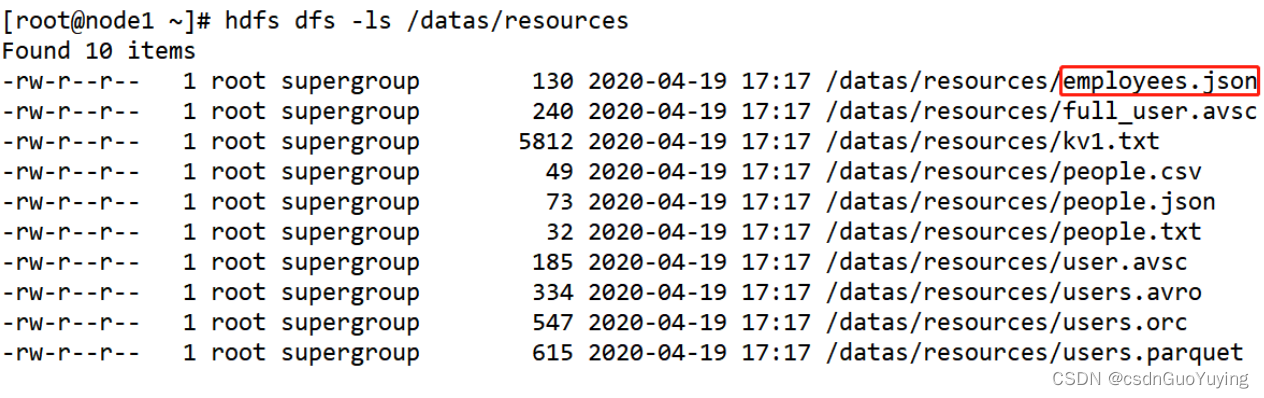
查看HDFS上数据文件,其中雇员信息数据【employees.json】
第二步、启动spark-shell命令行,采用本地模式localmode运行

第三步、读取雇员信息数据

3.2 Schema 信息
查看DataFrame中Schema是什么,执行如下命令:

可以看出Schema信息封装在StructType中,包含很多StructField对象,查看源码。
-
其一、StructType 定义,是一个样例类,属性为StructField的数组

-
其二、StructField 定义,同样是一个样例类,有四个属性,其中字段名称和类型为必填

自定义Schema结构,官方提供实例代码:

















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











