






6.3 parquet 数据
SparkSQL模块中默认读取数据文件格式就是parquet列式存储数据,通过参数【spark.sql.sources.default】设置,默认值为【parquet】。
范例演示代码:直接load加载parquet数据和指定parquet格式加载数据
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* SparkSQL读取Parquet列式存储数据
*/
object SparkSQLParquet {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// TODO: 从LocalFS上读取parquet格式数据
val usersDF: DataFrame = spark.read.parquet("datas/resources/users.parquet")
usersDF.printSchema()
usersDF.show(10, truncate = false)
println("==================================================")
// SparkSQL默认读取文件格式为parquet
val df = spark.read.load("datas/resources/users.parquet")
df.printSchema()
df.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
运行程序结果:

6.4 text 数据
SparkSession加载文本文件数据,提供两种方法,返回值分别为DataFrame和Dataset,前面【入门案例:词频统计WordCount】中已经使用,下面看一下方法声明:

可以看出textFile方法底层还是调用text方法,先加载数据封装到DataFrame中,再使用as[String]方法将DataFrame转换为Dataset,实际项目中推荐使用textFile方法,从Spark 2.0开始提供。
无论是text方法还是textFile方法读取文本数据时,一行一行的加载数据,每行数据使用UTF-8编码的字符串,列名称为【value】。
范例演示:分别使用text和textFile方法加载数据。
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* SparkSQL加载文本文件数据,方法text和textFile
*/
object SparkSQLText {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate() // 底层实现:单例模式,创建SparkContext对象
import spark.implicits._
// TODO: text方法加载数据,封装至DataFrame中
val dataframe: DataFrame = spark.read.text("datas/resources/people.txt")
dataframe.printSchema()
dataframe.show(10, truncate = false)
println("=================================================")
val dataset: Dataset[String] = spark.read.textFile("datas/resources/people.txt")
dataset.printSchema()
dataset.show(10, truncate = false)
spark.stop()// 应用结束,关闭资源
}
}
6.5 json 数据
实际项目中,有时处理数据以JSON格式存储的,尤其后续结构化流式模块:StructuredStreaming,从Kafka Topic消费数据很多时间是JSON个数据,封装到DataFrame中,需要解析提取字段的值。以读取github操作日志JSON数据为例,数据结构如下:
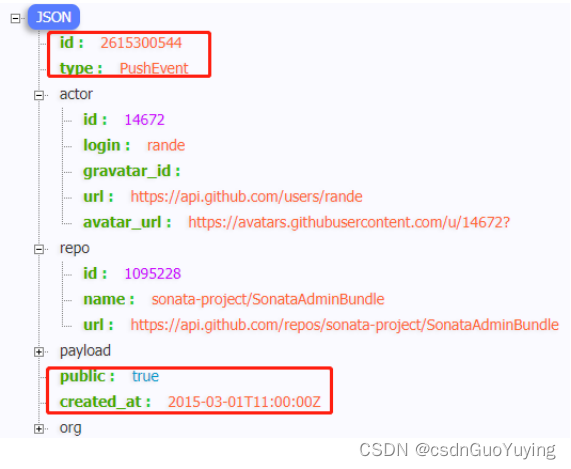
1)、操作日志数据使用GZ压缩:2015-03-01-11.json.gz,先使用json方法读取。
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 底层实现:单例模式,创建SparkContext对象
.getOrCreate()
import spark.implicits._
// TODO: 从LocalFS上读取json格式数据(压缩)
val jsonDF: DataFrame = spark.read.json("datas/json/2015-03-01-11.json.gz")
jsonDF.printSchema()
jsonDF.show(10, truncate = true)
2)、使用textFile加载数据,对每条JSON格式字符串数据,使用SparkSQL函数库functions中自带get_json_obejct函数提取字段:id、type、public和created_at的值。
-
函数:get_json_obejct使用说明

-
核心代码
val githubDS: Dataset[String] = spark.read.textFile("datas/json/2015-03-01-11.json.gz")
githubDS.printSchema() // value 字段名称,类型就是String
githubDS.show(1)
// TODO:使用SparkSQL自带函数,针对JSON格式数据解析的函数
import org.apache.spark.sql.functions._
// 获取如下四个字段的值:id、type、public和created_at
val gitDF: DataFrame = githubDS.select(
get_json_object($"value", "$.id").as("id"),
get_json_object($"value", "$.type").as("type"),
get_json_object($"value", "$.public").as("public"),
get_json_object($"value", "$.created_at").as("created_at")
)
gitDF.printSchema()
gitDF.show(10, truncate = false)
运行结果:
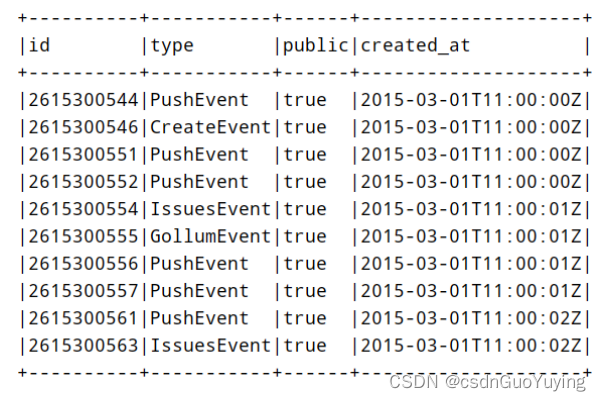
范例演示完整代码:
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* SparkSQL读取JSON格式文本数据
*/
object SparkSQLJson {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 底层实现:单例模式,创建SparkContext对象
.getOrCreate()
import spark.implicits._
// TODO: 从LocalFS上读取json格式数据(压缩)
val jsonDF: DataFrame = spark.read.json("datas/json/2015-03-01-11.json.gz")
jsonDF.printSchema()
jsonDF.show(10, truncate = true)
println("===================================================")
val githubDS: Dataset[String] = spark.read.textFile("datas/json/2015-03-01-11.json.gz")
githubDS.printSchema() // value 字段名称,类型就是String
githubDS.show(1)
// TODO:使用SparkSQL自带函数,针对JSON格式数据解析的函数
import org.apache.spark.sql.functions._
// 获取如下四个字段的值:id、type、public和created_at
val gitDF: DataFrame = githubDS.select(
get_json_object($"value", "$.id").as("id"),
get_json_object($"value", "$.type").as("type"),
get_json_object($"value", "$.public").as("public"),
get_json_object($"value", "$.created_at").as("created_at")
)
gitDF.printSchema()
gitDF.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
6.6 csv 数据
在机器学习中,常常使用的数据存储在csv/tsv文件格式中,所以SparkSQL中也支持直接读取格式数据,从2.0版本开始内置数据源。关于CSV/TSV格式数据说明:

SparkSQL中读取CSV格式数据,可以设置一些选项,重点选项:
1)、分隔符:sep
- 默认值为逗号,必须单个字符
2)、数据文件首行是否是列名称:header - 默认值为false,如果数据文件首行是列名称,设置为true
3)、是否自动推断每个列的数据类型:inferSchema - 默认值为false,可以设置为true
官方提供案例:

当读取CSV/TSV格式数据文件首行是否是列名称,读取数据方式(参数设置)不一样的 。
第一点:首行是列的名称,如下方式读取数据文件
// TODO: 读取TSV格式数据
val ratingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 设置数据文件首行为列名称,默认值为 false
.option("header", "true")
// 自动推荐数据类型,默认值为false
.option("inferSchema", "true")
// 指定文件的路径
.csv("datas/ml-100k/u.dat")
ratingsDF.printSchema()
ratingsDF.show(10, truncate = false)
第二点:首行不是列的名称,如下方式读取数据(设置Schema信息)
// 定义Schema信息
val schema = StructType(
StructField("user_id", IntegerType, nullable = true) ::
StructField("movie_id", IntegerType, nullable = true) ::
StructField("rating", DoubleType, nullable = true) ::
StructField("timestamp", StringType, nullable = true) :: Nil
)
// TODO: 读取TSV格式数据
val mlRatingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 指定Schema信息
.schema(schema)
// 指定文件的路径
.csv("datas/ml-100k/u.data")
mlRatingsDF.printSchema()
mlRatingsDF.show(5, truncate = false)
将DataFrame数据保存至CSV格式文件,演示代码如下:
/**
* 将电影评分数据保存为CSV格式数据
*/
mlRatingsDF
// 降低分区数,此处设置为1,将所有数据保存到一个文件中
.coalesce(1)
.write
// 设置保存模式,依据实际业务场景选择,此处为覆写
.mode(SaveMode.Overwrite)
.option("sep", ",")
// TODO: 建议设置首行为列名
.option("header", "true")
.csv("datas/ml-csv-" + System.nanoTime())
范例演示完整代码SparkSQLCsv.scala如下:
import org.apache.spark.SparkContext
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* SparkSQL 读取CSV/TSV格式数据:
* i). 指定Schema信息
* ii). 是否有header设置
*/
object SparkSQLCsv {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(SparkSQLCsv.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
import spark.implicits._
// 获取SparkContext实例对象
val sc: SparkContext = spark.sparkContext
/**
* 实际企业数据分析中
* csv\tsv格式数据,每个文件的第一行(head, 首行),字段的名称(列名)
*/
// TODO: 读取TSV格式数据
val ratingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 设置数据文件首行为列名称,默认值为 false
.option("header", "true")
// 自动推荐数据类型,默认值为false
.option("inferSchema", "true")
// 指定文件的路径
.csv("datas/ml-100k/u.dat")
ratingsDF.printSchema()
ratingsDF.show(10, truncate = false)
println("=======================================================")
// 定义Schema信息
val schema = StructType(
StructField("user_id", IntegerType, nullable = true) ::
StructField("movie_id", IntegerType, nullable = true) ::
StructField("rating", DoubleType, nullable = true) ::
StructField("timestamp", StringType, nullable = true) :: Nil
)
// TODO: 读取TSV格式数据
val mlRatingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 指定Schema信息
.schema(schema)
// 指定文件的路径
.csv("datas/ml-100k/u.data")
mlRatingsDF.printSchema()
mlRatingsDF.show(5, truncate = false)
println("=======================================================")
/**
* 将电影评分数据保存为CSV格式数据
*/
mlRatingsDF
// 降低分区数,此处设置为1,将所有数据保存到一个文件中
.coalesce(1)
.write
// 设置保存模式,依据实际业务场景选择,此处为覆写
.mode(SaveMode.Overwrite)
.option("sep", ",")
// TODO: 建议设置首行为列名
.option("header", "true")
.csv("datas/ml-csv-" + System.nanoTime())
// 关闭资源
spark.stop()
}
}















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











