






Direct 方式集成底层原理
SparkStreaming集成Kafka采用Direct方式消费数据,如下三个方面优势:
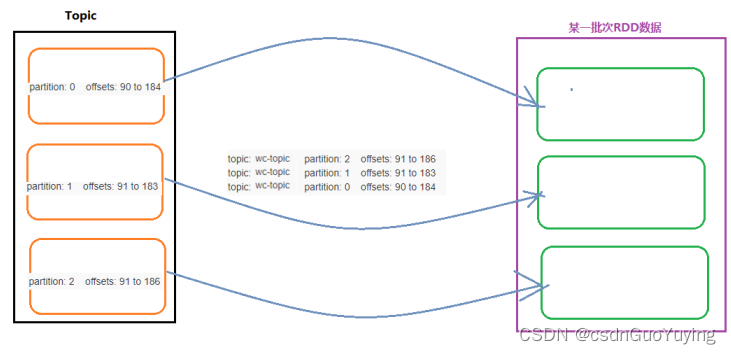
第一、简单的并行度(Simplified Parallelism)
- 读取topics的总的分区数目 = 每批次RDD中分区数目;
- topic中每个分区数据 被读取到 RDD中每个分区进行处理
第二、高效(Efficiency)
- 处理数据比使用Receiver接收数据高效很多
- 使用Receiver接收数据的时候,要将数据存储到Executor、为了可靠性还需要将数据存储文件系统中WAL
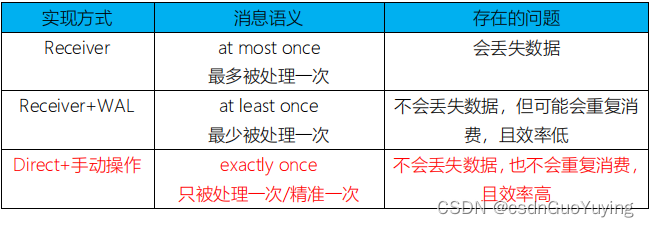
第三、Exactly-once semantics
- 能保证一次性语义,从Kafka消费数据仅仅被消费一次,不会重复消费或者不消费
- 在Streaming数据处理分析中,需要考虑数据是否被处理及被处理次数,称为消费语义
- At most once:最多一次,比如从Kafka Topic读取数据最多消费一次,可能出现不消费,此时数据丢失;
- At least once:至少一次,比如从Kafka Topic读取数据至少消费一次,可能出现多次消费数据;
- Exactly once:精确一次,比如从Kafka topic读取数据当且仅当消费一次,不多不少,最好的状态
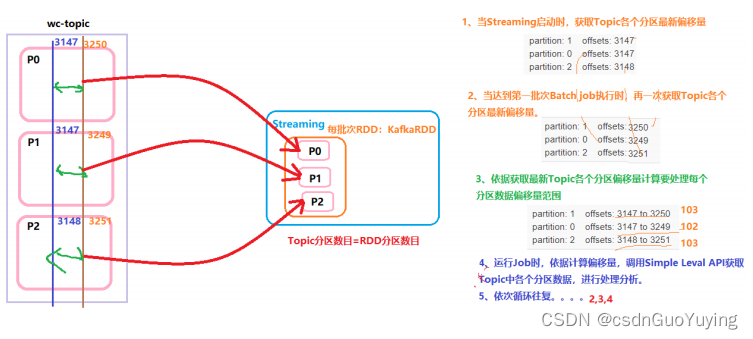
深入剖析SparkStreaming采用Direct方式消费Kafka数据,底层原理:
官方:this approach periodically queries Kafka for the latest offsets in each topic+partition, and accordingly
defines the offset ranges to process in each batch. When the jobs to process the data are launched, Kafka’s
simple consumer API is used to read the defined ranges of offsets from Kafka (similar to read files from
a file system).
示意图如下:
采用Direct方式消费数据时,需要设置每批次处理数据的最大量,防止【波峰】时数据太多,导致批次数据处理有性能问题:
- 参数:spark.streaming.kafka.maxRatePerPartition
- 含义:Topic中每个分区每秒中消费数据的最大值
- 举例说明:
- BatchInterval:5s、Topic-Partition:3、maxRatePerPartition: 10000
- 最大消费数据量:10000 * 3 * 5 = 150000 条
4.3 集成Kafka 0.10.x
使用Kafka 0.10.+提供新版本Consumer API集成Streaming,实时消费Topic数据,进行处理。
文档:http://spark.apache.org/docs/2.2.0/streaming-kafka-0-10-integration.html
添加相关Maven依赖:
<!-- Spark Streaming 与Kafka 0.10.0 集成依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
目前企业中基本都使用New Consumer API集成,优势如下:
第一、类似 Old Consumer API中Direct方式
- 直接到Kafka Topic中依据偏移量范围获取数据,进行处理分析;
- The Spark Streaming integration for Kafka 0.10 is similar in design to the 0.8 Direct Stream approach;
第二、简单并行度1:1
- 每批次中RDD的分区与Topic分区一对一关系;
- It provides simple parallelism, 1:1 correspondence between Kafka partitions and Spark partitions, and access to offsets and metadata;
- 获取Topic中数据的同时,还可以获取偏移量和元数据信息;
工具类KafkaUtils中createDirectStream函数API使用说明(函数声明):

具体演示案例代码如下:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Streaming通过Kafka New Consumer消费者API获取数据
*/
object StreamingSourceKafka {
def main(args: Array[String]): Unit = {
// 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// TODO: 2. 读取Kafka Topic中数据
/*
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]]
*/
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
/*
def Subscribe[K, V](
topics: ju.Collection[jl.String],
kafkaParams: ju.Map[String, Object]
): ConsumerStrategy[K, V]
*/
// ii.读取哪些Topic数据
val topics = Array("wc-topic")
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group_id_streaming_0001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v.采用新消费者API获取数据,类似于Direct方式
val kafkaDStream: DStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = kafkaDStream.transform(kafkaRDD => {
val resultRDD: RDD[(String, Int)] = kafkaRDD
.map(record => record.value()) // 获取Message数据
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD
})
// 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.foreachRDD{ (rdd, time) =>
val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO: 先判断RDD是否有数据,有数据在输出哦
if(!rdd.isEmpty()){
rdd
// 对于结果RDD输出,需要考虑降低分区数目
.coalesce(1)
// 对分区数据操作
.foreachPartition{iter =>iter.foreach(item => println(item))}
}
}
// 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











