






1. 开宗明义
当我们在谈数据分析的时候我们在谈什么?
当我们在谈数据分析的时候,我们通常在探讨如何利用数据挖掘、统计分析、机器学习等方法从原始数据中获取有意义的信息和洞见。这个过程可以帮助我们更好地理解和解决实际问题,如商业、金融、医疗、社交媒体等领域的问题。
不同的人对数据分析可能有不同的看法。
例如,对于一些业务人员和经理人来说,数据分析是一种工具,可以帮助他们更好地了解客户需求、市场趋势和业务运营情况,以便做出更好的决策。
对于数据科学家和工程师来说,数据分析则是一种技术,需要掌握各种数据处理、统计分析和机器学习算法等技能,以便从数据中发现有用的信息。
无论怎样,数据分析都是一种有用的工具和技术,可以帮助我们更好地理解和解决实际问题。
通过数据分析,我们可以从数据中发现模式和关系,预测未来的趋势和结果,并为业务决策提供更准确和有力的支持。
总结一下
我们是为了我们的目标然后进行分析,然后为我们的决策做出支持。
2. 通用分析框架
2.1 图例:
下面我想用一张图来描述数据分析的一个通用过程:
结合开篇所说的,在进行数据分析之前,首先需要对需要分析的问题进行理解和定义。也就是下图:

2.2 具体过程
- 确定问题:确定要解决的问题,例如“公司销售额下降的原因是什么?”。
- 收集背景信息:收集有关问题的背景信息,例如公司的历史数据、市场趋势等。
- 明确假设:明确问题的假设,例如“销售额下降是由于市场竞争加剧和产品质量不佳所致”。
- 确定数据需求:确定需要分析的数据类型和数据源,例如公司销售数据、客户调查数据等。
- 收集数据:收集需要分析的数据,并对数据进行清洗和预处理。
- 进行数据分析:使用适当的数据分析技术,如统计分析、机器学习等,对数据进行分析。
- 数据可视化:使用数据可视化技术,如散点图、柱状图等,将分析结果可视化,以帮助理解和解释结果。
- 验证假设:根据分析结果,验证问题的假设是否成立。
- 得出结论:根据分析结果和验证结果,得出对问题的结论,如“销售额下降主要是由于产品质量不佳所致”。
- 提出建议:根据结论,提出针对问题的解决方案和建议。
3. 使用python进行介入分析
接下来才是关于python进行数据分析的过程。我将分步骤说明:
获取数据
一般来说,这个是由爬虫工程师之类的获取,如果你们没有其他人,可能就需要自己干了。
- 使用爬虫进行获取,比如使用 scrapy 框架。
- 从文件系统中读取 CSV、Excel 或 JSON 文件中的数据。使用pandas。
- 从 Web API 或第三方数据源中获取数据,使用requests。
数据清洗和预处理
原始数据一般会有一些问题,不能直接应用,所以一般需要进行
- 删除重复的行或列。
- 转换数据类型,例如将文本类型转换为数字类型。
- 处理缺失值,例如使用均值、中位数或插值法进行填充。
下面举一个例子,假设你有一个包含学生姓名、年龄和成绩的 CSV 文件,但该文件包含一些缺失值和错误值,需要进行清洗和预处理,以便在数据分析和可视化之前使用。
下面是一些可能的数据清洗和预处理步骤:
- 读取 CSV 文件,并将其转换为 Pandas DataFrame 对象。
import pandas as pd
df = df.dropna() # 删除 NaN 值df = df[df[‘age’] > 0] # 删除年龄为负数的行
- 将文本类型转换为数字类型,例如将成绩从字符串类型转换为浮点数类型。
df[‘score’] = pd.to_numeric(df[‘score’], errors=‘coerce’)
df = df.drop_duplicates() # 删除重复的行df = df.drop_duplicates(subset=[‘name’]) # 根据学生姓名删除重复的行
- 对数据进行格式化和转换,以便后续的数据分析和可视化。
df[‘age’] = df[‘age’].astype(int) # 将年龄从浮点数类型转换为整数类型
数据分析
- 分组和聚合数据,例如计算平均值、中位数或总和。
- 统计分析数据,例如计算方差、标准差或相关系数。
- 使用机器学习算法对数据进行建模和预测。
假设你有一个包含学生姓名、年龄和成绩的 Pandas DataFrame 对象,你需要使用 Python 进行一些基本的数据分析,例如计算平均成绩和成绩的标准差等。
下面是一些可能的数据分析步骤:
- 计算平均成绩,例如使用 Pandas 中的 mean() 函数计算平均值。
mean_score = df[‘score’].mean()
std_score = df[‘score’].std()
- 计算成绩的分布情况,例如使用 Pandas 中的 hist() 函数绘制成绩的直方图。
import matplotlib.pyplot as plt
例如,可以按照年龄分组,计算每个年龄段的平均成绩:
df.groupby(‘age’)[‘score’].mean()
例如,可以将学生成绩数据和学生基本信息数据进行合并:
student_info = pd.read_csv(‘student_info.csv’)
数据可视化
- 使用散点图、线图或柱状图等可视化工具,展示数据的分布和趋势。
- 使用热图、等高线图或地图等可视化工具,展示数据的空间分布和变化。
- 使用交互式可视化工具,例如 Plotly、Bokeh 或 Dash,streamlit 等,增强数据可视化效果。
我的偏好是使用 streamlit 非常好用,而且可以进行交互。
下面举一个例子,用于说明 Python 数据分析流程中的数据可视化步骤,并展示如何使用 Streamlit 来进行可视化。
假设你有一个包含学生姓名、年龄和成绩的 Pandas DataFrame 对象,你需要使用 Python 进行数据可视化,例如展示成绩的分布情况和不同年龄段的平均成绩。
以下是使用 Streamlit 创建数据可视化应用程序的示例代码:
import streamlit as st
# 读取数据df = pd.read_csv(‘students.csv’)
# 计算不同年龄段的平均成绩age_mean_score = df.groupby(‘age’)[‘score’].mean()
机器学习
- 使用 Scikit-learn 库实现监督学习算法,例如线性回归、决策树或支持向量机。
- 使用 Keras 或 TensorFlow 库实现深度学习算法,例如神经网络、卷积神经网络或循环神经网络。
- 使用聚类算法或降维算法,例如 K-Means、PCA 或 t-SNE 等。
最后
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
如果需要可以点击链接免费领取或者滑到最后扫描二v码
👉[CSDN大礼包:《python学习路线&全套学习资料》免费分享](安全链接,放心点击)
👉Python学习大纲👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末


👉Python书籍和视频合集👈

👉Python面试刷题👈

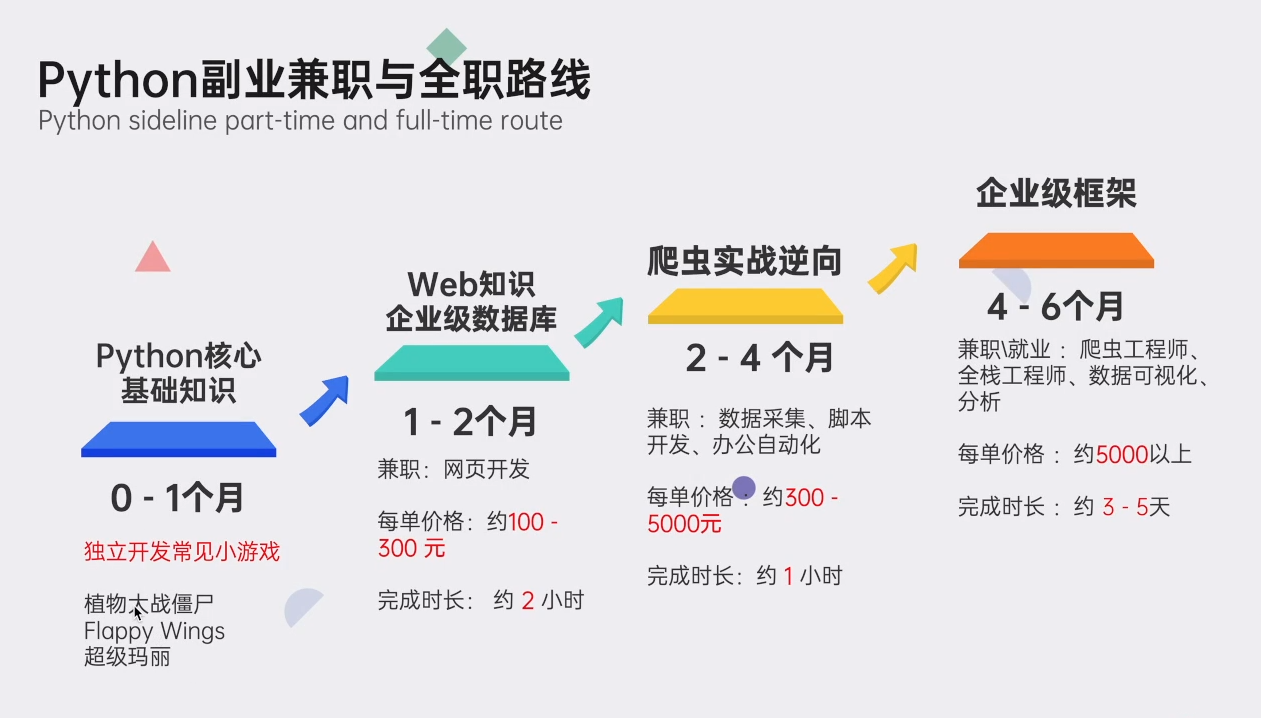
👉Python副业兼职路线👈
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以点击链接免费领取或者保存图片到wx扫描二v码免费领取 【保证100%免费】
👉[CSDN大礼包:《python学习路线&全套学习资料》免费分享](安全链接,放心点击)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









