






爬虫的介绍以及原理等等七七八八的东西我就不多bb了,咱们直接上教程。本案例我就以 彼岸图网 这个网站做教程,原网址下方链接
【文末有读者福利】
https://pic.netbian.com/
首先打开网站
可以看到有很多好看的图片,一页总共21张图片:

彼岸图网首页
我们右键选择检查或者直接按F12来到控制台
点击左上角的箭头或者快捷键ctrl+shift+c,然后随便点在一张图片上面
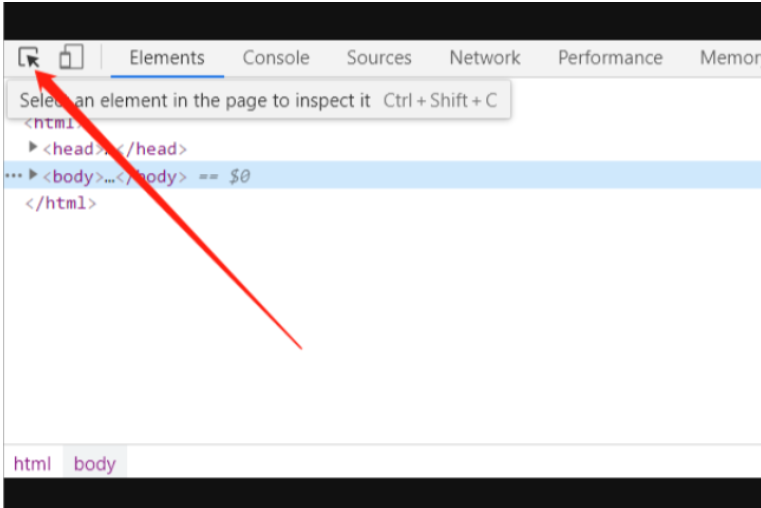
随便点击一张图片
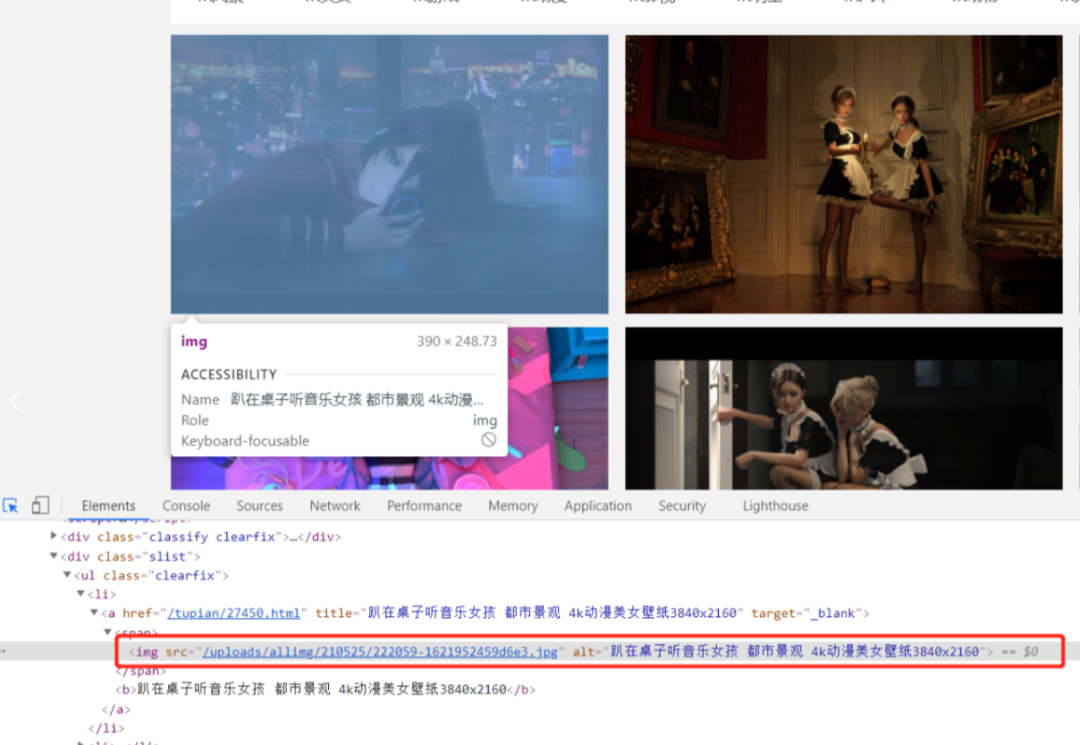
选择一张图片查看html
这时候我们就能看到这张图片的详细信息,src后面的链接就是图片的链接,将鼠标放到链接上就能看到图片,这就是我们这次要爬的
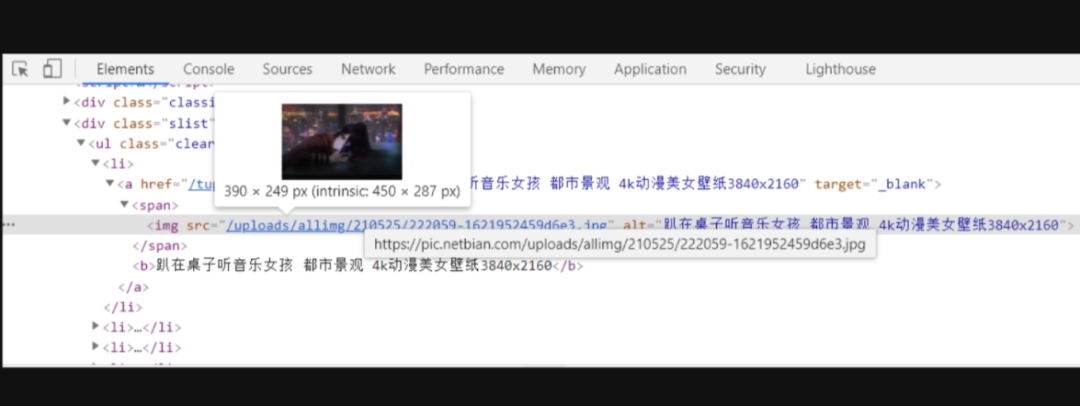
图片的url
一、导入相关库(requests库)
import requests
requests翻译过来就是请求的意思,用来向某一网站发送请求。这是Python的一个库。如果没有安装过,可以使用下面的命令安装:
pip install requests
二、相关的参数(url,headers)
我们回到刚刚的控制台,点击上方的Network,按下ctrl+r刷新,随便点开一张图片:
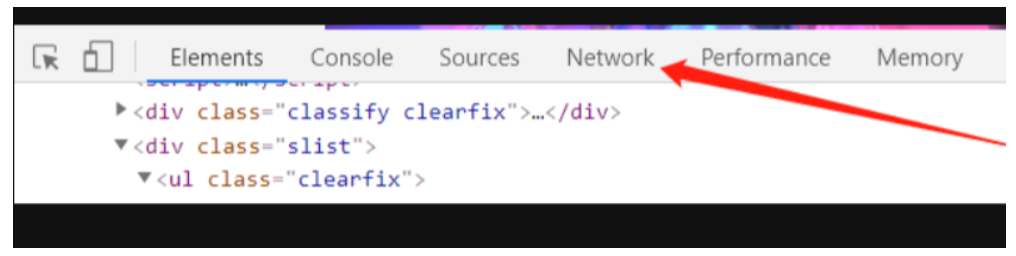
控制台的网络
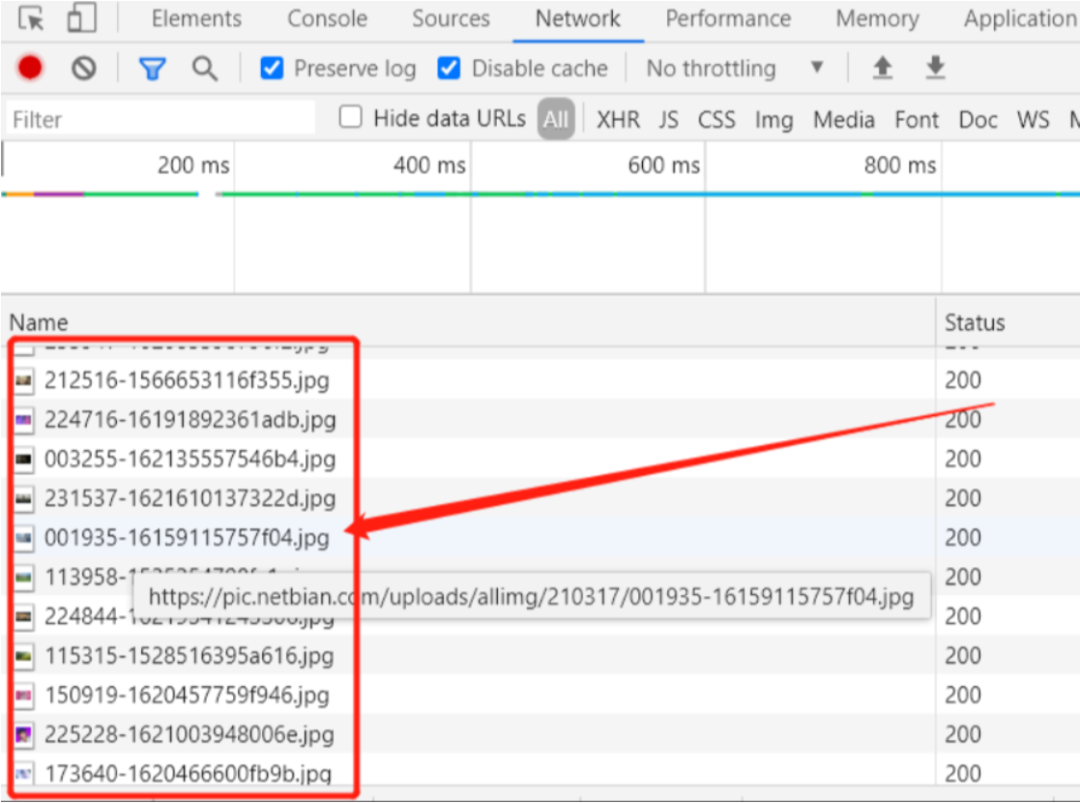
查看里面的信息
这里我们只需要到两个简单的参数,本次案例只是做一个简单的爬虫教程,其他参数暂时不考虑:
| 参数 | 作用 |
|---|---|
| Request URL | 发送请求的网站地址,也就是图片所在的网址 |
| user-agent | 用来模拟浏览器对网站进行访问,避免被网站监测出非法访问 |
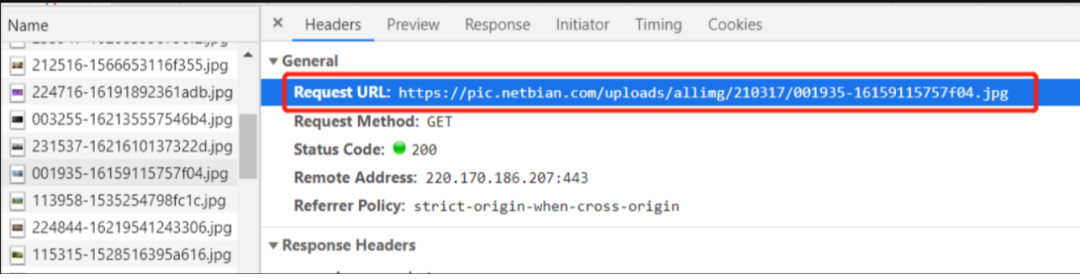
Request URL
参数代码的准备:
url = "https://pic.netbian.com/uploads/allimg/210317/001935-16159115757f04.jpg"headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"}
三、向网站发出请求
response = requests.get(url=url,headers=headers)print(response.text) # 打印请求成功的网页源码,和在网页右键查看源代码的内容一样的
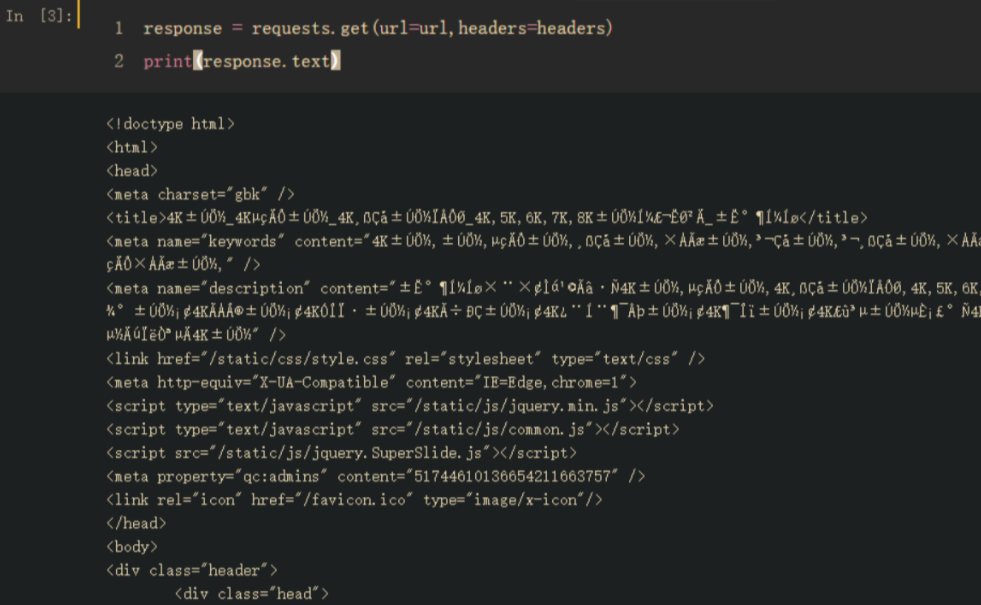
查看回应
这时候我们会发现乱码?!!!!这其实也是很多初学者头疼的事情,乱码解决不难
# 通过发送请求成功response,通过(apparent_encoding)获取该网页的编码格式,并对response解码response.encoding = response.apparent_encodingprint(response.text)
看着这些密密麻麻的一大片是不是感觉脑子要炸了,其实我们只需要找到我们所需要的就可以了
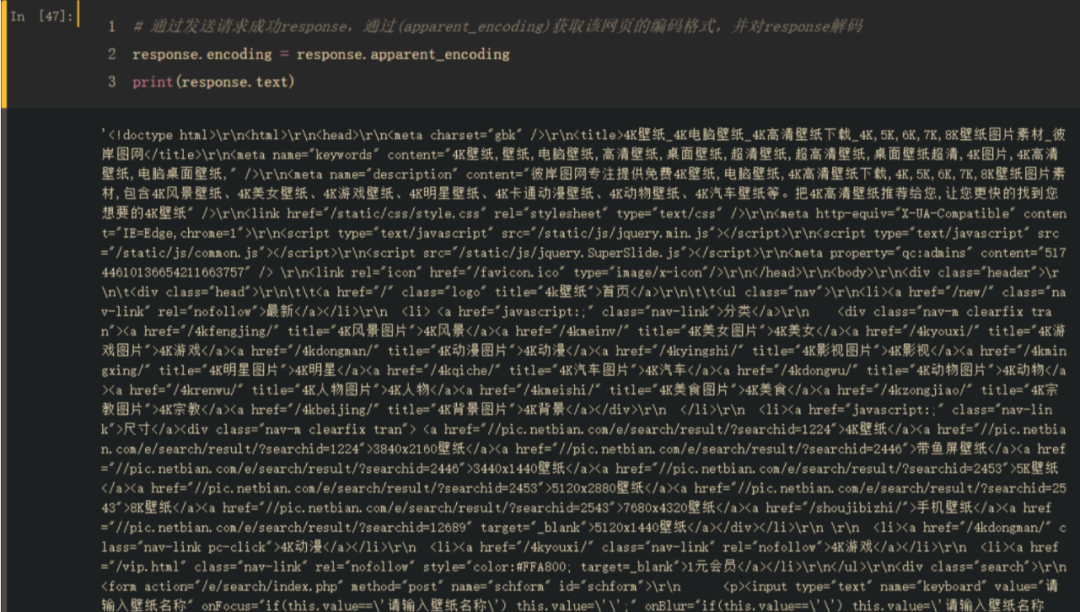
网站信息
四、匹配(re库,正则表达式)
什么是正则表达式?简单点说就是由用户制定一个规则,然后代码根据我们指定的所规则去指定内容里匹配出正确的内容
我们在前面的时候有看到图片信息是什么样子的,根据信息我们可以快速找到我们要的
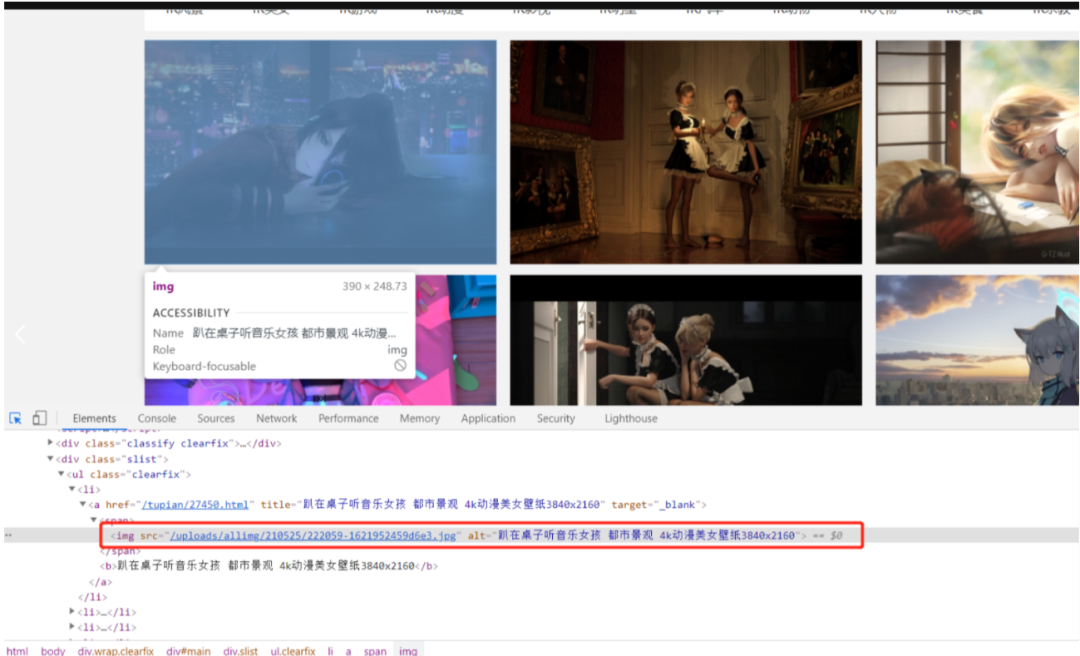
正则化
接下来就是通过正则表达式把一个个图片的链接和名字给匹配出来,存放到一个列表中:
import re""". 表示除空格外任意字符(除\n外)* 表示匹配字符零次或多次? 表示匹配字符零次或一次.*? 非贪婪匹配"""# src后面存放的是链接,alt后面是图片的名字# 直接(.*?)也是可以可以直接获取到链接,但是会匹配到其他不是我们想要的图片# 我们可以在前面图片信息看到链接都是/u····开头的,所以我们就设定限定条件(/u.*?)这样就能匹配到我们想要的parr = re.compile('src="(/u.*?)".alt="(.*?)"')image = re.findall(parr,response.text)for content in image: print(content)
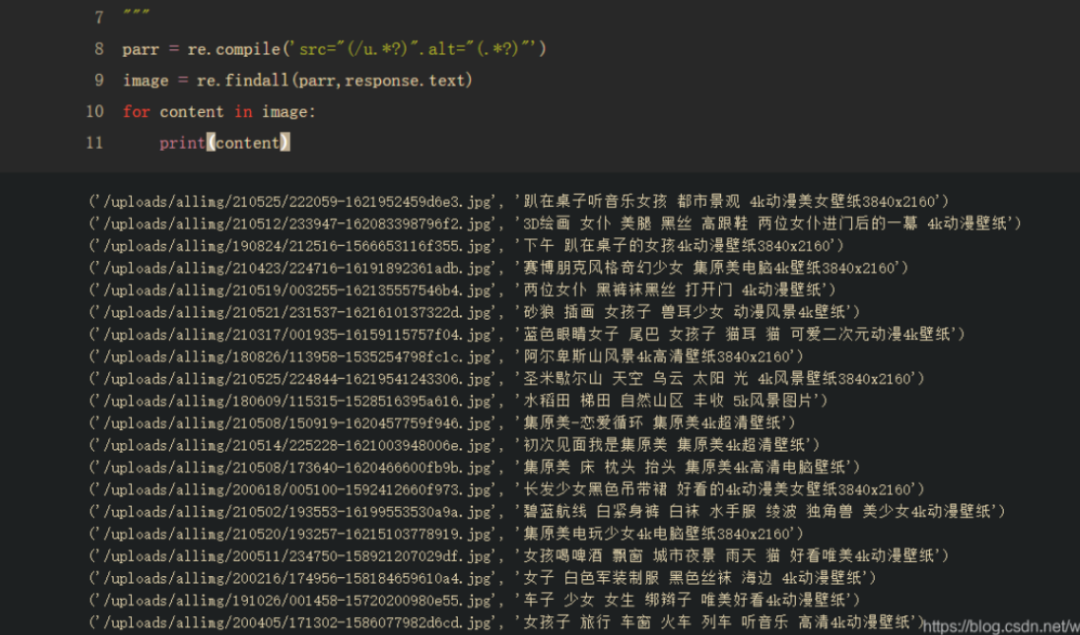
成功爬取
image[0]:列表第一个元素,也就是链接和图片 image[0][0]:列表第一个元素中的第一个值,也就是链接 image[0][1]:列表第一个元素中的第二个值,也就是名字
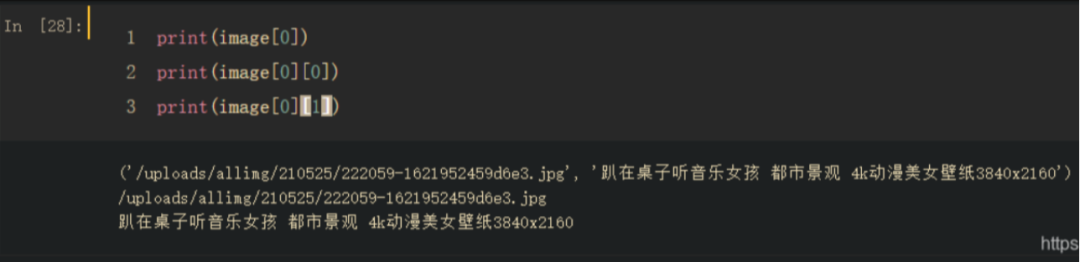
检查正则化的东西
五、获取图片,保存到文件夹中(os库)
首先通过os库创建一个文件夹(当前你也可以手动在脚本目录创建一个文件夹)
import ospath = "彼岸图网图片获取"if not os.path.isdir(path): ok.mkdir(path)
然后对列表进行遍历,获取图片:
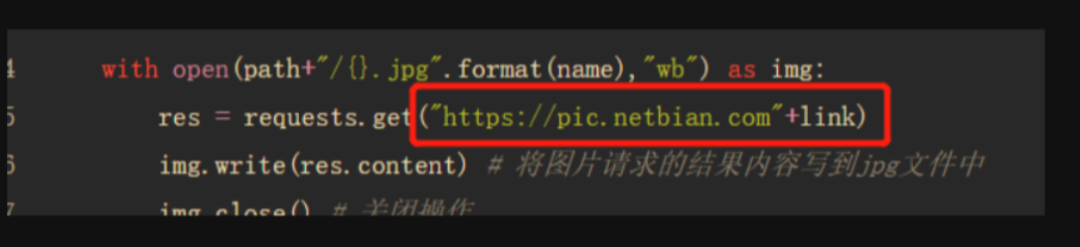
# 对列表进行遍历for i in image: link = i[0] # 获取链接 name = i[1] # 获取名字 """ 在文件夹下创建一个空jpg文件,打开方式以 'wb' 二进制读写方式 @param res:图片请求的结果 """ with open(path+"/{}.jpg".format(name),"wb") as img: res = requests.get(link) img.write(res.content) # 将图片请求的结果内容写到jpg文件中 img.close() # 关闭操作 print(name+".jpg 获取成功······")
运行我们就会发现报错了,这是因为我们的图片链接不完整所导致的:

网址不完整
我们回到图片首页网站,点开一张图片,我们可以在地址栏看到我们的图片链接缺少前面部分,我们复制下来 https://pic.netbian.com
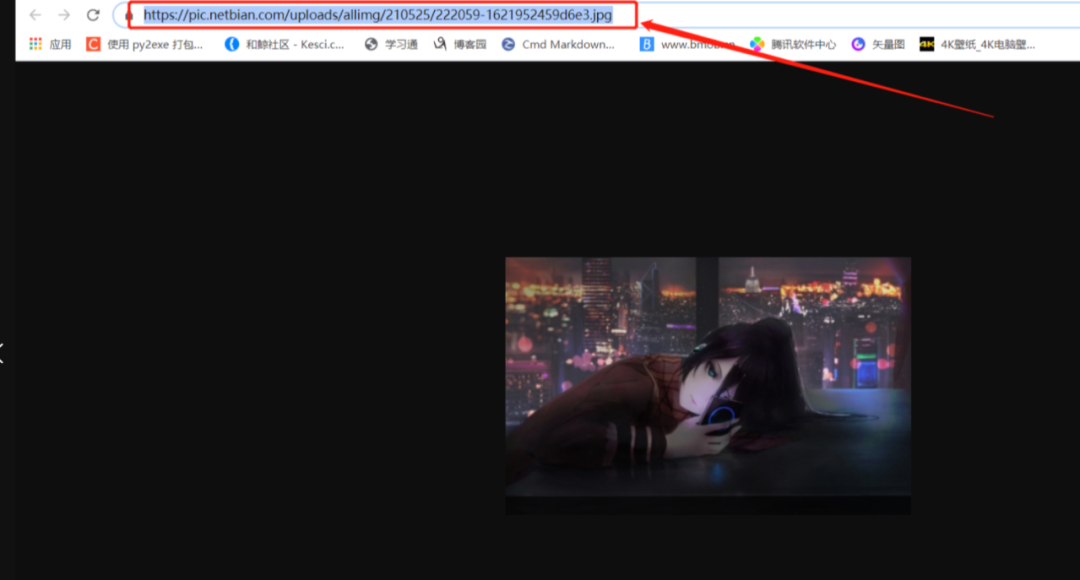
在获取图片的发送请求地址前加上刚刚复制的https://pic.netbian.com
运行,OK,获取完毕
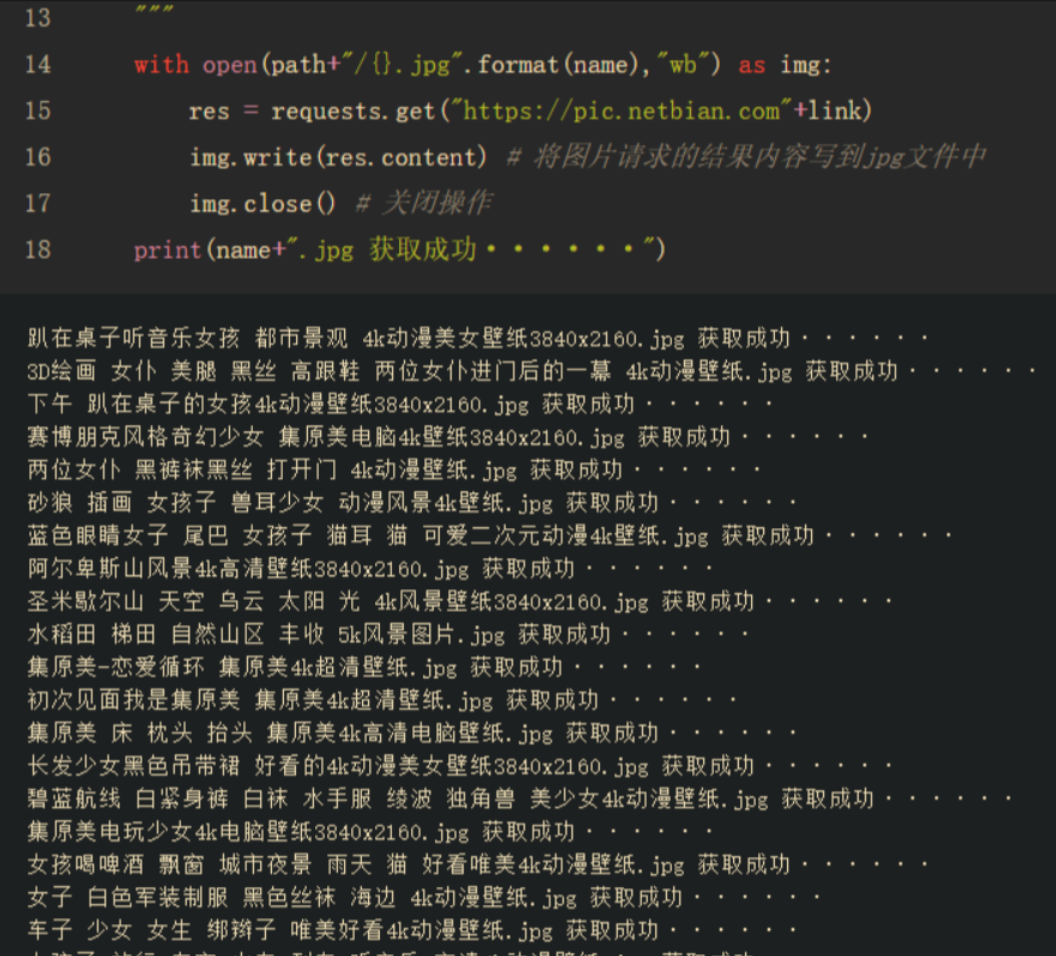
成功运行代码
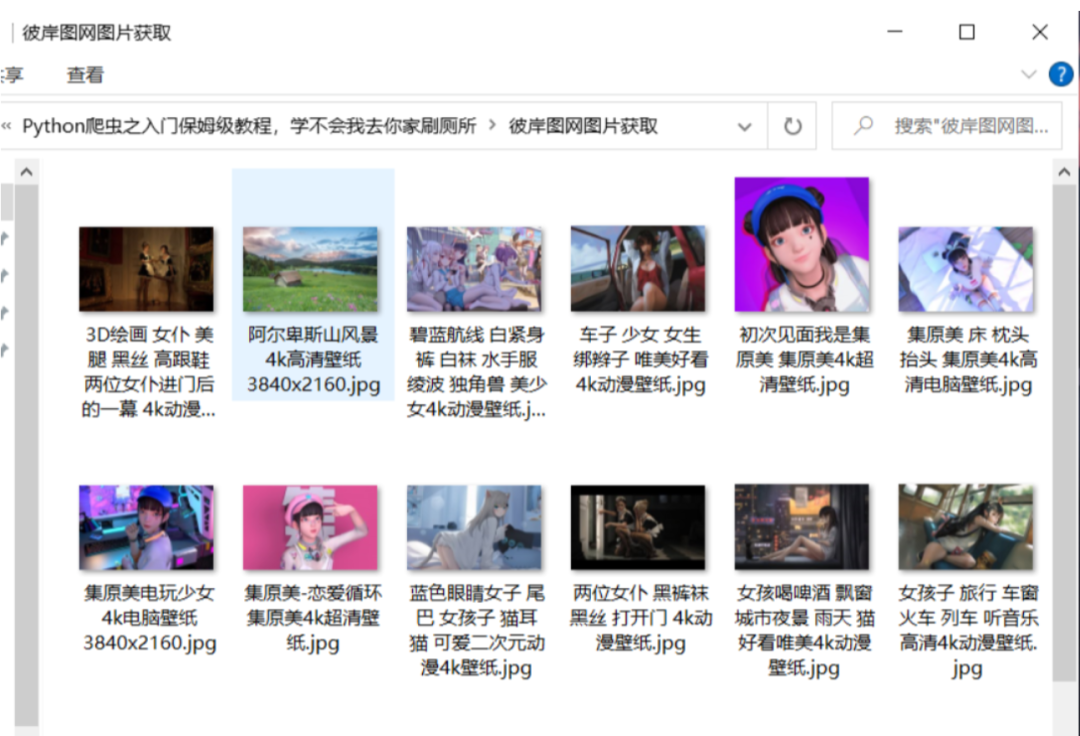
保存的图片
完整代码
import requestsimport reimport osurl = "https://pic.netbian.com/"headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"}response = requests.get(url=url,headers=headers)response.encoding = response.apparent_encoding""". 表示除空格外任意字符(除\n外)* 表示匹配字符零次或多次? 表示匹配字符零次或一次.*? 非贪婪匹配"""parr = re.compile('src="(/u.*?)".alt="(.*?)"') # 匹配图片链接和图片名字image = re.findall(parr,response.text)path = "彼岸图网图片获取"if not os.path.isdir(path): # 判断是否存在该文件夹,若不存在则创建 os.mkdir(path) # 创建 # 对列表进行遍历for i in image: link = i[0] # 获取链接 name = i[1] # 获取名字 """ 在文件夹下创建一个空jpg文件,打开方式以 'wb' 二进制读写方式 @param res:图片请求的结果 """ with open(path+"/{}.jpg".format(name),"wb") as img: res = requests.get("https://pic.netbian.com"+link) img.write(res.content) # 将图片请求的结果内容写到jpg文件中 img.close() # 关闭操作 print(name+".jpg 获取成功······")
-END-
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、自动化测试带你从零基础系统性的学好Python!
👉[CSDN大礼包:《python安装工具&全套学习资料》免费分享](安全链接,放心点击)
👉Python学习大礼包👈

👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python书籍和视频合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉Python面试刷题👈

👉Python副业兼职路线👈


这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以点击链接免费领取或者保存图片到wx扫描二v码免费领取 【保证100%免费】
👉[CSDN大礼包:《python安装工具&全套学习资料》免费分享](安全链接,放心点击)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









