







Java道经第3卷 - 第5阶 - Redis(一)
|_ v3-5-ssm-redis
|_ 8020 redis-jedis
|_ 8021 redis-template
|_ 8022 redis-redisson
JB3-5-Redis(一)
JB3-5-Redis(二)
JB3-5-Redis(三)
武技:创建 v3-5-ssm-redis 父项目
- 在父项目中管理依赖:
<dependencyManagement>
<dependencies>
<!--spring-boot-starter-parent-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<!--声明该项目是一个POM类型的父项目,不参与打包,只用于传递依赖-->
<type>pom</type>
<!--导入该项目的 `<dependencyManagement>` 到本项目-->
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
- 在父项目中添加依赖:
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<junit.version>4.13.2</junit.version>
<lombok.version>1.18.24</lombok.version>
<hutool.version>5.8.25</hutool.version>
<jedis.version>2.9.0</jedis.version>
<redisson-spring-boot-starter.version>3.33.0</redisson-spring-boot-starter.version>
</properties>
<dependencies>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<!--hutool-all-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
</dependency>
</dependencies>
S01. Redis服务搭建
E01. Windows服务搭建
武技:在 Windows 中搭建单机 Redis 服务
1. 下载安装Redis服务
下载:下载 redis-for-windows 服务:
- 偶数版本号如 3.0 为稳定版,奇数版本号如 3.1 为不稳定版。
- Redis2.8+ 支持 redis-sentinel 哨兵。
- Redis3.0+ 支持 redis-cluster 集群。
安装:直接解压缩即可,目录结构如下:
redis-server.exe: 服务端程序,提供 Redis 服务。redis-cli.exe: 客户端程序,通过它连接 Redis 服务和操作数据。redis-check-aof.exe: 更新日志检查工具,用于对 AOF 文件进行修复。redis-benchmark.exe: 性能测试工具,用于模拟客户端向服务端发送操作请求。redis.windows.conf: Redis主配文件,在将 Redis 作为第三方软件使用时生效。redis.windows-service.conf: Redis 主配文件,在将 Redis 作为系统服务使用时生效。
2. 启动Redis服务端
- 在 Redis 家目录新建 start 目录,将 Redis 的客户端和服务端的 .exe 程序都拷贝到该目录下。
- 开发配置文件 start/6379.conf,初始内容可以从 redis.windows.conf 中复制,精简后内容如下:
# 配置Redis服务的IP地址,127.0.0.1用于自动获取本机IP地址
bind 127.0.0.1
# 配置Redis服务的端口号,是同一IP地址下,不同服务的标识
port 6379
# 配置连接超时时间,单位秒: 若该时间内,客户端和服务端都没有进行数据交互则断开连接
# 0表示永不断开
timeout 0
# 配置数据目录,RDB快照和AOF文件都会存储在这里
dir ./
# 配置客户端连接服务端时,需要的密码,该项配置用于提高安全性
requirepass 123
- 启动 Redis 服务端,服务器运行需要一直保持 CMD 窗口,相关命令如下:
# 进入start目录
cd D:\redis\redis-x64-3.2.100\start
# 去注释查看配置文件
findstr /V "#" 6379.conf
# 以指定配置文件启动Redis服务端
redis-server 6379.conf
# 查看Redis服务端进程
tasklist | findstr redis*
# 查看6379端口号当前被哪个进程占用
netstat -ano | findstr 6370
# 强制杀死11820进程
taskkill /pid 11820 /f
3. 启动Redis客户端
- 启动 Redis 客户端,服务器运行需要一直保持CMD窗口,相关命令如下:
# 进入start目录
cd D:\redis\redis-x64-3.2.100\start
# 以指定配置文件启动Redis服务端
# 参数 `-h 127.0.0.1`: 服务器IP,默认127.0.0.1,可省略。
# 参数 `-p 6379`: 服务器端口,默认6379,可省略。
# 参数 `-a` 表示密码,不填写密码也可以登录,但无操作数据权限。
redis-cli -h 127.0.0.1 -p 6379 -a 123
# 测试客户端: 返回 `PONG` 表示连通成功
ping
4. 部署Redis服务端
心法:将 Redis 部署为 Windows 服务可以一直保持后台运行(部署哨兵服务需要额外添加
--sentinel参数)。
# 进入start目录
cd D:\redis\redis-x64-3.2.100\start
# 部署服务
redis-server --service-install 6379.conf --service-name redis6379
# 在任意位置删除redis6379服务,需要CMD使用管理员权限
sc delete redis6379
# 在任意位置启动redis6379服务,需要CMD使用管理员权限
net start redis6379
# 在任意位置停止redis6379服务,需要CMD使用管理员权限
net stop redis6379
E02. Docker容器搭建
武技:在 Docker 中搭建单机 Redis 容器
1. 创建相关目录
# 创建单机Redis的配置目录
mkdir -p /opt/redis/single/conf;
# 创建单机Redis的数据目录
mkdir -p /opt/redis/single/data;
# 提升目录权限
chmod -R 777 /opt/redis/single;
2. 编写配置文件
心法:Redis 服务在启动时会读取
redis.conf中的配置项。
| 配置项 | 描述 |
|---|---|
port: 6379 | Redis 服务端口号 |
bind: 0.0.0.0 | 接收来自任意一个网卡的 Redis 请求 |
protected-mode: no | 关闭保护模式,允许外网远程连接,前提是不设置密码 |
enable-debug-command: yes | 启用 debug 命令,便于学习和测试命令 |
dir ./ | 工作目录,RDB 文件和 AOF 文件都会在这个目录下生成 |
武技:编写 Redis 配置文件
- 创建 redis.conf 文件:
touch /opt/redis/single/conf/redis.conf
- 填写如下内容:
# Redis服务端口号
port 6379
# 接收来自任意一个网卡的Redis请求
bind 0.0.0.0
# 关闭保护模式,允许外网远程连接,前提是不设置密码
protected-mode no
# 启用debug命令,便于学习和测试命令
enable-debug-command yes
# 工作目录,RDB文件和AOF文件都会在这个目录下生成
dir ./
3. 创建运行容器
- 创建并运行 Redis 容器:
# 拉取镜像(二选一)
docker pull registry.cn-hangzhou.aliyuncs.com/joezhou/redis:7.0.5;
docker pull redis:7.0.5;
# 创建并运行Redis容器
# 参数 `redis-server /etc/redis/redis.conf`: 以容器内指定配置文件启动Redis容器
docker run -itd --name redis --network host -p 6379:6379 \
-v /opt/redis/single/conf:/etc/redis \
-v /opt/redis/single/data:/data \
registry.cn-hangzhou.aliyuncs.com/joezhou/redis:7.0.5 \
redis-server /etc/redis/redis.conf
- 查看 Redis 容器:
# 查看Redis容器
docker ps --format "{{.ID}}\t{{.Names}}\t{{.Ports}}"
# 查看Redis后30条启动日志
docker logs redis --tail 30
- 连接 Redis 服务:
# 进入Redis容器内部
docker exec -it redis bash
# 查看Redis版本
redis-server --version
# 连接Redis服务(-p 6379 可以省略)
redis-cli -p 6379
# 测试存值
6379> set a 10
# 测试取值
6379> get a
- 永久开放 Redis 相关端口(防火墙关闭时可忽略):
# 永久开发6379端口
firewall-cmd --add-port=6379/tcp --permanent
firewall-cmd --reload
E03. 安装可视界面
1. RedisHelper
武技:在 IDEA 中搭建 Redis 可视化界面
- 安装 Redis Helper 插件。
- 点击右侧 Redis Helper 进入配置页面,填写连接名,虚拟机地址和 Redis 端口号,密码空着即可。
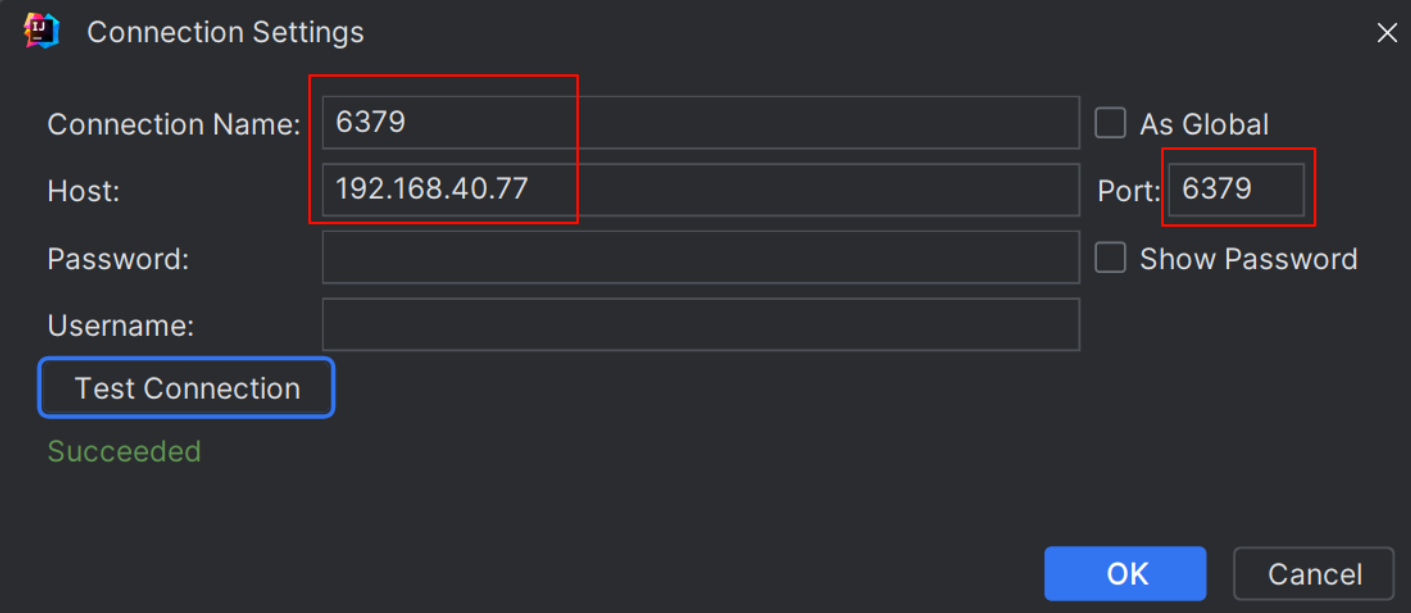
- 点击测试按钮 Test Connection,若通过测试则点击 OK 完成添加。
S02. Redis基础入门
E01. 基础概念入门
1. NoSQL基础概念
心法:NoSQL 全称 Not Only SQL,意为不止于 SQL,是一种泛指非关系型数据库的全新理念,如键值对结构的 Redis,文档结构的 MongoDB,图形结构的 Neo4j 等。
| NoSQL特点 | 描述 |
|---|---|
| 高扩展 | 数据之间无关联,故非常容易进行修改和扩展 |
| 高性能 | 数据结构简单,在海量数据量场景下具有高读写性能 |
| 更灵活 | 无需事前建立表结构,更灵活的操作数据,避免繁琐的表,字段的关系操作 |
| 高可用 | 通常采用分布式架构,可以在多台服务器上部署,实现水平扩展和高可用性 |
2. Redis基础概念
心法:Redis 缓存中间件是一款基于 C 语言开发的免费开源的缓存数据库,目前被 github,twitter,stackOverFlow,阿里巴巴,百度,美团,搜狐,新浪微博等项目使用。
Redis 技术特点如下:
| Redis特点 | 描述 |
|---|---|
| 原子操作 | Redis 是单线程的,避免了并发问题和线程切换消耗 |
| 内存存储 | 数据默认保存在内存,官测 50 个并发执行 10W 个请求时,读速 11W次/s,写速 8.1W次/s |
| 多种场景 | 常用于缓存热点数据,高效计数,秒杀限购,分布式锁等场景 |
| 多种结构 | 包括字符串、哈希、列表、集合、有序集合等结构,足以应付更多复杂的使用场景 |
Redis 配合 MySQL:Redis 更多被用来实现应用和数据库之间读操作的缓存层,主要目的是减少数据库 IO,为 DB 抵挡伤害。
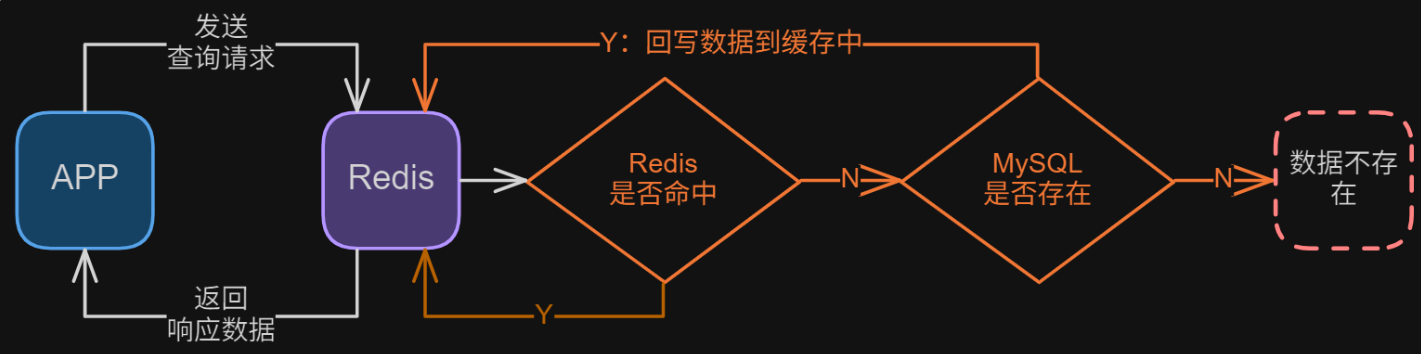
E02. 双写同步方案
心法:如何保持 Redis 和 MySQL 数据双写一致性
若追求数据的 强一致性,则推荐使用 分布式锁,但并发性能会因此而被大幅度降低。
若追求数据的 最终一致性,则推荐使用 延迟双删 等无锁策略,牺牲极少量的数据一致性来换取并发性能的提升。
1. 旁路缓存策略
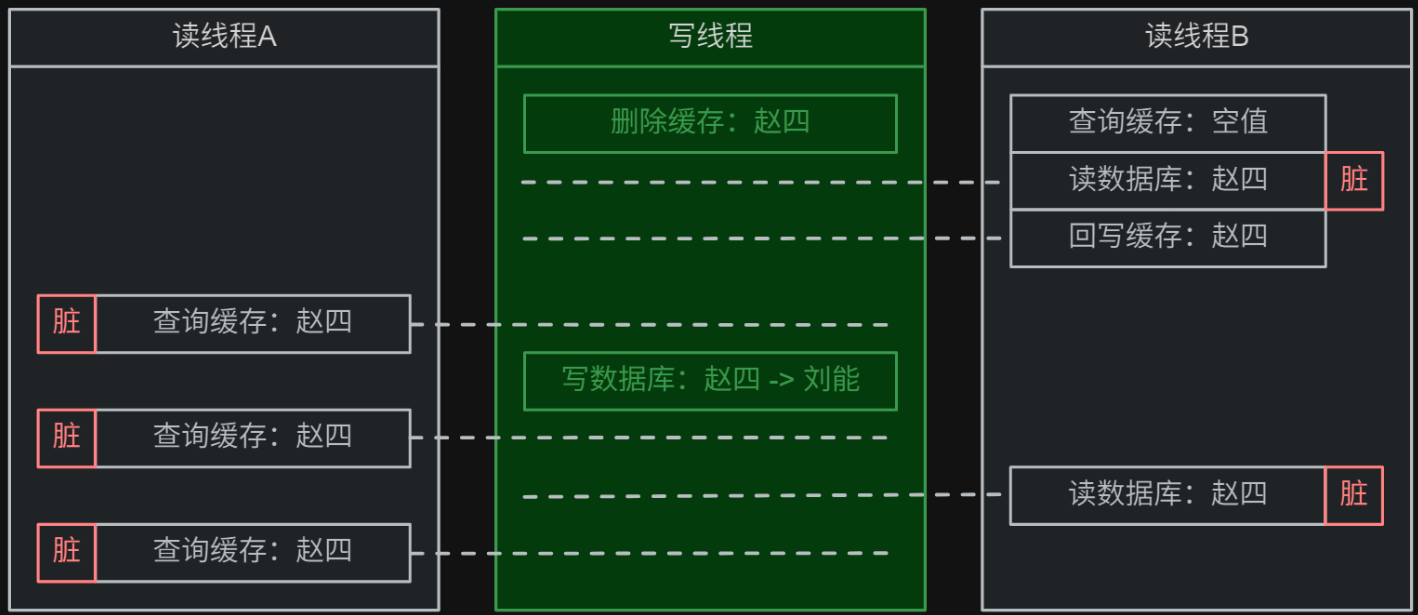
心法:旁路缓存策略就是先删除缓存,再写数据库,该方案数据一致性最差。
旁路缓存缺点:使用旁路缓存策略时,某读线程若恰好在写线程的 删除缓存 和 写数据库 之间发生了读操作,则:
- 缓存未命中,该读线程会从数据库中查询到脏数据,并回写到缓存中。
- 随后导致在该缓存数据过期时间内,后续的全部查询请求都直接从缓存中得到了脏数据。
- 可以发现,一个
恰好就会导致很多脏数据的出现,数据一致性最差。
模拟流程如下所示:假设 1 个写线程需要将缓存和数据库中的数据从 name = "赵四" 修改为 name = "刘能":
2. 双删缓存策略
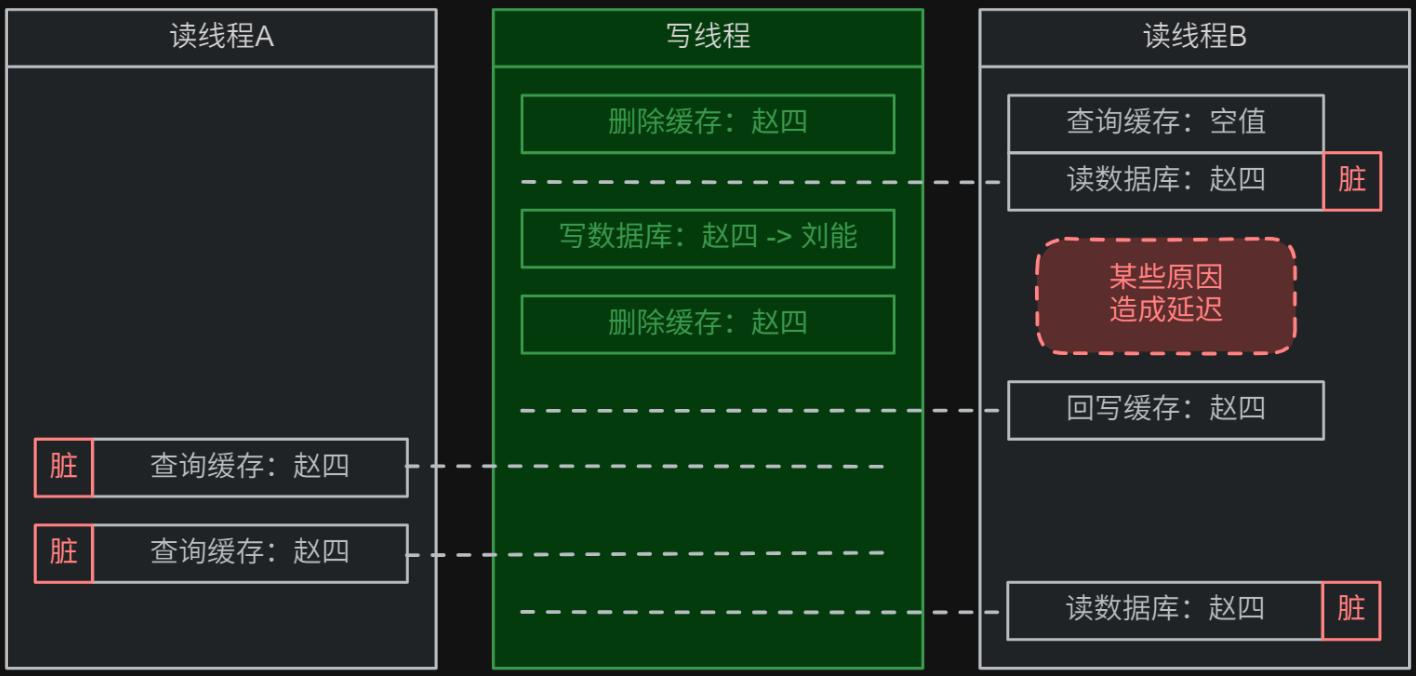
心法:双删缓存策略就是在旁路缓存的基础上,在写完数据库后,立刻再删除一遍缓存,减少脏数据,提升了一些数据一致性,但也不是最优解。
双删缓存缺点:使用双删缓存策略时,某读线程若恰好在写线程的 删除缓存 和 写数据库 之间发生了读操作,则:
- 缓存未命中,该读线程会从数据库中查询到脏数据。
- 又恰好该读线程因为某些原因发生了延迟,在写线程的第二次删除缓存操作后才完成缓存回写。
- 则仍然会导致在该缓存数据过期时间内,后续的全部查询请求都直接从缓存中得到了脏数据。
- 可以发现,两个
恰好才会导致很多脏数据的出现,数据一致性比旁路缓存策略强一点。
模拟流程如下所示:假设 1 个写线程需要将缓存和数据库中的数据从 name = "赵四" 修改为 name = "刘能":
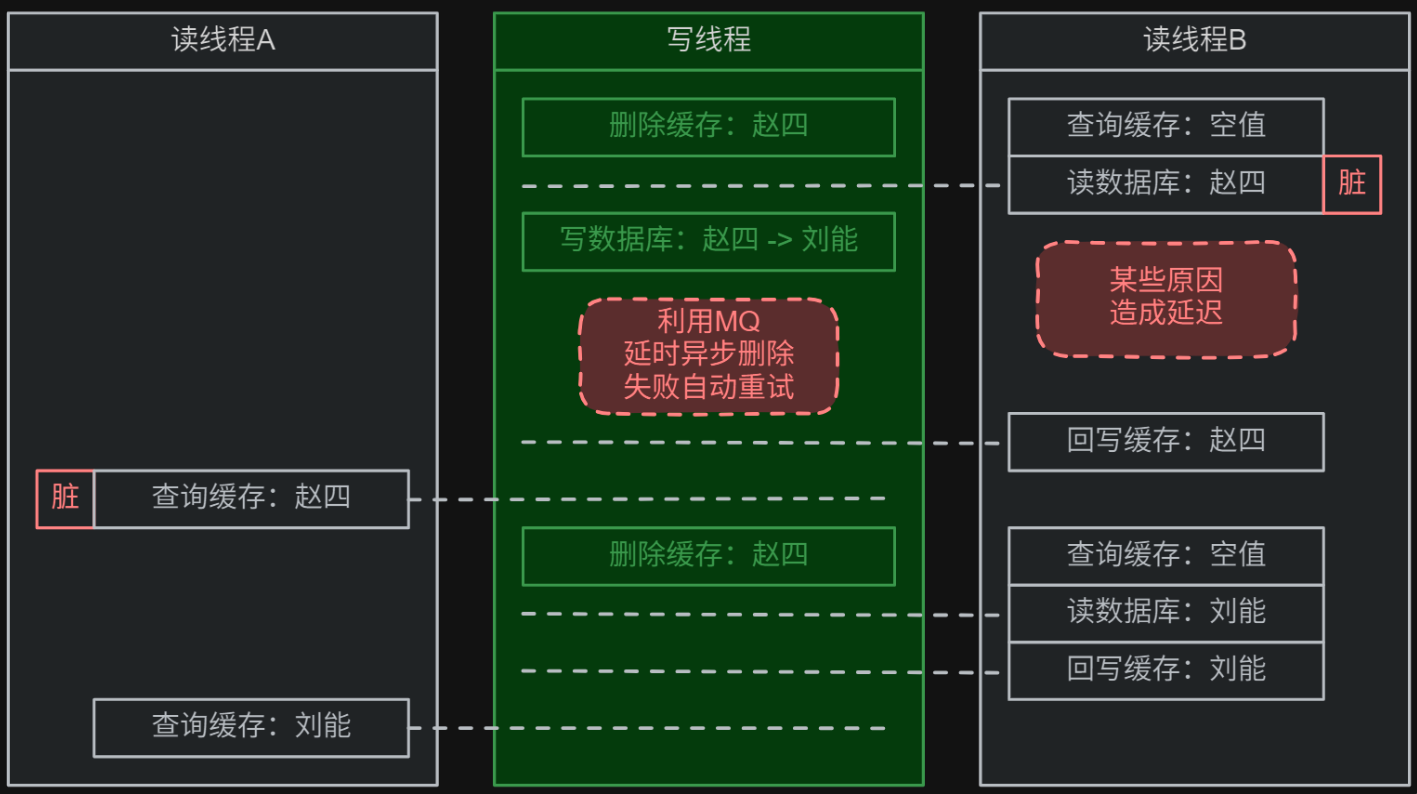
3. 延时双删策略
心法:延时双删策略就是在立即双删的基础上,将第二次的删除操作修改为通过 MQ 延时删除,(一般延迟 1 ~ 2 秒即可),以保证读线程回写的脏数据最终可以被删除,大大减少了脏数据,数据一致性最好。
模拟流程如下所示:假设 1 个写线程需要将缓存和数据库中的数据从 name = "赵四" 修改为 name = "刘能" :
4. 订阅binlog日志
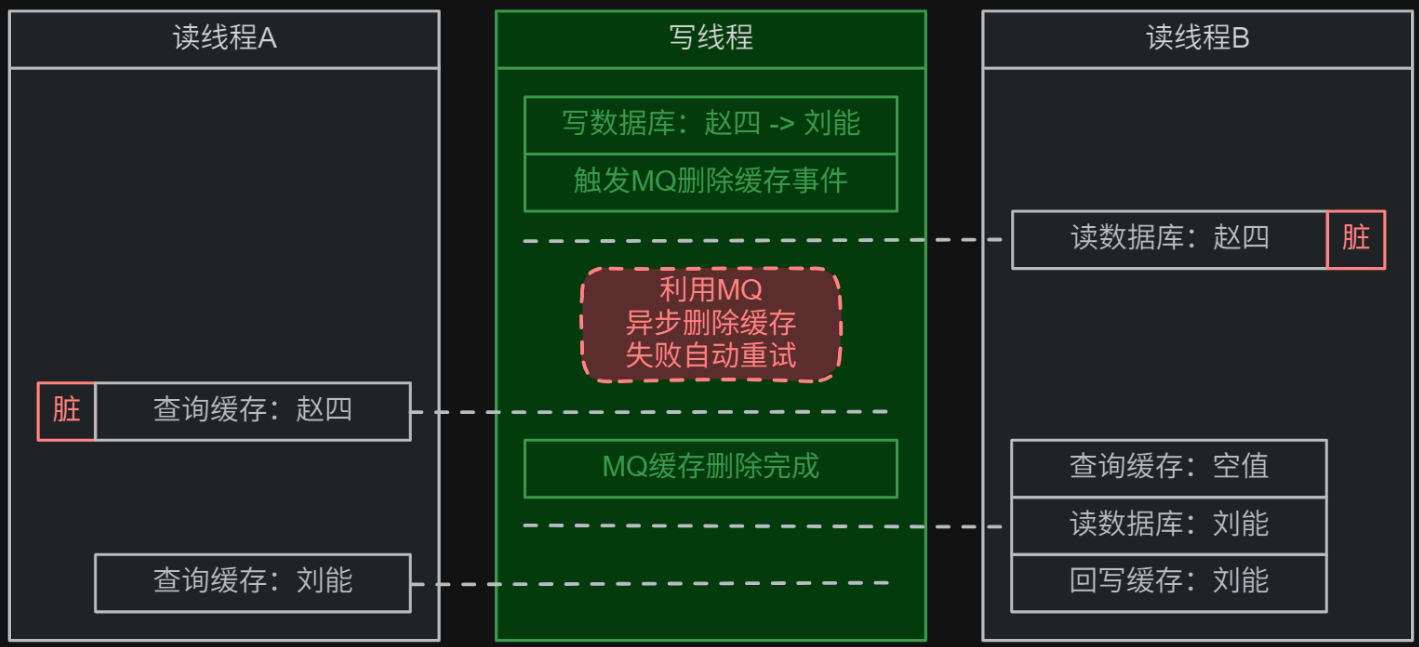
心法:binlog 是 MySQL 中的一种二进制日志文件,用于记录 MySQL 内部对数据库的所有修改。
订阅 binlog 缺点:
- 需要提前让 MQ 监听 MySQL 的 binlog 日志的实时变化,学习成本上升。
- 写线程直接操作数据库,触发 MQ 监听,然后让 MQ 异步删除 Redis 缓存,此过程中可能会产生少量脏数据。
模拟流程如下所示:假设 1 个写线程需要将缓存和数据库中的数据从 name = "赵四" 修改为 name = "刘能" :
E03. 常见并发现象
1. Redis缓存击穿
心法:缓存击穿指的是热点 key 突然过期,导致大量请求打在 DB 身上的现象。
情景模拟:小米 1 号手机做活动,今晚 9 点开抢:
- 8.00:运营人员赵四将该手机数据预热到 Redis 中。
- 9.00:活动开始,大量请求来袭。
- 9.30:小米 1 号手机的缓存突然过期,大量相同请求打到 DB 身上致其死亡,该缓存被击穿。
解决方案:
- 设置缓存永不过期:需要注意,这样可能会导致缓存空间不足或者数据过时的问题。
- 加锁更新缓存:使用分布式锁来保证只有一个线程去查询数据库并更新缓存。
- 自动续期:设置该缓存每次被查询时自动续期等。
2. Redis缓存穿透
心法:缓存穿透指的是大量请求意图访问根本不存在的数据,导致大量请求打在 DB 身上的现象。
情景模拟:小米 1 号手机做活动,今晚 9 点开抢:
- 8.00:运营人员广坤将全部手机数据预热到 Redis 中。
- 8.59:某当红主播为小米 1 号手机做宣传,结果口误说成了小米 2 号手机,而 DB 中根本没有这款产品。
- 9.00:活动开始,大批量 “查询 2 号手机” 的无效请求直接穿透 Redis 缓存打在 DB 身上,最终导致 DB 宕机。
解决方案:
- 存储空值:即使 DB 中查无此数据时,也要在 Redis 中缓存一个 null 值以拦截后续无效请求(内存占用高)。
- 布隆过滤器:使用布隆过滤器拦截无效请求。
3. Redis缓存雪崩
心法:缓存雪崩可以理解为大面积的击穿在同一时间发生的现象。
情景模拟:今日小米全部手机都活动,今晚 9 点开抢:
- 8.00:运营人员刘能将全部手机数据预热到 Redis 中。
- 9.00:活动开始,大量请求来袭。
- 9.30:全部小米手机的缓存同时过期,大量不同请求打到 DB 身上致其死亡,缓存大面积雪崩。
解决方案:
- 设置缓存永不过期:需要注意,这样可能会导致缓存空间不足或者数据过时的问题。
- 添加随机盐:为批量缓存的过期时间添加不同的随机盐。
- 分散缓存:将热点数据分布在不同的 Redis 节点中。
E04. 过期删除策略
心法:Redis 默认对过期的缓存数据采取惰性 + 定期的策略进行清理。
1. 过期字典
心法:Redis 过期字典 ,全称 expires dict,底层采用 hash 结构存储所有设置了过期时间的缓存数据。
过期字典结构:
- 过期字典的 key:是一个指针,指向某个缓存数据。
- 过期字典的 value:是一个 long 型整数,存储缓存数据的过期时间。
过期字典使用流程:当客户端访问某条缓存数据时,Redis 会首先检查该缓存数据是否存在于过期字典中:
- 若不存在,则正常读取缓存数据。
- 若存在,则比对该缓存数据的过期时间和本地时间,判定该缓存数据是否已经过期。
2. 定时删除策略
心法:定时删除策略,全称 Timed Deletion Strategy,该策略下,为某 KEY 添加过期时间的同时,会为其创建一个定时器,时间一到,立刻删除它。
优点:KEY 一过期就会立刻被删除,即内存可以被尽快地释放。
缺点:当过期 KEY 较多时,CPU 可能会将大量时间和资源浪费在删除过期 KEY 上,影响其他重要操作。
3. 惰性删除策略
心法:惰性删除策略,全称 Lazy Deletion Strategy,该策略下,不主动删除过期 KEY,每当客户端访问某 KEY 时,都先检查它是否已过期,若是则立刻删除它,然后返回 null。
优点:将删除过期 KEY 的操作延后,从而让出 CPU 资源到更有用的 KEY 上。
缺点:若一个过期 KEY 长时间没有被访问到,则会一直占用内存。
4. 定期删除策略
心法:定期删除策略,全称 Regular Deletion Strategy,该策略下,默认每隔 100ms 从 Redis 中随机抽样 20 条 KEY 并删除其中全部过期 KEY,若删除比例超过 1/4,则重复操作。
优点:既能缓解一部分定时删除对 CPU 的压力,又能缓解一部分惰性删除对内存的压力。
缺点:内存释放方面比不过定时删除策略,CPU 资源方面比不过惰性删除策略。
E05. 内存淘汰策略
心法:内存淘汰策略,全称 Memory Eviction Strategy,指的是当 Redis 的运行内存已超过 Redis 设置的最大内存后,会使用哪种策略来删除某些 KEY,以保障 Redis 高效运行。
最大内存限制:可通过配置文件中的 maxmemory 项进行调整,单位字节,默认 0,表示无限制。
内存淘汰策略:可通过配置文件中的 maxmemory-policy 项进行调整,默认 noeviction,其余可选项如下:
| 淘汰策略 | 描述 | 其他 |
|---|---|---|
| noeviction | 不淘汰,内存溢出直接 OOM | Redis3.0 之后默认 |
| volatile-random | 在过期字典中随机淘汰任意 KEY | |
| volatile-ttl | 在过期字典中优先淘汰离自然死亡更近的 KEY | |
| volatile-lru | 在过期字典中淘汰最久未被使用的 KEY | Redis3.0 之前默认 |
| volatile-lfu | 在过期字典中淘汰最少被使用的 KEY | Redis4.0 新增 |
| allkeys-random | 在所有 KEY 中随机淘汰任意 KEY | |
| allkeys-lru | 在所有 KEY 中淘汰最久未被使用的 KEY | |
| allkeys-lfu | 在所有 KEY 中淘汰最少被使用的 KEY |
武技:查看当前 Redis 版本所使用的内存淘汰策略和最大内存限制
# 进入Redis容器内部
docker exec -it redis bash
# 查看当前Redis版本所使用的内存淘汰策略
redis-cli -p 6379 config get maxmemory-policy
# 查看当前Redis版本所使用的最大内存限制
redis-cli -p 6379 config get maxmemory
# (临时)设置内存淘汰策略为 valatile-lru,仅对当前会话有效
redis-cli -p 6379 config set maxmemory-policy volatile-lru
# (永久)设置内存淘汰策略为 valatile-lru,此时会重写 redis.conf 文件
redis-cli -p 6379 config set maxmemory-policy volatile-lfu
redis-cli -p 6379 config rewrite
E06. 慢查日志操作
心法:Redis 慢查日志用于记录 Redis 命令的执行时间,但 Redis 服务端和客户端之间的网络 IO 时间并不会被记录。
慢查询记录在内存中的一个 FIFO 的定长队列中,该队列随 Redis 服务关闭而销毁,建议对其定期进行持久化操作。
慢查询日志结构如下:
| 慢查询日志结构 | 描述 | 示例 | |
|---|---|---|---|
| 第一部分 | 命令标识 | 慢查询日志的唯一标识,自动递增 | (integer) 0 |
| 第二部分 | 命令时间 | 命令发生的时间,是一个 UNIX 时间戳(秒级) | (integer) 1699957754 |
| 第三部分 | 命令耗时 | 命令执行的总耗时,单位微秒,1000 微秒是 1 毫秒 | (integer) 1622 |
| 第四部分 | 命令内容 | 该命令本身内容以及组成该命令的参数数组 | 1) "get"2) "money" |
| 第五部分 | 客户端地址 | 客户端的IP地址和端口(发起该命令的客户端连接信息) | 127.0.0.1:46340 |
| 第六部分 | 客户端名称 | 若通过 client setname xxx 命令设置过名称则显示,否则为空串 | "" |
武技:在 Redis 主配中配置慢查询项
- 修改相关配置:
# 进入Redis容器内部并登录默认端口6379的Redis服务端
docker exec -it redis bash
redis-cli -p 6379
# (临时设置)耗时超过1微秒的命令都会进入队列,-1表示关闭慢查询,默认10000,开发中建议设置1000
config set slowlog-log-slower-than 1
# (临时设置)慢查询数量超过此值后,先进的记录会被丢弃,默认128,开发中建议设置1000以上
config set slowlog-max-len 1024
- 测试慢查询是否配置成功:
# 进入Redis容器内部并登录默认端口6379的Redis服务端
docker exec -it redis bash
redis-cli -p 6379
# 获取慢查询队列中的3条数据(倒查)
6379> slowlog get 3
# 获取慢查询队列中有多少条数据
6379> slowlog len
# 重置整个慢查询队列
6379> slowlog reset
S03. Redis数据类型
心法:Redis 默认支持 string, hash, list, set 和 zset 五种数据类型。
除 string 外的四种数据类型都视为容器类型且满足以下两条原则:
- 自建:添加元素时自动创建容器,以加速创建过程。
- 自毁:容器中无元素时自动删除容器,以立刻释放内存。
E01. Redis类型基础
1. Redis缓存结构
心法:Redis 底层使用
key-value结构存储数据
| 结构 | 描述 |
|---|---|
key | 仅支持 string 类型,可使用英文冒号分割目录层级,如 “user:01:name” 等。 |
value | 支持 string、hash、list、set 和 sorted_set 五种自带本地方法的数据类型。 |
2. Redis大KEY问题
心法:普遍来讲,当一个 Key 对应的 value 值所占用的内存在 10KB ~ 1MB 时,就可以认为它是大 Key 了,具体数值根据具体业务场景进行调整。
大 KEY 风险问题:
- 响应时间变慢:操作大 KEY 比操作小 KEY 更耗时。
- 备份恢复变慢:大 KEY 会使 RDB 快照文件更大,或 AOF 重写时间更长。
- 网络传输变慢:主从复制或集群间的数据迁移时,大 KEY 会占用更多网络带宽。
大 KEY 检索方案:
- 使用工具:使用 rdbtools 工具分析 RDB 文件,找出内存占用大的 KEY,很久不更新了。
- 查看慢日志:因为大 KEY 很容易导致命令更加耗时,从而被记录在慢日志中。
- RedisInsight 客户端:RedisInsight 可以监控大 Key,它提供了内置的 Memory Analysis 内存分析功能,能直观识别和定位大 Key。
- 使用自带命令:在 Redis 5.0 版本之后,redis-cli 增加了一个非常有用的命令 --bigkeys,用于扫描并报告数据库中的大键(即占用空间较大的键)。
大 KEY 解决方案:
- 提前压缩数据:一些不需要即时解压的字符串数据可以提前进行压缩,比如日志数据等。
- 提前拆分数据:将大 KEY 的数据按时间或 hash 等维度拆分成多个小 KEY 进行存储,并通过逻辑键进行关联。
- 使用集群分片:将数据分散到多个节点上,缓解单点压力。
- 设置过期时间:为大 KEY 设置适当的过期时间,自动清理不再需要的数据。
- 建立监控系统:一旦发现潜在的大 KEY,立即通过报警提示进行干预。
武技:使用 redis-cli --bigkeys 命令定位大 KEY
# 进入Redis容器内部
docker exec -it redis bash
# 全库分析大 KEY
redis-cli --bigkeys
# 仅在0号库和1号库分析大 KEY,此时假设定位到有一个大 KEY 叫做 key:1
redis-cli --bigkeys -d 0 -d 1
# 单独查看 key:1 所占内存(单位字节),结果包括实际内容长度和相关元信息
redis-cli memory usage key:1
3. SDS字符串
心法:SDS字符串,全称 Simple Dynamic String,即简单动态字符串,是 Redis 自主使用 C 语言实现的字符串的底层算法,其意图是提升字符串的速度和性能。
SDS 结构是通过 struct sdshdr 来表示的,其定义如下:
struct sdshdr {
// 记录 buf 数组中已使用字节的数量,若需要获取字符串长度,可直接取出此值,无需像C一样遍历计算,提升速度。
int len;
// 记录 buf 数组中未使用字节的数量,该空间可以在字符串追加时,自动进行拓展和预分配以避免频繁操作内存。
int free;
// 字节数组,用于保存实际数据,最后一个字符为空字符且不会被计算在len的结果中。
char buf[];
};
SDS字符串优势如下:
- 长度计算更快:SDS 在头部存储了字符串的长度信息,因此可以直接获取字符串的长度,而不需要像 C 字符串那样遍历整个字符串。
- 空间预分配:SDS 在分配空间时会预先分配一定大小的空间,以减少频繁的内存分配操作。
- 惰性释放:当 SDS 字符串缩短时,并不会立即释放多余的空间,而是采取惰性空间释放的策略,待需要时再释放多余的空间。
- 二进制安全:SDS 可以保存任意二进制数据,而不仅仅局限于保存文本数据,因此具有二进制安全性。
- 兼容 C 字符串:SDS 封装了一些 C 字符串函数,使得它们也可以用于 SDS,方便了开发者的使用。
4. 重量级命令
心法:在使用 Redis 时,合理选择重量级命令和轻量级命令可以有效提高系统的性能和效率,避免不必要的资源浪费。
重量级命令:通常需要遍历大量的数据集或执行复杂的操作,可能会消耗更多的系统资源和时间,如 keys, flushdb, bgrewriteaof, bgsave 等。
轻量级命令:通常执行单个数据项的读写操作或简单的数据结构操作,消耗的系统资源和时间相对较少,如 set, get, lpop, rpush, del 等。
5. 通用命令
心法:Redis 通用命令中包含很多重量级命令,即耗时较长的命令,需要尽量避免在生产环境中使用。
武技:测试 Redis 常用的通用命令
# 生成100条测试数据,key值默认为 `key:0` 到 `key:99`
6379> debug populate 100
# 模拟阻塞5秒钟
6379> debug sleep 5
# 返回总键数,直接获取内部记录,不会遍历所有的键,不是重量级命令
6379> dbsize
# 返回符合RE表达式的所有键,重量级命令
6379> keys *:?9
# 返回 `key:0` 的数据类型,键不存在返回none
6379> type key:0
# 重命名 `key:0` 为 `key01`,键不存在报错
6379> rename key:0 key01
# 删除键 `key:0` 和 `key:1`,删除成功返回影响数,键不存在返回0
6379> del key:0 key:1
# 判断 `key:0` 和 `key:1` 是否存在,返回存在的总个数
6379> exists key:0 key:1
# 设置 `key:0` 在10秒后过期,成功返回1,键不存在返回0
6379> expire key:0 10
# 返回 `key:0` 的当前寿命,单位秒,键不存在返回-2,键永生返回-1
6379> ttl key:0
# 移除 `key:0` 的过期时间,使其永生
6379> persist key:0
# 删除当前库中的全部key,慎用
6379> flushdb
# 删除全部库中的全部key,更慎用
6379> flushall
# 优雅退出Redis客户端,等效于 `quit` 命令
6379> exit
E02. Redis字符类型
1. 字符类型string
心法:字符型 string 包括字符串,整数和二进制等。
数据结构:底层最终都是用字节数组存储数据,一个 string 最多存储 512MB 数据。
使用场景:常用于缓存,计数器,分布式锁,全局 ID,限流,位统计在线用户等场景。
常用命令:
SET key value [NX\|XX]:设置 key 的字符串值 。SETNX key value:仅当 key 不存在时,设置 key 的字符串值。SETEX key seconds value:设置 key 的字符串值和过期时间。GET key:获取 key 的值。STRLEN key:获取存储在 key 中的字符串值的长度。INCR key:将 key 的整数值增加一。DECR key:将 key 的整数值递减一。
武技:测试字符型 string 的常用 API 方法,模拟存储小米 99 号手机
m99的库存。
# 查看string类型的全部本地方法
6379> help @string
# 永久存储米99手机的库存为200,同名覆盖,无论key是否存在都成功,总是返回OK
6379> set Mi99 200
# 永久存储米99手机的库存为200,仅在key不存在时才成功并返回1,否则返回0
6379> setnx Mi99 200
# 存储米99手机的库存为200,并设置60秒后过期,返回OK
6379> setex Mi99 60 200
# 获取米99手机当前库存量,key不存在返回nil
6379> get Mi99
# 获取米99手机库存量的字节数组长度,UTF8编码下中文占3字节,GBK编码下中文占2字节
6379> strlen Mi99
# 对米99手机库存量自增1,键不存在时视库存量为0,自增后返回1,值不为数字报错
6379> incr Mi99
# 对米99手机库存量自减1,键不存在时视库存量为0,自减后返回-1,值不为数字报错
6379> decr Mi99
2. 哈希类型hash
心法:哈希型 hash 可视为 Java 中的 HashMap 容器,每个 hash 最多存储 42 亿个键值对。
数据结构:hash 类型拥有 key,field 和 value 三个字段。
使用场景:常用于存储实体类数据,比如用户数据,购物车数据等。
常用命令:
HSET key field value [field value ...]:设置 hash 字段的字符串值。HSETNX key field value:仅当 hash 字段不存在时,才设置该字段的值。HEXISTS key field:确定是否存在 hash 字段。HGET key field:获取 hash 字段的值。HGETALL key:获取 hash 中的所有字段和值。HINCRBY key field increment:将 hash 字段的整数值增加给定的数字。HLEN key:获取 hash 中的字段数。HDEL key field [field ...]:删除一个或多个 hash 字段。
武技:测试哈希型 hash 的常用 API 方法,模拟存储 1 号用户
u01的 bean 信息。
# 查看hash类型的全部本地方法
6379> help @hash
# 为1号用户添加姓名为lucky,成功返回1
6379> hset u01 name lucky
# 为1号用户添加姓名为lucky,若key已存在则失败返回0
6379> hsetnx u01 name lucky
# 判断1号用户是否已经设置了姓名,存在返回1,不存在返回0
6379> hexists u01 name
# 返回1号用户的姓名,key不存在返回nil
6379> hget u01 name
# 返回1号用户的所有属性和值,key不存在返回 `empty` 提示
6379> hgetall u01
# 为1号用户的年龄自增5,key不存在时年龄视为0,返回5,值不为数字报错,支持负数
6379> hincrby u01 age 5
# 返回1号用户中所有的键值对个数
6379> hlen u01
# 同时删除1号用户的姓名和性别,返回成功总数
6379> hdel u01 age gender
3. 列表类型list
心法:列表型 list 类似 Java 中有序双向 LinkedList 类型,用于存储有序字符串,允许重复元素,最多包含 42 亿个元素。
使用场景:列表类型常用于搭建消息队列,模拟栈结构和队列结构,展示数据列表,分页等场景。
常用命令:
LPUSH key element [element ...]:将一个或多个 element 前置到 list 中。RPUSH key element [element ...]:将一个或多个 element 后置到 list 中。LLEN key:获取 list 中的元素个数。LRANGE key start stop:从 list 中根据范围获取元素,包括两端值。LPOP key [count]:删除并获取 list 中的前 count 个元素,默认 count 为 1。RPOP key [count]:删除并获取 list 中的后 count 个元素,默认 count 为 1。LREM key count element:从左侧删除 list 中的 count 个 element 元素,返回影响条目数。LINSERT key BEFORE pivot element:在 list 中的 pivot 元素之前插入 element。LINSERT key AFTER pivot element:在 list 中的 pivot 元素之后插入 element。LINDEX key index:按索引从 list 中获取元素。
武技:测试列表型 list 的常用 API 方法,模拟存储 1 号用户的
u02选课信息。
# 查看list类型的全部本地方法
6379> help @list
# 2号用户左插选课js和java,返回插入后队列长度
6379> lpush u02 js java
# 2号用户右插选课mysql和spring,返回插入后队列长度
6379> rpush u02 mysql spring
# 返回2号用户一共选了多少课程
6379> llen u02
# 返回2号用户所选的0-3号课程,两端包括,负数视为倒数
6379> lrange u02 0 3
# 弹出2号用户所选的第一门课程,空列表返回nil
6379> lpop u02
# 弹出2号用户所选的最后2门课程,空列表返回nil
6379> rpop u02 2
# 从左向右删除2号用户所选的2个java课程,返回影响条目数
6379> lrem u02 2 java
# 在2号用户所选的js课程前插入jq,js不存在返回-1
6379> linsert u02 before js jq
# 在2号用户所选的js课程后插入css,js不存在返回-1
6379> linsert u02 after js css
# 返回1号位的元素
6379> lindex u02 1
4. 集合类型set
心法:集合型 set 可视为 Java 中的无序的 HashSet 类型,元素不允许重复,最多包含 42 亿个元素。
使用场景:set 类型常用于用户关注,共同好友,抽奖,点赞,签到,打卡等场景。
常用命令:
SADD key member [member ...]:将一个或多个成员添加到 set。SCARD key:获取 set 中的成员数。SMEMBERS key:获取 set 中的所有成员。SREM key member [member ...]:从 set 中删除一个或多个成员。SISMEMBER key member:确定指定成员是否为 set 的成员。SRANDMEMBER key [count]:从 set 中获取一个或多个随机成员。SPOP key [count]:从 set 中移除并返回一个或多个随机成员。SDIFFSTORE destination key [key ...]:求多个 set 的差集并将结果集存储到 destination 中。SINTERSTORE destination key [key ...]:求多个 set 的交集并将结果集存储到 destination 中。SUNIONSTORE destination key [key ...]:求多个 set 的并集并将结果集存储到 destination 中。
武技:测试集合型 set 的常用 API 方法,模拟存储 3 号用户的
u03关注明星。
# 查看set类型的全部本地方法
6379> help @set
# 3号用户同时关注jay和jj,重复添加返回0,返回总影响数
6379> sadd u03 jay jj
# 返回3号用户关注的全部明星数量
6379> scard u03
# 返回3号用户关注了哪些明星,重量级命令
6379> smembers u03
# 3号用户同时取关jay和jj,返回总成功影响数
6379> srem u03 jay jj
# 判断3号用户是否关注了jay,存在返回1,不存在返回0
6379> sismember u03 jay
# 随机3号用户的关注中选出5个明星,结果中的明星不重复
6379> srandmember u03 5
# 随机3号用户的关注中选出5个明星,结果中的同个明星有可能重复出现
6379> srandmember u03 -5
# 随机3号用户的关注中弹出5个不重复的元素,不支持负数
6379> spop u03 5
# 返回s1和s2的差集(相同部分减去)并存入result,重量级命令
6379> sdiffstore result s1 s2
# 返回s1和s2的交集(相同部分保留)并存入result,重量级命令
6379> sinterstore result s1 s2
# 返回s1和s2的并集(组合去重)并存入result,重量级命令
6379> sunionstore result s1 s2
5. 有序集合类型zset
心法:排序集合型 sorted-set,简称 zset,该类型底层使用的是跳表数据结构,其中的每个元素都会关联一个用于排序的 double 类型的分数,元素不允许重复但是分数可以重复。
使用场景:sorted-set 类型常用于排行榜,GEO 地理定位等场景。
常用命令:
ZADD key [NX\|XX] score member [score member ...]:将一或多个成员添加到zset中。ZCARD key:获取zset中的成员数。ZCOUNT key min max:对得分在给定值内的zset中的成员进行计数。ZSCORE key member:获取zset中与给定成员相关联的分数。ZRANGE key start stop [WITHSCORES]:按索引返回zset中的成员范围,得分从低到高排序。ZREVRANGE key start stop [WITHSCORES]:按索引返回zset中的成员范围,得分从高到低排序。ZRANGEBYSCORE key min max [WITHSCORES]:按分数返回zset中的成员范围,得分从低到排序。ZREVRANGEBYSCORE key max min [WITHSCORES]:按分数返回zset中的成员范围,得分从高到低排序。ZRANK key member:返回zset中指定成员的排名,得分从低到高排序。ZREVRANK key member:返回zset中指定成员的排名,得分从高到低排序。ZREM key member [member ...]:从zset中删除一个或多个成员。ZINCRBY key increment member:增加zset中指定成员的分数。
武技:测试排序集合型 sorted_set 的常用 API 方法,模拟存储
movie电影评分。
# 查看sorted-set类型的全部本地方法
6379> help @sorted-set
# 向movie中添加2.5分的LaoPao元素,同名覆盖,返回总影响数
6379> zadd movie 2.5 LaoPao
# 返回movie中全部元素总数
6379> zcard movie
# 返回movie中分数在0到9之间的元素数量
6379> zcount movie 0 9
# 返回movie中LaoPao元素的分数,LaoPao不存在返回nil
6379> zscore movie LaoPao
# 升序带分返回movie中索引0到3的元素
6379> zrange movie 0 3 withscores
# 降序带分返回movie中索引0到3的元素
6379> zrevrange movie 0 3 withscores
# 升序带分返回movie中3到7分的元素
6379> zrangebyscore movie 3 7 withscores
# 降序带分返回movie中7到3分的元素
6379> zrevrangebyscore movie 7 3 withscores
# 返回LaoPao元素在movie中的升序排名,从0开始
6379> zrank movie LaoPao
# 返回LaoPao元素在movie中的降序排名,从0开始
6379> zrevrank movie LaoPao
# 从movie中删除LaoPao元素,返回总影响数
6379> zrem movie LaoPao
# 将movie中LaoPao元素的分数自增5后返回,负数表示自减
6379> zincrby movie 5 LaoPao


















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









