







1. 概述
排序算法有很多种,每种排序算法都可以从时间复杂度,稳定性和是否是原地排序进行衡量。并不是时间复杂度低的算法就一定最好,不同的排序算法,应用场景不同,如何选择排序算法,如何实现一个通用的工业级排序算法,需要根据不同的情况,做出恰当的选择。
2. 如何选择排序算法
下图是前述讲到的排序算法一览表:
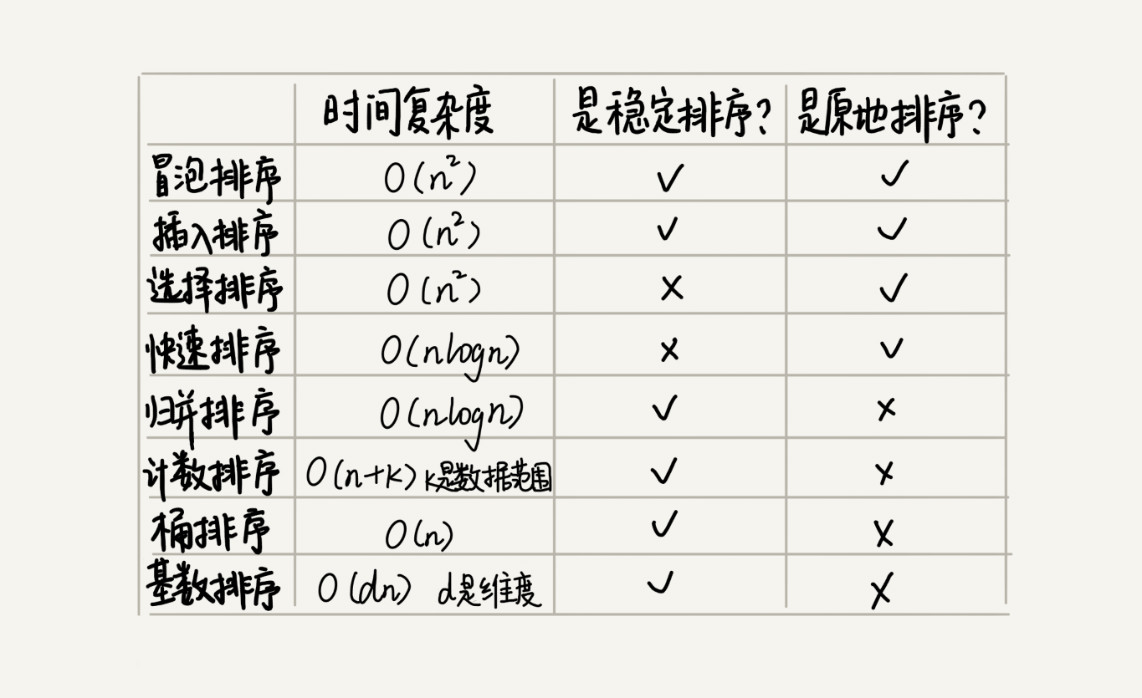
对于工业级排序算法,必然是通用的,因此:
- 由于现行排序算法应用场景特殊,因此不能选择线性排序算法。
- 对于数据规模小的排序,可以选用 O ( n 2 ) O(n^2) O(n2)的算法。
- 对于数据规模大的排序,选用 O ( n l o g ( n ) ) O(nlog(n)) O(nlog(n)),更加高效。
- 通用算法,为了兼顾数据规模,一般都会选择 O ( n l o g ( n ) ) O(nlog(n)) O(nlog(n))算法。
- 快速排序和堆排序,由于是原地排序,因此比归并排序更加实用,所以一般通用排序都会首选快排或者堆排序。
3. 如何优化快速排序
快排时间复杂度退化的根因在于“分区点是否合理”,因此主要优化分区点,保证被分两个区中数据量差不多。
- 三数取中法
从区间的首、中、尾分别取一个数,然后比较大小,取中间值作为分区点。
如果要排序的数组比较大,那“三数取中”可能就不够用了,可能要“5数取中”或者“10数取中”。 - 随机法
每次从要排序的区间中,随机选择一个元素作为分区点。
快排由于用递归实现,因此要警惕堆栈溢出。
- 限制递归深度,一旦递归超过了设置的阈值就停止递归。
- 在堆上模拟实现一个函数调用栈,手动模拟递归压栈、出栈过程,这样就没有系统栈大小的限制。
4. 通用排序算法实现技巧
- 数据量不大时,可以采取用时间换空间的思路
- 数据量大时,优化快排分区点的选择
- 防止堆栈溢出,可以选择在堆上手动模拟调用栈解决
- 在排序区间中,当元素个数小于某个常数是,可以考虑使用O(n^2)级别的插入排序
- 用哨兵简化代码,每次排序都减少一次判断,尽可能把性能优化到极致
5. 分析java中排序算法的实现
在JDK中,排序相关的主要是两个工具类:Arrays.java 和 Collections.java,具体的排序方法是sort()。这里要注意的是,Collections.java中的sort()方法是将List转为数组,然后调用Arrays.sort()方法进行排序,具体代码如下:
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
在Arrays类中,sort()有一系列的重载方法,罗列几个典型的Arrays.sort()方法如下:
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
public static void sort(long[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
public static void sort(Object[] a) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
}
重载方法虽然多,但是从“被排序的数组所存储的内容”这个维度可以将其分为两类:
- 存储的数据类型是基本数据类型
- 存储的数据类型是Object
第一种情况使用的是快排,在数据量很小的时候,使用的插入排序;
第二种情况使用的是归并排序,在数据量很小的时候,使用的也是插入排序,这种排序叫做专业名为TimSort。其中legacyMergeSort使用其实是堆排序。
以上两种场景所用到的排序都是「混合式的排序」,也都是为了追求极致的性能而设计的。
6. 典型问题
关于递归太深导致堆栈溢出的问题。对于这个问题,您说一般有两种解决方法,一是设置最深的层数,如果超过层数了,就报错。对于这样的问题,我想排序一个数列,超过了层数,难道就不排了么?
其次,stl中的sort默认是使用快排,但当递归深度过大时会转为使用归并排序。但是归并排序也是递归排序啊,如果两种排序都达到了最深层数怎么处理?
最后,应对堆栈溢出的方法是通过在堆上模拟实现一个函数调用栈,手动模拟递归压栈、出栈的过程,怎么实现?
- 递归太深报错也没问题,不过不建议这么处理
- 归并排序比较稳定,栈的深度是logn 非常小,所以不会堆栈溢出
- 关于手动模拟栈,你可以看看qsort()函数的实现。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









